近期,线上有个重要Mysql客户的表在从5.6升级到5.7后,master上插入过程中出现Duplicate key的错误,而且是在主备及RO实例上都出现。以其中一个表为例,迁移前通过“show create table” 命令查看的auto increment id为1758609, 迁移后变成了1758598,实际对迁移生成的新表的自增列用max求最大值为1758609。用户采用的是Innodb引擎,而且据运维同学介绍,之前碰到过类似问题,重启即可恢复正常。
内核问题排查
由于用户反馈在5.6上访问正常,切换到5.7后就报错。因此,首先得怀疑是5.7内核出了问题,因此第一反应是从官方bug list中搜索一下是否有类似问题存在,避免重复造车。经过搜索,发现官方有1个类似的bug,这里简单介绍一下该bug。Innodb引擎中的auto increment 相关参数及数据结构主要参数包括:innodb_autoinc_lock_mode用于控制获取自增值的加锁方式,auto_increment_increment, auto_increment_offset用于控制自增列的递增的间隔和起始偏移。主要涉及的结构体包括:数据字典结构体,保存整个表的当前auto increment值以及保护锁;事务结构体,保存事务内部处理的行数;handler结构体,保存事务内部多行的循环迭代信息。这部分网上有篇文章介绍的比较好,具体参见:(https://www.cnblogs.com/zengkefu/p/5683258.html)。
背景知识2
mysql及Innodb引擎中对autoincrement访问及修改的流程(1) 数据字典结构体(dict_table_t)换入换出时对autoincrement值的保存和恢复。换出时将autoincrement保存在全局的的映射表中,然后淘汰内存中的dict_table_t。换入时通过查找全局映射表恢复到dict_table_t结构体中。相关的函数为dict_table_add_to_cache及dict_table_remove_from_cache_low。(2) row_import, table truncate过程更新autoincrement。(3) handler首次open的时候,会查询当前表中最大自增列的值,并用最大列的值加1来初始化表的data_dict_t结构体中的autoinc的值。(4) insert流程。相关对autoinc修改的堆栈如下:
ha_innobase::write_row:write_row的第三步中调用handler句柄中的update_auto_increment函数更新auto increment的值
handler::update_auto_increment: 调用Innodb接口获取一个自增值,并根据当前的auto_increment相关变量的值调整获取的自增值;同时设置当前handler要处理的下一个自增列的值。
ha_innobase::get_auto_increment:获取dict_tabel中的当前auto increment值,并根据全局参数更新下一个auto increment的值到数据字典中
ha_innobase::dict_table_autoinc_initialize:更新auto increment的值,如果指定的值比当前的值大,则更新。
handler::set_next_insert_id:设置当前事务中下一个要处理的行的自增列的值。
(5) update_row。对于”INSERT INTO t (c1,c2) VALUES(x,y) ON DUPLICATE KEY UPDATE”语句,无论唯一索引列所指向的行是否存在,都需要推进auto increment的值。相关代码如下:
if (error == DB_SUCCESS
&& table->next_number_field
&& new_row == table->record[0]
&& thd_sql_command(m_user_thd) == SQLCOM_INSERT
&& trx->duplicates) {
ulonglong auto_inc;
