
一个「PPT」框架,让超大模型调参变简单:清华刘知远、黄民烈团队力作
视学算法报道
机器之心编辑部
来自清华大学的刘知远、黄民烈等研究者提出了一个名为「PPT」的新框架。PPT=Pre-trained Prompt Tuning。

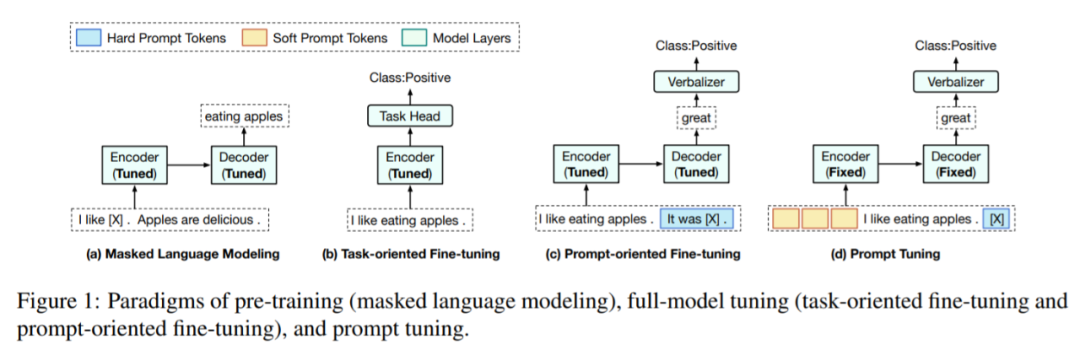

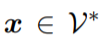 及其标签
及其标签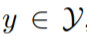 ,首先应用模式映射
,首先应用模式映射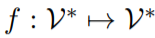 将 x 转换为一个新的 token 序列 f(x),其中 V 是 PLM 的词汇表。f(x)不仅添加了一些 prompt token 作为提示,还保留了至少一个 masking token <X>,让 PLM 预测掩码位置的 token。接下来,使用一个 verbalizer
