3行代码完成时序建模,最新开源的时序算法发布!
Datawhale开源
方向:时间序列开源项目
时序是什么?时序预测可以为业务带来哪些价值? 产品销量预测、电池剩余寿命预测……这些高价值场景如何提高预测准确率? 深度学习模型在时序预测有什么优势? 如何寻得一款集前沿高尖时序技术的产品,为业务所用? 近日,百度飞桨重磅发布了一款 开源时序建模算法库——PaddleTS ,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,具有更优的使用体验:- 超易用 :3行代码即可完成时序建模
- 速度快 :模型训练效率比同类产品快2倍
- 效果好 :时序专属的自动建模与集成预测效果突出
-
零售企业 :准确的预测产品销量,可以为企业备货、配送、运营策略的制定提供有效依据,显著降本增效;
- 电网公司 :准确的预测发电量与用电量,可以使电网的调度更加合理化,发挥最大效能;
- 制造企业 :提前预测生产设备可能发生的故障,可以提前预警、维修,降低停工造成的损失;
- 新能源车企 :实时预测电池剩余电量、预测剩余寿命,可以更经济、更合理的使用车辆;
- 金融领域 :利率、股票、现金流、外汇等走势预测都对经济产生重大影响。
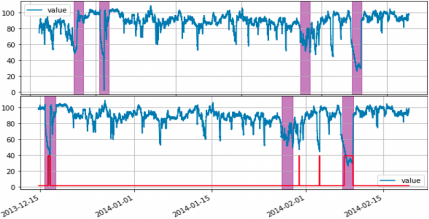 工业设备异常检测
经典的机器学习算法应用到时间序列预测中,其优势在于模型使用灵活、训练简单,但也存在明显的缺点,需要大量的人工工作在特征工程上。近年来,深度学习逐步在语音、视觉、自然语言理解等领域得到广泛应用,其算法的优势明显。首先,它可以自动捕捉关键特征,不需要依赖统计学知识,不需要复杂的特征工程;其次,它在建模流程与准确率上有着机器学习不可比拟的优势;此外,它还具备很多功能优势,如使用灵活、表达力强、兼容多样性等。
既然深度学习这么优秀,怎么为时序场景业务所用呢?
PaddleTS提供了一系列先进的基于深度学习技术的时序建模算法及相关组件
,它功能丰富、简单易用、效果领先,包括能源、交通、制造等多个行业客户早已应用起来,还不快来试试~~
工业设备异常检测
经典的机器学习算法应用到时间序列预测中,其优势在于模型使用灵活、训练简单,但也存在明显的缺点,需要大量的人工工作在特征工程上。近年来,深度学习逐步在语音、视觉、自然语言理解等领域得到广泛应用,其算法的优势明显。首先,它可以自动捕捉关键特征,不需要依赖统计学知识,不需要复杂的特征工程;其次,它在建模流程与准确率上有着机器学习不可比拟的优势;此外,它还具备很多功能优势,如使用灵活、表达力强、兼容多样性等。
既然深度学习这么优秀,怎么为时序场景业务所用呢?
PaddleTS提供了一系列先进的基于深度学习技术的时序建模算法及相关组件
,它功能丰富、简单易用、效果领先,包括能源、交通、制造等多个行业客户早已应用起来,还不快来试试~~

- GitHub传送门
https://github.com/PaddlePaddle/PaddleTS
