
生产实践|腾讯欧拉平台数据血缘架构
导读 本文将介绍腾讯欧拉数据血缘的建设及应用。
主要内容包括以下几个部分:1. 背景和目标
2. 项目架构
3. 模块化建设
4. 应用场景
5. 问答环节
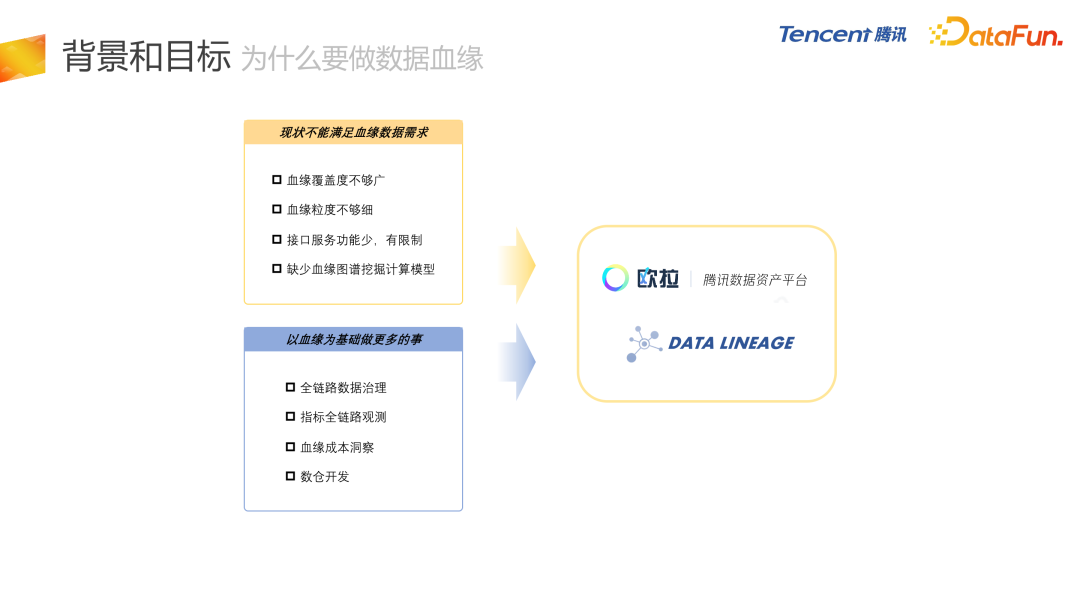
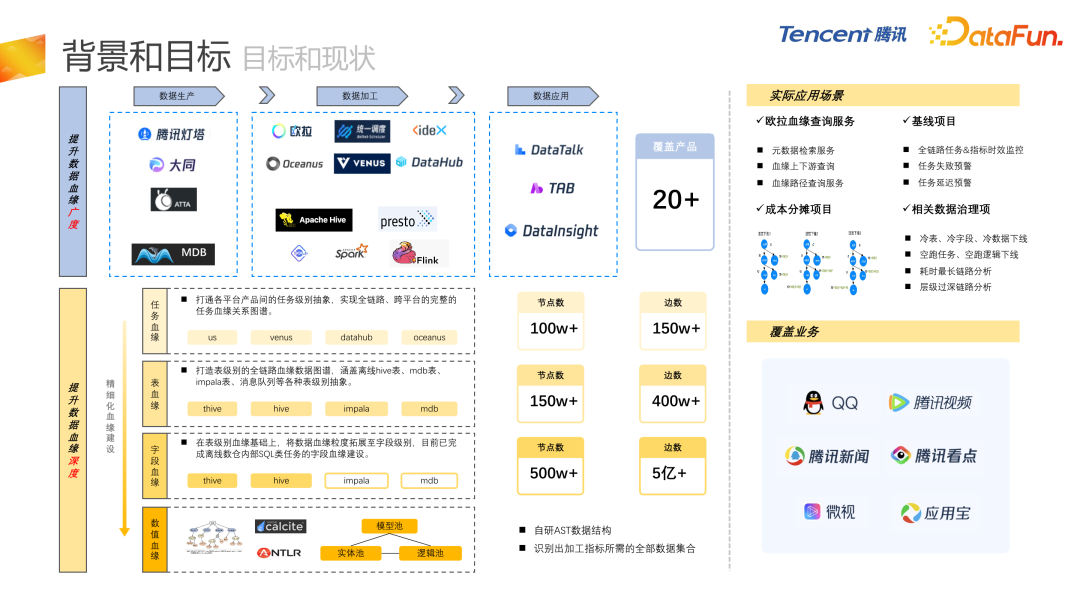
01 背景和目标

- 首先是资产工厂,负责整体的数仓建设、数仓模型的开发;
- 第二块是欧拉的治理引擎,负责全链路成本的数据治理;
- 第三块是数据发现,负责元数据的管理。
项目架构
接下来介绍欧拉数据血缘项目架构。 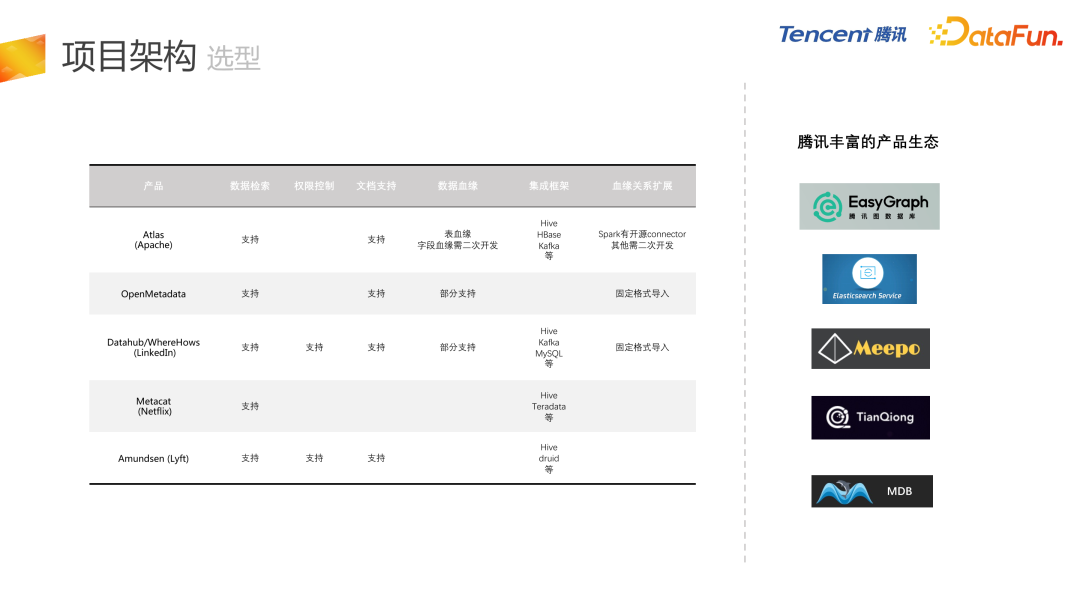
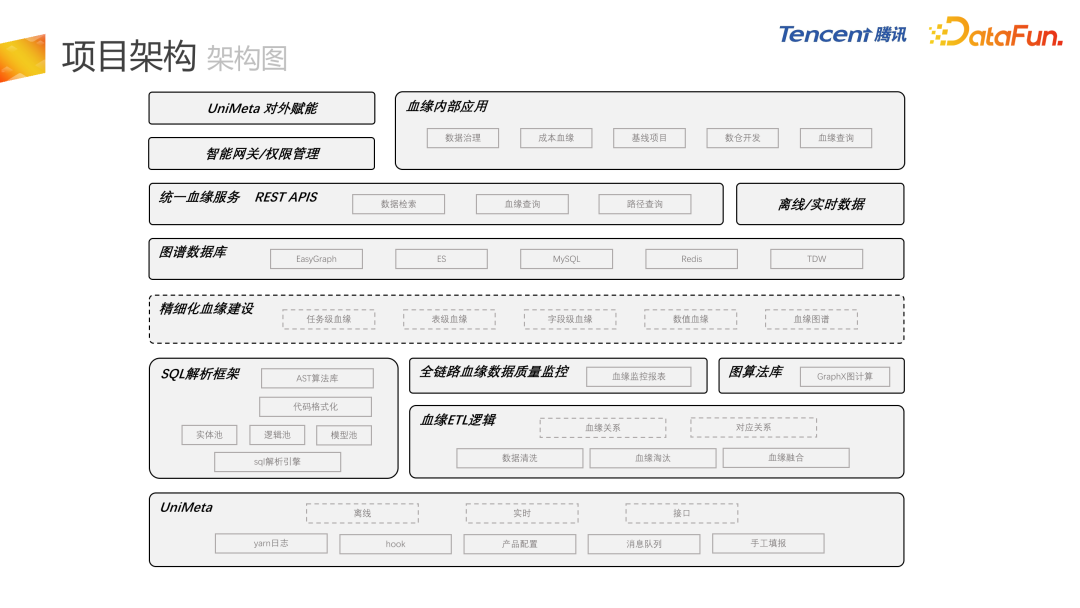
