
全链路压测体系建设方案的思考与实践
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
全链路压测的意义
ALIWARE


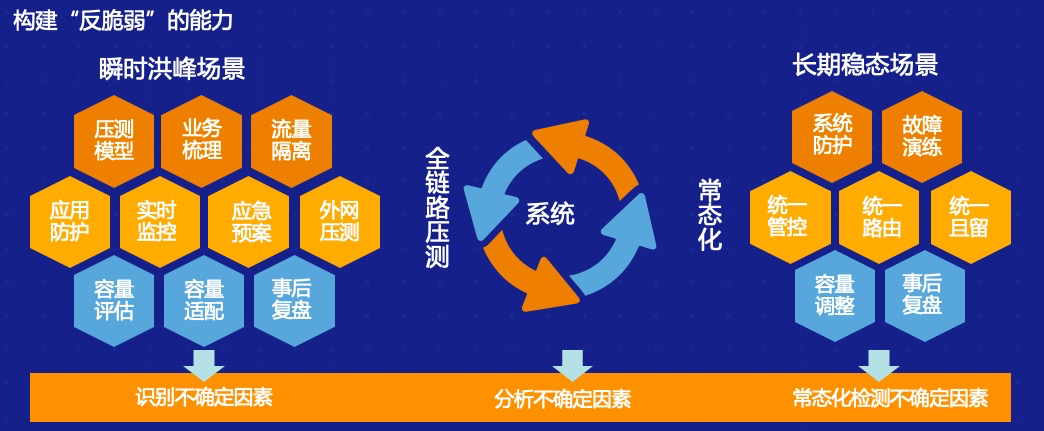
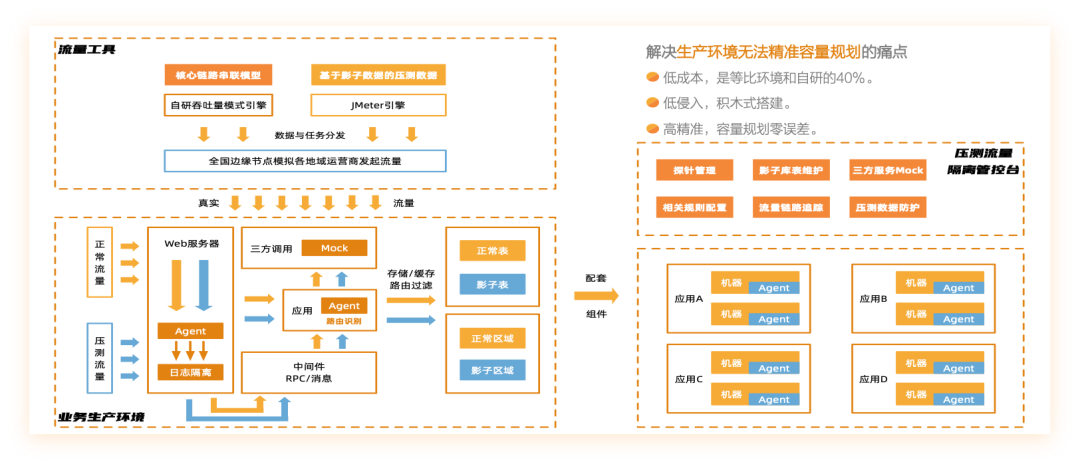
全链路压测解决方案
ALIWARE
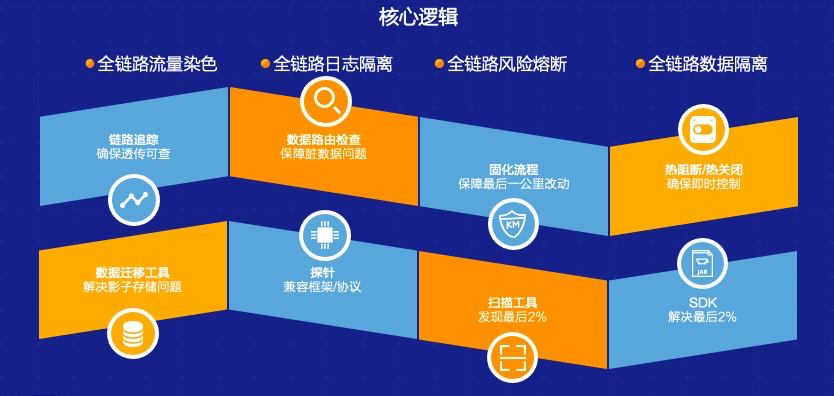
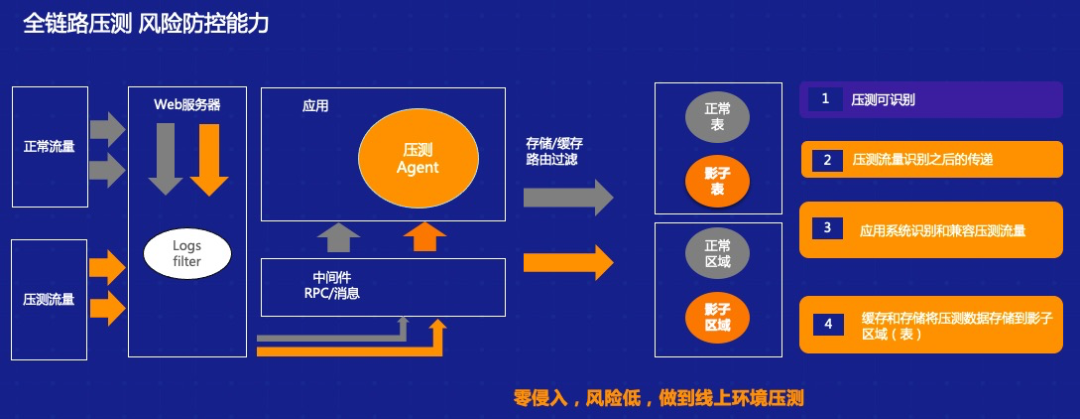
对于整个全链路压测来说,我们需要几个关键的技术:
全链路流量染色
