
面试官:跨库多表存在大量数据依赖问题有哪些解决方案?
1
前言
曾经设计的一个供应链系统中,存在商品、销售订单、采购这三个服务,它们的主数据的部分结构如下所示:
商品:
| ID | 名称 | 分类 | 型号 | 生产年份 | 编码 |
|---|
订单和子订单:
| 订单ID | 下单时间 | 客户 | 总金额 | 子订单ID | 商品ID | 单价 | 数量 |
|---|
采购单和子订单:
| 采购单ID | 下单时间 | 供应商 | 总金额 | 采购子订单ID | 商品ID | 单价 | 数量 |
|---|
在设计这个供应链系统时,我们需要满足以下两个需求:
根据商品的型号/分类/生成年份/编码等查找订单;
根据商品的型号/分类/生成年份/编码等查找采购订单。
初期我们的方案是这样设计的:严格按照的微服务划分原则将商品相关的职责存放在商品系统中。因此,在查询订单与采购单时,如果查询字段包含商品字段,我们需要按照如下顺序进行查询:
先根据商品字段调用商品的服务,然后返回匹配的商品信息;
在订单或采购单中,通过 IN 语句匹配商品 ID,再关联查询对应的单据。
为了方便理解这个过程,订单查询流程图如下图所示:
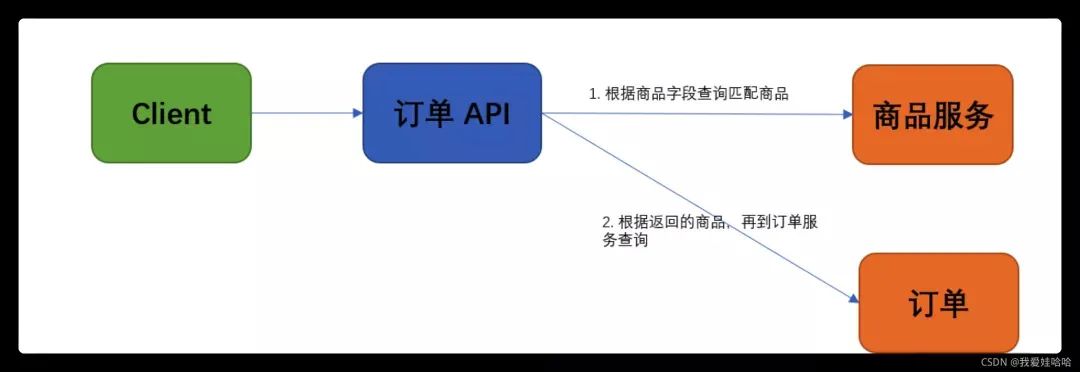
初期方案设计完后,很快我们就遇到了一系列问题:
随着商品数量的增多,匹配的商品越来越多,于是订单服务中包含 IN 语句的查询效率越来越慢
商品作为一个核心服务,依赖它的服务越来越多,同时随着商品数据量的增长,商品服务已不堪重负,响应速度也变慢,还存在请求超时的情况
由于商品服务超时,相关服务处理请求经常失败。
结果就是业务方每次查询订单或采购单时,只要带上了商品这个关键字,查询效率就会很慢而且老是失败。于是,我们重新想了一个新方案——数据冗余,下面我们一起来看下。
2
数据冗余的方案
数据冗余说白了就是在订单、采购单中保存一些商品字段信息。
为了方便理解,我们借助上面实际业务场景具体说明下,看看两者的区别。
商品:
| ID | 名称 | 分类ID | 型号 | 生产年份ID | 编码 |
|---|
订单和子订单:
| 订单ID | 下单时间 | 客户 | 总金额 | ||||
|---|---|---|---|---|---|---|---|
| 子订单ID | 商品ID | 单价 | 数量 | 商品名称 | 商品分类ID | 商品型号 | 生产批次ID |
采购单和子订单:
| 采购单ID | 下单时间 | 供应商 | 总金额 | ||||
|---|---|---|---|---|---|---|---|
| 采购子订单ID | 商品ID | 单价 | 数量 | 商品名称 | 商品分类ID | 商品型号 | 生产批次ID |
调整架构方案后,每次查询时,我们就可以不再依赖商品服务了。
但是,如果商品进行了更新,我们如何同步冗余的数据呢?在此分享2种解决办法。
每次更新商品时,先调用订单与采购服务,再更新商品的冗余数据。
每次更新商品时,先发布一条消息,订单与采购服务各自订阅这条消息后,再各自更新商品冗余数据。
那么这2种方案会出现哪些问题呢?
