
数据分析中最常用的pandas21模块操作
点击上方蓝色字体关注我们
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。
下面对pandas常用的功能进行一个可视化的介绍,希望能让大家更容易理解和学习pandas。
1、Series序列
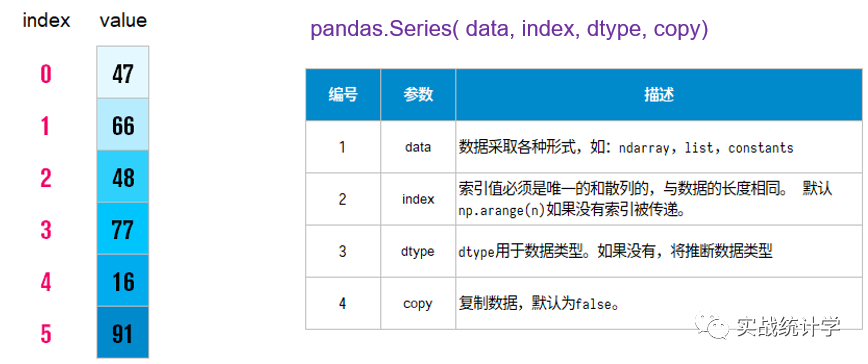
2、从ndarray创建一个系列
如果数据是ndarray,则传递的索引必须具有相同的长度。如果没有传递索引值,那么默认的索引将是范围(n),其中n是数组长度,即[0,1,2,3…. range(len(array))-1] - 1]。

3、从字典创建一个系列

4、序列数据的访问
通过各种方式访问Series数据,系列中的数据可以使用类似于访问numpy中的ndarray中的数据来访问。
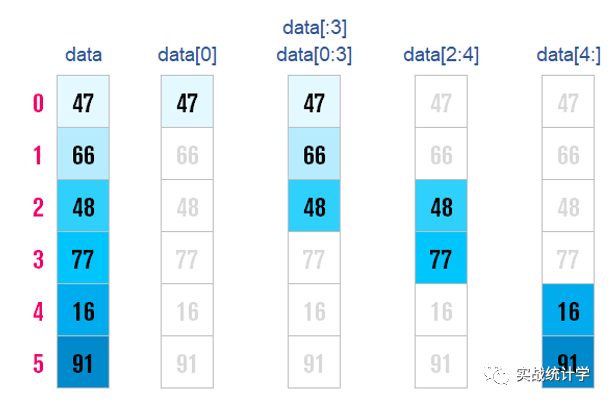
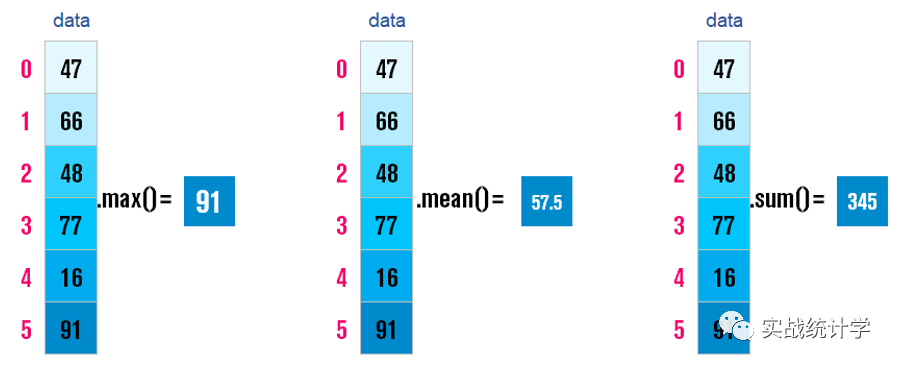
5、序列的聚合统计
Series有很多的聚会函数,可以方便的统计最大值、求和、平均值等
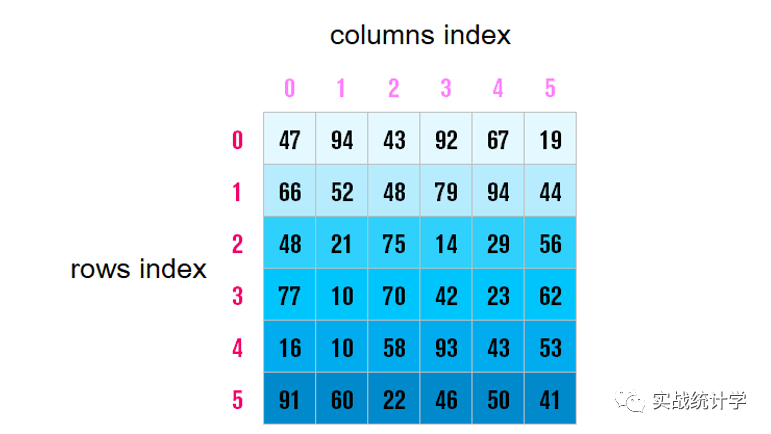
6、DataFrame(数据帧)
DataFrame是带有标签的二维数据结构,列的类型可能不同。你可以把它想象成一个电子表格或SQL表,或者 Series 对象的字典。它一般是最常用的pandas对象。

7、从列表创建DataFrame
从列表中很方便的创建一个DataFrame,默认行列索引从0开始。

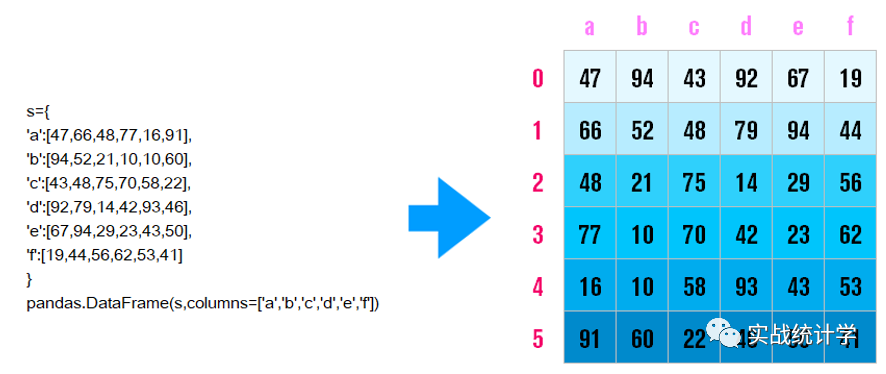
8、从字典创建DataFrame
从字典创建DataFrame,自动按照字典进行列索引,行索引从0开始。
9、列选择
在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下整理常用的列选择。

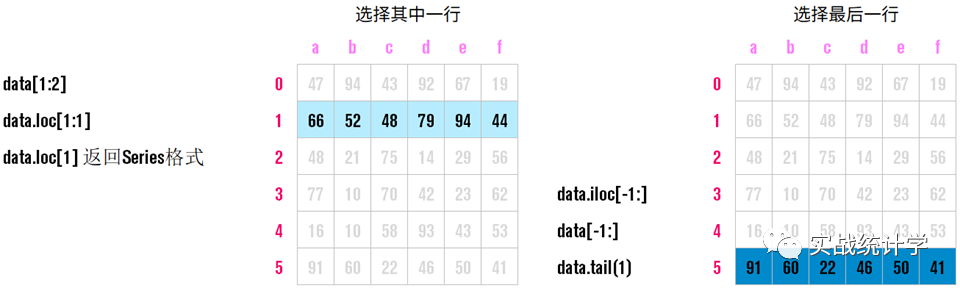
10、行选择
整理多种行选择的方法,总有一种适合你的。
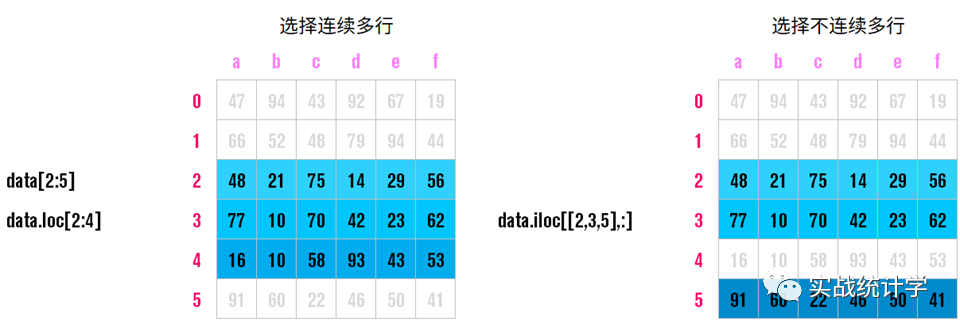

