
如何阅读源码 —— 以 Vetur 为例
作者:范文杰
简介:字节跳动前端工程师
来源:SegmentFault 思否社区
我很早就意识到,能熟练、高效阅读开源前端框架源码是成为一个高级前端工程师必须具备的基本技能之一,所以在我职业生涯的最早期,就已经开始做了很多次相关的尝试,但结果通常都以失败告终,原因五花八门:
缺乏必要的背景知识,犹如阅读天书
不理解项目架构、设计理念,始终不得要领
目标不够聚焦,阅读过程容易复杂化
容易陷入细节,在不重要的问题上纠结半天
容易追着分支流程跑,分散注意力
没有及时记录笔记和总结,没有把知识碾碎、重组、内化成自己的东西
没有处理过特别复杂问题的经历,潜在的不自信心理
个人毅力、韧性不足,或者目标感不够强烈,遇到困难容易放弃
等等
弄清楚目标
为了增进对框架的认知深度,提升个人能力
为了应对面试
为了解决当下某个棘手的 bug 或性能问题
基于某些原因,需要对框架做二次改造
反正闲着,也不知道该学点啥,试试呗。。。
好奇
当下确实需要以阅读源码的方式增进自己对框架的认知深度吗?有没有一些更轻量级,迭代速度更快的学习方式?
你所选定的框架,其复杂度、技术难度是否与你当下的能力匹配?最好的状态是你自认为踮踮脚就能够到,过高,不具有可行性;过低,ROI 不值当。
阅读技巧
了解背景知识
优质参考资料 —— 收集一波质量较高的学习资料,收集过程可以同步通读一遍
框架是如何运行的 —— 也就是所谓的入口
IO —— 框架如何与外部交互?它通常接受什么形态的运行参数?输出什么形式的结果?
生态 —— 优秀的框架背后通常都带有一套成熟的生态系统,例如 Vue,框架衍生品如何补齐框架本身的功能缺失?它们以何种方式,以什么样的 IO 与主框架交互?遵循怎么样的写法规则?
如何断点调试 —— 这几乎是最有效的分析方法,断点调试能够帮助你细致地了解每一行代码的作用。
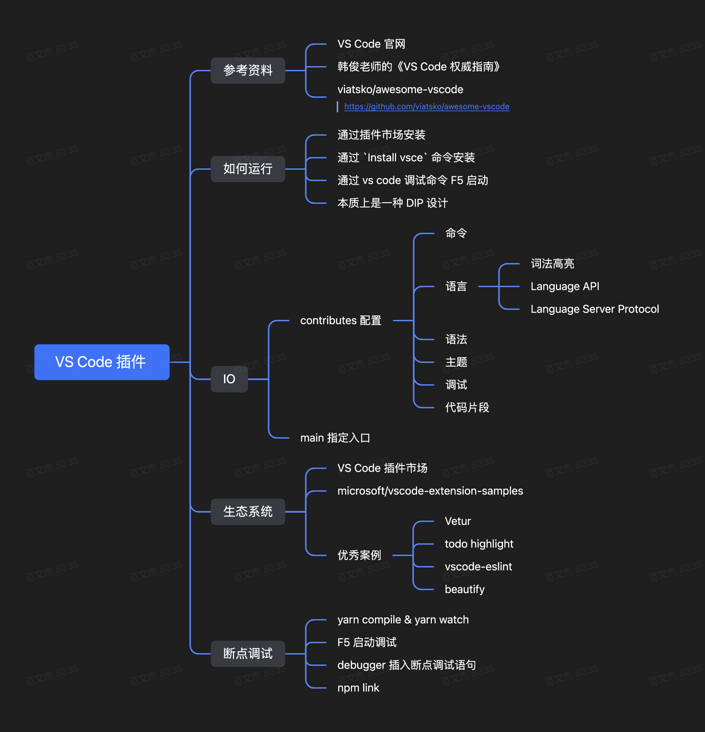
怎么写插件:通过 package.json 文件的 contributes 、main 等属性,声明插件的功能与入口
怎么运行:开发阶段使用 F5 启动调试
怎么编写语言特性:使用 词法高亮、Language API、Language Server Protocol 三类技术实现
六步循环分析
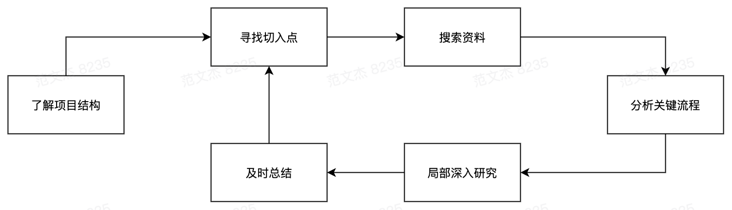
理解项目结构
寻找合适的切入点
就着切入点查阅文章资料
就着切入点分析代码流程
局部深入研究
及时总结
之后,再继续设定切入点,重复执行上述流程直到透彻地理解了问题
理解项目结构
分析项目入口
分析项目依赖了哪些基础工具,包括编译工具,如 webpack、Typescript、babel;基础库,如 lodash、tapable、snabbdom。
将项目中重要文件夹、文件逐一列举出来,理解它们如何按照依赖关系组成一个整体的架构。
入口分析
contributes.languages 指定语言配置文件
contributes.grammars 指定语法配置文件
"main": "./dist/vueMain.js" 指定插件执行入口
探索 contributes.languages 配置
{
// ...