如果商品服务每次更新商品都要调用订单与采购服务,然后再更新冗余数据,则会出现以下两种问题。
数据一致性问题:如果订单与采购的冗余数据更新失败了,整个操作都需要回滚。这时商品服务的开发人员肯定不乐意,因为冗余数据不是商品服务的核心需求,不能因为边缘流程阻断了自身的核心流程。
依赖问题:从职责来说,商品服务应该只关注商品本身,但是现在商品还需要调用订单与采购服务。而且,依赖商品这个核心服务的服务实在是太多了,也就导致后续商品服务每次更新商品时,都需要调用更新订单冗余数据、更新采购冗余数据、更新门店库存冗余数据、更新运营冗余数据等一大堆服务。那么商品到底是下游服务还是上游服务?还能不能安心当底层核心服务?
因此,第一个解决办法直接被我们否决了,即我们采取的第二个解决办法——通过消息发布订阅的方案,因为它存在如下 2 点优势:
商品无须调用其他服务,它只需要关注自身逻辑即可,顶多多生成一条消息送到 MQ。
如果订单、采购等服务的更新冗余数据失败了,我们使用消息重试机制就可以了,最终能保证数据的一致性。
此时,我们的架构方案如下图所示:
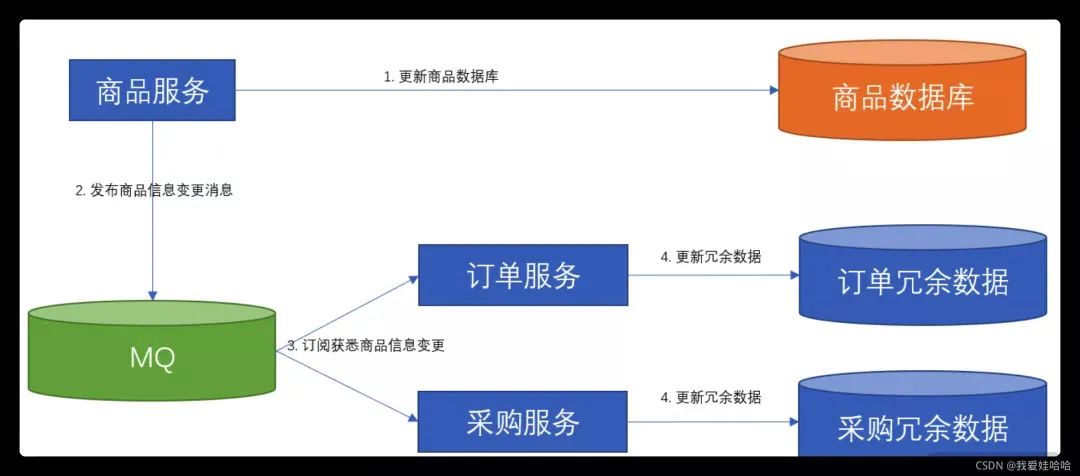
这个方案看起来已经挺完美了,而且市面上基本也是这么做的,不过该方案存在如下几个问题。
1、在这个方案中,仅仅保存冗余数据还远远不够,我们还需要将商品分类与生产批号的清单进行关联查询。也就是说,每个服务不只是订阅商品变更这一种消息,还需要订阅商品分类、商品生产批号变更等消息。下面请注意查看订单表结构的红色加粗部分内容。
| 订单ID | 下单时间 | 客户 | 总金额 | ||||
|---|---|---|---|---|---|---|---|
| 子订单ID | 商品ID | 单价 | 数量 | 商品名称 | 商品分类ID | 商品型号 | 生产批次ID |
以上只是列举了一部分的结构,事实上,商品表中还有很多字段存在冗余,比如保修类型、包换类型等。为了更新这些冗余数据,采购服务与订单服务往往需要订阅近十种消息,因此,我们基本上需要把商品的一小半逻辑复制过来。
