
B 站崩了,总结下「高可用」和「异地多活」
共 5354字,需浏览 11分钟
·
2021-07-17 06:42
这是悟空的第 112 篇原创文章
你好,我是悟空。
一、背景
不用想象一种异常场景了,这就真实发生了:B 站昨天晚上 11 点突然挂了,网站主页直接报 404。
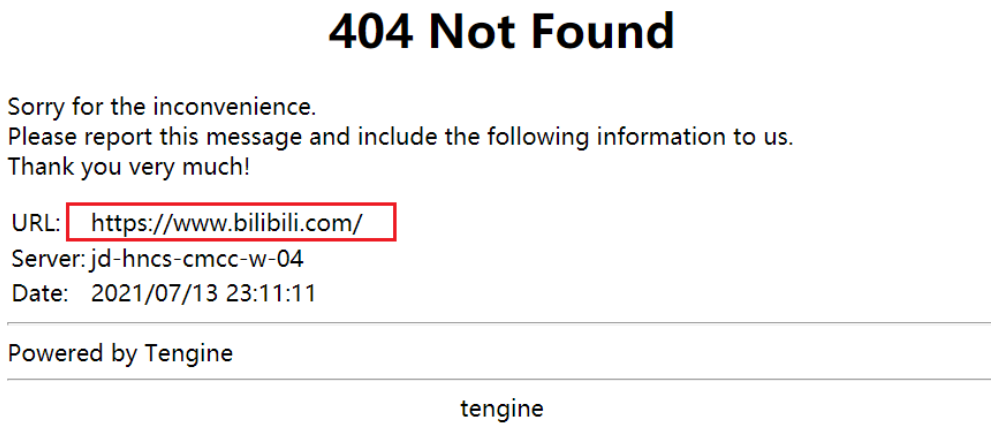
手机 APP 端数据加载不出来。

23:30 分,B 站做了降级页面,将 404 页面跳转到了比较友好的异常页面。
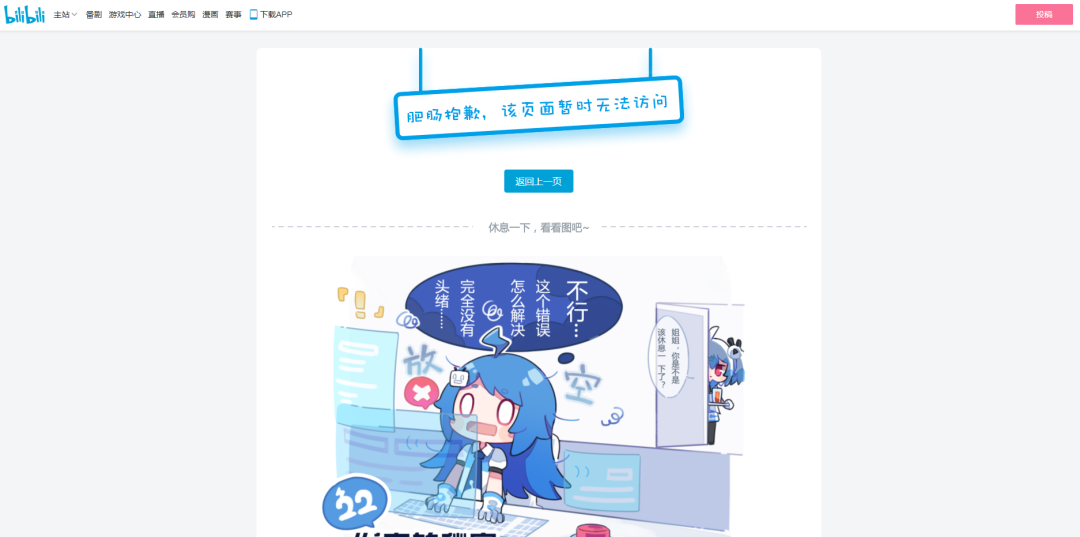
但是刷新下页面,又会跳转到 404 页面。
22:35 主页可以加载出数据了,但是点击动态还是会报 502
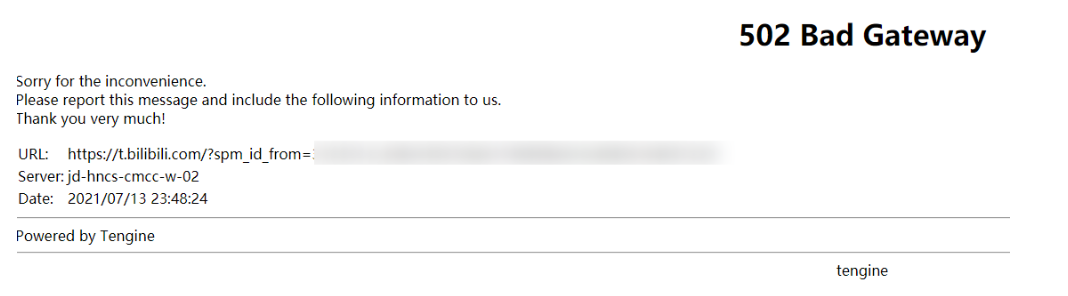