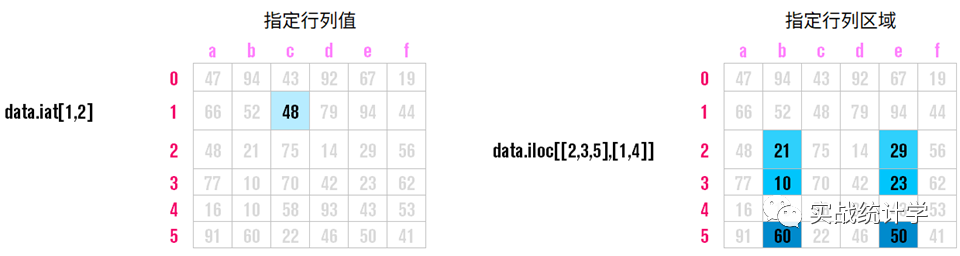
11、返回指定行列
pandas的DataFrame非常方便的提取数据框内的数据。
12、条件查询
对各类数值型、文本型,单条件和多条件进行行选择
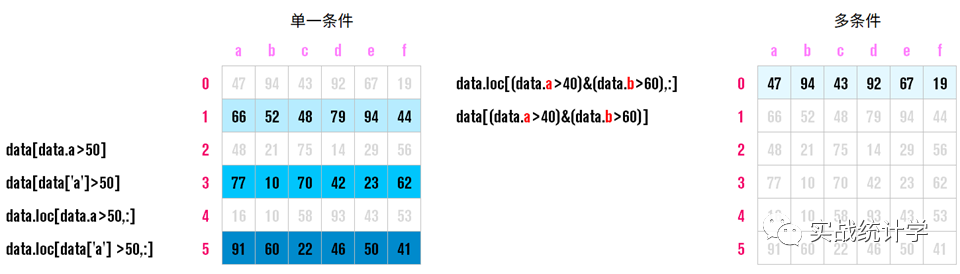

13、聚合
可以按行、列进行聚合,也可以用pandas内置的describe对数据进行操作简单而又全面的数据聚合分析。
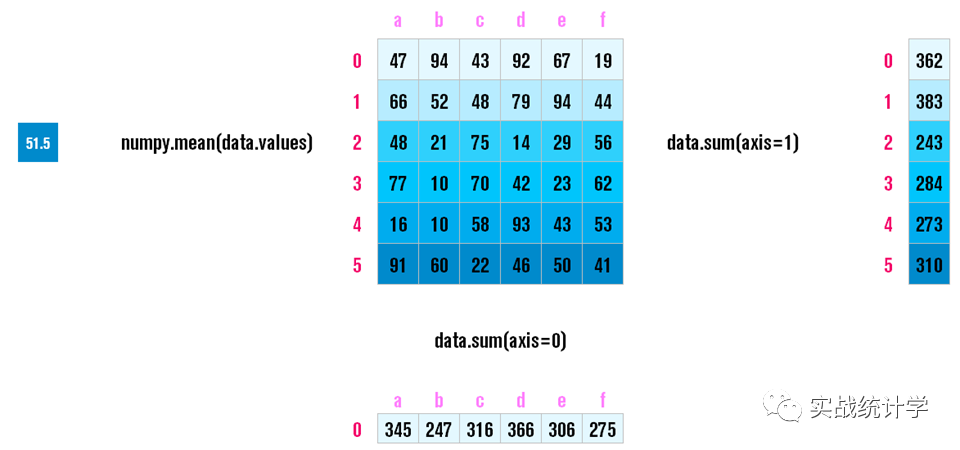
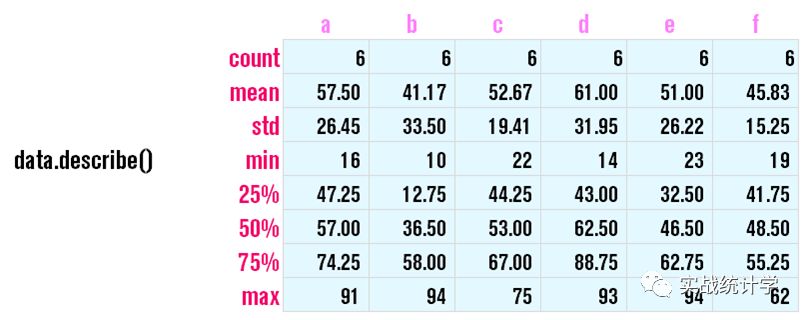
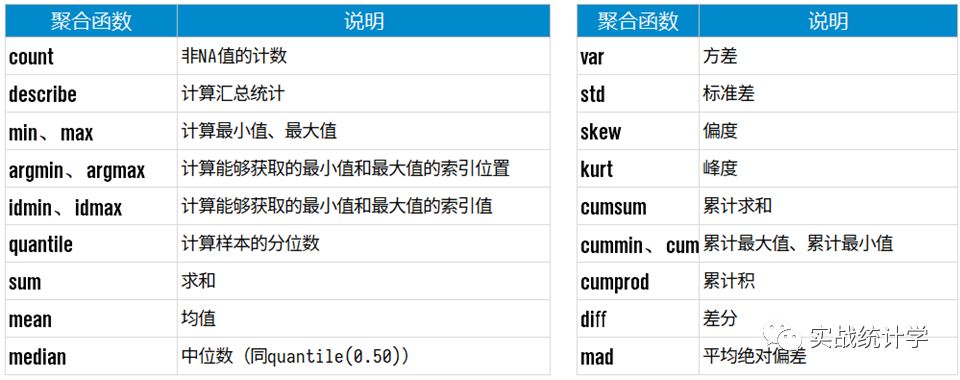
14、聚合函数
data.function(axis=0) 按列计算
data.function(axis=1) 按行计算
15、分类汇总
可以按照指定的多列进行指定的多个运算进行汇总。

