
4 种数据库缓存最终一致性的优缺点对比?最终选择方案四!

阅读本文大概需要 4 分钟。
来自:叶不闻 jjuejin.im/post/5d5c99b66fb9a06ae072060d
背景
缓存是什么
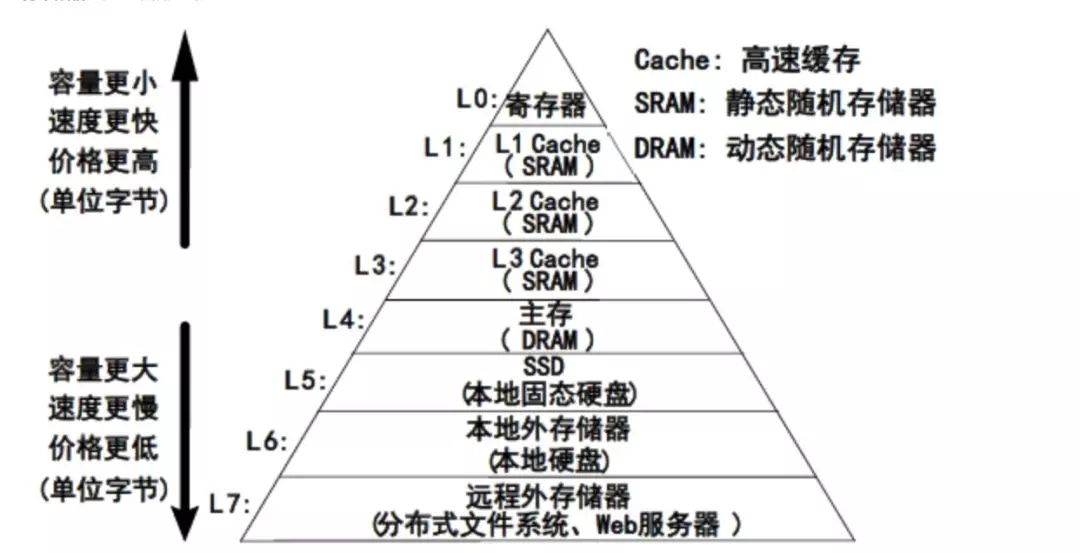
为什么需要缓存
存在问题
redis作为mysql缓存
解决方案
方案一
开发成本低,易于实现; 管理成本低,出问题的概率会比较小。
完全依赖过期时间,时间太短容易缓存频繁失效,太长容易有长时间更新延迟(不一致)
方案二
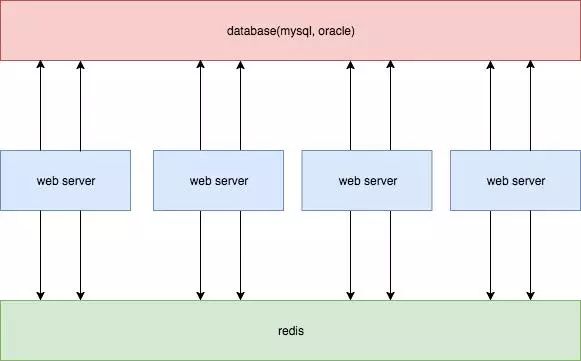
相对方案一,更新延迟更小。
如果更新mysql成功,更新redis却失败,就退化到了方案一; 在高并发场景,业务server需要和mysql,redis同时进行连接。这样是损耗双倍的连接资源,容易造成连接数过多的问题。
方案三
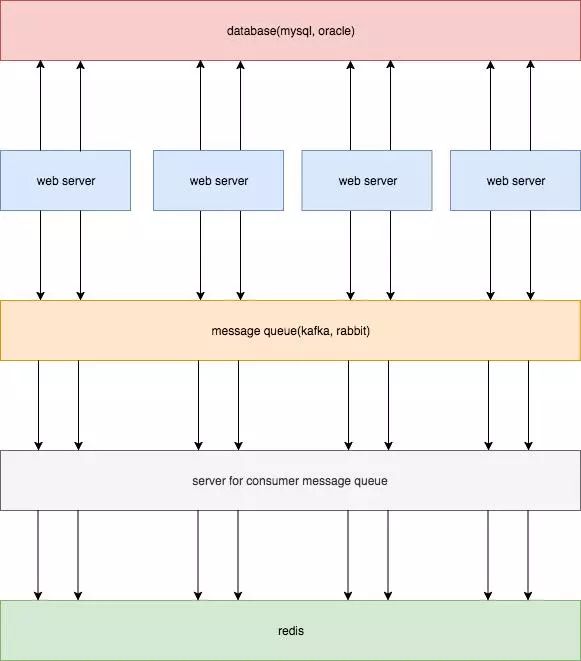
消息队列可以用一个句柄,很多消息队列客户端还支持本地缓存发送,有效解决了方案二连接数过多的问题; 使用消息队列,实现了逻辑上的解耦; 消息队列本身具有可靠性,通过手动提交等手段,可以至少一次消费到redis。
依旧解决不了时序性问题,如果多台业务服务器分别处理针对同一行数据的两条请求,举个栗子,a = 1;a = 5;,如果mysql中是第一条先执行,而进入kafka的顺序是第二条先执行,那么数据就会产生不一致。 引入了消息队列,同时要增加服务消费消息,成本较高。
方案四
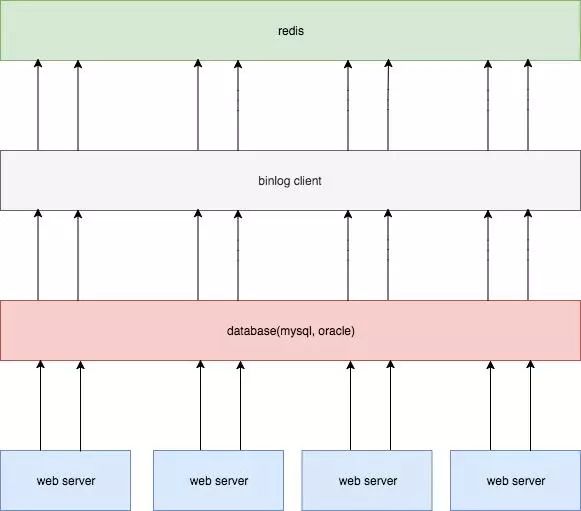
在mysql压力不大情况下,延迟较低; 和业务完全解耦; 解决了时序性问题。
要单独搭建一个同步服务,并且引入binlog同步机制,成本较大。
总结
方案选型
首先确认产品上对延迟性的要求,如果要求极高,且数据有可能变化,别用缓存。 通常来说,方案1就够了,笔者咨询过4,5个团队,基本都是用方案1,因为能用缓存方案,通常是读多写少场景,同时业务上对延迟具有一定的包容性。方案1没有开发成本,其实比较实用。 如果想增加更新时的即时性,就选择方案2,不过没必要做重试保证之类的。 方案3,方案4针对于对延时要求比较高业务,一个是推模式,一个是拉模式,而方案4具备更强的可靠性,既然都愿意花功夫做处理消息的逻辑,不如一步到位,用方案4。
结论
推荐阅读:
套娃成功!在《我的世界》里运行Win95、玩游戏,软件和教程现已公开
SpringBoot+Gradle+ MyBatisPlus3.x搭建企业级的后台分离框架
微信扫描二维码,关注我的公众号
朕已阅 
评论