点击某个视频,直接报 404。
2021-07-14 02:00 之后 B 站开始逐渐恢复。
二、什么原因
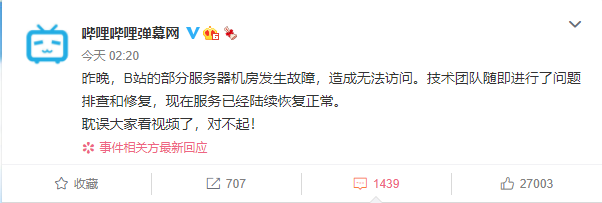
今日凌晨 2 点,B 站发布公告称,昨晚,B 站的部分服务器机房发生故障,造成无法访问。技术团队随即进行了问题排查和修复,现在服务已经陆续恢复正常。而针对网友传言的 B 站大楼失火一事,上海消防官博进行了辟谣,B 站大楼并未出现火情。
看来 B 站的高可用并不令我们满意。接下来我们来探讨下什么是高可用以及跨机房部署的思路。本篇正文内容如下:
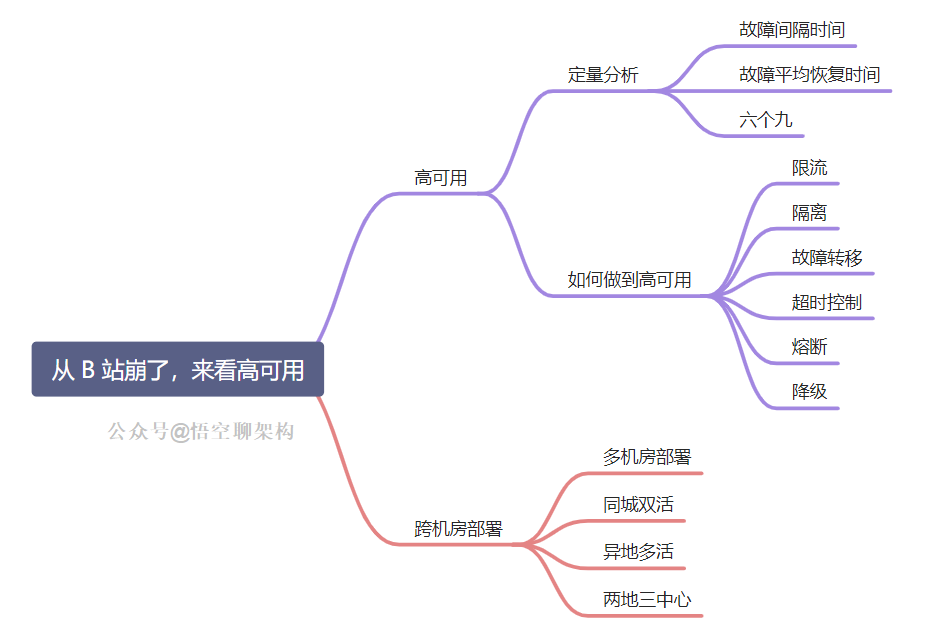
三、到底什么是高可用
经过了 2 个小时,B 站才开始逐渐恢复,那 B 站系统到底算不算高可用呢?
首先高可用是个相对的形容词。那什么是高可用呢?
3.1 高可用
高可用性(High Availability,HA)我们已经耳熟能详,指的是系统具备较高的无故障运行的能力。
B 站针对高可用架构还做过一篇分享:
重点:以后 B 站面试这类题不考,望周知。
常见的高可用的方案就是一主多从,主节点挂了,可以快速切换到从节点,从节点充当主节点,继续提供服务。比如 SQL Server 的主从架构,Redis 的主从架构,它们都是为了达到高可用性,即使某台服务器宕机了,也能继续提供服务。
刚刚提到了快速,这是一个定性词语,那定量的高可用是怎么样的?
3.2 定量分析高可用
有两个相关的概念需要提及:MTBF 和 MTTR。
MTBF:故障间隔时间,可以理解为从上次故障到这次故障,间隔多久,间隔的越长,系统稳定性越高。
MTTR:故障平均恢复时间,可以理解为突然发生故障了,到系统恢复正常,经历了多长时间,这个时间越短越好,不然用户等着急了,会收到很多投诉。
可用性计算公式:MTBF/(MTBF+MTTR)* 100%,就是用故障的间隔时间除以故障间隔时间+故障平均恢复时间的总和。
通常情况下,我们使用几个九来表示系统的可用性,之前我们项目组的系统要求达到年故障时间不超过 5 分钟,也就是五个九的标准。
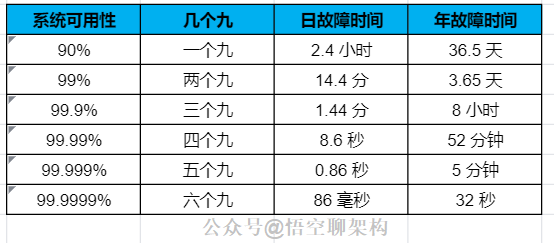
3.3 定量分析 B 站
来反观下 B 站故障了多久,2021-07-13 23:00 到 2021-07-14 02:00,系统逐渐恢复,如果按照年故障总时间来算的话:B 站故障超过 1 个小时了,只能算达到了三个九的标准。如果按照日故障时间来算,只能达到两个九的标准,也就是 99% 的高可用性,有点惨...
3.4 一个九和两个九
非常容易达到,一个正常的线上系统不会每天宕机 15 分钟吧,不然真用不下去了。
3.5 三个九和四个九
允许故障的时间很短,年故障时间是 1 小时到 8 小时,需要从架构设计、代码质量、运维体系、故障处理手册等入手,其中非常关键的一环是运维体系,如果线上出了问题,第一波收到异常通知的肯定是运维团队,根据问题的严重程度,会有不同的运维人员来处理,像 B 站这种大事故,就得运维负责人亲自上阵了。
另外在紧急故障发生时,是否可以人工手段降级或者加开关,限制部分功能,也是需要考虑的。之前我遇到过一个问题,二维码刷卡功能出现故障,辛亏之前做了一个开关,可以将二维码功能隐藏,如果用户要使用二维码刷卡功能,统一引导用户走线下刷卡功能。
3.6 五个九
年故障时间 5 分钟以内,这个相当短,即使有强大的运维团队每天值班也很难在收到异常报警后,5 分钟内快速恢复,所以只能用自动化运维来解决。也就是服务器自己来保证系统的容灾和自动恢复的能力。
3.7 六个九
这个标准相当苛刻了,年故障时间 32 秒。
针对不同的系统,其实对几个九也不相同。比如公司内部的员工系统,要求四个九就可以,如果是给全国用户使用,且使用人数很多,比如某宝、某饿,那么就要求五个九以上了,但是即使是数一数二的电商系统,它里面也有非核心的业务,其实也可以放宽限制,四个九足以,这个就看各家系统的要求,都是成本、人力、重要程度的权衡考虑。
四、如何做到高可用
高可用的方案也是很常见,故障转移、超时控制、限流、隔离、熔断、降级,这里也做个总结。
也可以看这篇:双 11 的狂欢,干了这碗「流量防控」汤
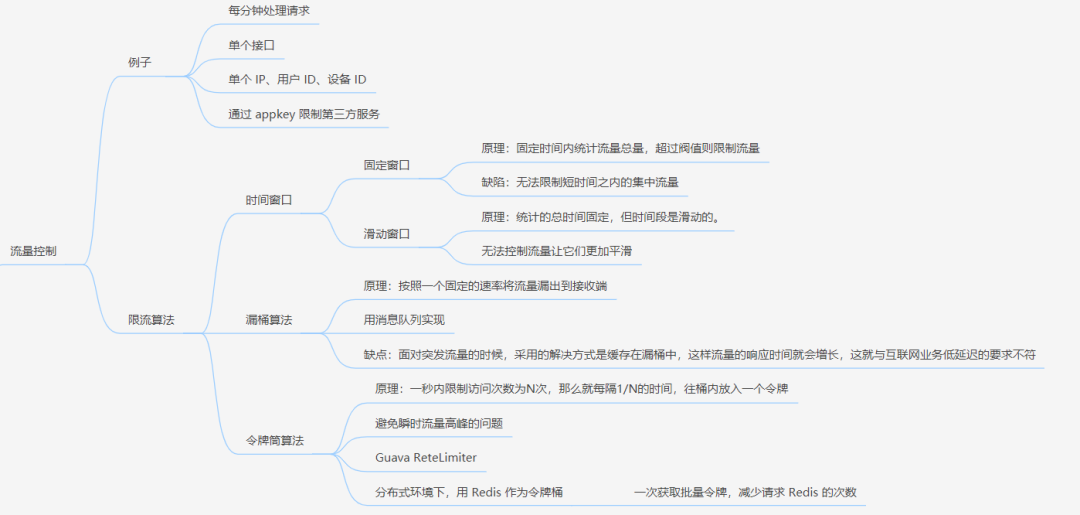
4.1 限流
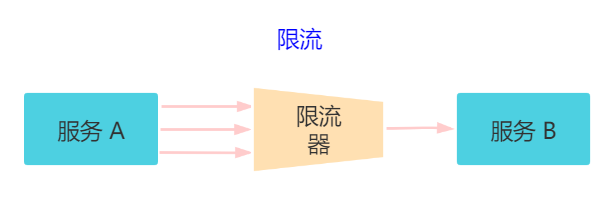
对请求的流量进行控制, 只放行部分请求,使服务能够承担不超过自己能力的流量压力。
常见限流算法有三种:时间窗口、漏桶算法、令牌桶算法。
4.1.1 时间窗口
时间窗口又分为固定窗口和滑动窗口。具体原理可以看这篇:东汉末年,他们把「服务雪崩」玩到了极致(干货)
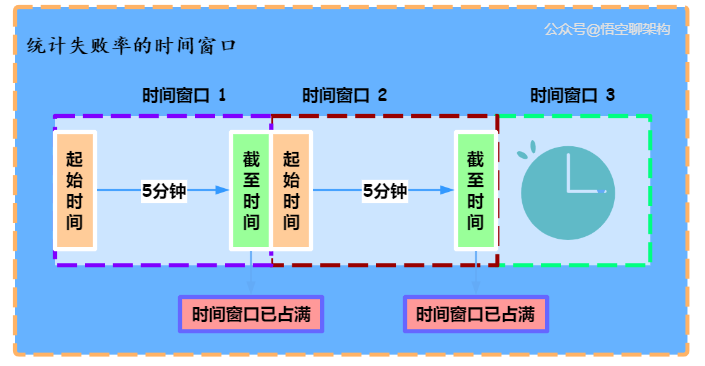
固定时间窗口:
原理:固定时间内统计流量总量,超过阀值则限制流量。
