
为了把Hive数据同步到ClickHouse,我调研了Waterdrop
一 背景
接到一个需求,需要把hive数据同步到clickhouse,本来以为是一个非常简单的需求,因为数据平台已经集成了datax,最新版的datax是支持clickhouse writer的。
万万没想到,同步的时候有点慢,每小时400w条数据左右,表里面这么多数据,要同步到什么时候去。所以开始了漫漫调研路,最终选择了waterdrop
二 关于waterdrop
Waterdrop是生产环境中的海量数据计算引擎,可以满足你的流式,离线,etl,聚合等计算需求。InterestingLab是一个以为用户简化和普及大数据处理为核心目标的开源技术团队。核心项目Waterdrop是基于Spark,Flink构建的配置化,零开发成本的大规模流式及离线处理工具。目前已有360、滴滴、华为、微博、新浪、一点资讯、永辉集团、水滴筹等多个行业的公司在线上使用。
项目地址: https://github.com/InterestingLab/waterdrop
文档地址:https://interestinglab.github.io/waterdrop-docs/
快速入门:https://interestinglab.github.io/waterdrop-docs/#/zh-cn/v1/quick-start
行业应用案例:https://interestinglab.github.io/waterdrop-docs/#/zh-cn/v1/case_study/
插件开发:https://interestinglab.github.io/waterdrop-docs/#/zh-cn/v1/developing-plugin
Waterdrop的设计与实现原理:https://mp.weixin.qq.com/s/lYECVCYdKsfcL64xhWEqPg
三 waterdrop架构
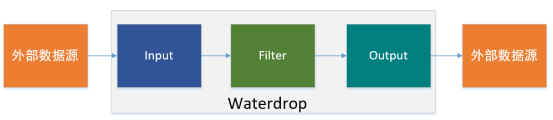
3.1 input
3.2 filter
3.3 output

四 安装使用
4.1 下载
https://github.com/InterestingLab/waterdrop/releases
4.2 解压
tar -zxvf waterdrop-1.4.2-with-spark.zip |
4.3配置文件修改(hive-->clickhouse)
waterdrop-env.sh
#!/usr/bin/env bash # Home directory of spark distribution. SPARK_HOME=/usr/local/spark-current/ |
test_df.conf
spark { spark.app.name = "hive-ck" spark.executor.instances = 8 spark.executor.cores = 2 spark.executor.memory = "2g" spark.sql.catalogImplementation = "hive" spark.yarn.queue="root.test" }
input { hive { pre_sql = "select * from wedw_tmp.test_df" table_name = "test_df" }
}
filter {
}
output {
clickhouse { host = "10.20.xxx.xxx:8123" database = "ck" clickhouse.socket_timeout=600000 table = "test_df" username = "root" password = "123456" bulk_size = 50000 retry = 3 }
} |
4.4 启动waterdrop同步数据
/home/pgxl/liuzc/waterdrop-1.4.2/bin/start-waterdrop.sh --master yarn --deploy-mode client --config /home/pgxl/liuzc/waterdrop-1.4.2/config/test.conf |
4.5 速度
2亿条数据,一个小时左右
五 使用中可能遇到的问题
5.1 Too many parts (304). Merges are processing significantly slower than inserts
merge速度跟不上插入速度,也就是insert,可能原因: 数据是否可能跨多个分区, 如果这样的话每次写入有多个partition, merge压力很大,可以减少并发
spark.executor.instances = 4 |
5.2 read time out
超时问题,可适当增加 超时时间
clickhouse.socket_timeout=600000 |
5.3 找不到类
需要看一下spark的配置
--end--
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群