"contributes": {
"languages": [
{
"id": "vue",
"configuration": "./languages/vue-language-configuration.json"
},
{
"id": "vue-html",
"configuration": "./languages/vue-html-language-configuration.json"
}
// ...
]
}
// ...
}这里回过头翻一下 VS Code 对 [contributes.languages] 的解释:
{
"comments": {
// symbol used for single line comment. Remove this entry if your language does not support line comments
"lineComment": "//",
// symbols used for start and end a block comment. Remove this entry if your language does not support block comments
"blockComment": [
"/*",
"*/"
]
},
// ...
}
翻阅参考资料,理解 contributes.languages 配置的作用
打开对应入口文件,猜测各个配置项的作用
继续翻阅参考资料,或者修改配置,验证猜想
探索 contributes.grammars 配置
{
"contributes": {
"grammars": [
{
"language": "vue",
"scopeName": "source.vue",
"path": "./syntaxes/vue-generated.json",
"embeddedLanguages": {
"text.html.basic": "html",
// ...
}
},
{
"language": "vue-postcss",
"scopeName": "source.css.postcss",
"path": "./syntaxes/vue-postcss.json"
}
// ...
]
}
}
language:语言的名称
scopeName:语言的分类,与 TextMate scopeName 同义,可用于嵌套语法定义
path:语言的词法规则文件
{
"name": "Vue HTML",
"scopeName": "text.html.vue-html",
"fileTypes": [],
"uuid": "ca2e4260-5d62-45bf-8cf1-d8b5cc19c8f8",
"patterns": [
// ...
{
"name": "meta.tag.any.html",
"begin": "(<)([A-Z][a-zA-Z0-9:-]*)(?=[^>]*></\\2>)",
"beginCaptures": {
"1": {
"name": "punctuation.definition.tag.begin.html"
},
"2": {
"name": "support.class.component.html"
}
}
}
],
"repository": {
// ...
}
}
探索 main 配置
"main": "./dist/vueMain.js"
import vscode from 'vscode';
export async function activate(context: vscode.ExtensionContext) {
// ... 启动逻辑
}
调用 registerXXXCommands 方法注册一系列命令
调用 initializeLanguageClient 方法初始化 LSP Client 对象
小结
Vetur 本质上是一个 VS Code 插件,所有配置 —— 包括入口都记录在 package.json 文件中
Vetur 包含三种启动入口:
contributes.languages:定义一些简单的语言基本配置,包括怎么折叠,怎么注释
contributes.grammars:定义了一套基于 TextMate 引擎的词法规则,用于实现代码高亮
main:定义了插件的启动入口,入口中注册了一系列命令,同时创建了基于 LSP 协议的 Language Client 对象,而 LSP 协议用于实现如代码补全、错误诊断、跳转定义等高级特性
基础依赖分析
VS Code 插件配置信息,大体上在上一节都有描述,这里不展开
工程化命令,核心有:
watch:对应命令为 rollup -c rollup.config.js -w ,由此可以推断 Vetur 基于 Rollup 实现构建
compile:功能与 watch 相似
lint:对应命令为 tslint -c tslint.json **.ts ,由此可以推断 Vetur 基于 tslint 实现代码检查
项目的 devDependencies 依赖,主要包含 typescript、tslint、rollup、vscode-languageclient、husky、mocha、vscode-test、prettier
Vetur 使用 Rollup + typescript 等工具执行构建工作,按常理执行 yarn watch 命令应该就能启动一个持续的构建工作进程
Vetur 使用 tslint 实现代码检查,配合 huscky + prettier 完成格式化工作
Vetur 使用 mocha + vscode-test 实现自动化测试
文件结构
vetur
├─ .vscode
│ ├─ ...