缺陷:无法限制短时间之内的集中流量。
滑动窗口原理:
原理:统计的总时间固定,但时间段是滑动的。
缺陷:无法控制流量让它们更加平滑
时间窗口的原理图在这里:
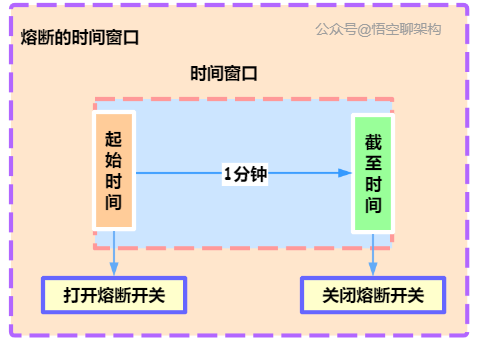
4.1.2 漏桶算法。
原理:按照一个固定的速率将流量露出到接收端。
缺陷:面对突发流量的时候,采用的解决方式是缓存在漏桶中,这样流量的响应时间就会增长,这就与互联网业务低延迟的要求不符。
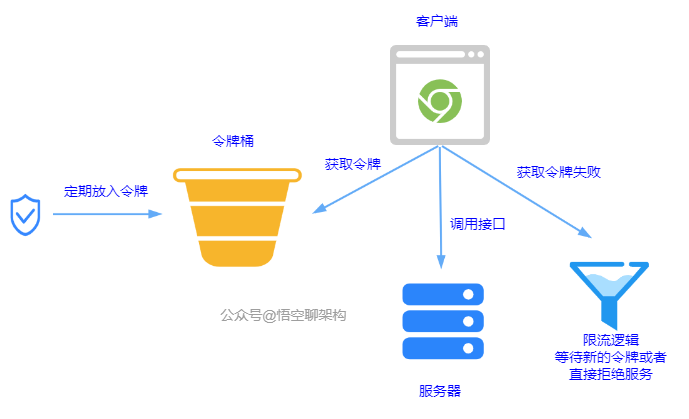
4.1.3 令牌桶算法
原理:一秒内限制访问次数为 N 次。每隔 1/N 的时间,往桶内放入一个令牌。分布式环境下,用 Redis 作为令牌桶。原理图如下:
总结的思维导图在这里:
4.2 隔离
每个服务看作一个独立运行的系统,即使某一个系统有问题,也不会影响其他服务。
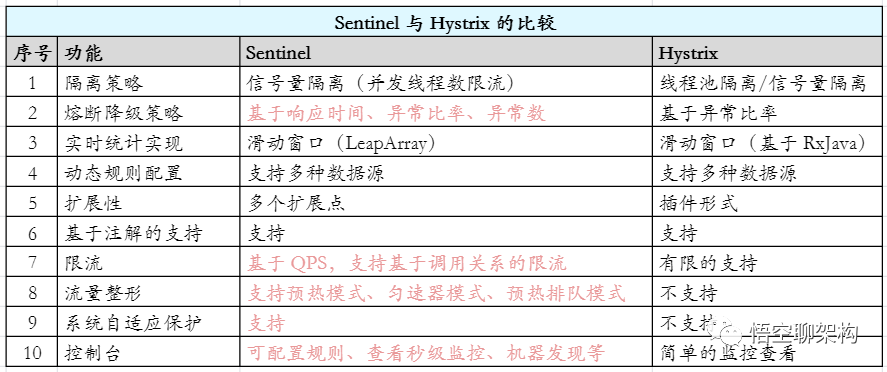
而常规的方案是使用两款组件:Sentinel 和 Hystrix。
4.3 故障转移
故障转移分为两种:
完全对等节点的故障转移。节点都是同等性质的。 不对等节点的故障转移。不对等就是主备节点都存在。
对等节点的系统中,所有节点都承担读写流量,并且节点不保存状态,每个节点就是另外一个的镜像。如果某个节点宕机了,按照负载均衡的权重配置访问其他节点就可以了。
不对等的系统中,有一个主节点,多个备用节点,可以是热备(备用节点也在提供在线服务),也可以是冷备(只是备份作用)。如果主节点宕机了,可以被系统检测到,立即进行主备切换。
而如何检测主节点宕机,就需要用到分布式 Leader 选举的算法,常见的就有 Paxos 和 Raft 算法,详细的选举算法可以看这两篇:
4.4 超时控制
超时控制就是模块与模块之间的调用需要限制请求的时间,如果请求超时的设置得较长,比如 30 s,那么当遇到大量请求超时的时候,由于请求线程都阻塞在慢请求上,导致很多请求都没来得及处理,如果持续时间足够长,就会产生级联反应,形成雪崩。
