
正值高考,用AI写2022高考作文题试试
关注涛涛CV,设置星标,更新不错过


 基于EAST、CRNN、Bert和GPT-2语言模型的高考作文生成AI 支持bert tokenizer,当前版本基于clue chinese vocab 17亿参数多模块异构深度神经网络,超2亿条预训练数据 线上点击即用的文本生成效果demo:17亿参数作文杀手 端到端生成,从试卷识别到答题卡输出一条龙服务
基于EAST、CRNN、Bert和GPT-2语言模型的高考作文生成AI 支持bert tokenizer,当前版本基于clue chinese vocab 17亿参数多模块异构深度神经网络,超2亿条预训练数据 线上点击即用的文本生成效果demo:17亿参数作文杀手 端到端生成,从试卷识别到答题卡输出一条龙服务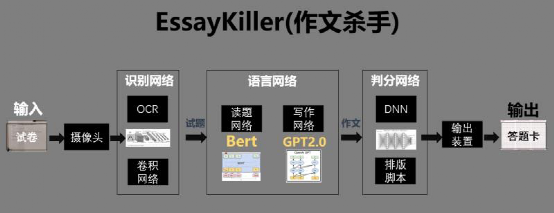

复用BERT_SUM生成Top3的NER粒度token作为标题
高考议论文的写作格式要求。
模型 | 参数量 | 下载链接 | 备注 |
EAST | < 0.1 Billion | GoogleDrive | 检测模型 |
CRNN | < 0.1 Billion | 网盘链接 提取码:vKeD | 识别模型 |
BERT | 0.1 Billion | GoogleDrive | 摘要模型 |
GPT-2 | 1.5 Billion | GoogleDrive | 生成模型 |
整个AI的参数量分布不均匀,主要原因在于,这是一个语言类AI,99%的参数量集中在语言网络中,其中GPT-2(15亿)占88%,BERT(1.1亿)占7%,其他的识别网络和判分网络共占5%。
总结:
课程:
《机器视觉:应用讲解》,一总体概述,二相机篇,三镜头篇,四光源篇,五光学系统选型,六视觉开发软件,七相机标定技术,八项目案例解析,九视觉公司分析,十产业发展情况
笔记:
《智能革命》《人工智能》《AI•未来》《好好赚钱》《韭菜的自我修养》读书笔记
行业:
服务机器人公司,机器视觉公司,自动驾驶公司,ADAS公司总结, 防疫机器人发展,腾讯未来交通
SLAM:
Vslam方案+源码,语义SLAM与深度相机,SLAM和导航避障,视觉SLAM总结
秦学英《三维物体的识别与跟踪》,章国锋《视觉SLAM》,申抒含《基于图像的三维建模》,姜翰青《RGB -D SLAM》记录笔记
机器视觉:
毫米波雷达,雷达视觉融合,2021视觉研讨会,2020上海研讨会,双目和激光的三维重建,2021视觉市场研究,太阳能行业应用
机器视觉基本概念笔记,记录五,记录四,记录三,记录二,记录一
图像处理:
图像处理基本概念笔记,记录八,记录七,记录六 ,记录五,记录四 ,记录三,记录二 ,记录二,记录一
欢迎支持,点击在看,分享
评论