2、每个依赖的服务需要重复实现冗余数据更新同步的逻辑。前面我们讲了采购、订单及其他服务都需要依赖商品数据,因此每个服务需要将冗余数据的订阅、更新逻辑做一遍,最终重复的代码就会很多。
3、MQ 消息类型太多了:联调时最麻烦的是 MQ 之间的联动,如果是接口联调还好说,因为调用哪个服务器的接口相对可控而且比较好追溯;如果是消息联调就比较麻烦,因为我们常常不知道某条消息被哪台服务节点消费了,为了让特定的服务器消费特定的消息,我们就需要临时改动双方的代码。不过联调完成后,我们经常忘了改回原代码。
为此,我们不希望针对冗余数据这种非核心需求出现如此多的问题,最终决定使用一个特别的同步冗余数据方案,接下来我们进一步说明。
3
解耦业务逻辑的数据同步方案
解耦业务逻辑的数据同步方案的设计思路是这样的:
将商品及商品相关的一些表(比如分类表、生产批号表、保修类型、包换类型等)实时同步到需要依赖使用它们的服务的数据库,并且保持表结构不变;
在查询采购、订单等服务时,直接关联同步过来的商品相关表;
不允许采购、订单等服务修改商品相关表。
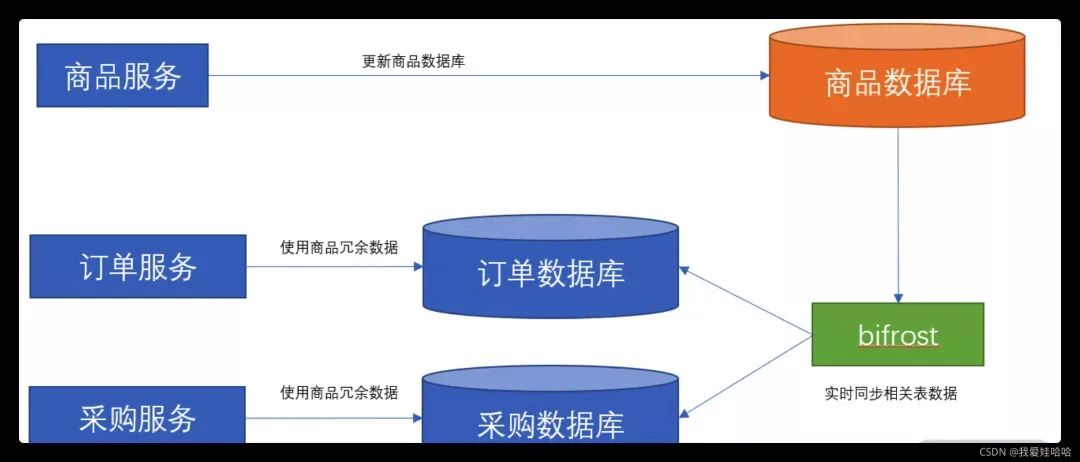
此时,整个方案的架构如下图所示:
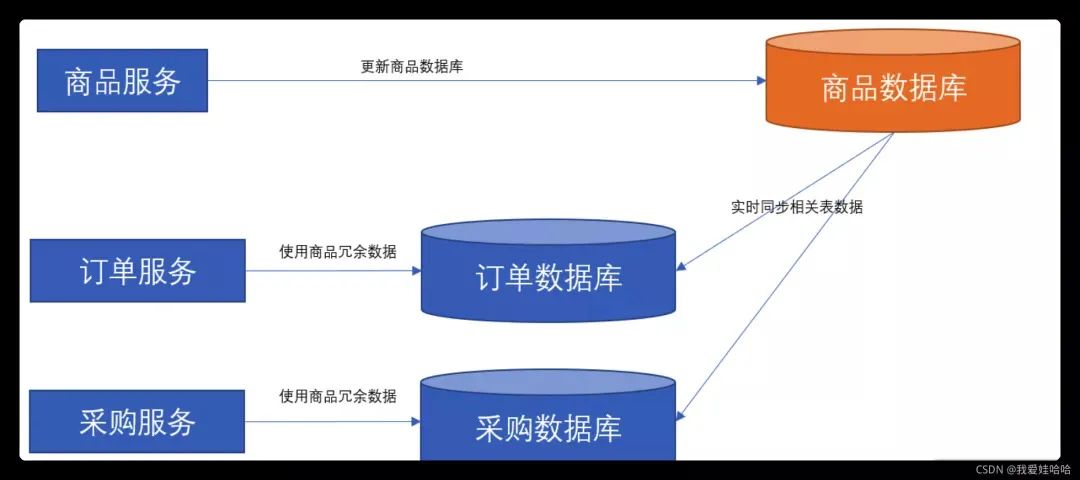
以上方案就能轻松解决如下两个问题:
商品无须依赖其他服务,如果其他服务的冗余数据同步失败,它也不需要回滚自身的流程;
采购、订单等服务无须关注冗余数据的同步。
不过,该方案的“缺点”是增加了订单、采购等数据库的存储空间(因为增加了商品相关表)。
仔细计算后,我们发现之前数据冗余的方案中每个订单都需要保存一份商品的冗余数据,假设订单总数是 N,商品总数是 M,而 N 一般远远大于 M。因此,在之前数据冗余的方案中,N 条订单就会产生 N 条商品的冗余数据。相比之下,解耦业务逻辑的数据同步方案更省空间,因为只增加了 M 条商品的数据。
此时问题又来了,如何实时同步相关表的数据呢?