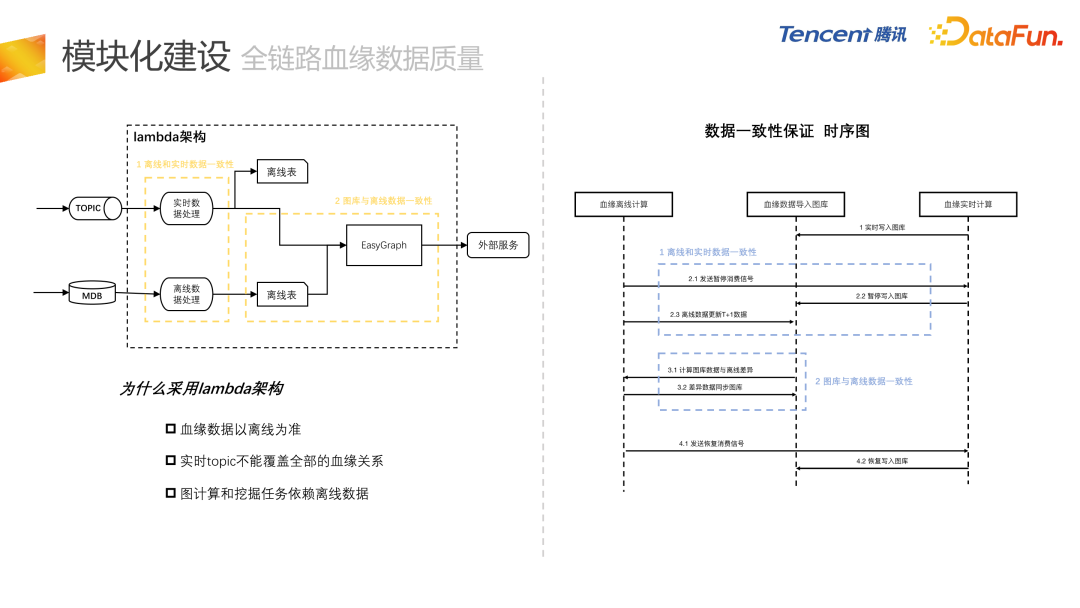
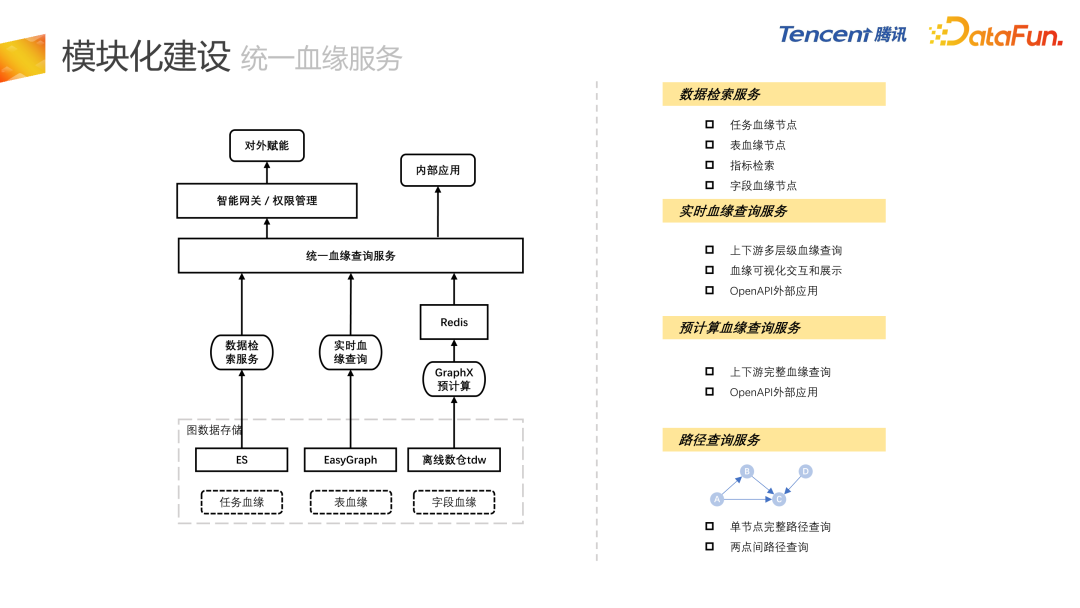
模块化建设
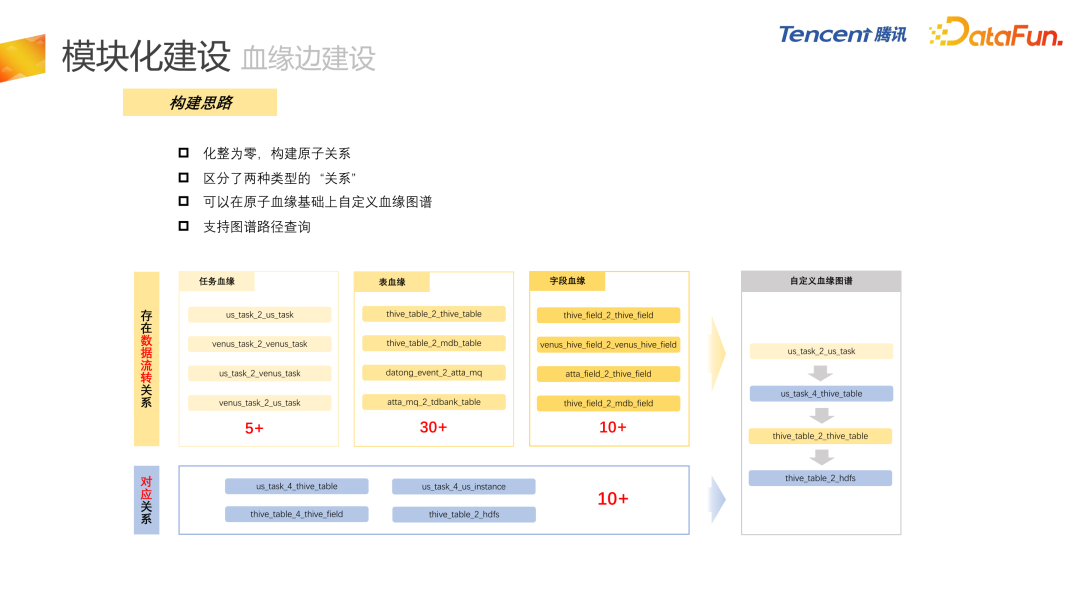
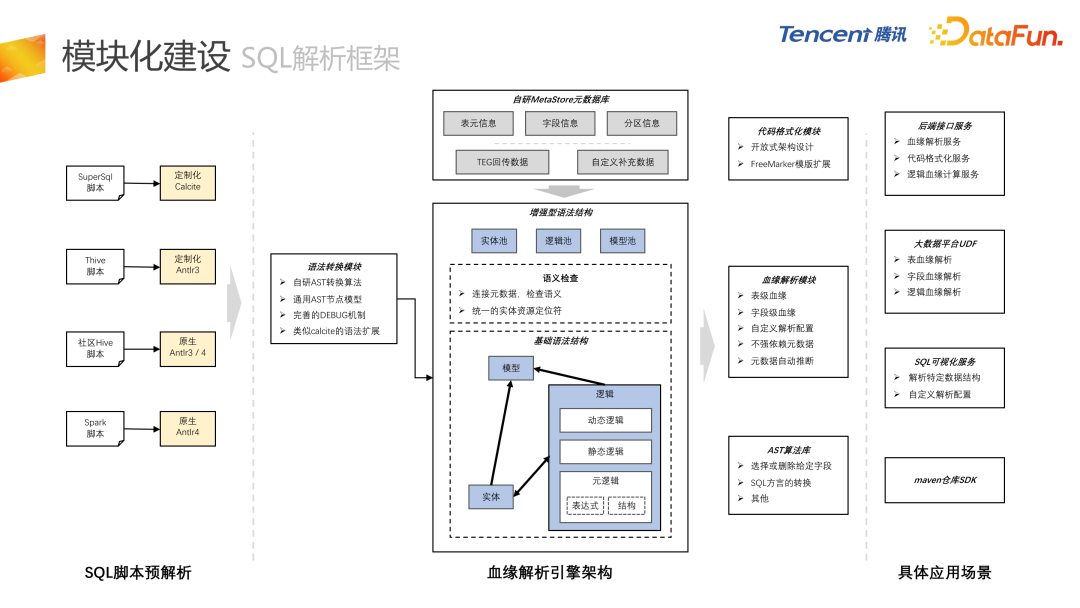
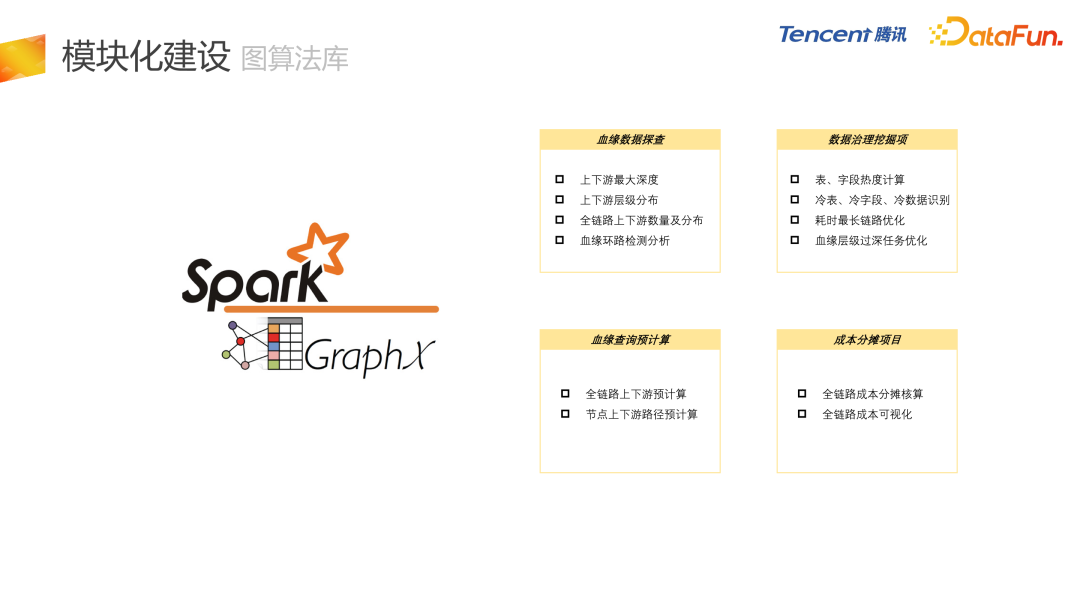
接下来介绍每个子模块的细节。 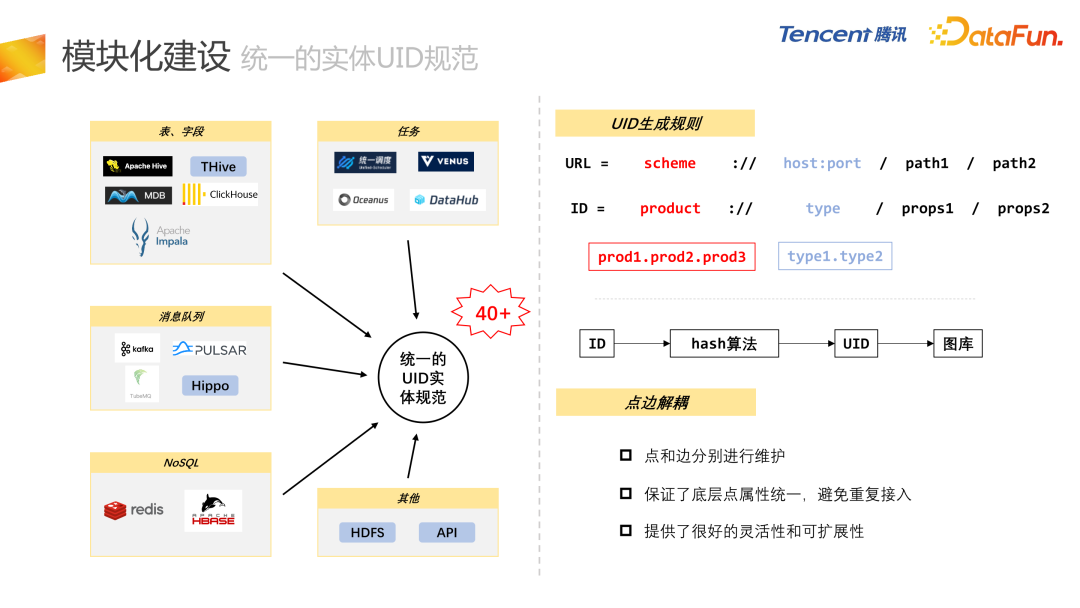
应用场景
最后介绍内部的应用场景,整体分为五大类。 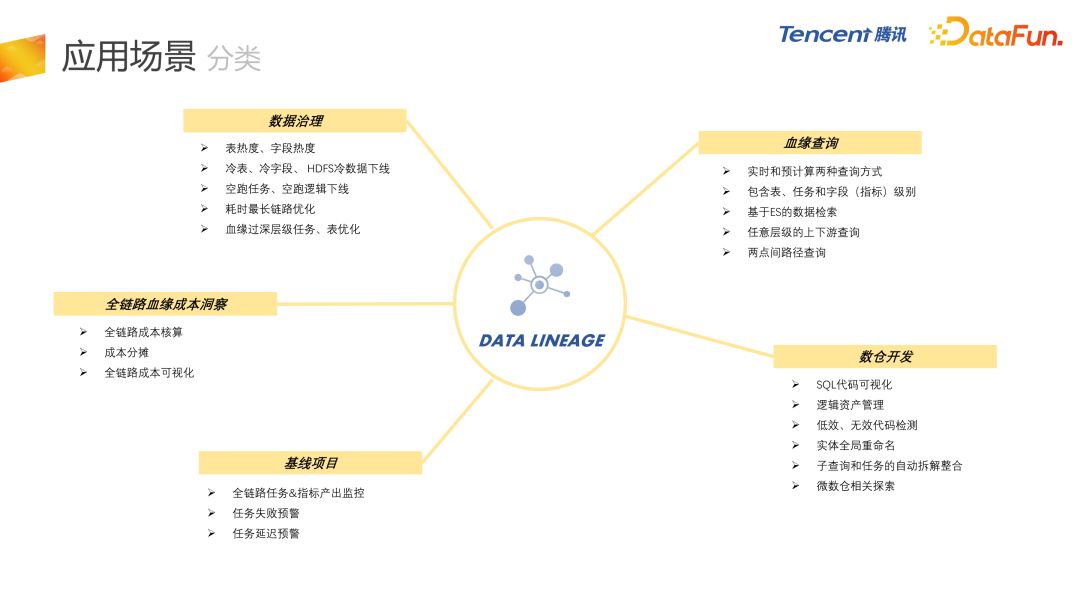
