
一个数据爬取和分析系统的演变过程
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

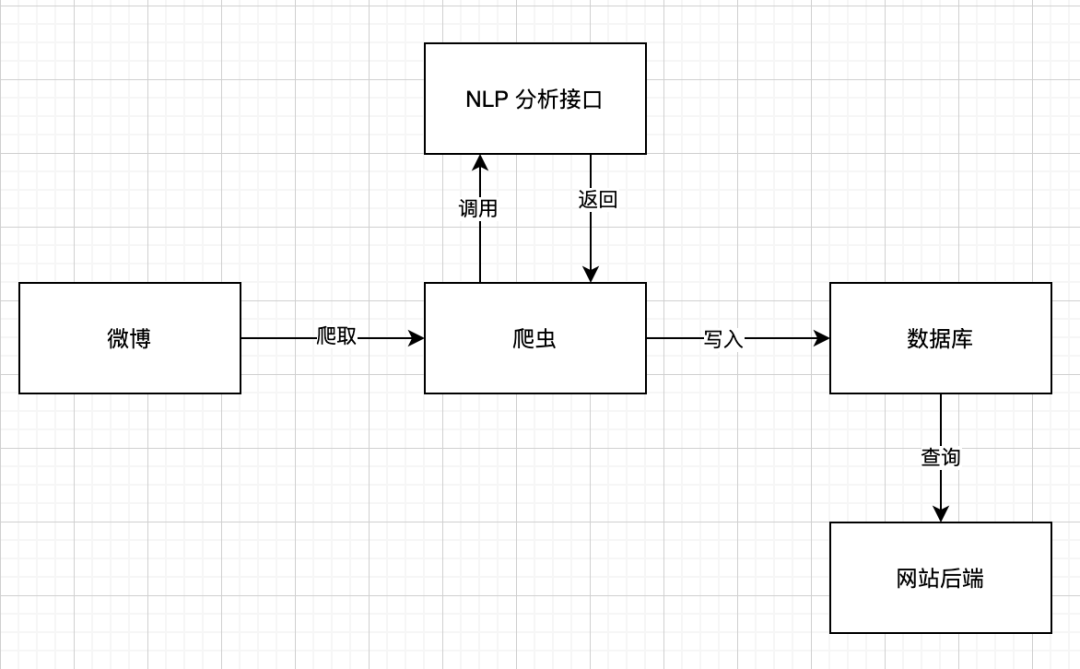
假设有这样一个需求,需要你写一个爬虫,爬取微博中关于某个话题的讨论,然后分析情感,最后用一个网页来展示分析结果。那么你一开始的数据流程可能是这样的:
后来,老板发现只有微博一个源不够,于是又给你加了100000个源。现在你的系统是这样的:
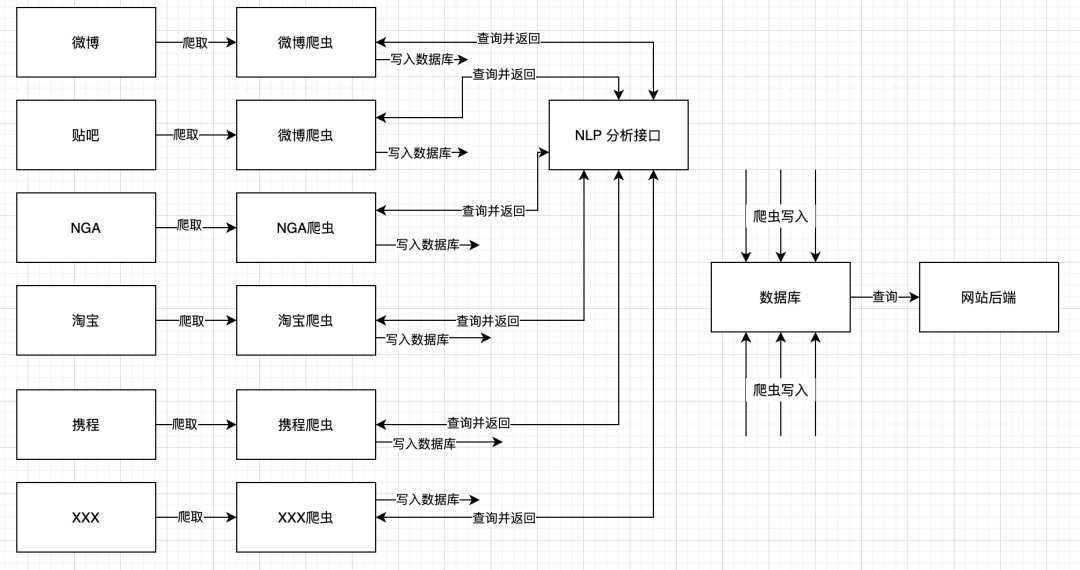
为了防止太多的线做交叉,我做了一些处理。
一开始你调用 NLP 分析接口的时候,传入的参数只有爬取内容的正文,但有一天,NLP 研究员希望做一个情感衰减分析。于是你要修改每一个爬虫,让每一个爬虫在调用 NLP 分析接口的时候,都带上时间参数。这花了你几天的时间。
