
报表工具的二次革命
先回顾第一次革命
第一次革命发生在报表工具诞生的初期,当时基础类,工具类软件,基本都是国外软件的天下,报表工具似乎也不例外,外国人带着他们的报表工具进入中国,也想像数据库一样,占领和收割国内的庞大软件市场,但是这一次他们折戟了,国外的报表工具不仅没有成功,反而是被国产的工具打的落花流水,甚至连开源免费的也被打趴下了 为什么一向厉害的国外软件在报表领域却没有打败国产的呢? 刚进入国内的国外报表软件,其实在前期也打开了一定的市场,形成了一定的规模,知名度也挺高,比如水晶报表,但是很快就漏出疲态,由于产品处于初期阶段,而且欧美人的表格可能也比较简单,这些国外报表工具,使用上很不方便,只能做简单的表格 可以看看下面这俩,看着就有点蒙圈,不知道该怎么弄了,完全和我们平时看到的表格不一样,增加学习成本不说,即使学会了也不用,做不了复杂的表格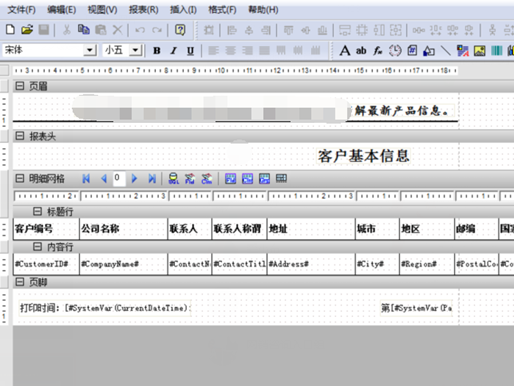
 这时候,报表工具的第一次革命就来了
面对这些国外工具解决不了的难题,国内报表工具的代表厂商,润乾报表,在研究了无数复杂表样后,开发出了全新一代的类 EXCEL 的工具,创造出了独一无二的非线性报表模型,不仅学习简单,操作方便,而且可以轻松做出各类中国式复杂报表
这时候,报表工具的第一次革命就来了
面对这些国外工具解决不了的难题,国内报表工具的代表厂商,润乾报表,在研究了无数复杂表样后,开发出了全新一代的类 EXCEL 的工具,创造出了独一无二的非线性报表模型,不仅学习简单,操作方便,而且可以轻松做出各类中国式复杂报表
 这次革新,不仅让国产软件打败了国外软件,而且国产厂商也重新定义了报表软件的标准,此后的工具,就全都是好用的 EXCEL 方式的操作,和模仿非线性报表的复杂报表模型了
这次革新,不仅让国产软件打败了国外软件,而且国产厂商也重新定义了报表软件的标准,此后的工具,就全都是好用的 EXCEL 方式的操作,和模仿非线性报表的复杂报表模型了
再来说第二次革命
一次革命后,复杂报表的制表方面的难题就基本都解决了 但随着行业的发展,我们又慢慢发现,虽然报表工具已经很牛,什么复杂表格都能做,但有些时候,报表开发还是很让人头疼,因为给报表准备数据有时候是一件更困难的事情 做过实际项目开发的工程师都知道,应用中的报表,有 80% 的数据来源和计算都比较简单,很多一个简单的 SQL 语句就搞定了,但还有 20% 的情况中,数据准备工作就没有那么好做了,一些过程式的多步骤复杂计算,常常要写很长的多层嵌套的 SQL 或者存储过程才能搞定,如果数据来源再复杂一些,要对各类数据源混算,一些非关系数据库或者文本数据源都不支持 SQL 了,那还得用 JAVA 等语言来写,SQL 10 几行能写完的,JAVA 恨不得写出几百行来,编码难度和效率就更糟糕了 然而恰恰是这仅占 20% 的需要硬编码来做复杂数据准备的工作,却占了我们 80% 的工作量 而且,随着系统不断的开发使用,这些存储过程,中间表,JAVA 程序,也都会慢慢的累积起来,越来越多,导致应用高度耦合,维护困难
另外,随着大数据时代的到来,报表的性能问题也变的格外突出,单纯通过报表工具的运算能力来解决性能问题已经有点捉襟见肘
怎么解决这些新的难题呢,这就唤起了报表工具的二次革命
虽然数据准备、优化应用这些事已经不完全算是报表工具能力应该覆盖的范畴,工程师们也都非常理解,但只要是和报表相关的难题,作为一个报表厂商,急用户之所急,我们就得想办法去去克服这个难题
第二次革命,是提升数据准备能力,优化应用结构和提升性能的革命
集算器,SPL,就是润乾发起二次革命,解决上面这些新问题的利器,而且是开源免费的,不仅在国内有很多开发商在用,国外也有庞大的用户基础,不仅润乾报表可以用,也可以配合其他报表工具来用
而且,随着系统不断的开发使用,这些存储过程,中间表,JAVA 程序,也都会慢慢的累积起来,越来越多,导致应用高度耦合,维护困难
另外,随着大数据时代的到来,报表的性能问题也变的格外突出,单纯通过报表工具的运算能力来解决性能问题已经有点捉襟见肘
怎么解决这些新的难题呢,这就唤起了报表工具的二次革命
虽然数据准备、优化应用这些事已经不完全算是报表工具能力应该覆盖的范畴,工程师们也都非常理解,但只要是和报表相关的难题,作为一个报表厂商,急用户之所急,我们就得想办法去去克服这个难题
第二次革命,是提升数据准备能力,优化应用结构和提升性能的革命
集算器,SPL,就是润乾发起二次革命,解决上面这些新问题的利器,而且是开源免费的,不仅在国内有很多开发商在用,国外也有庞大的用户基础,不仅润乾报表可以用,也可以配合其他报表工具来用
