云原生背景下如何配置 JVM 内存

前段时间业务研发反馈说是他的应用内存使用率很高,导致频繁的重启,让我排查下是怎么回事;
在这之前我也没怎么在意过这个问题,正好这次排查分析的过程做一个记录。
首先我查看了监控面板里的 Pod 监控:
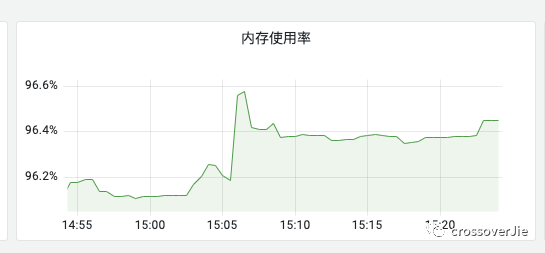
发现确实是快满了,而此时去查看应用的 JVM 占用情况却只有30%左右;说明并不是应用内存满了导致 JVM 的 OOM,而是 Pod 的内存满了,导致 Pod 的内存溢出,从而被 k8s 杀掉了。
而 k8s 为了维持应用的副本数量就得重启一个 Pod,所以看起来就是应用运行一段时间后就被重启。
在解决这个问题之前还是先简单了解下容器的运行原理,因为在 k8s 中所有的应用都是运行在容器中的,而容器本质上也是运行在宿主机上的一个个经常而已。
但我们使用 Docker 的时候会感觉每个容器启动的应用之间互不干扰,从文件系统、网络、CPU、内存这些都能完全隔离开来,就像两个运行在不同的服务器中的应用。
其实这一点也不是啥黑科技,Linux 早就支持 2.6.x 的版本就已经支持 namespace 隔离了,使用 namespace 可以将两个进程完全隔离。
仅仅将资源隔离还不够,还需要限制对资源的使用,比如 CPU、内存、磁盘、带宽这些也得做限制;这点也可以使用 cgroups 进行配置。
它可以限制某个进程的资源,比如宿主机是 4 核 CPU,8G 内存,为了保护其他容器,必须给这个容器配置使用上限:1核 CPU,2G内存。
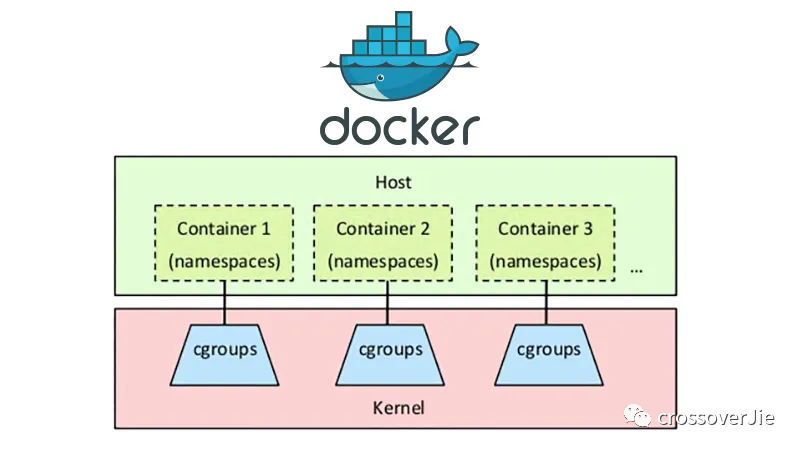
这张图就很清晰的表示了 namespace 和 cgroups 在容器技术中的作用,简单来说就是:
- namespace 负责隔离
- cgroups 负责限制
在 k8s 中也有对应的提现:
resources:
requests:
memory: 1024Mi
cpu: 0.1
limits:
memory: 1024Mi
cpu: 4
这个资源清单表示该应用至少需要为一个容器分配一个 0.1 核和 1024M 的资源,CPU 的最高上限为 4 个核心。
不同的OOM回到本次的问题,可以确认是容器发生了 OOM 从而导致被 k8s 重启,这也是我们配置 limits 的作用。
k8s 内存溢出导致容器退出会出现 exit code 137 的一个 event 日志。
因为该应用的 JVM 内存配置和容器的配置大小是一样的,都是8GB,但 Java 应用还有一些非 JVM 管理的内存,比如堆外内存之类的,这样很容易就导致容器内存大小超过了限制的 8G 了,也就导致了容器内存溢出。
云原生背景的优化因为这个应用本身使用的内存不多,所以建议将堆内存限制到 4GB,这样就避免了容器内存超限,从而解决了问题。
当然之后我们也会在应用配置栏里加上建议:推荐 JVM 的配置小于容器限制的 2/3,预留一些内存。
其实本质上还是开发模式没有转变过来,以传统的 Java 应用开发模式甚至都不会去了解容器的内存大小,因为以前大家的应用都是部署在一个内存较大的虚拟机上,所以感知不到容器内存的限制。
从而误以为将两者画了等号,这一点可能在 Java 应用中尤为明显,毕竟多了一个 JVM;甚至在老版本的 JDK 中如果没有设置堆内存大小,无法感知到容器的内存限制,从而自动生成的 Xmx 大于了容器的内存大小,以致于 OOM。
从源码彻底理解 Prometheus/VictoriaMetrics 中的 relabel/metric_configs 配置


一个诡异的 Pulsar InterruptedException 异常