
通过小实例讲解 base64 原理
作者: 黄鹂
详解 base64 原理
案例:'鹅' --> 经过base64编码 --> 6bmF
那它怎么编码的呢?
以 '鹅' 字为例
base64 对应的编码表: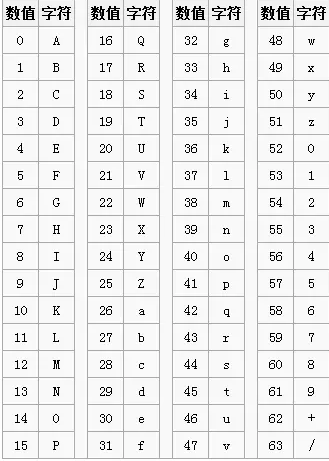 **字符串转base64的转码规则:第一步,将每三个字节作为一组,一共是24个二进制位。第二步,将这24个二进制位分为四组,每个组有6个二进制位。第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节。第四步,根据上表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
**字符串转base64的转码规则:第一步,将每三个字节作为一组,一共是24个二进制位。第二步,将这24个二进制位分为四组,每个组有6个二进制位。第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节。第四步,根据上表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
异常情况处理(如果字节不足三的情况)
二个字节的情况:将这二个字节的一共16个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个0以外,后面也要加两个0。这样得到一个三位的Base64编码,再在末尾补上一个"="号。 一个字节的情况:将这一个字节的8个二进制位,按照上面的规则转成二组,最后一组除了前面加二个0以外,后面再加4个0。这样得到一个二位的Base64编码,再在末尾补上两个"="号。
使用 node 的 buffer 进行处理:
demo1.js
const CHARTS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
function encode(str) {
let buf = Buffer.from(str);
let result = '';
let suffix = '';
for (let b of buf) {
result += b.toString(2).padStart(8, 0)
}
if ((result.length % 6) === 4) { // 一个字节的情况
suffix = '=';
result += '00';
}
if ((result.length % 6) === 2) { // 剩余两个字节的情况
suffix = '==';
result += '0000';
}
return result.match(/(\d{6})/g).map(val => parseInt(val, 2)).map(val => CHARTS[val]).join('') + suffix
}
function decode(str) {
var result = '';
for (let b of str) {
if(b==='=') break;
result += (CHARTS.indexOf(b)).toString(2).padStart(6, 0)
}
var list = result.match(/(\d{8})/g).map((number)=>{
return parseInt(number, 2)
})
return Buffer.from(list).toString('utf8')
}
var ss = encode('朱昆m');
console.log(ss) // 5pyx5piGbQ==
console.log(decode(ss)) // 朱昆m
上述代码阐述的编解码的过程。但是如果去看第三方库的代码,会发现还是看不懂的~
为什么会看不懂了?
原因:
为了兼容浏览器的Unicode编码,需要先对Unicode进行编解码。 引入二进制操作,提高位操作效率;
举例:

鹅 -> Unicode字符集(40517 十进制) -> 0b1001 1110 0100 0101(二进制) 鹅 -> utf8编码(15317381 十进制) -> 0b1110 1001 1011 1001 1000 0101(二进制)
Unicode转utf8:
将高位字节的高四位,与1110 形成一个新字节。 将高位字节的低四位,与低位字节的高两位,与10形成一个新字节 将地位字节的低六位与10 形成一个新字节。 三个新字节按顺序排布,形成一个新的编码,就是utf编码。
utf8转Unicode:将上述的顺序翻转。就可以返回新的Unicode编码。
let _keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
console.log(decode(encode('鹅')))
function encode(input) {
var output = "";
var chr1, chr2, chr3, enc1, enc2, enc3, enc4;
var i = 0;
// 将Unicode,变成 utf8
input = _utf8_encode(input);
// 将utf8 转成 base64
while (i < input.length) {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4);
}
return output;
}
function decode(input) {
var output = "";
var chr1, chr2, chr3;
var enc1, enc2, enc3, enc4;
var i = 0;
input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "");
//将base64转化成utf8
while (i < input.length) {
enc1 = _keyStr.indexOf(input.charAt(i++));
enc2 = _keyStr.indexOf(input.charAt(i++));
enc3 = _keyStr.indexOf(input.charAt(i++));
enc4 = _keyStr.indexOf(input.charAt(i++));
chr1 = (enc1 << 2) | (enc2 >> 4);
chr2 = ((enc2 & 15) << 4) | (enc3 >> 2);
chr3 = ((enc3 & 3) << 6) | enc4;
output = output + String.fromCharCode(chr1);
if (enc3 != 64) {
output = output + String.fromCharCode(chr2);
}
if (enc4 != 64) {
output = output + String.fromCharCode(chr3);
}
}
// 将utf8转成浏览器认识的Unicode
output = _utf8_decode(output);
return output;
}
function _utf8_encode(string) { // 将Unicode,变成 utf8
string = string.replace(/\r\n/g, "\n");
var utftext = "";
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n);
if (c < 128) {
utftext += String.fromCharCode(c);
} else if ((c > 127) && (c < 2048)) {
utftext += String.fromCharCode((c >> 6) | 192);
utftext += String.fromCharCode((c & 63) | 128);
} else {
utftext += String.fromCharCode((c >> 12) | 0b11100000);
utftext += String.fromCharCode(((c >> 6) & 0b111111) | 0b10000000);
utftext += String.fromCharCode((c & 0b111111) | 0b10000000);
}
}
return utftext;
}
function _utf8_decode(utftext) { // 将utf8转成Unicode
var string = "";
var i = 0;
var c = c1 = c2 = 0;
while (i < utftext.length) {
c = utftext.charCodeAt(i); // 第一个字节
if (c < 128) {
string += String.fromCharCode(c);
i++;
} else if ((c > 191) && (c < 224)) {
c2 = utftext.charCodeAt(i + 1);
string += String.fromCharCode(((c & 31) << 6) | (c2 & 63));
i += 2;
} else {
c2 = utftext.charCodeAt(i + 1); // 第一个字节
c3 = utftext.charCodeAt(i + 2); // 第二个字节
string += String.fromCharCode(((c & 0b1111) << 12) | ((c2 & 0b111111) << 6) | (c3 & 0b111111));
i += 3;
}
}
return string;
}
重点:上述代码中,明白二进制的移位操作,和Unicode码的转码规则。理解起来难度就不大了。
解释:
Unicode字符集 相当于 字和词的汇总,相当于语言的概念; utf8编码 是一种编码格式, 相当于汉语,英语的概念。 鹅 在汉语中叫 '鹅',在 英语中叫 'goose' 汉语,英语放在计算机里面就相当于一种编码,类似utf8,gbk。
参考文档:
Base64原理程序员必备:
彻底弄懂常见的7种中文字符编码
Unicode 和 UTF-8 有什么区别base64笔记
| 文本 | 鹅 | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| utf8编码 | e9 | b9 | 85 | |||||||||||||||||||||
| 二进制 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| base64索引 | 58 | 27 | 38 | 5 | ||||||||||||||||||||
| base64编码 | 6 | b | m | F | ||||||||||||||||||||
1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入高级前端交流群!「在这里有好多 前端 开发者,会讨论 前端 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持
评论