还是以我们最熟悉的下单场景为例:用户下单了一个商品,客户端调用订单服务来生成预付款订单,订单服务调用商品服务查看下单的哪款商品,商品服务调用库存服务判断这款商品是否有库存,如有库存,则可以生成预付款订单。
雪崩如何造成的?
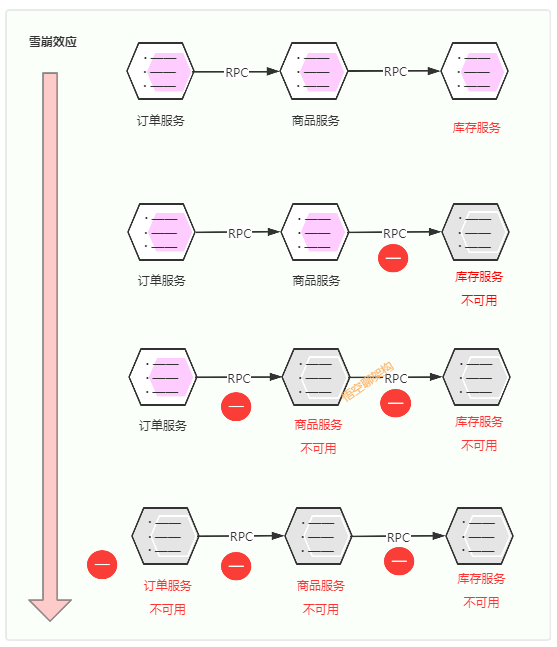
第一次滚雪球:库存服务不可用(如响应超时等),库存服务收到的很多请求都未处理完,库存服务将无法处理更多请求。 第二次滚雪球:因商品服务的请求都在等库存服务返回结果,导致商品服务调用库存服务的很多请求未处理完,商品服务将无法处理其他请求,导致商品服务不可用 第三次滚雪球:因商品服务不可用,订单服务调用商品服务的的其他请求无法处理,导致订单服务不可用。 第四次滚雪球:因订单服务不可用,客户端将不能下单,更多客户将重试下单,将导致更多下单请求不可用。
所以设置合理的超时时间非常重要。具体设置的地方:模块与模块之间、请求数据库、缓存处理、调用第三方服务。
4.5 熔断
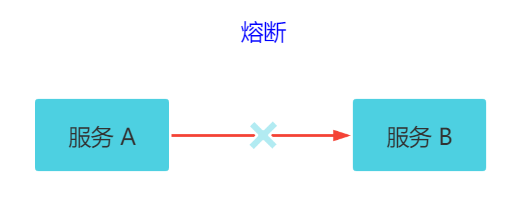
关键字:断路保护。比如 A 服务调用 B 服务,由于网络问题或 B 服务宕机了或 B 服务的处理时间长,导致请求的时间超长,如果在一定时间内多次出现这种情况,就可以直接将 B 断路了(A 不再请求B)。而调用 B 服务的请求直接返回降级数据,不必等待 B 服务的执行。因此 B 服务的问题,不会级联影响到 A 服务。
熔断的详细原理还是可以上面提到的:东汉末年,他们把「服务雪崩」玩到了极致(干货)
4.6 降级
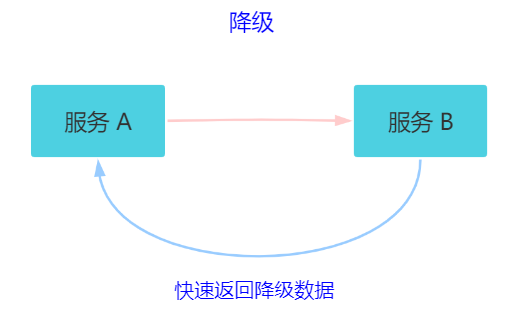
关键字:返回降级数据。网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级(停止服务,所有的调用直接返回降级数据)。以此缓解服务器资源的压力,保证核心业务的正常运行,保持了客户和大部分客户得到正确的响应。降级数据可以简单理解为快速返回了一个 false,前端页面告诉用户“服务器当前正忙,请稍后再试。”