├─ build
│ ├─ ...
├─ client
│ ├─ client.ts
│ ├─ commands
│ │ ├─ ...
│ ├─ grammar.ts
│ ├─ ...
├─ languages
│ ├─ vue-html-language-configuration.json
│ ├─ ...
├─ scripts
│ ├─ build_grammar.ts
│ └─ tsconfig.json
├─ server
│ ├─ .gitignore
│ ├─ .mocharc.yml
│ ├─ .npmrc
│ ├─ bin
│ │ └─ vls
│ ├─ package.json
│ ├─ rollup.config.js
│ ├─ src
│ │ ├─ ...
├─ syntaxes
│ ├─ markdown-vue.json
│ ├─ pug
│ │ ├─ ...
│ ├─ ...
│ └─ vue.yaml
├─ test
│ ├─ ...
├─ vti
│ ├─ README.md
│ ├─ bin
│ │ └─ vti
│ ├─ package.json
│ ├─ rollup.config.js
│ ├─ src
│ │ ├─ ...
│ ├─ tsconfig.json
│ └─ yarn.lock
├─ tsconfig.options.json
├─ package.json
├─ ...
└─ yarn.lock
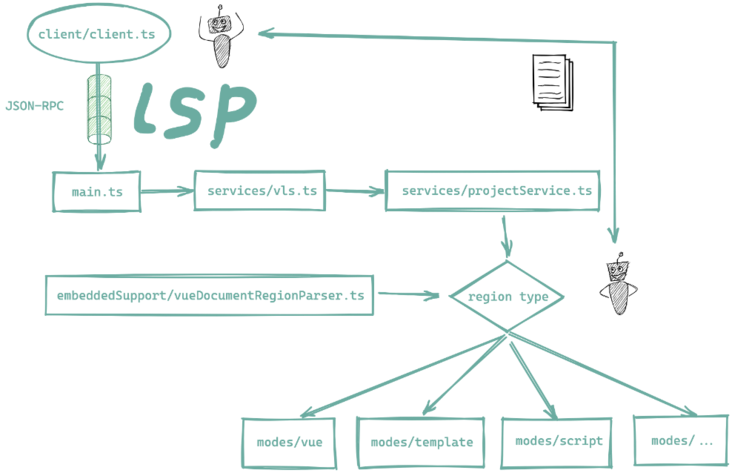
client:VS Code 插件的入口代码,package.json 文件中 main 字段会指向这个目录的产物
server:LSP 架构中的 Server 端,上述 client 会通过 LSP 协议与这个 server 目录通信
syntaxes:Vetur 的词法规则文件夹,内部包含许多 JSON 格式,符合 TextMate 规则的词法声明
languages:Vetur 提供的语言配置信息,规则比较简单,了解作用即可,不必深入
vti:按 vti/bin/vti 文件可以推断,这里是 Vetur 的命令行工具,不在主流程内可以先忽略
docs:按内容可以推断这是 Vetur 的介绍文档,此处可忽略
build:构建命令,package.json 文件的 script 命令有一些会指向这个目录,可以忽略
一系列基础配置文件,包括 tsconfig.json 、package.json 等,可先忽略
小结
Vetur 是一个语言插件,所以必然是使用 词法高亮、Language API、Language Server Protocol 三类技术实现核心逻辑的,而 package.json 文件中的 contributes 配置项的内容也恰好验证了这一点
词法高亮 相关的代码集中在 syntaxes 文件夹
Language Server Protocol 相关的代码集中在 client 与 server 文件夹
可以用 yarn watch 命令持续构建,配合 F5 快捷键启动调试
设定切入点
善用搜索引擎
谷歌 and 百度一类的搜索引擎,体感上谷歌的搜索质量会好很多,不过有一定的英语门槛
开源项目的官网、社区、wiki、github 等官方渠道,通常都会有比较不错的资料
Segmentfault、知乎、掘金、公众号等垂直社区
国外的 Medium/StackOverflow 社区,质量极高,很多大佬在上面活跃
Xxx 源码解析
Xxx 原理
如何实现 xxx
分析关键流程
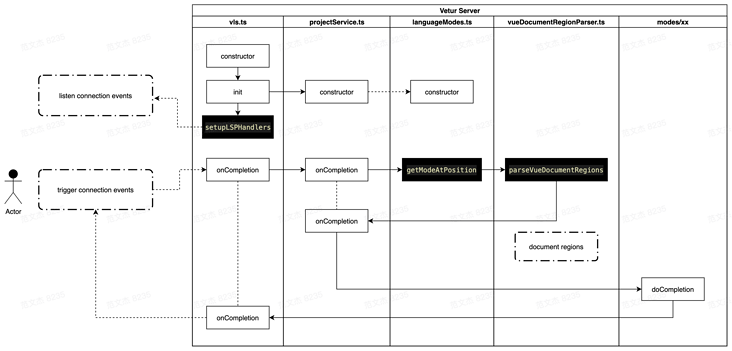