我们直接找一个现成的开源中间件就可以了,不过它需要满足支持实时同步、支持增量同步、不用写业务逻辑、支持 MySQL 之间同步、活跃度高这五点要求。
根据这五点要求,我们在市面上找了一圈,发现了 Canal、Debezium、DataX、Databus、Flinkx、Bifrost 这几款开源中间件,它们之间的区别如下表所示:
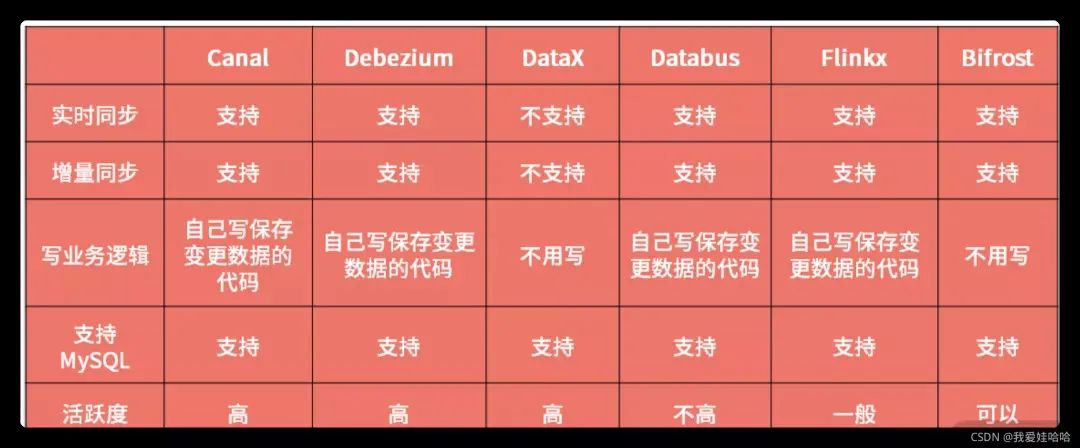
从对比表中来看,比较贴近我们需求的开源中间件是 Bifrost,原因如下:
它的界面管理不错;
它的架构比较简单,出现问题后,我们可以自行调查,之后就算作者不维护了也可以自我维护,相对比较可控。
作者更新活跃;
自带监控报警功能。
因此,最终我们使用了 Bifrost 开源中间件,此时整个方案的架构如下图所示:
4
最终效果
整个架构方案上线后,商品数据的同步还算比较稳定,此时商品服务的开发人员只需要关注自身逻辑,无须再关注使用数据的人。如果需要关联使用商品数据的订单,采购服务的开发人员也无须关注商品数据的同步问题,只需要在查询时加上关联语句即可,实现了双赢。
然而,唯一让我们担心的是 Bifrost 不支持集群,没法保障高可用性。不过,到目前为止,它还没有出现宕机的情况,反而是那些部署多台节点负载均衡的后台服务常常会出现宕机。
最终,我们总算解决了服务之间数据依赖的问题。
往期推荐