
480万标记样本:Facebook提出「预微调」,持续提高语言模型性能
共 1489字,需浏览 3分钟
·
2021-02-19 13:33

新智元报道
新智元报道
来源:venturebeat
编辑:yaxin
【新智元导读】近日,Facebook的研究人员提出了一种能够改善训练语言模型性能的方法——预微调,在大约50个分类、摘要、问答和常识推理数据集上进行了480万个标记样本。
机器学习研究人员在自我监督的语言模型预训练方面取得了非凡的成功。自监督学习是不需要标记数据而进行训练。预训练是指通过一项任务来训练模型,并可应用于其他任务。
这样,预训练就模仿了人类处理新知识的方式。也就是说,通过使用以前学习过的任务参数,模型可以学习适应新的和不熟悉的任务。
但是,对于许多自然语言任务,存在针对相关问题的训练示例。
为了利用这些优势,Facebook的研究人员提出了一种训练语言模型的方法——预微调。

Facebook研究人员提出能够改善训练模型性能的方法
预先训练的语言模型使自然语言处理变得更便宜、更快、更容易,以更少的训练数据获得更好的性能。
语言模型预训练使用自我监督,不需要任何训练数据。另一方面,微调可用于进行端点调整以增强性能。
Facebook研究人员提出「预微调」训练语言模型的这一方法在大约50个分类、摘要、问答和常识推理数据集上进行了480万个标记样本。
他们声称,预微调能够持续改善预训练模型的性能,同时还能显着提高微调过程中的采样效率。
这是以前尝试过的方法,通常会取得成功。
在2019年的一项研究中,艾伦研究所的研究人员注意到,在多选问题数据集上对BERT模型进行预微调似乎可以教给该模型一些有关多选问题的知识。

随后的研究发现,预微调提高了模型对名称交换的鲁棒性。在这种情况下,不同人的名字被替换为该模型必须回答的句子。
为了确保他们的微调前阶段包含通用语言表示形式,Facebook研究人员囊括了在四个不同领域中的任务:分类、常识推理、机器阅读理解和摘要。
他们称其为预先优化的模型MUPPET,代表「具有预先优化的大型多任务表示」。
训练任务大于15个,「预微调」能够改善模型性能
在对两种受欢迎经过预训练的自然语言理解模型RoBERTa和BART进行了预微调之后,研究人员在广泛使用的基准(包括RTE,BoolQ,RACE,SQuAD和MNLI)上测试了它们的性能。
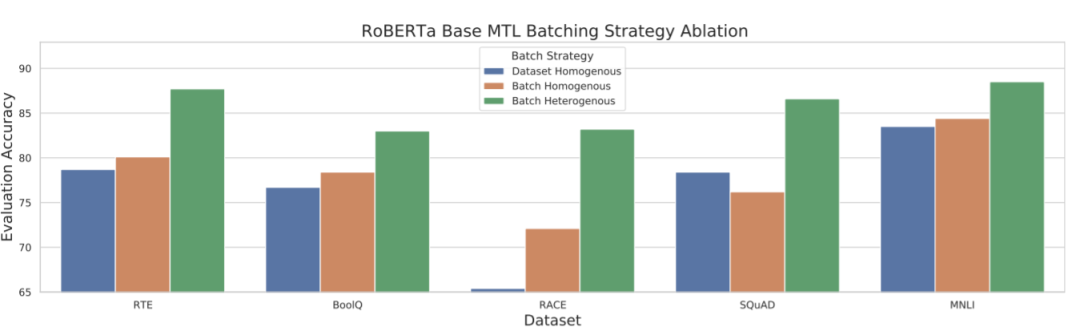
有趣的是,结果表明,当很少的任务直到临界点时(通常超过15个任务),预调整会损害性能。
但是,超出这15个任务进行预微调会导致与语言任务数量相关的性能改进。
MUPPET模型的性能优于其经过香草预训练的同类模型,利用34-40个任务的表示形式。
与基线RoBERTa模型相比,使用较少的数据即可使模型达到更高的精确度。
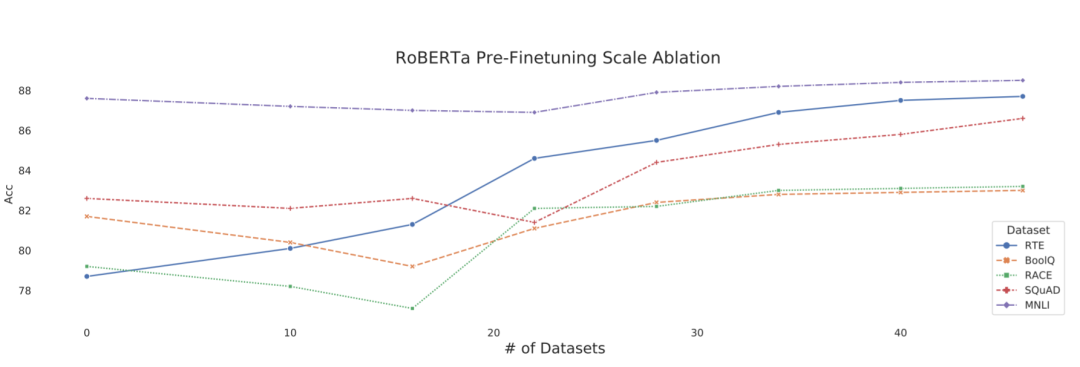
研究人员在描述其工作的论文中写道,在资源匮乏的情况下,这些性能提高尤其明显,因为在这种情况下,用于微调的标签数据相对较少。我们证明,通过大规模多任务学习,我们可以有效地学习更强大的表示形式。
Facebook的研究工作表明,看似非常不同的数据集能够通过改善模型的表示形式互相帮助。
参考链接:
https://venturebeat.com/2021/02/01/facebook-researchers-propose-pre-fine-tuning-to-improve-language-model-performance/
推荐阅读:
