
10 分钟上手Web Scraper,从此爬虫不求人
我现在很少写爬虫代码了,原因如下:
网站经常变化,因此需要持续维护代码。 爬虫的脚本通常很难复用,因此价值就很低。 写简单的爬虫对自己的技能提升有限,对我来不值。
但是不写爬虫,就不能方便的获取数据,自己写代码又要花费很多时间,少则一两个小时,多则半天的时间,这就让人很矛盾。
有没有一种方法可以不写代码,分分钟就就可以实现网页的数据抓取呢?
我去搜了下,还真有,我从这里面选了一个我认为最好用的,那就是 Web Scraper,有了它,基本上可以应付学习工作中 90% 的数据爬取需求,相对于 Python 爬虫,虽然灵活度上受到了一定的限制,但是学习成本很低,我用半个小时就学会了基本用法,这种低成本高效率的解决问题的工具,对我来说就是好东西。
好东西就值得分享,本文介绍 Web Scraper 的安装和使用方法,优缺点等,让你 10 分钟就可以上手。
PS:阅读原文可以访问文中的链接。
安装
Web Scraper 是一个谷歌浏览器插件。访问官方网站 https://webscraper.io/,点击 “Install”
会自动跳转至 Chrome 的网上商店,点击 “Add to Chrome” 即可。
