
深度学习之后会是啥?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达



我们为什么和在哪里陷入困境?
需要太多标签化的训练数据。
模型的训练时间太长或者需要太多昂贵的资源,而且还可能根本无法训练。
超参数,尤其是围绕节点和层的超参数,仍然是神秘的。自动化甚至是公认的经验法则仍然遥不可及。
迁移学习,意味着只能从复杂到简单,而不是从一个逻辑系统到另一个逻辑系统。
是什么阻止了我们

看起来像DNN却不是的东西
有一条研究路线与Hinton的反向传播密切相关,即认为节点和层的基本结构是有用的,但连接和计算方法需要大幅修改。

Capsule是一组嵌套的神经层。在普通的神经网络中,你会不断地添加更多的层。在CapsNet中,你会在一个单层内增加更多的层。或者换句话说,把一个神经层嵌套在另一个神经层里面。capsule里面的神经元的状态就能捕捉到图像里面一个实体的上述属性。一个胶囊输出一个向量来代表实体的存在。向量的方向代表实体的属性。该向量被发送到神经网络中所有可能的父代。预测向量是基于自身权重和权重矩阵相乘计算的。哪个父代的标量预测向量乘积最大,哪个父代就会增加胶囊的结合度。其余的父代则降低其结合度。这种通过协议的路由方式优于目前的max-pooling等机制。
多粒度级联森林
只需要训练数据的一小部分。 在您的桌面CPU设备上运行,无需GPU。 训练速度一样快,在许多情况下甚至更快,适合分布式处理。 超参数少得多,在默认设置下表现良好。 依靠容易理解的随机森林,而不是完全不透明的深度神经网。
Pyro and Edward
不像深网的方法
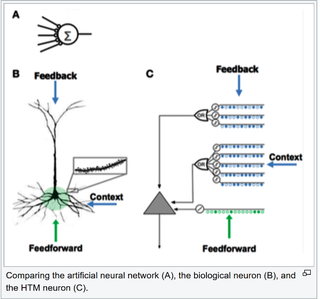
层次时间记忆(HTM)
一些值得注意的渐进式改进
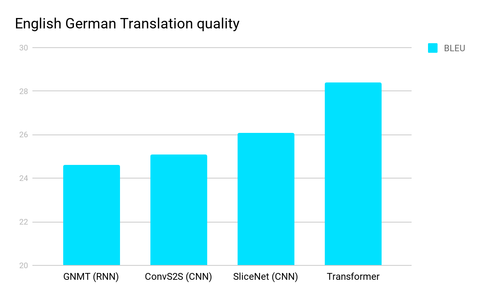
https://www.datasciencecentral.com/profiles/blogs/what-comes-after-deep-learning
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论