PaddleTS相关技术交流群
1. 微信扫描下方二维码,关注公众号,填写问卷后进入微信群
2. 查看 群公告 领取福利

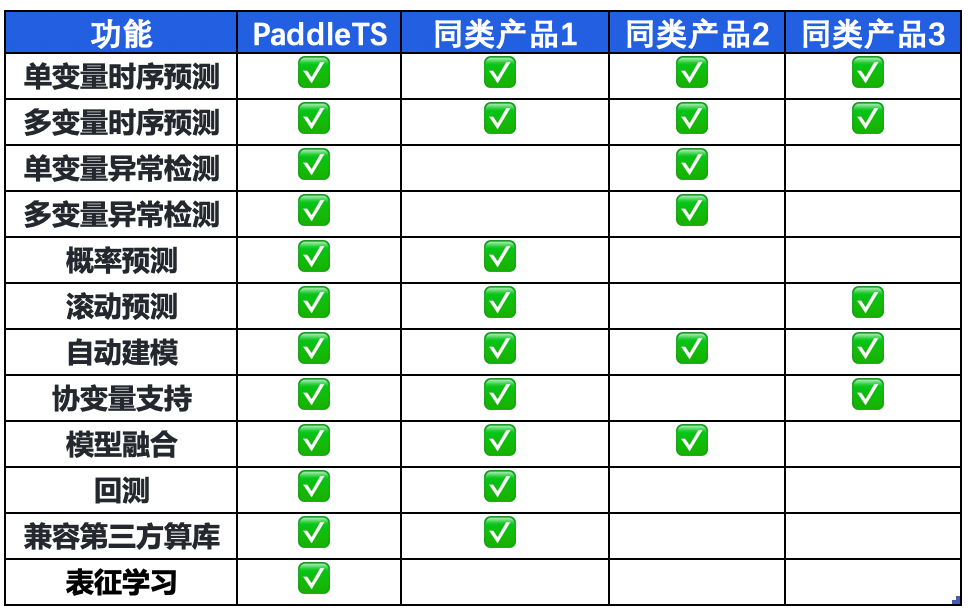
功能全面丰富
PaddleTS覆盖 时序预测 和 时序异常检测 两大核心应用场景,针对建模全流程,提供了丰富的功能。既支持单变量也支持多变量的时序分析,同时还具备模型融合、自动建模及丰富的建模工具组件。PaddleTS无论是在功能丰富度上,还是在集成的时序算法数量上,都超过了市面上典型的开源时序产品。除了基础能力以外,产品还有以下特色功能:
-
全面的数据类型支持 :PaddleTS提供的 协变量支持 功能,支持历史观测协变量、未来可知协变量、静态协变量和分类变量等各种协变量数据类型,帮助开发者有效利用各种数据充分发挥数据的价值。
- 主流新颖的深度模型 :PaddleTS集成了 Transformer、TCN、 VAE、TS2Vec 、 N-beats 等丰富的深度学习模型,可以很好的捕捉复杂时序场景中的多变量动态依赖关系,解决长周期、多变量、小样本等问题,取得更好的模型效果。
- 丰富的分析建模工具集 :PaddleTS内置了 时序特征处理、数据分析、回测、滚动预测、自动建模、模型融合 等分析建模过程中非常实用的功能,可以帮助开发者减少编码数量,提升开发效率。
简单易用、快速上手
不需要深刻的专业背景和复杂的特征工程
3行代码实现时序建模
PaddleTS覆盖了大部分主流深度学习模型,开发者只需将数据按照格式要求灌入数据集,再通过简单的归一化处理即可进行模型训练预测。相较于传统统计模型对开发者统计知识的要求,机器学习模型在训练前复杂的特征工程,开发者使用PaddleTS构建深度学习模型更加快速、简单。- 时序建模代码示例
dataset = TSDataset.load_from_dataframe(df, **kwargs)
mlp = MLPRegressor(in_chunk_len = 7 * 24, out_chunk_len = 24)
mlp.fit(dataset)
兼容第三方库,机器学习模型也能高效利用
P addleTS默认集成了sklearn、pyod等第三方库,解决了传统机器学习方法不能直接用于时序数据,且建模过程复杂等问题。 开发者通过几行代码即可实现传统机器学习的调用,搭配PaddleTS中丰富的建模全流程工具,充分满足个性化需求。-
时序预测代码示例
ts_forecasting_model = make_ml_model(sklearn.linear_model.LinearRegression, in_chunk_len=16, out_chunk_len=1)
ts_forecasting_model.fit(tsdataset)
res = ts_forecasting_model.predict(tsdataset)