将 x 转换为一个新的 token 序列 f(x),其中 V 是 PLM 的词汇表。f(x)不仅添加了一些 prompt token 作为提示,还保留了至少一个 masking token <X>,让 PLM 预测掩码位置的 token。接下来,使用一个 verbalizer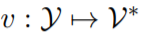 将 y 映射到一个标签 token 序列 v(y)。借助 f(·)和 v(·),分类任务可以用 pattern-verbalizer 对 (f, v) 来表示:
将 y 映射到一个标签 token 序列 v(y)。借助 f(·)和 v(·),分类任务可以用 pattern-verbalizer 对 (f, v) 来表示: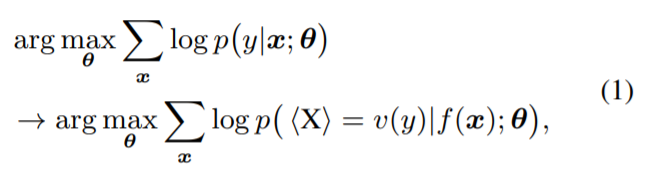
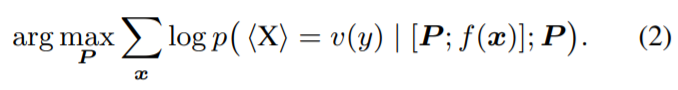

