
商品库存的扣除过程,如何防止超卖?
点击下方“IT牧场”,选择“设为星标”

作者:iloveoverfly
来源:blog.csdn.net/new_com/article/details/105568124
在商品购买的过程中,库存的抵扣过程,一般操作如下:
select根据商品id查询商品的库存。
根据下单的数量,计算库存是否足够,如果存库不足则抛出库存不足的异常,如果库存足够,则减去扣除的库存得到最新的库存剩余值。
set设置最新的库存剩余值。
上述过程的伪代码如下:
// 根据商品id获取商品剩余库存select stock_remaing from stock_table where id=${goodsId};// 操作库存// 比较库存if(stock_remaing// 抛出库存不足的异常}else{// 抵扣以后的库存值int new_stock=stock_remaing - quantity;}// 根据商品id设置计算后的库存update stock_table set stock_remaing =${new_stock} id=${goodsId};
# 并发修改数据库存超卖
如果数据库事务的隔离级别不是串行化(serializable),根据事务的特性,在并发修改的时候,可能会出现写覆盖的问题。
假设,商品的剩余库存stock_remaing 为100,客户A下单20,客户B下单30,在并发扣库存的时候,可能存在超卖。如果客户A和客户B同时获取剩余库存为100,则会出现事务后提交的值会覆盖前一个客户提交的值,有可能剩余的库存是80或者70。流程如下:
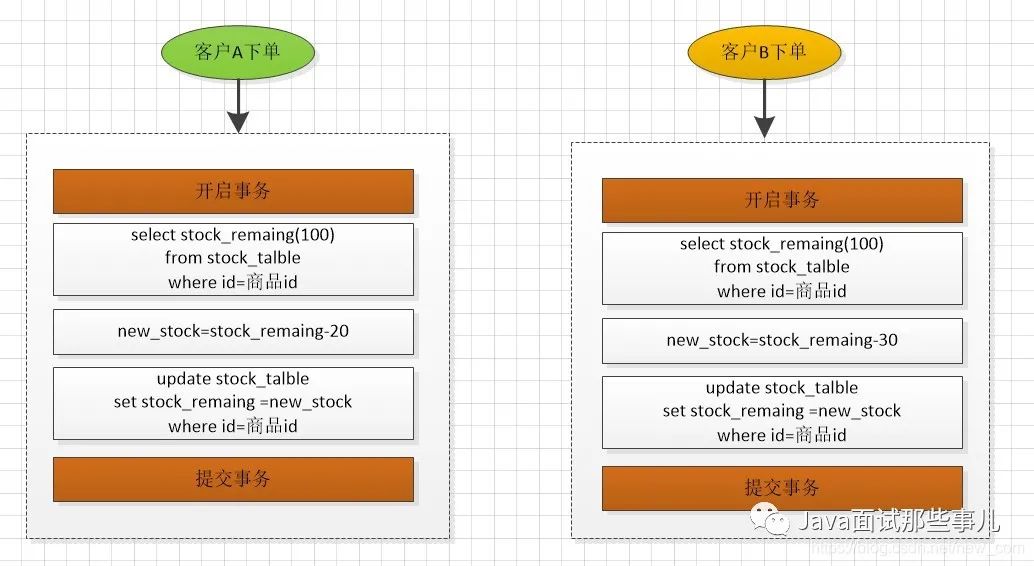
# 加锁更新存库
为了在事务控制中,防止写覆盖,你会想到使用select for update的方式,将该商品的库存锁住,然后执行余下的操作。
流程如下:
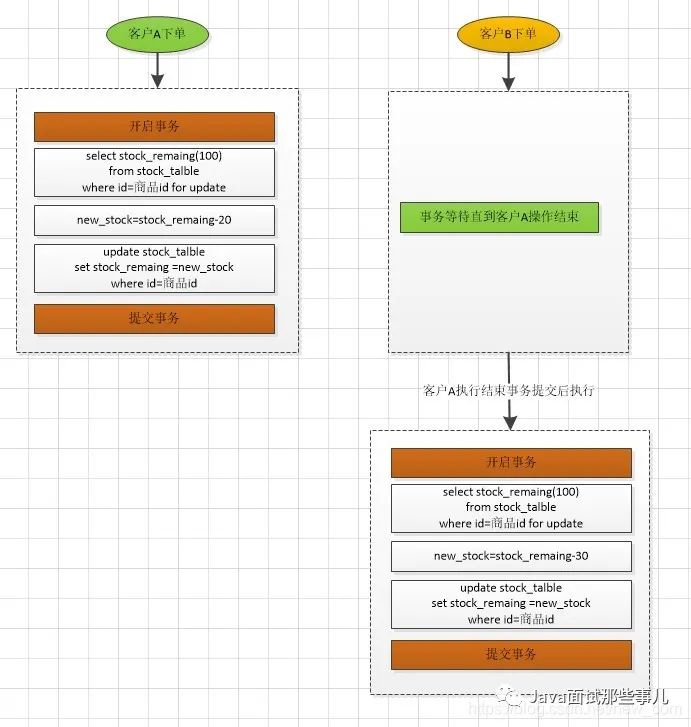
以上,使用悲观锁方式,在分布式服务中,如果并发情况比较高的时候,扣减库存的操作是串行操作,效率很低。
# 使用乐观锁的方式更新
在更新的时候,使用(CAS+版本号更新)+重试条件(重试次数或者重试时间限制)乐观锁的方式更新库存。此时,如果,客户A和客户B同时读取到库存剩余100,在更新的时候,有一个操作会失败。流程如下:

该种方式可以大大提高并发性,也可以保证数据的一致性;通过重试次数和重试时间的条件控制,可以防止过多的重试带来的数据库压力。
# 可以使用直接递减的方式执行么?
在抵扣库存的时候,有的人提议不执行select,计算,set三段式的操作,直接扣减的方式,并且对于扣减到小于零的情况作了判断。伪代码如下:
update stock_table set remaing_stock=remaing_stock-${quantity}where id =商品idand remaing_stock>${quantity};
在分布式服务调用中,因为网络异常,获取服务器异常,可能在微服务调用时,存在服务重试。例如,场景的网关超时,服务重试机制。此时,该种方式不满足幂等性,而存在多扣的情况。例如,同一用户扣减库存时,服务重试,极端情况下,该用户扣减库存操作执行多次,则就出现了商品超卖。
# 可以使用redis进行库存的抵扣么?
由于没有研究过redis源码,对于这种方式参考了大牛的回复,答案是可以使用redis的事务性扣减余额,但在CAS机制上比mysql没有优势,高性能是因为其内存存储的原因,带来的副作用是数据有丢失风险。
干货分享
最近将个人学习笔记整理成册,使用PDF分享。关注我,回复如下代码,即可获得百度盘地址,无套路领取!
•001:《Java并发与高并发解决方案》学习笔记;•002:《深入JVM内核——原理、诊断与优化》学习笔记;•003:《Java面试宝典》•004:《Docker开源书》•005:《Kubernetes开源书》•006:《DDD速成(领域驱动设计速成)》•007:全部•008:加技术群讨论
加个关注不迷路
喜欢就点个"在看"呗^_^