可能通过在压缩机上做一些标识,比如加一个后缀,或者通过一些标识手段把流量读出来,分散到相关的表里去。同时在全链路流量展示过程中我们还需要做流量的识别,对于压测流量经过的每一个中间件,每一个服务我们都希望能够准确的识别出来,这个流量是来自于压测机还是来自于正常流量,这是第一步。
全链路的数据隔离
我们需要通过哪些手段,比如通过影子库,通过运维的同学做一个和生产上面同样的影子库,然后切到影子库上,或者在生产库上做一个相同的影子表,来做数据隔离。第一种方式安全度高一些,但是缺点在于我们用影子库的时候整个生产环境是不可用的。生产影子库不能完全模拟出整个线上的情况,因为影子表需要我们有更高的技术水平,能够保障整个链路可追踪,包括整个数据如果一旦出错数据恢复能力等等。
全链路风险管控机制
全链路日志日志隔离
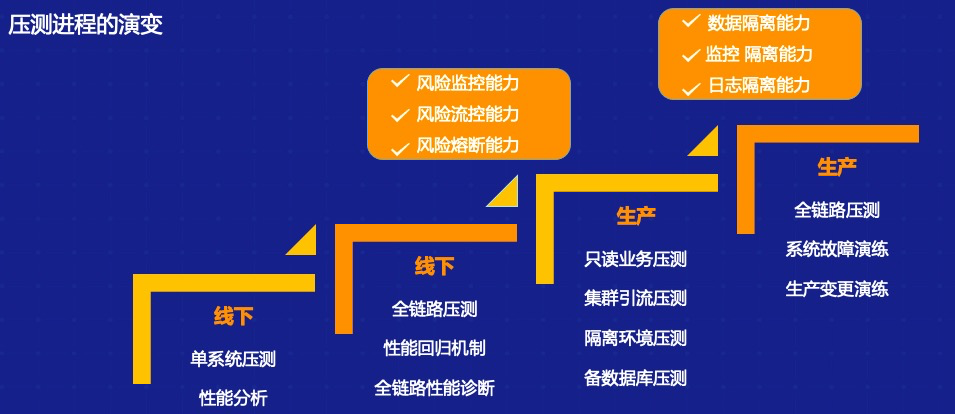
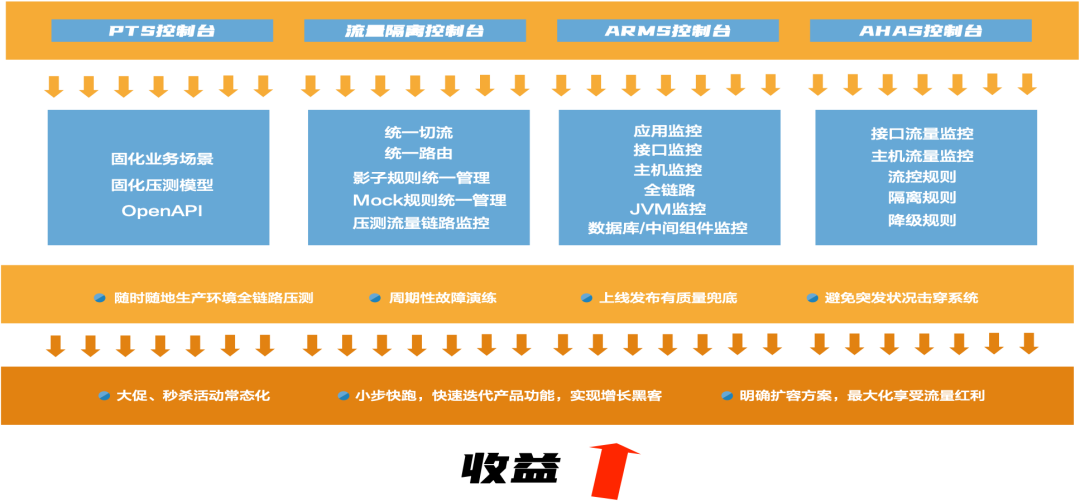
压测流程的建议
ALIWARE
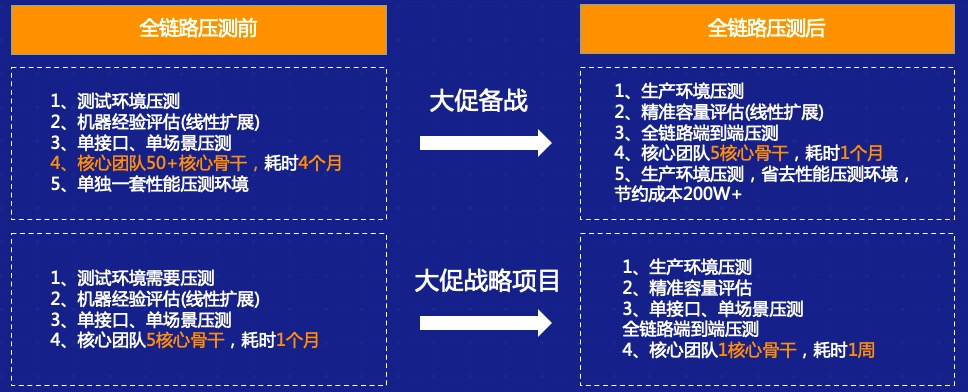
客户案例
ALIWARE
案例一
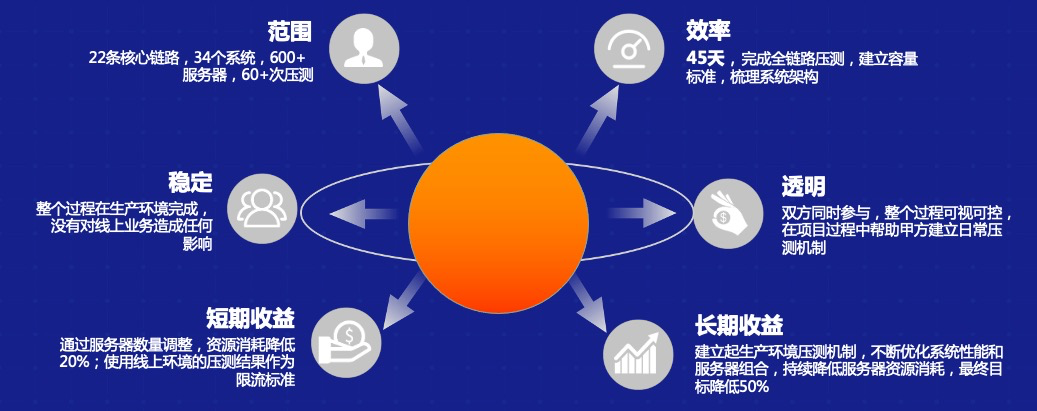
案例二
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈

评论