启动阶段,vls 类型会初始化化 projectService 对象,之后再监听各类 LSP 事件
执行阶段,LSP 事件触发时,vls 会将事件直接委托给 projectService 对象处理,而 projectService 会做两件事情:
针对 SFC 文件做 region 切割,解析出 template、script、style 等区块
针对不同区块,调用 modes/xxx 对象的 doComplete 函数处理
对于 template 的格式化请求,最终会流转到 modes/template/index.ts 文件的 format 函数做处理
对于 style 的格式化请求,则流转到 modes/style/index.ts 文件的 format 函数
同理可以推导出包括代码补全、hover 提示、跳转到定义、错误诊断等等高级特性上
局部深入
静态猜想:“读”源码,从面上理解代码逻辑并作出猜想
动态验证:“运行”源码,借用 debug 工具逐行跟踪代码执行过程,必要时可以改动原有代码,验证猜想
静态分析 —— 做猜想
函数层面,关注输入输出及副作用:
函数接受什么结构的参数,这些参数经过函数内部的每一条语句之后会发生什么变化,或者如何影响语句的执行
函数执行完毕之后,会返回什么结构的结果,这些结果下一步会被谁消费,影响谁的执行逻辑
特别的,有不少库的函数实现有明显的“副作用”,不是那么“纯”,包括 Webpack、Vetur、Eslint 等 —— 这会急剧提升理解成本,所以阅读的时候多留个心眼
分支语句中,优先关注主流程,分支流程很容易增加心智负担,到后面就不认得谁是谁了
对于循环语句,通常可以关注循环之前的状态与之后的状态,通过这些变化推断循环的作用
对于变量与子函数,根据命名推断作用,通常不必过度细究
跳过参数校验、错误处理等分支逻辑,抓主流程!抓重点!
谨记你要研究的切入点,遇到特别复杂的子模块,先大致理解功能,点到为止,记下这个硬骨头回头再作为一个新的切入点继续研究
学点常用的设计模式,工厂、装饰器、代理等等,这些模式的使用率非常高
动态分析 —— 验证猜想
如果框架已经接入了一些工程化工具,需要弄清楚如何将源码编译为运行产物,例如 Vetur 项目接入了 tsc + rollup,对应的命令为 yarn watch/compile
如何启动调试模式,例如 Vetur 场景下需要借用 VS Code 的 .vscode/launch.json 配置文件 + F5 命令启动调试;而对于前端框架如 Vue、React,通常打开浏览器的 DevTool 面板即可
如何插入调试语句,前端或 Node 场景下通常添加 debugger; 语句即可
及时总结
下一个切入点
最佳实践
设定好具体、可衡量的目标,不要为了学习而学习,如果有切实的强诉求,那就别由于彷徨,马上去做
磨刀不误砍柴工,不要上来就对着源码疯狂输出,一定要花点时间站在高层视角去看框架的背景和生态
抓大放小,忽略哪些还不熟悉的概念、语句、工具、分支逻辑,你要认识到复杂事物的学习模型往往螺旋上升,逐步深入的,不可能过一遍就能掌握所有细节和精髓,如果一开始就过度关注细节,通常会让整个学习周期拉到无限长。要弄清楚啥时候,什么情况下应该忽略细节,什么时候应该抓住不放 —— 这与你的目标和切入点有很大的关系
随时笔记:一旦有任何新发现、新问题,做好笔记,记录下来,这些都会成为继续探索的重要线索
随时总结:
笔记记录当下的、零碎的发现,总结则将这些线索串联形成知识点。
总结过程你会发现更多认知漏洞,提出更多问题,可以反过来继续挖掘
好记性不如烂笔头,探索的结果落到纸面上才会真正成为你自己的东西,极端一点看,没有形成输出的学习过程往往会随着时间的流逝,变成徒劳