你一想,这不行啊,岂不是每次增加修改字段,都要改每一个爬虫?为了避免动到爬虫,于是你对系统架构做了一些修改:
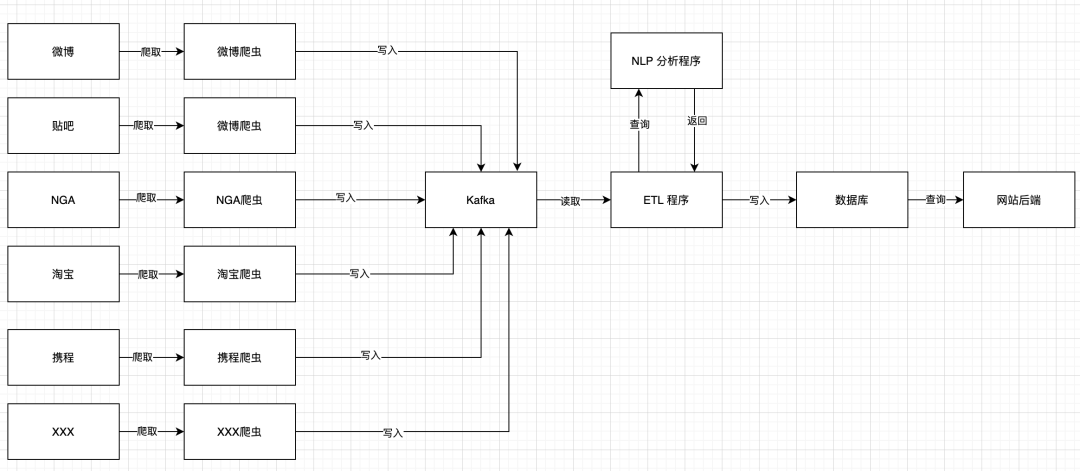
现在,爬虫这边总是会把它能爬到的全部数据都写进 Kafka 里面。你的 ETL 程序只挑选需要的字段传给 NLP 接口进行分析,分析完成以后,写入数据库中。程序的处理线条变得清晰了。
你以为这样就完了?还早呢。
有一天,你发现网页上的数据很久没有更新了。说明数据在某个地方停了。现在,你首先去 Kafka 检查爬虫的数据,发现爬虫数据是正常入库的。那么,说明问题出现在下图这一块:
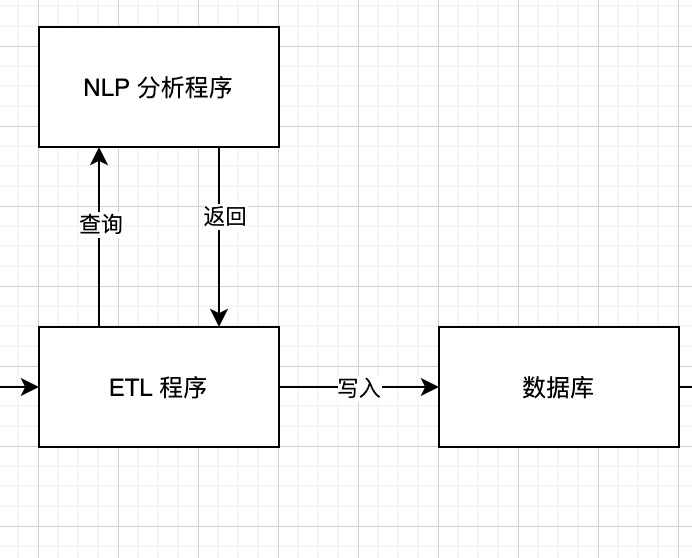
那么,请问是 ETL 在处理数据的时候出现问题导致数据丢失了,还是 NLP 接口出了问题,导致你传给他的数据没有返回?还是数据库不堪重负,写入数据库的时候出错了?