16、透视表
透视表是pandas的一个强大的操作,大量的参数完全能满足你个性化的需求。

17、处理缺失值
pandas对缺失值有多种处理办法,满足各类需求。

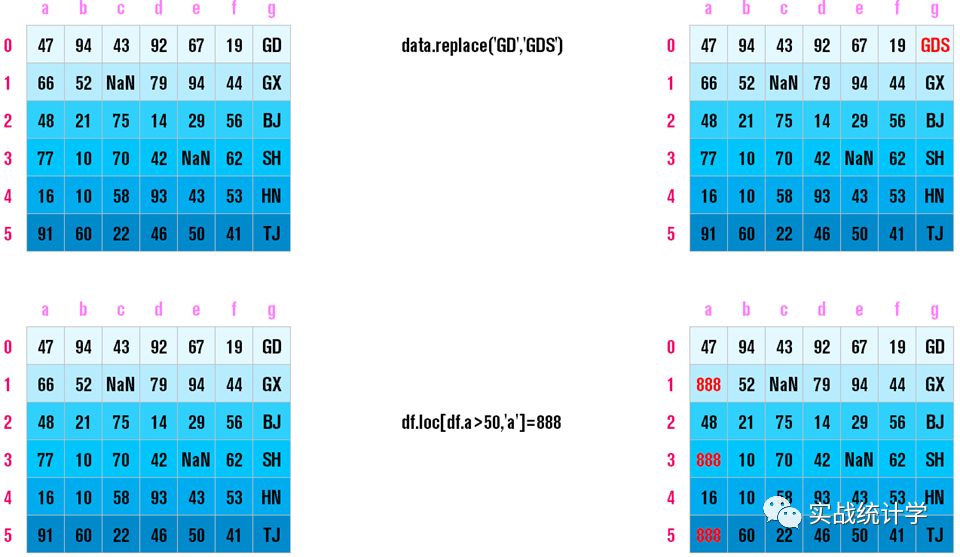
18、查找替换
pandas提供简单的查找替换功能,如果要复杂的查找替换,可以使用map(), apply()和applymap()
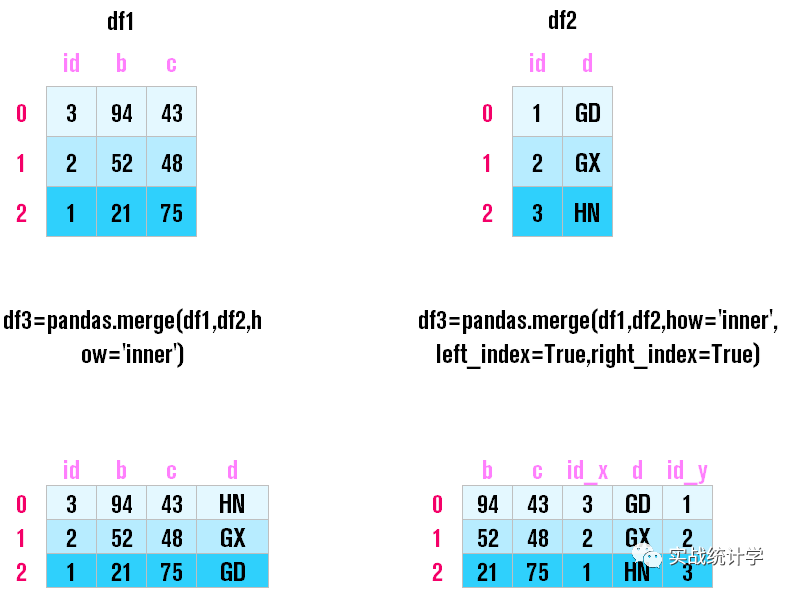
19、数据合并
两个DataFrame的合并,pandas会自动按照索引对齐,可以指定两个DataFrame的对齐方式,如内连接外连接等,也可以指定对齐的索引列。
20、更改列名(columns index)
更改列名我认为pandas并不是很方便,但我也没有想到一个好的方案。

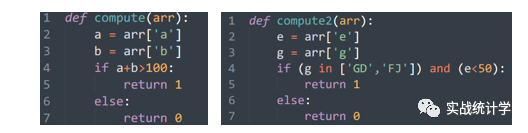
21、apply函数
这是pandas的一个强大的函数,可以针对每一个记录进行单值运算而不需要像其他语言一样循环处理。

整理这个pandas可视化资料不易,
如果你觉得本文对其他人有帮助,
请分享给你的朋友,或点个在看,感谢感谢。
扫描下方二维码关注我们,
你的关注是我写作的动力,
下次再整理更多的pandas可视化教程。