- 时序异常检测代码示例
ts_anomaly_model = make_ml_model(pyod.models.knn.KNN, in_chunk_len=16)
ts_anomaly_model.fit(tsdataset)
res = ts_anomaly_model.predict(tsdataset)
时序专属的自动建模与集成预测器
策略更优、操作更简单
PaddleTS将传统的自动建模和集成学习工具进行改良优化,针对时序场景重新设计了更加便捷的建模工具。 自动建模AutoTS :在该模块中内置了默认搜索空间、超参优化算法、重采样策略与参数评估策略,开发者仅需 2行代码 即可完成自动建模的主体训练流程定义。-
AutoTS功能代码示例
autots_model = AutoTS(MLPRegressor, 96, 24)
autots_model.fit(tsdataset)
集成预测器Ensemble
:该模块采用集成学习的思想,提供两种集成预测器,开发者通过简单的操作即可把多个PaddleTS预测器集合成一个,满足多数场景下的集成需求。
-
Ensemble功能代码示例
ensemble_model = StackingEnsembleForecaster(96,24,estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
ensemble_model.fit(ts_train, ts_val)
速度快、效果优
PaddleTS基于飞桨框架,对数据加载、模型训练、模型预测等核心环节精心打磨优化,效率相比同类开源产品有非常大的优势。
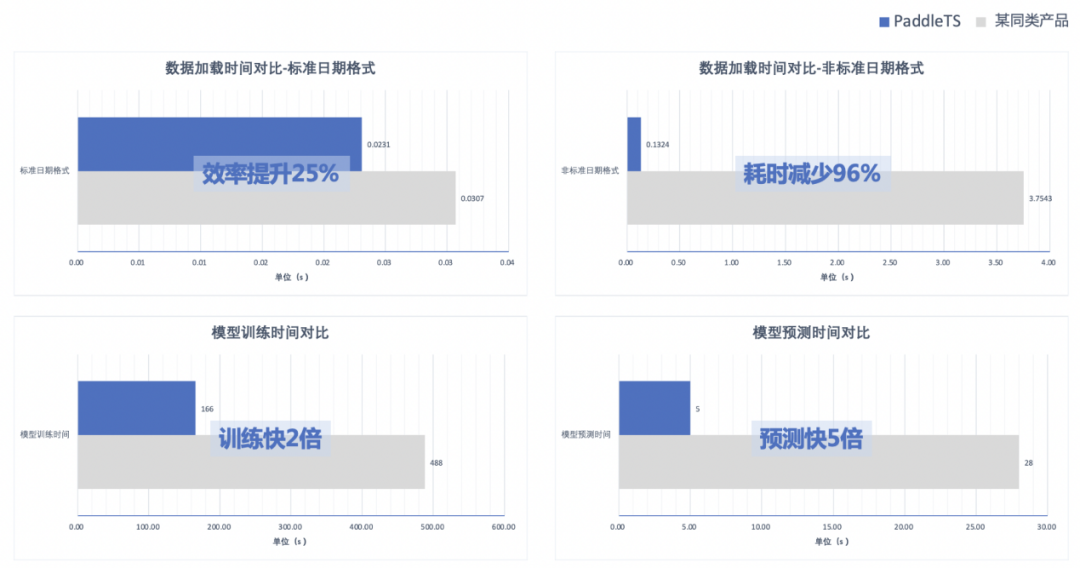 训练环境:GPU CUDA 11.2,设备 NVIDIA A30
指标说明:MAE,即绝对平均误差,它表示预测值和观测值之间绝对误差的平均值,越小则预测效果越好
此外,相较于同类产品,使用PaddleTS中的AutoTS自动建模工具可以取得更优的建模效果,在大多数情况下优于专家经验调参。
训练环境:GPU CUDA 11.2,设备 NVIDIA A30
指标说明:MAE,即绝对平均误差,它表示预测值和观测值之间绝对误差的平均值,越小则预测效果越好
此外,相较于同类产品,使用PaddleTS中的AutoTS自动建模工具可以取得更优的建模效果,在大多数情况下优于专家经验调参。
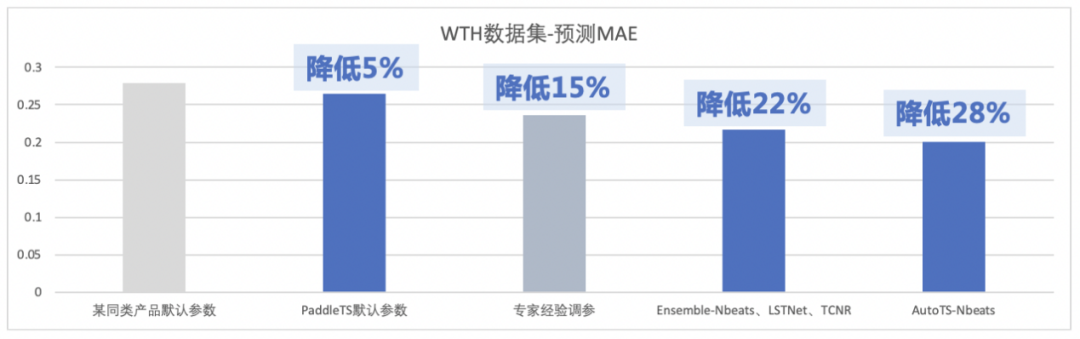
WTH数据集:包含2010年至2013年4年间近1600个美国地区的当地气候数据
*利用默认的TPE算法,运行50次参数试验PaddleTS直播课预告
11月8日(周二)19:00 ,百度资深工程师将为大家深度解析 时序建模算法库PaddleTS ,欢迎大家 扫描海报二维码 报名直播课,与各位开发者进行技术和业务深度交流!

更多精彩直播推荐