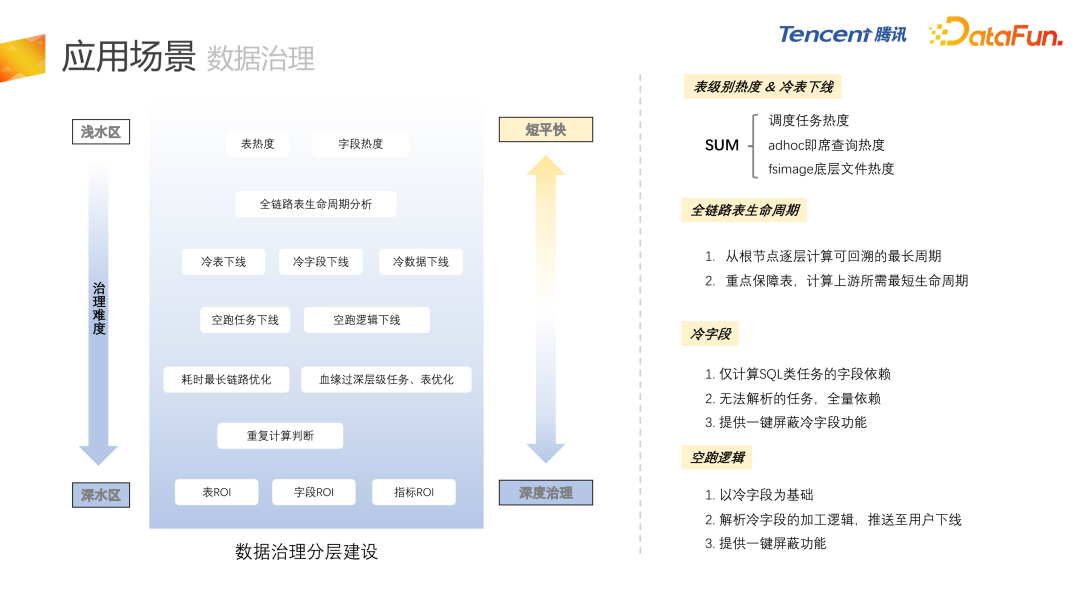
- 首先是数据治理,血缘最直接的应用就是应用在数据治理上,包括冷表、冷字段、甚至 HDFS 冷数据的下线,还有空跑任务、空跑逻辑的下线,耗时最长链路的优化等等。
- 第二是血缘查询,直接面向用户进行血缘查询。
- 第三是数仓开发,支持 SQL 代码的可视化,逻辑资产管理,低效、无效代码的检测,因为是 AST 级别的血缘,所以能够有效地把低效和无效代码检测出来。 另外,会基于 AST 的血缘进行微数仓相关的探索。
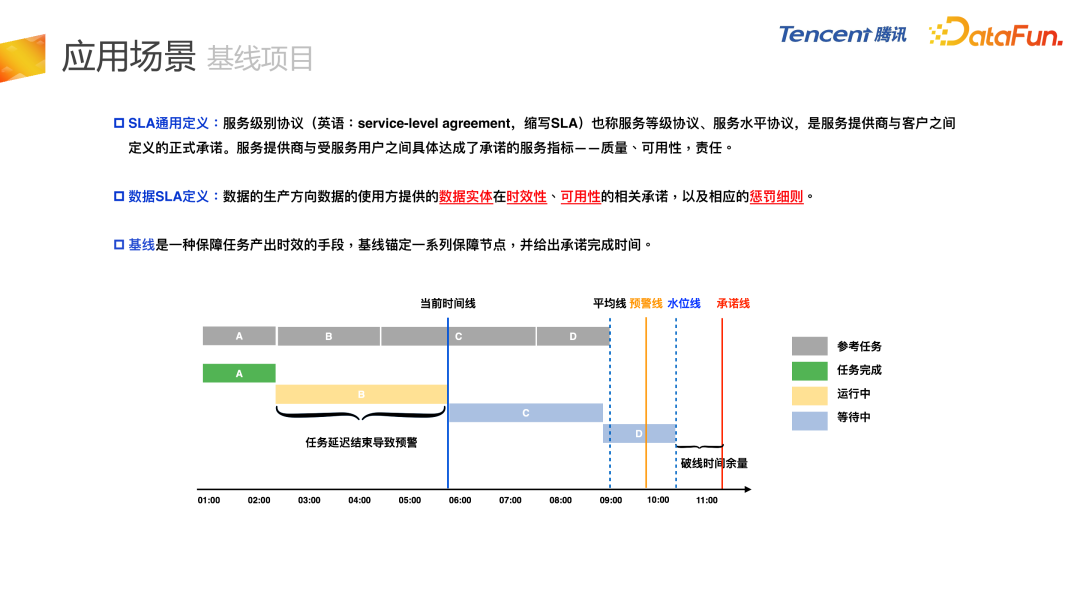
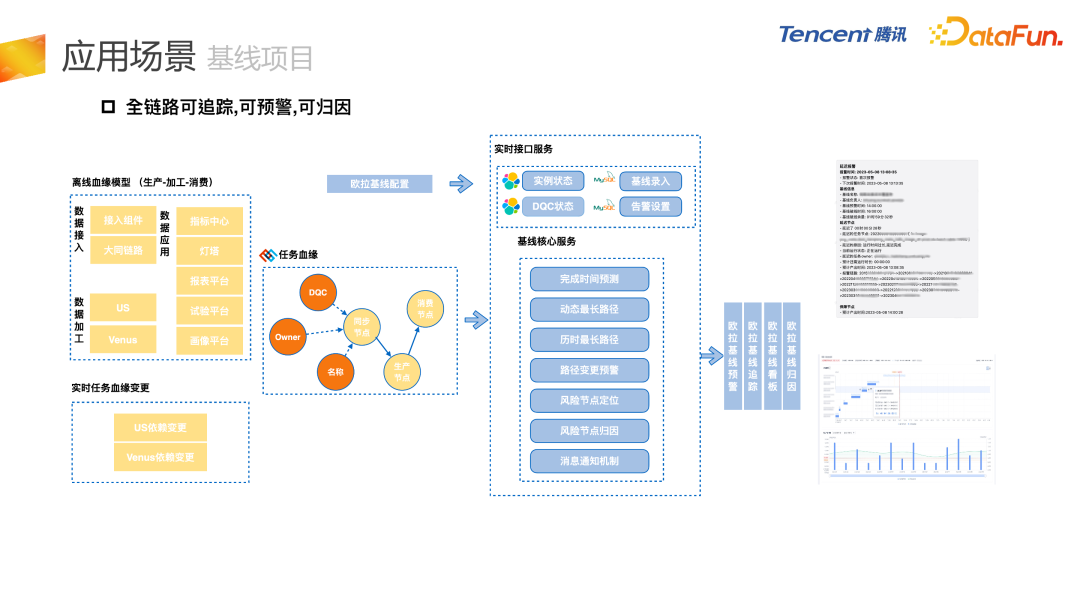
- 第四是基线项目,对全链路任务的失败或者延迟进行监控。