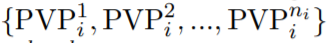 ,其中,
,其中,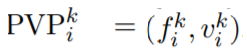 。针对每个组,研究者设计了一个对应的预训练任务
。针对每个组,研究者设计了一个对应的预训练任务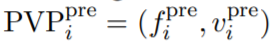 ,在这些预训练任务上预训练了 soft prompt 之后(所有模型参数固定),研究者得到 m 个预训练 prompt:{P_1, P_2, ..., P_m}。在预训练之后,对于 T_i 中的每个任务
,在这些预训练任务上预训练了 soft prompt 之后(所有模型参数固定),研究者得到 m 个预训练 prompt:{P_1, P_2, ..., P_m}。在预训练之后,对于 T_i 中的每个任务 ,研究者继续优化式(2),使用 P_i 作为 soft prompt 的初始化。
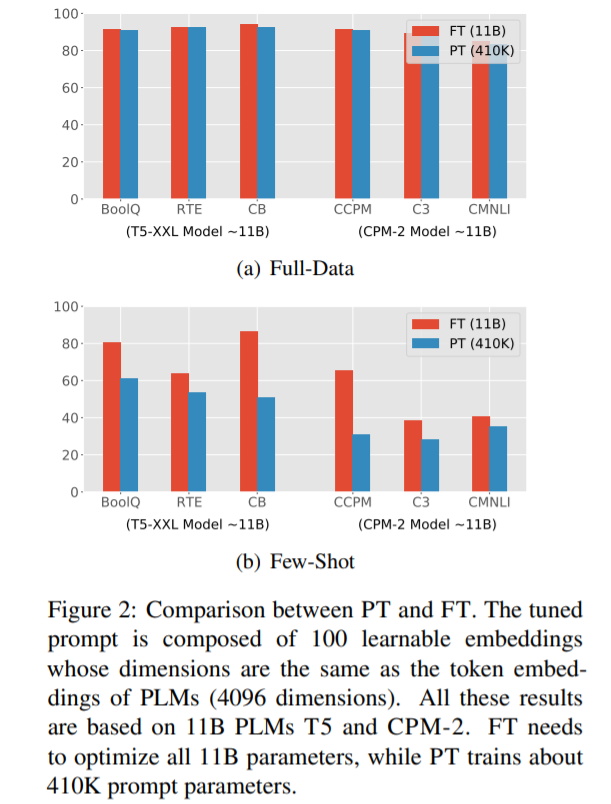
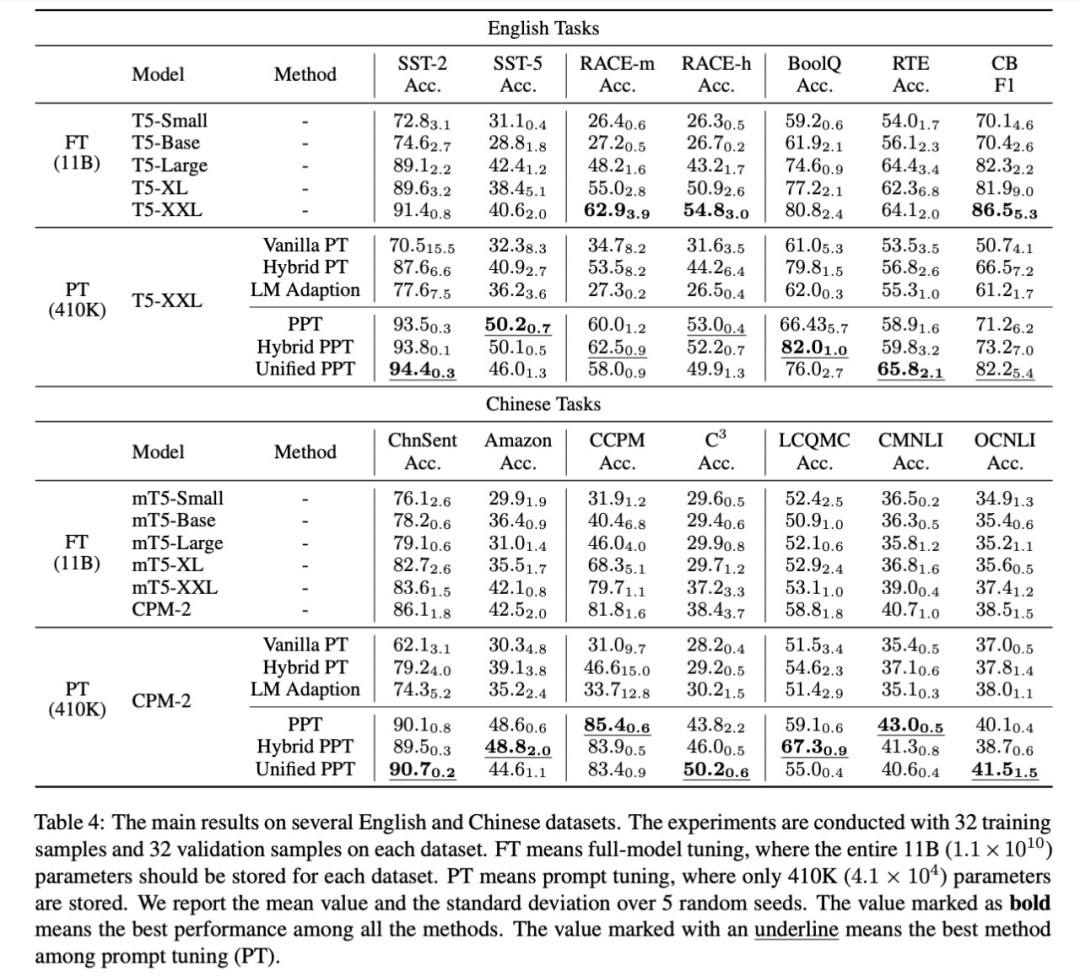
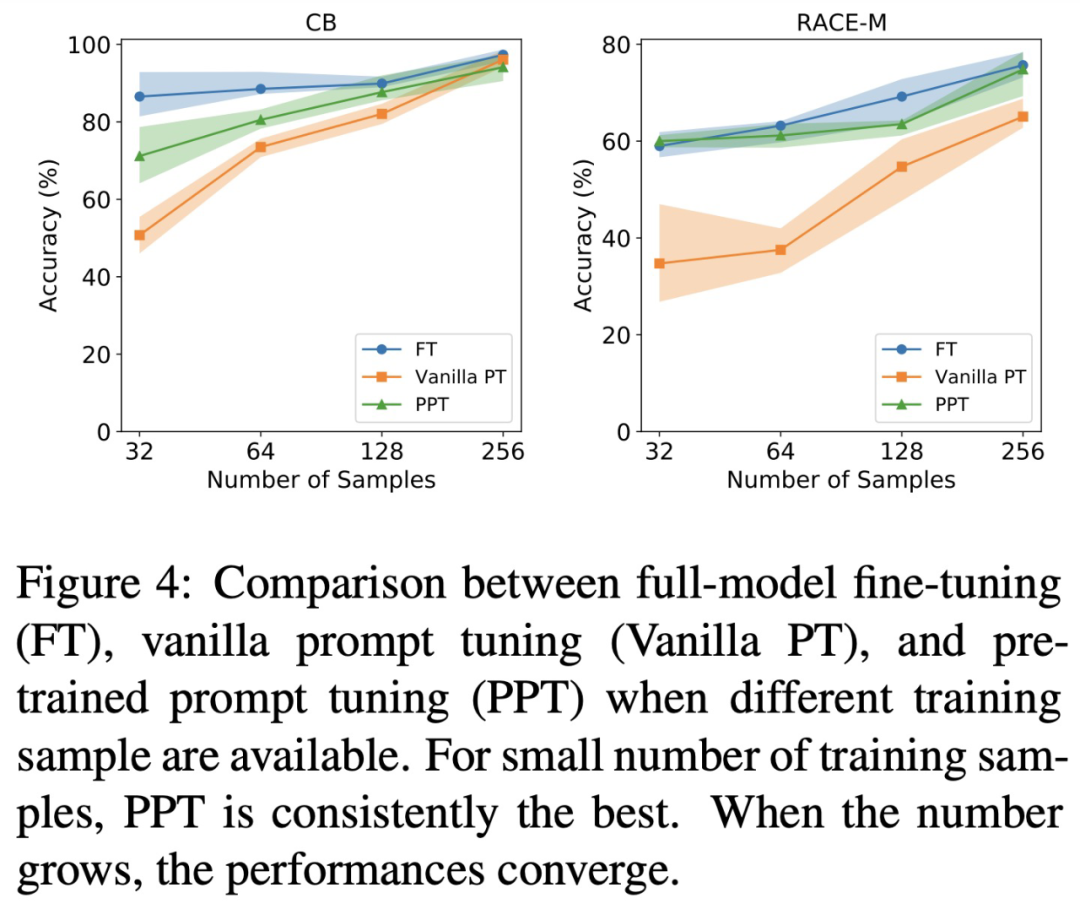
,研究者继续优化式(2),使用 P_i 作为 soft prompt 的初始化。随着参数数量的增加,FT 的性能有所提升。
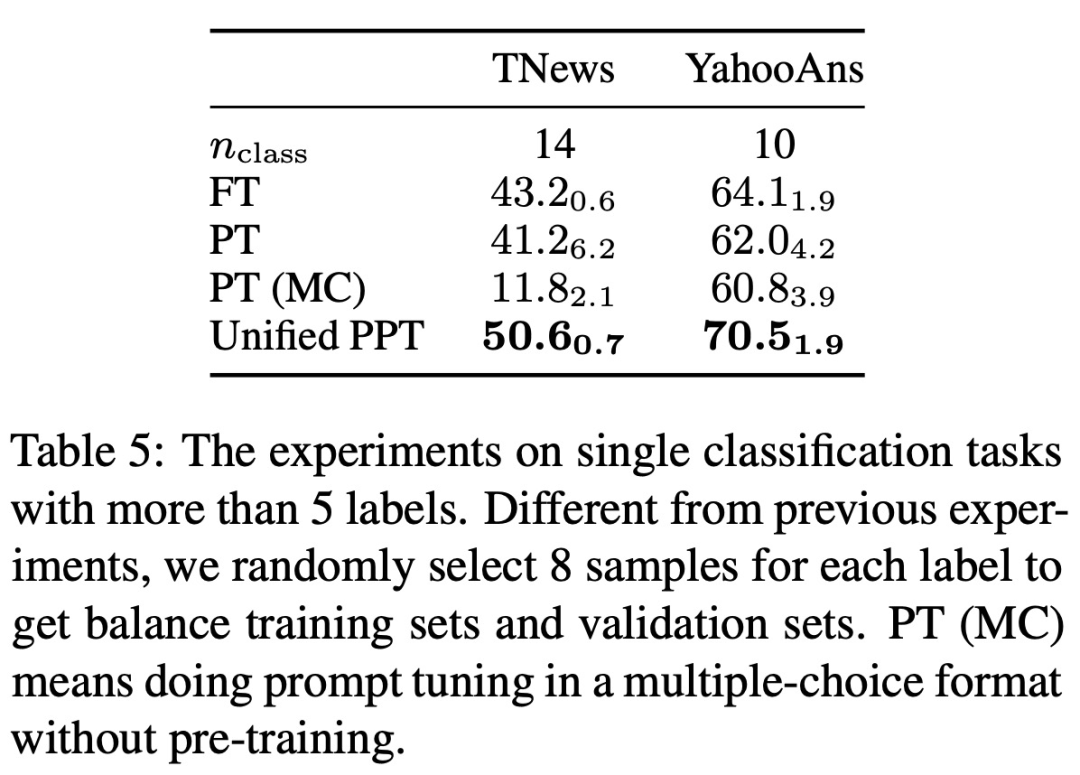
在大多数数据集中,PPT 明显优于 Vanilla PT 和 LM Adaption。
PPT 在所有中文数据集和大多数英文数据集上都优于 10B 模型的 FT。
PPT 在大多数数据集上会产生较小的方差,相比之下,一般的 few-shot 学习常存在不稳定性,例如 Vanilla PT。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论