如果无法访问 Chrome 的网上商店,请访国内的插件网站进行安装,如下:
浏览器插件下载中心 https://www.chromefor.com/
173应用网 https://173app.com/chrome-ext
Chrome 网上应用店镜像 https://www.gugeapps.com/
再来个英文的下载网站 https://www.crx4chrome.com/
Crx离线安装包下载 http://yurl.sinaapp.com/crx.php
Chrome插件 http://chromecj.com/
ChromeFor浏览器插件 https://chrome-extension-downloader.com/
使用
孰能生巧,新手可能会有点难以理解,其实只需要记住一句话,网页的内容是一棵树,树根就是网站的 url,从网站的 url 到我们需要访问的数据所在的元素(html element)就是从树根到叶子节点的遍历的过程。这个过程有简单的,就是直接一条路就走到叶子节点,也有复杂的,采用递归的思想处理页面刷新情况。
这里,我只展示一些简单的,让你建立对 Web Scraper 的初步认识,复杂的的爬取请访问官方文档,阅读视频和文档来学习。
请牢记,网页的内容是一棵树,这样方便你理解工具的工作原理。Web Scraper 就是以树的形式来组织 sitemap 的,以爬取知乎的热榜数据为例,一步步展示使用该插件。
知乎热榜的页面如下图所示:
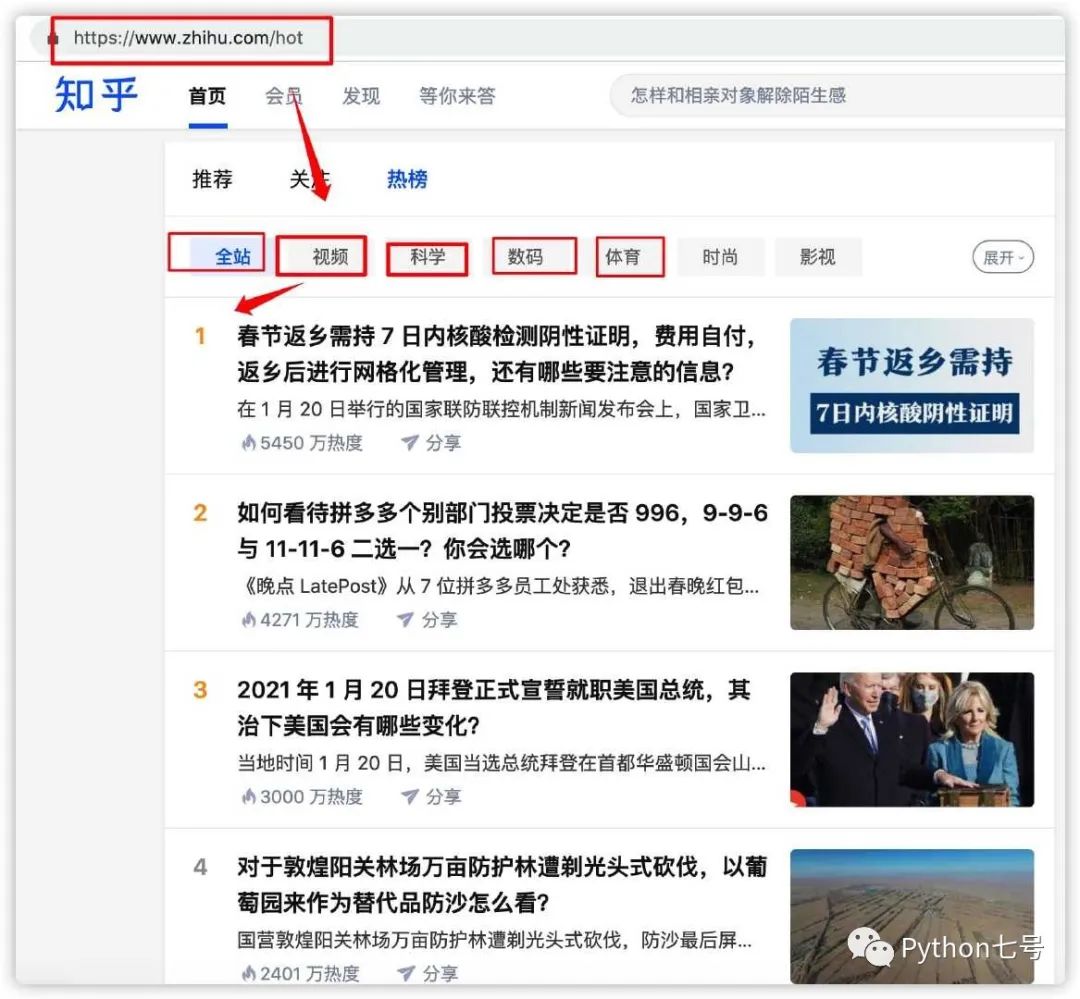
根就是页面的网址,即 https://www.zhihu.com/hot,现在给这个根起个名字,叫 zhihu_hot(名字任意起,便于识别即可),zhihu_hot 的子节点可以是视频、科学、数码、体育这些子节点。这些子节点下的子节点就是我们要抓取的内容列表。
现在开始使用 Web Scraper:
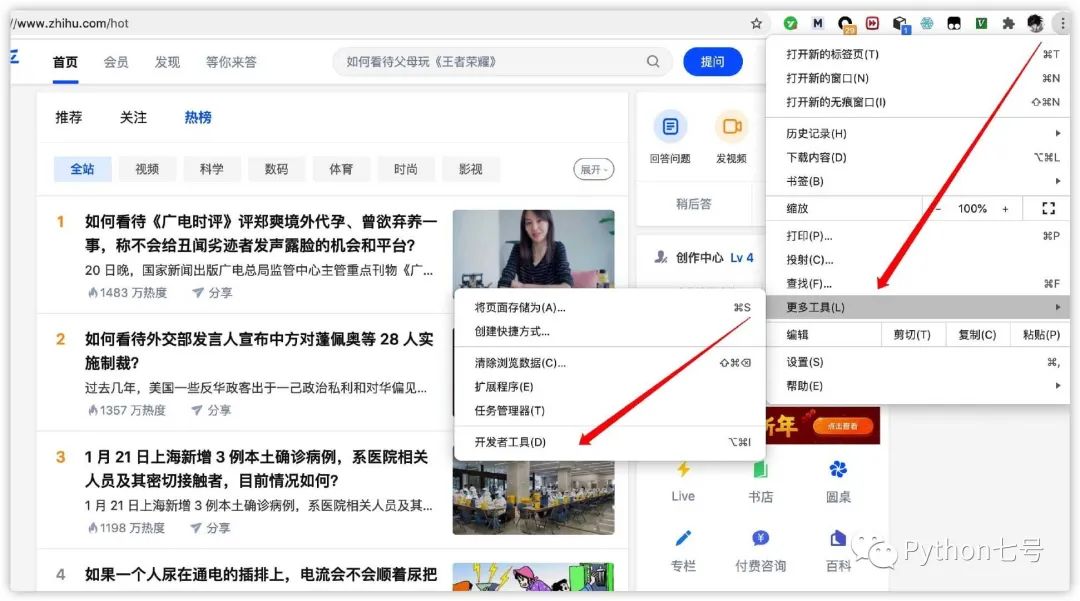
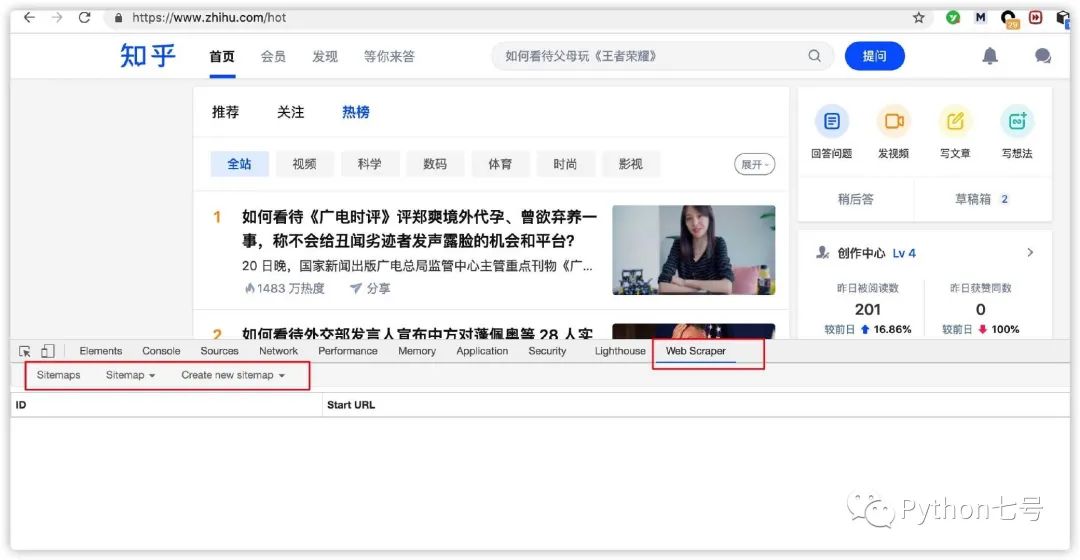
第一步,打开谷歌浏览器的开发者工具,单击最右边的 Web Scraper 菜单,如下图所示:
第二步,创建 sitemap 及 selector:
单击 Create new sitemap -> Create sitemap,在 Sitemap name 处输入 zhihu_hot,这里 zhihu_hot 可以随意其名称,方便自己识别即可,只能是英文,然后 Start Url 填写 https://www.zhihu.com/hot:然后单击 Create sitemap 按钮完成创建,如下图所示:
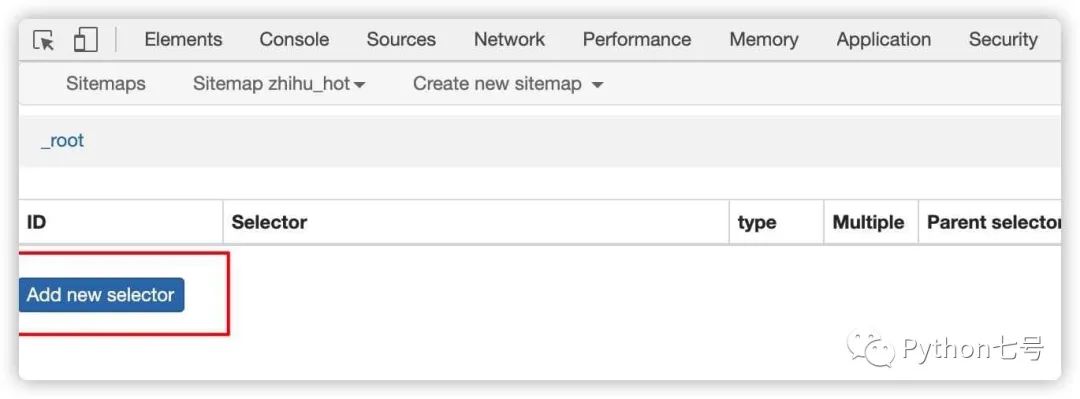
单击 Add new selector 添加 selector,也就是添加子节点:
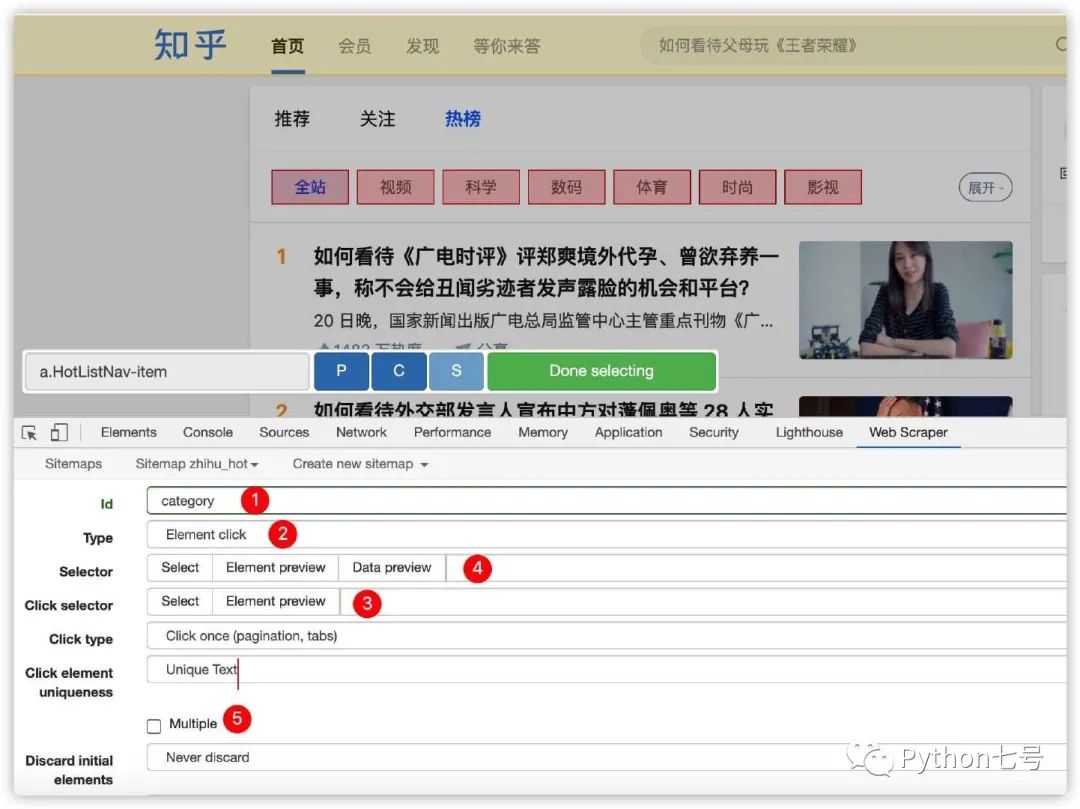
然后会弹出一个框让我们填写 selector 的相关信息,ID 这里填写 category,类型选择 Element Click,此时会出现两个选择器,一个是 selector,代表着要传递给 category 的子节点使用的元素,另一个是 Click selector,代表要点击的元素。为了方便你理解,请先选择 Click selector,在选择 selector,具体操作如下图所示:
Click selector 的选择:
selector 的选择:
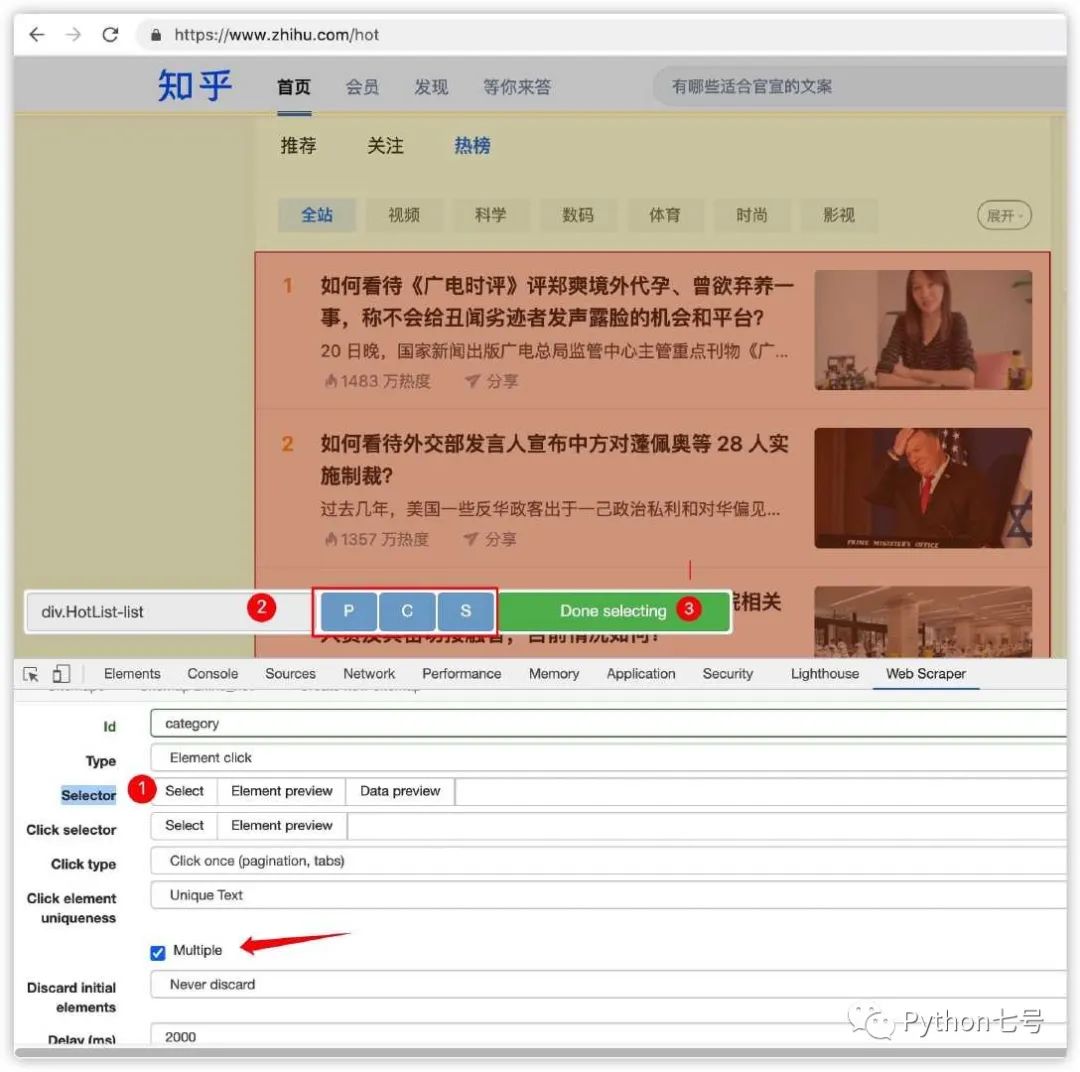
选择完成之后,勾选 Mutiple 表示爬取多个分类,点击 Save selector 保存。
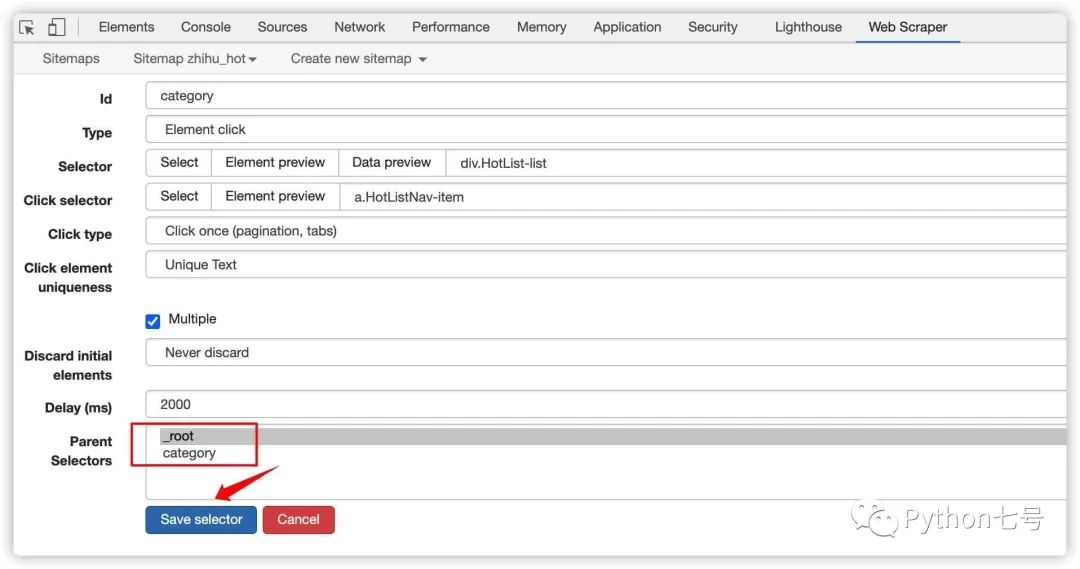