熔断和降级的相同点? 熔断和限流都是为了保证集群大部分服务的可用性和可靠性。防止核心服务崩溃。 给终端用户的感受就是某个功能不可用。 熔断和降级的不同点? 熔断是被调用方出现了故障,主动触发的操作。 降级是基于全局考虑,停止某些正常服务,释放资源。
五、异地多活
5.1 多机房部署
含义:在不同地域的数据中心(IDC)部署了多套服务,而这些服务又是共享同一份业务数据的,而且他们都可以处理用户的流量。
某个服务挂了,其他服务随时切换到其他地域的机房中。
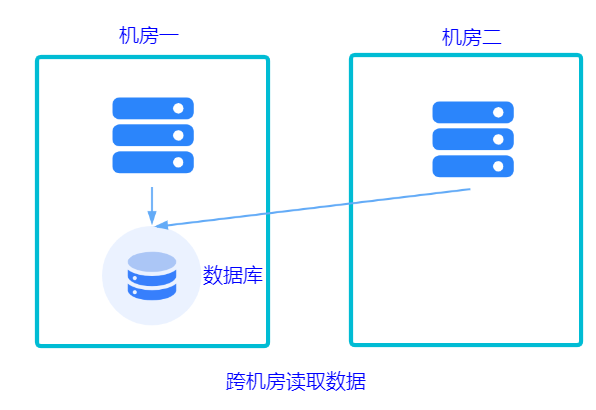
现在服务是多套的,那数据库是不是也要多套,无非就两种方案:共用数据库或不共用。
共用一套机房的数据库。
不共用数据库。每个机房都有自己的数据库,数据库之间做同步。实现起来这个方案更复杂。
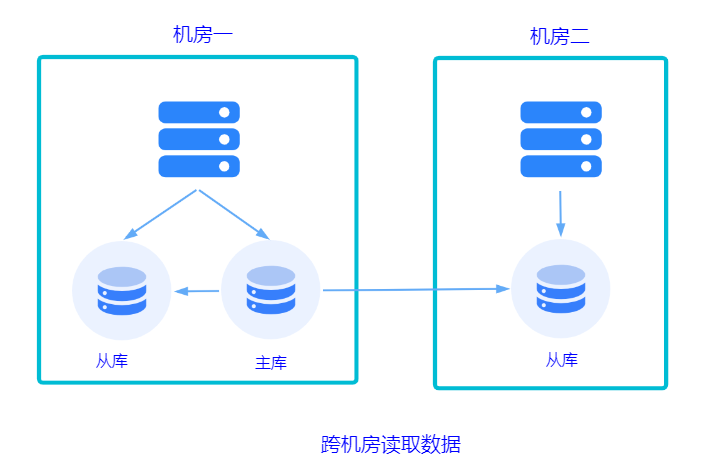
不论使用哪种方式,都涉及到跨机房数据传输延迟的问题。
同地多机房专线,延迟 1ms~3 ms。 异地多机房专线,延迟 50 ms 左右。 跨国多机房,延迟 200 ms 左右。
5.2 同城双活
高性能的同城双活,核心思想就是避免跨机房调用:
保证同机房服务调用:不同的 PRC(远程调用) 服务,向注册中心注册不同的服务组,而 RPC 服务只订阅同机房的 RPC 服务组,RPC 调用只存在于本机房。
保证同机房缓存调用:查询缓存发生在本机房,如果没有,则从数据库加载。缓存也是采用主备的方式,数据更新采用多机房更新的方式。
保证同机房数据库查询:和缓存一样,读取本机房的数据库,同样采用主备方式。
5.3 异地多活
同城双活无法做到城市级别的容灾。所以需要考虑异地多活。
比如上海的服务器宕机了,还有重庆的服务器可以顶上来。但两地距离不要太近,因为发生自然灾害时有可能会被另外一地波及到。