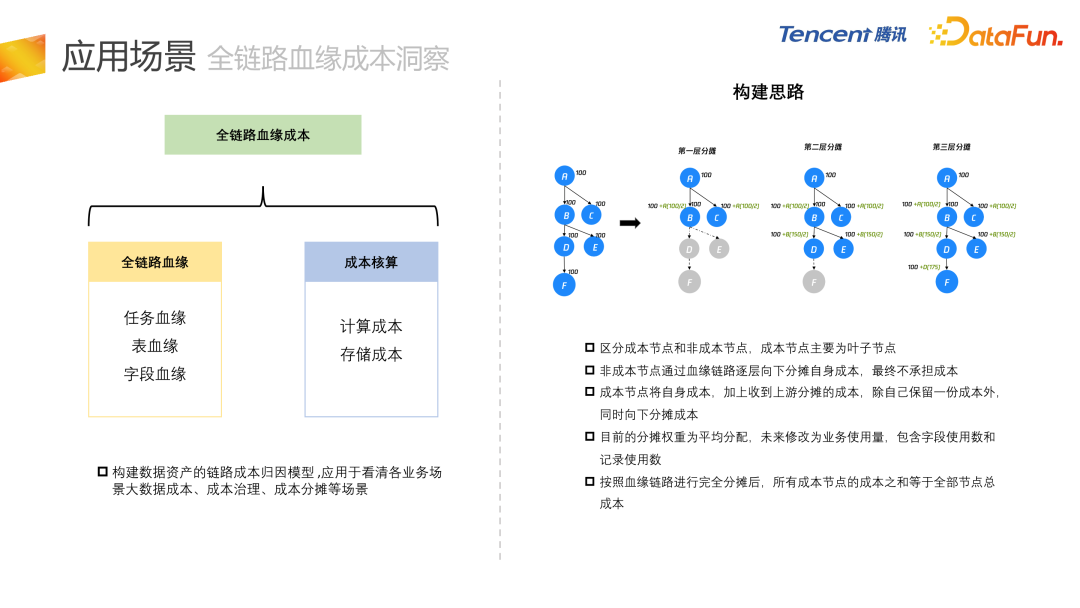
- 最后是全链路血缘成本洞察项目,结合血缘和成本核算两块内容。

问答环节
Q1 :请问从头开始血缘关系建设的话,是从任务到字段建设好,还是从字段到任务建设好? A1:我们推荐从任务到字段,表血缘需要和任务血缘进行对齐操作,字段血缘也需要和表血缘进行对齐操作。表血缘的上下游有,它的字段血缘肯定是要有上下游关系的。还有一个情况,目前任务级血缘是最准的,因为任务血缘是用户进行线上的任务增删改查的操作,下发的消息或者 MDB 数据,所以我们还是推荐从任务血缘向表血缘和字段血缘进行向下建设。 Q2 :怎么评估血缘的准确性? A2:我们有一个内部监控,这个监控只能去监控解析的成功率和一些比较固定的形式。我们目前采用的方法还是结合固定监控和人工探查。比如字段血缘,其实目前的解析准确率已经很高了,能达到 99% 以上,但是 99% 这个数值,也是通过人工选取一些样例数据,对比解析的结果和人工判断的结果,得到的准确率。 Q3 :在读写数据的时候用的 JDBC 或者自定义的 data source,怎么把这些血缘串联起来?现在是否支持? A3:我们目前能够收集到的就是任务的配置,但是 JDBC 我们目前还没有介入到这一块,因为可能涉及到jar 包任务。刚才提到 jar 包任务,我们会进行上下游表级血缘的全量依赖,并对字段级别进行存量依赖。我们会分两个概念,表级别的,我们可以通过配置来拿到,字段级别就会使用表级别的血缘进行上下游的存量依赖。 Q4 :基线项目的用户都有哪些角色? A4:基线项目目前主要面对的是 DE 和 DS,即数据工程师和数据分析师,保证任务和指标能够正常产出。他们会关注任务今天为什么会延迟,会逐层地往上找,我们通过基线项目及时给他发一个预警,告诉他链条中哪一个节点出了延迟或者出了问题,方便快速地进行定位。 Q5 :支持 Spark dataframe 的字段血缘吗? A5:这个属于 jar 包任务,目前处于全量依赖的阶段,根据表血源去把字段血源制成全量依赖,避免字段级别的血缘突然在某一层断掉。 Q6 :主要用的数据结构和算法? A6:SQL 解析框架用到的数据结构和算法会比较多,因为这个是纯自研的 SQL 解析框架,并且它和普通的 SQL 解析框架还不太一样,它不是直接去写 SQL 的 Parser,而是基于 Calcite 和 Antlr 解析好的 AST 语法树,进行转换操作,转换到我们自研的语法结构。数据结构主要是递归和回溯,另外有比较细节的算法,处理某个问题节点会应用到特定的算法。 Q7 :欧拉平台考虑对外开放吗?还是只对内?如果对外开放依赖组件这么多,会不会有维护和运维的成本? A7:据我了解,是有对外开放规划的,而且目前已经和多方进行了合作。欧拉平台有一些模块集成在腾讯云上,有对外售卖。例如治理引擎,对事后的存量数据资产进行问题的扫描、发现、推进、治理等等。这个模块目前在腾讯云上是有对外开放的。欧拉在内部的平台更加完善,功能也更多,有一些跟内部的组件有深度的耦合和依赖。未来我们也会逐步考虑有哪些组件可以抽象出来,对外开放。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!
全网首发|大数据专家级技能模型与学习指南(胜天半子篇) 互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么? 193篇文章暴揍Flink,这个合集你需要关注一下 Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点 我们在学习Spark的时候,到底在学习什么? 在所有Spark模块中,我愿称SparkSQL为最强! 硬刚Hive | 4万字基础调优面试小总结 数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】社招和校招的经验之谈 大数据方向另一个十年开启 |《硬刚系列》第一版完结 我写过的关于成长/面试/职场进阶的文章 当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
评论