继续在 category 下添加 Selector,即 category_e, category_e 接受到的元素就是 category 中的 selector 选择的元素,即那个 div.HostList-list。category_e 的配置如下图所示:
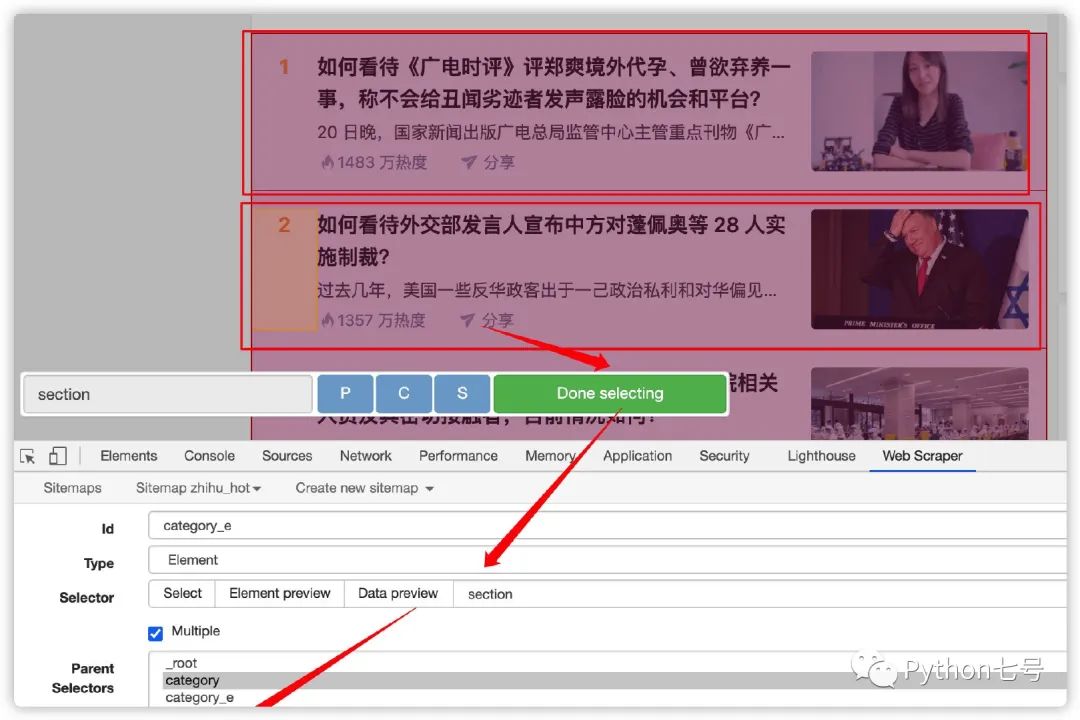
然后继续在 category_e 下面继续添加三个 Selector,即 hot_no、title、hot_degree,分别如下图所示:

保存之后,点击 Selector graph
可以看到如下图所示的树:
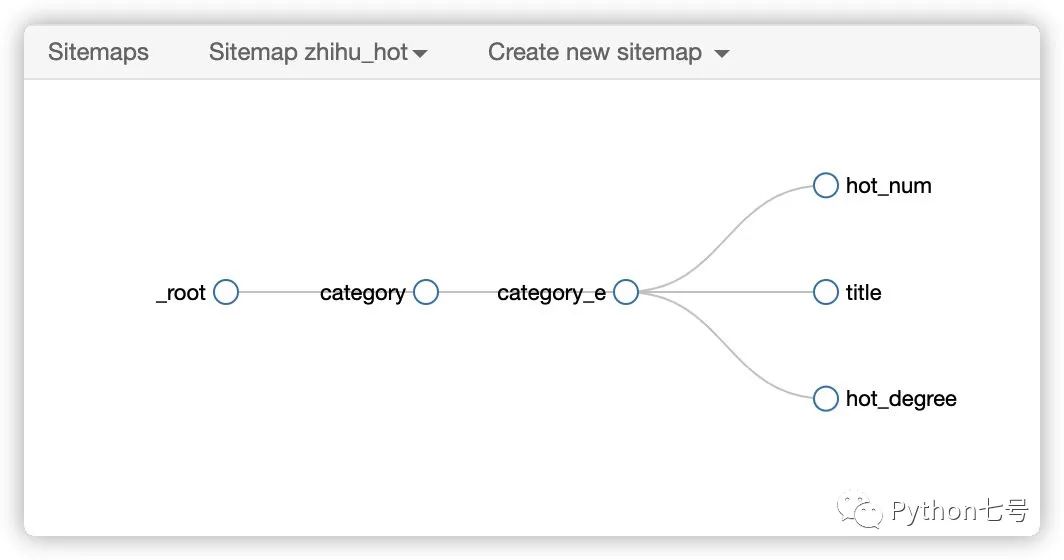
到这一步,我们的 sitemap 及其 selector 都创建完成。
第三步,运行 Web Scraper。
单击菜单中的 Scrape 按钮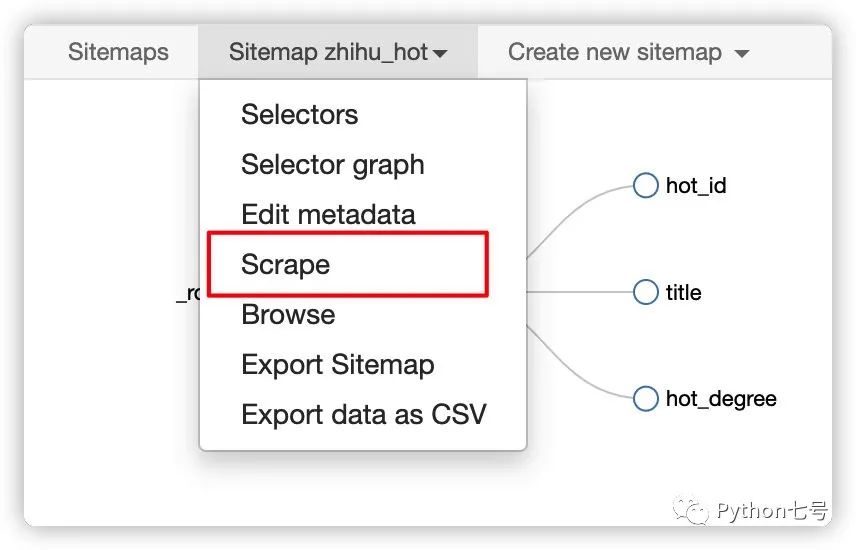
然后会让你设置爬取时的间隔,保持默认即可,如果网速比较慢可以适当延长:
点击 Start scraping 即可运行 Web Scraper,此时 Web Scraper 会打开一个新的浏览器窗口,执行按钮点击操作,并将数据保存在浏览器的 LocalStorage 中,运行结束后会自动关闭这个新窗口,点击下图中的 Refresh 按钮:
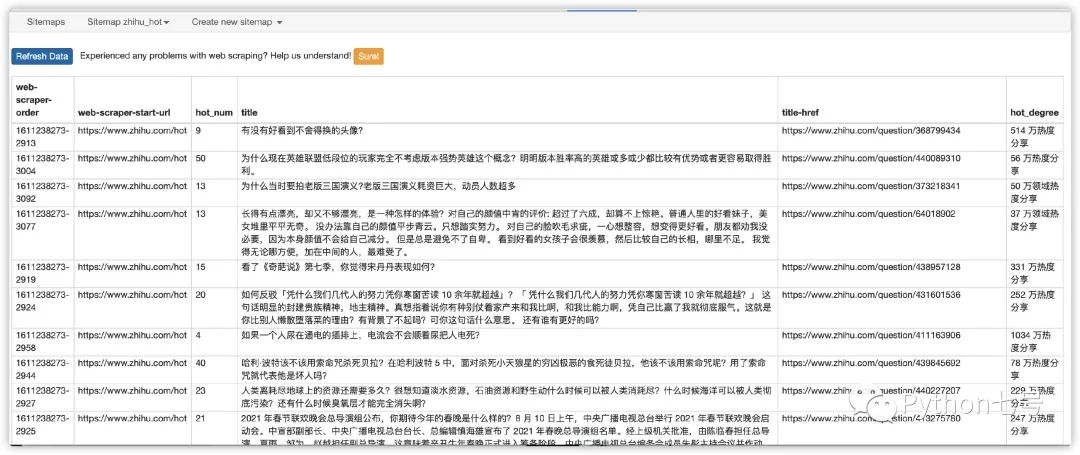
即可看到抓取的数据,如下图所示:
数据可以导出到 csv 文件,点击 Export data as CSV -> download now
即可下载得到 csv 文件:
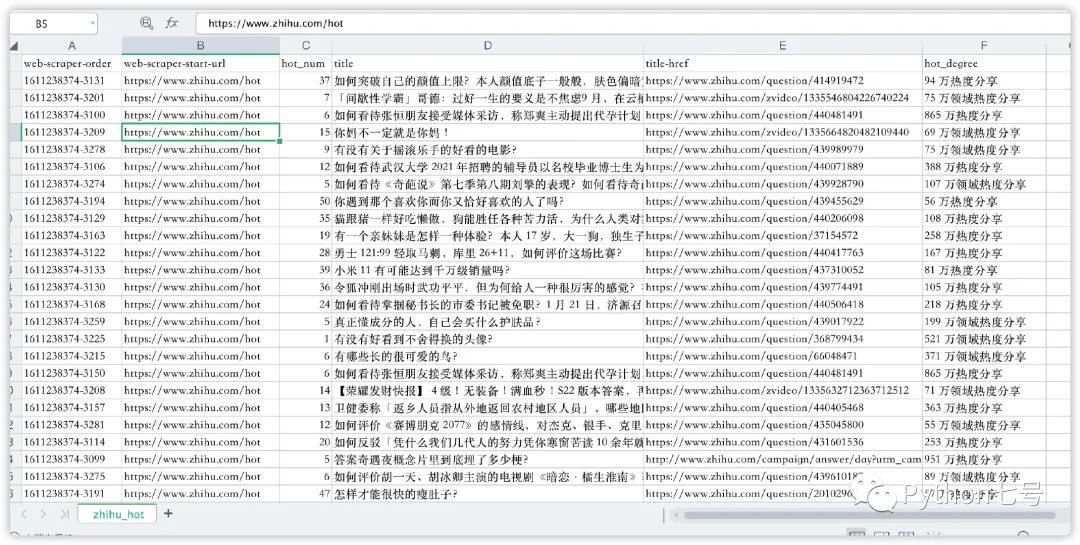
是不是非常方便?
如果你还是不能成功爬取上述数据,以下是我导出的 sitemap 信息,你可以复制这些文本导入 sitemap,再进行尝试,对比看看哪里不一样:
{"_id":"zhihu_hot","startUrl":["https://www.zhihu.com/hot"],"selectors":[{"id":"category","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.HotList-list","multiple":true,"delay":2000,"clickElementSelector":"a.HotListNav-item","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