
SpringCloud 常见注册中心的比较
一、概述
springcloud是一个非常优秀的微服务框架,要管理众多的服务,就需要对这些服务进行治理,也就是我们说的服务治理,服务治理的作用就是在传统的rpc远程调用框架中,管理每个服务与每个服务之间的依赖关系,可以实现服务调用、负载均衡、服务容错、以及服务的注册与发现。
如果微服务之间存在调用依赖,就需要得到目标服务的服务地址,也就是微服务治理的服务发现。要完成服务发现,就需要将服务信息存储到某个载体,载体本身即是微服务治理的服务注册中心,而存储到载体的动作即是服务注册。
springcloud支持的注册中心有Eureka、Zookeeper、Consul、Nacos
| 组件名称 | 所属公司 | 组件简介 |
|---|---|---|
| Eureka | Netflix | springcloud最早的注册中心,目前已经进入停更进维了 |
| Zookeeper | Apache | zookeeper是一个分布式协调工具,可以实现注册中心功能 |
| Consul | Hashicorp | Consul 简化了分布式环境中的服务的注册和发现流程,通过 HTTP 或者 DNS 接口发现。支持外部 SaaS 提供者等。 |
| Nacos | Alibaba | Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。 |
1.1 eureka
Spring Cloud Netflix 在设计 Eureka 时就紧遵AP原则,Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。在这种架构风格中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。
在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务;
Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用);
当网络稳定时,当前实例新注册的信息会被同步到其它节点中;
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使得整个注册服务瘫痪
Eureka保证高可用(A)和最终一致性:
服务注册相对要快,因为不需要等注册信息replicate到其他节点,也不保证注册信息是否replicate成功
当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性。
1.2 zookeeper
与 Eureka 有所不同,Apache Zookeeper 在设计时就紧遵CP原则,即任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是 Zookeeper 不能保证每次服务请求都是可达的。从 Zookeeper 的实际应用情况来看,在使用 Zookeeper 获取服务列表时,如果此时的 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,又或者 Zookeeper 集群中半数以上服务器节点不可用(例如有三个节点,如果节点一检测到节点三挂了 ,节点二也检测到节点三挂了,那这个节点才算是真的挂了),那么将无法处理该请求。所以说,Zookeeper 不能保证服务可用性。
1.3 consul
Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X)。Consul 内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其他工具(比如 ZooKeeper 等),使用起来也较为简单。
Consul 遵循CAP原理中的CP原则,保证了强一致性和分区容错性,且使用的是Raft算法,比zookeeper使用的Paxos算法更加简单。虽然保证了强一致性,但是可用性就相应下降了,例如服务注册的时间会稍长一些,因为 Consul 的 raft 协议要求必须过半数的节点都写入成功才认为注册成功 ;在leader挂掉了之后,重新选举出leader之前会导致Consul 服务不可用。
Consul强一致性(C)带来的是:
服务注册相比Eureka会稍慢一些。因为Consul的raft协议要求必须过半数的节点都写入成功才认为注册成功
Leader挂掉时,重新选举期间整个consul不可用。保证了强一致性但牺牲了可用性。
1.4 Nacos
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。Nacos除了服务的注册发现之外,还支持动态配置服务。动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。一句话概括就是Nacos = 注册中心 + 配置中心。
二、功能异同
这四个组件虽然都实现了注册中心的功能,但是他们的功能和实现方式都有不同的地方,也各有各的优点,单从注册中心方面来比价四个注册中心(如果不了解CAP定理可先阅读下一章节):
2.1 基本实现不同
官网地址
eureka: https://github.com/Netflix/eureka
zookeeper: https://zookeeper.apache.org/
consul: https://www.consul.io/
nacos: https://nacos.io/zh-cn/| 组件名称 | 实现语言 | CAP | 健康检查 |
|---|---|---|---|
| Eureka | Java | AP | 可配 |
| Zookeeper | Java | CP | 支持 |
| Consul | Golang | CP | 支持 |
| Nacos | Java | AP | 支持 |
eureka就是个servlet程序,跑在servlet容器中; Consul则是go编写而成。
2.2 功能支持度不同
| Nacos | Eureka | Consul | CoreDNS | Zookeeper | |
|---|---|---|---|---|---|
| 一致性协议 | CP+AP | AP | CP | — | CP |
| 健康检查 | TCP/HTTP/MYSQL/Client Beat | Client Beat | TCP/HTTP/gRPC/Cmd | — | Keep Alive |
| 负载均衡策略 | 权重/metadata/Selector | Ribbon | Fabio | RoundRobin | — |
| 雪崩保护 | 有 | 有 | 无 | 无 | 无 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 不支持 | 支持 |
| 访问协议 | HTTP/DNS | HTTP | HTTP/DNS | DNS | TCP |
| 监听支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 多数据中心 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 跨注册中心同步 | 支持 | 不支持 | 支持 | 不支持 | 不支持 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| Dubbo集成 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| K8S集成 | 支持 | 不支持 | 支持 | 支持 | 不支持 |
三、CAP定理
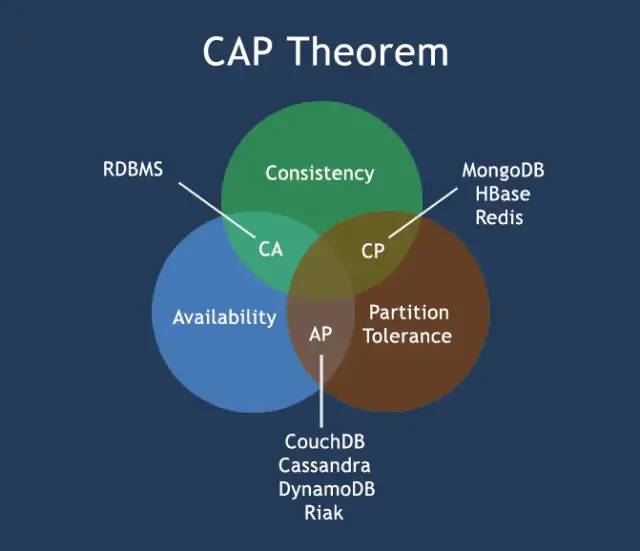
cap定理
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。参考 阮一峰博客。
Consistency 一致性:所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)Availability 可用性:在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)Partition Tolerance 容错性:以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP原则的精髓就是要么AP,要么CP,要么AC,但是不存在CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时C和P两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了CP系统,但是CAP不可同时满足。
因此在进行分布式架构设计时,必须做出取舍。当前一般是通过分布式缓存中各节点的最终一致性来提高系统的性能,通过使用多节点之间的数据异步复制技术来实现集群化的数据一致性。通常使用类似 memcached 之类的 NOSQL 作为实现手段。虽然 memcached 也可以是分布式集群环境的,但是对于一份数据来说,它总是存储在某一台 memcached 服务器上。如果发生网络故障或是服务器死机,则存储在这台服务器上的所有数据都将不可访问。由于数据是存储在内存中的,重启服务器,将导致数据全部丢失。当然也可以自己实现一套机制,用来在分布式 memcached 之间进行数据的同步和持久化,但是实现难度是非常大的
CAP定理关注的粒度是数据,而不是整体的架构。
例如,根据CAP定理将NoSql数据分成了满足CA原则、满足CP原则和满足AP原则的三大类:
CA-单点集群,满足一致性可用性的系统,扩展能力不强CP-满足一致性和容错性系统,性能不高AP-满足可用性、容错性的系统,对一致性要求低一些。

喜欢,在看