你现在根本不知道哪里出了问题。于是互相甩锅。
为了避免这个问题,你再一次修改了系统架构:
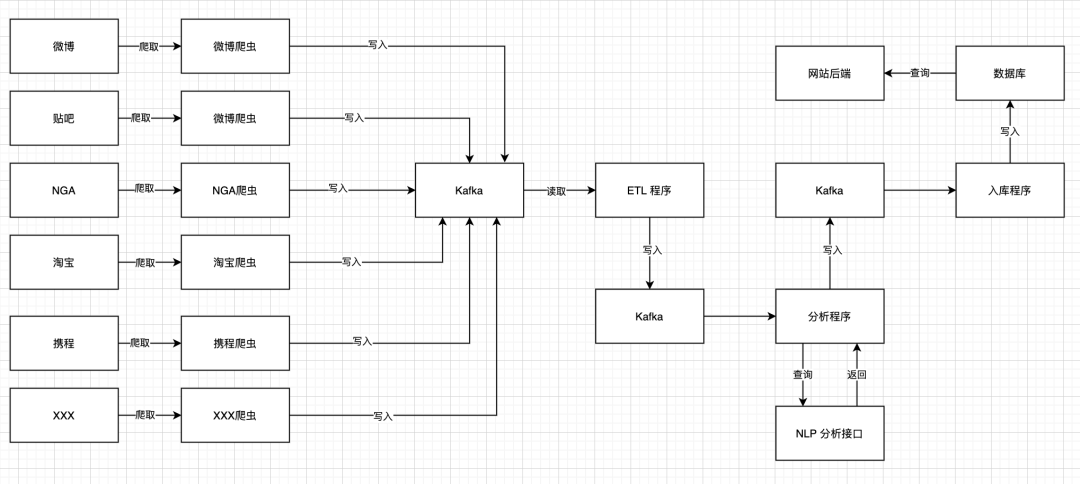
现在通过检查 Kafka 的数据,我可以知道 ETL 程序是否正常输出内容。也可以知道 NLP 分析程序是否正常返回数据。我还可以对比两边的数据变化率进行监控。甚至还可以通过监控 Kafka,发现负面内容太多时,及时报警。
当然,这还没有完,如果还需要发现新的链接,并自动抓取,那么又需要增加新的节点。又或者有一些内容需要用浏览器渲染,又要增加新的节点……
大家可以看到,数据会反复进出 Kafka,那么它的效率显然会比直接用爬虫串联万物的写法慢。但我认为这样的效率损失是值得的。因为通过把系统拆解成不同的小块,我们可以对系统运行的每一个阶段进行监控,从而能够更好地了解系统的运行状态。并且,每一个小块也能够更方便地进行维护,无论是修 bug 还是增加新功能,都能减小对其他部分的影响,并且可以提高修复的速度。
<Data Pipeline For All learner>
<更多好文推荐>