和同城双活的核心思想一样,避免跨机房调用。但是因为异地方案中的调用延迟远大于同机房的方案,所以数据同步是一个非常值得探讨的点。提供两种方案:
基于存储系统的主从复制,MySQL 和 Redis 天生就具备。但是数据量很大的情况下,性能是较差的。 异步复制的方式。基于消息队列,将数据操作作为一个消息放到消息队列,另外的机房消费这条消息,操作存储组件。
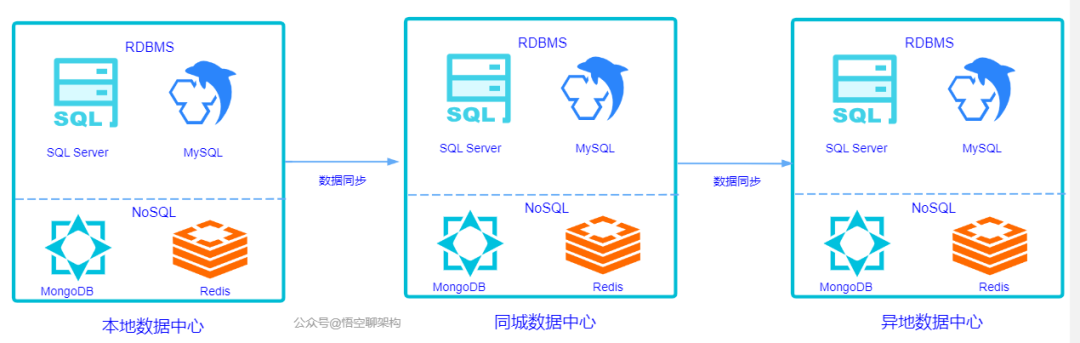
5.4 两地三中心
这个概念也被业界提到过很多次。
两地:本地和异地。
三中心:本地数据中心、同城数据中心、异地数据中心。
这两个概念也就是我上面说的同城双活和异地多活的方式,只是针对的是数据中心。原理如下图所示:
通过 B 站这件事情,我从中也学到了很多,本篇算是抛砖引玉,欢迎大家留言探讨。
巨人的肩膀:
https://cloud.tencent.com/developer/article/1618923
https://mp.weixin.qq.com/s/Vc4N5RcsN-K45o3VaRT4rA
https://time.geekbang.org/column/article/171115
https://time.geekbang.org/column/article/140763
www.passjava.cn
- END -

架构好书推荐

▊《架构整洁之道》
[美] Robert C. Martin 著
孙宇聪 译
鄢倩 校
整洁之道再续新篇
Bob大叔封山之作
熔举世热门架构于一炉
揭通用黄金法则以真言
左耳朵耗子|余晟倾情作序
善用软件架构的通用法则,即可显著提升开发者在所有软件系统全生命周期内的生产力。
(扫码了解本书详情)

▊《业务架构 应用架构 数据架构 实战》
每一页都是实践经验的总结,参考性超强
每一页都简洁明了重点突出,可读性超强
大局+架构+文档,三大篇,操作性超强
(扫码了解本书详情)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