……
auto_inc = table->next_number_field->val_int();
auto_inc = innobase_next_autoinc(auto_inc, 1, increment, offset, col_max_value);
error = innobase_set_max_autoinc(auto_inc);
……
}
从我们的实际业务流程来看,我们的错误只可能涉及insert及update流程。BUG 76872 / 88321: InnoDB AUTO_INCREMENT produces same value twice(1) bug概述:当autoinc_lock_mode大于0,且auto_increment_increment大于1时,系统刚重启后多线程同时对表进行insert操作会产生“duplicate key”的错误。(2) 原因分析:重启后innodb会把autoincrement的值设置为max(id) + 1。此时,首次插入时,write_row流程会调用handler::update_auto_increment来设置autoinc相关的信息。首先通过ha_innobase::get_auto_increment获取当前的autoincrement的值(即max(id) + 1),并根据autoincrement相关参数修改下一个autoincrement的值为next_id。当auto_increment_increment大于1时,max(id) + 1 会不大于next_id。handler::update_auto_increment获取到引擎层返回的值后为了防止有可能某些引擎计算自增值时没有考虑到当前auto increment参数,会重新根据参数计算一遍当前行的自增值,由于Innodb内部是考虑了全局参数的,因此handle层对Innodb返回的自增id算出的自增值也为next_id,即将会插入一条自增id为next_id的行。handler层会在write_row结束的时候根据当前行的值next_id设置下一个autoincrement值。如果在write_row尚未设置表的下一个autoincrement期间,有另外一个线程也在进行插入流程,那么它获取到的自增值将也是next_id。这样就产生了重复。(3) 解决办法:引擎内部获取自增列时考虑全局autoincrement参数,这样重启后第一个插入线程获取的自增值就不是max(id) + 1,而是next_id,然后根据next_id设置下一个autoincrement的值。由于这个过程是加锁保护的,其他线程再获取autoincrement的时候就不会获取到重复的值。通过上述分析,这个bug仅在autoinc_lock_mode > 0 并且auto_increment_increment > 1的情况下会发生。实际线上业务对这两个参数都设置为1,因此,可以排除这个bug造成线上问题的可能性。
现场分析及复现验证
既然官方bug未能解决我们的问题,那就得自食其力,从错误现象开始分析了。(1) 分析max id及autoincrement的规律 由于用户的表设置了ON UPDATE CURRENT_TIMESTAMP列,因此可以把所有的出错的表的max id、autoincrement及最近更新的几条记录抓取出来,看看是否有什么规律。抓取的信息如下: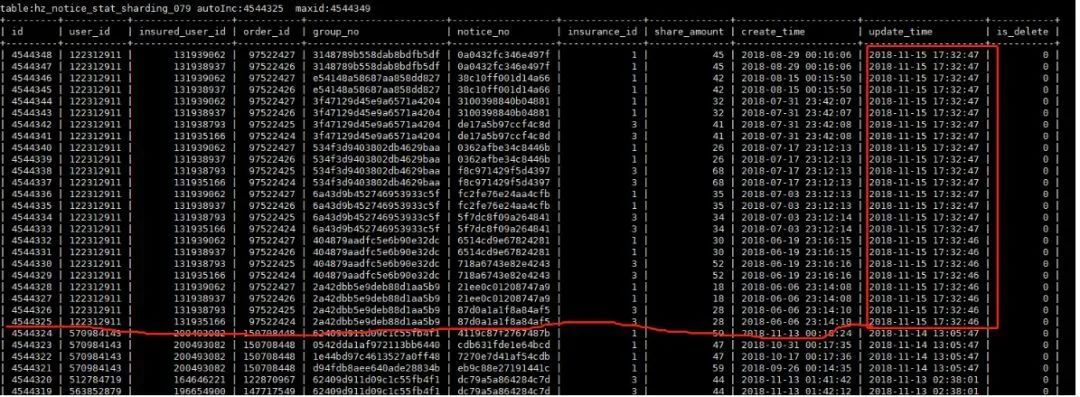 乍看起来,这个错误还是很有规律的,update time这一列是最后插入或者修改的时间,结合auto increment及max id的值,现象很像是最后一批事务只更新了行的自增id,没有更新auto increment的值。联想到【官方文档】中对auto increment用法的介绍,update操作是可以只更新自增id但不触发auto increment推进的。按照这个思路,我尝试复现了用户的现场。复现方法如下:
乍看起来,这个错误还是很有规律的,update time这一列是最后插入或者修改的时间,结合auto increment及max id的值,现象很像是最后一批事务只更新了行的自增id,没有更新auto increment的值。联想到【官方文档】中对auto increment用法的介绍,update操作是可以只更新自增id但不触发auto increment推进的。按照这个思路,我尝试复现了用户的现场。复现方法如下: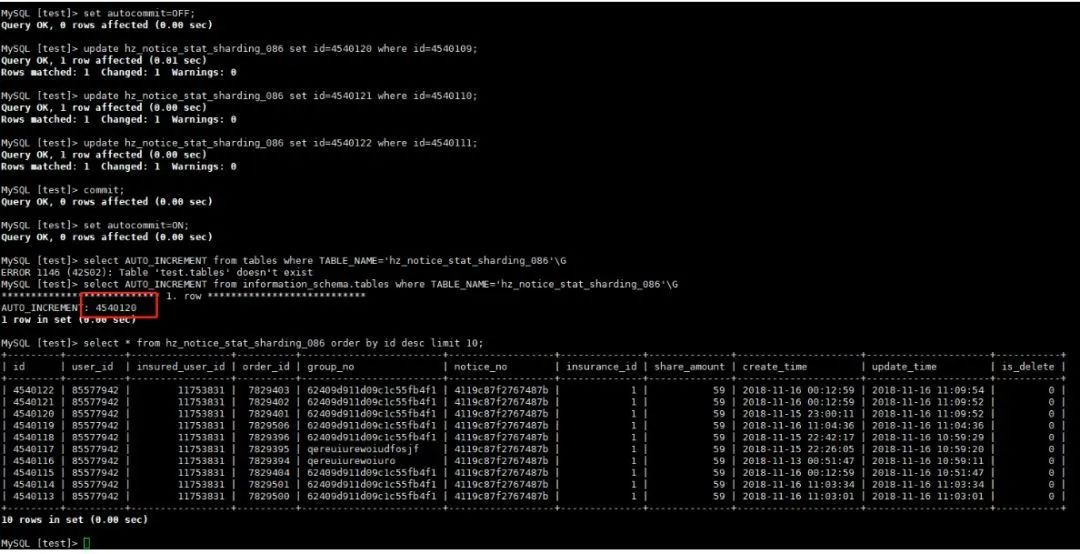 同时在binlog中,我们也看到有update自增列的操作。如图:
同时在binlog中,我们也看到有update自增列的操作。如图: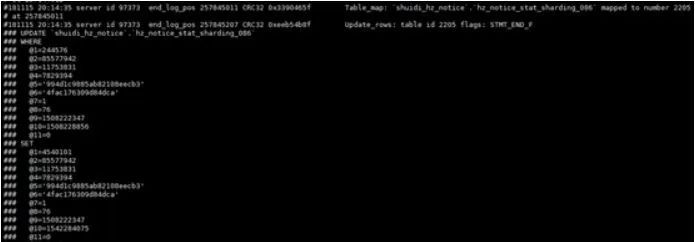 不过,由于binlog是ROW格式,我们也无法判断这是内核出问题导致了自增列的变化还是用户自己更新所致。因此我们联系了客户进行确认,结果用户很确定没有进行更新自增列的操作。
不过,由于binlog是ROW格式,我们也无法判断这是内核出问题导致了自增列的变化还是用户自己更新所致。因此我们联系了客户进行确认,结果用户很确定没有进行更新自增列的操作。
(2) 分析用户的表及sql语句 继续分析,发现用户总共有三种类型的表(hz_notice_stat_sharding, hz_notice_group_stat_sharding,hz_freeze_balance_sharding),这三种表都有自增主键。但是前面两种都出现了autoinc错误,唯独hz_freeze_balance_sharding表没有出错。难道是用户对这两种表的访问方式不一样?抓取用户的sql语句,果然,前两种表用的都是replace into操作,最后一种表用的是update操作。难道是replace into语句导致的问题?搜索官方bug, 又发现了一个疑似bug。bug #87861: “Replace into causes master/slave have different auto_increment offset values”(1) Mysql对于replace into实际是通过delete + insert语句实现,但是在ROW binlog格式下,会向binlog记录update类型日志。Insert语句会同步更新autoincrement,update则不会。(2) replace into在Master上按照delete+insert方式操作, autoincrement就是正常的。基于ROW格式复制到slave后,slave机上按照update操作回放,只更新行中自增键的值,不会更新autoincrement。因此在slave机上就会出现max(id)大于autoincrement的情况。此时在ROW模式下对于insert操作binlog记录了所有的列的值,在slave上回放时并不会重新分配自增id,因此不会报错。但是如果slave切master,遇到Insert操作就会出现”Duplicate key”的错误。(3) 由于用户是从5.6迁移到5.7,然后直接在5.7上进行插入操作,相当于是slave切主,因此会报错。
解决方案
(1) binlog改为mixed或者statement格式(2) 用Insert on duplicate key update代替replace into(1) 在ROW格式下如果遇到replace into语句,则记录statement格式的logevent,将原始语句记录到binlog。(2) 在ROW格式下将replace into语句的logevent记录为一个delete event和一个insert event。(1) autoincrement的autoinc_lock_mode及auto_increment_increment这两个参数变化容易导致出现重复的key,使用过程中要尽量避免动态的去修改。(2) 在碰到线上的问题时,首先应该做好现场分析,明确故障发生的场景、用户的SQL语句、故障发生的范围等信息,同时要对涉及实例的配置信息、binlog甚至实例数据等做好备份以防过期丢失。只有这样才能在找官方bug时精准的匹配场景,如果官方没有相关bug,也能通过已有线索独立分析。 喜欢我可以给我设为星标哦
喜欢我可以给我设为星标哦