"category_e","type":"SelectorElement","parentSelectors":["category"],"selector":"section","multiple":true,"delay":0},{"id":"hot_num","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-rank","multiple":false,"regex":"","delay":0},{"id":"title","type":"SelectorLink","parentSelectors":["category_e"],"selector":".HotItem-content a","multiple":false,"delay":0},{"id":"hot_degree","type":"SelectorText","parentSelectors":["category_e"],"selector":"div.HotItem-metrics","multiple":false,"regex":"","delay":0}]}至于分页,或者无限加载,都是就可以轻松搞定的,本次案例中的分类按钮就相当于一类分页按钮,其他分页操作,官网都有对应的视频教程。
优缺点
优点:
Web Scraper 的优点就是不需要学习编程就可以爬取网页数据,对于非计算机专业的人可谓是爬虫不求人的利器。
即使是计算机专业的人,使用 Web Scraper 爬取一些网页的文本数据,也比自己写代码要高效,可以节省大量的编码及调试时间。
依赖环境相当简单,只需要谷歌浏览器和插件即可。
缺点:
只支持文本数据抓取,图片短视频等多媒体数据无法批量抓取。
不支持复杂网页抓取,比如说采取来反爬虫措施的,复杂的人机交互网页,Web Scraper 也无能为力,其实这种写代码爬取也挺难的。
导出的数据并不是按照爬取的顺序展示的,想排序就就要导出 Excel 再进行排序,这一点也很容易克服,大部分数据都是要导出 Excel 再进行数据分析的。
最后的话
掌握了 Web Scraper 的基本使用之后,就可以应付学习工作中 90% 的数据爬取需求,遇到一些稍微复杂的页面,可以多去看看官方网站的教程。
虽然只支持文本数据的抓取,基本上也够用了。如果是复杂网站的数据抓取,即使写代码也挺难爬取的,因此能快速解决手头的问题,提升工作效率,就是好工具,Web Scraper 就是这样的工具,是非常值得去学习的。
有问题?欢迎留言讨论。