集算器 SPL
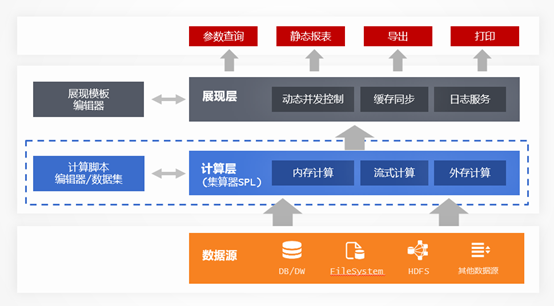 SPL 是一个中间计算层,类似于数据中台,它可以轻松解决项目中的数据准备开发难题,可以优化应用结构,提升运算性能
SPL 是一个中间计算层,类似于数据中台,它可以轻松解决项目中的数据准备开发难题,可以优化应用结构,提升运算性能
 下面我们就来具体看下 SPL 是怎么解决这三个方面的难题的
下面我们就来具体看下 SPL 是怎么解决这三个方面的难题的
降低报表数据准备开发难度
比 JAVA 和 SQL 更易写
当前复杂报表的数据准备工作一般是采用 JAVA 或 SQL 完成的,存储过程以及中间表也可以看作是 SQL。SPLSPL 的语法比 JAVA 和 SQL 更为简单易懂,采用 SPL 能在很大程度上简化这些开发量 JAVA 等语言没有提供批量数据计算的类库,写个简单的 SUM 也要好几行,更何况分组、连接等运算,而对于过滤、汇总用到的通用表达式计算,基本上是大多数应用程序员无法完成的任务了 SPL 则提供了大量与结构化计算相关的基础对象和方法,分组汇总这些只要一句,而且是解析执行的动态语言,可以进行随意的表达式计算。使用 SPL 完成报表数据准备工作要比 JAVA 容易得多,代码也要短小很多,这一点很好理解,就不具体举例了 代码短小不仅是写得更快,而且还能容易理解算法和排错,绝大多数报表的数据准备算法可以在一个屏幕内显示出来,可以更直观地理解代码的整体含义。而使用 JAVA 时,一个完整的业务逻辑常常需要几百行代码,翻看到后面时已经忘了前面的了 有经验的程序员都知道,SQL 用来实现很零碎的多步运算很不方便,特别是与次序相关的运算,程序员常常要把数据从数据库中取出来用 JAVA 等完成。而 SPL 则正好在这方面做了强化,在分步计算、集合化、有序计算和对象引用等几方面做了完善,对于常用的日期和字串等运算,也比大部分 SQL 提供了更丰富的方法 举个例子,我们要算某支股票最长连续涨了多少交易日 SQL 的写法
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL 的写法
|
|
A |
|---|---|
| 1 | =stock.sort(tradeDate) |
| 2 | =0 |
| 3 |
=A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
SPL 简化 SQL 编码的例子很多,有兴趣可以去参考:
4 SPL 方案与案例
(http://c.raqsoft.com.cn/article/1647044867607)
比报表中计算更广泛
报表工具都可以完成计算列、分组排序等运算,润乾报表还提供了跨行组运算和相对格与集合的引用方案,可以完成更复杂一些的运算 报表工具中的运算是一种状态式的计算,也就是把所有计算表达式写在报表布局上,由报表工具根据依赖关系决定计算次序。这种方法好处是很直观,在依赖关系不太复杂时能一目了然地了解各单元格的运算目标 但是,在依赖关系较为复杂,数据准备计算需要分成多步时,状态式计算就困难了,要实施过程式计算,经常需要借用隐藏格,隐藏格不仅将破坏状态式运算的直观性,由于状态式计算一般需要全内存处理依赖关系,还会占用更多不必要的内存。而且还有许多运算即使用隐藏格也难以完成 比如统计各地区前五的销售业绩,第六名以后全部归并为其他 如果不借助数据准备环节,就要在报表中使用隐藏行列手段将不该列出来的条目隐藏,而不能直接过滤掉 单纯报表工具实现: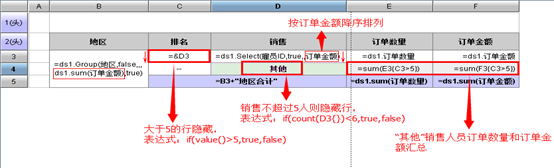 SPL 做好数据准备后 + 报表工具实现
SPL 做好数据准备后 + 报表工具实现
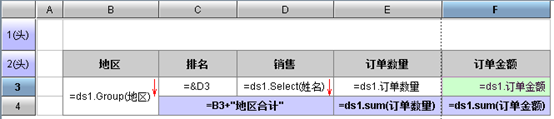 再比如带明细的分组报表要按汇总值排序,需要先分组后排序,许多报表工具无法控制这个次序,报表就无法完成了
还有个典型例子是舍位平衡,明细值四舍五入后再合计,可能会与合计值的四舍五入值不相等,会造成了报表上明细与合计数值不一致,这时需要根据合计的舍入值倒推明细的舍入值,这不是报表工具能搞定的事了
这几个运算的逻辑都很简单,但在报表工具中却很难实现,单句的 SQL 也很难写,而为了这种简单且无复用价值的运算写一段 JAVA 程序或存储过程显得很无聊,况且也不是很轻松。但是,如果采用 SPL 就会容易得多,在数据准备阶段完成计算,报表只负责呈现少量的直观计算,能有效地保持状态式计算的优势。过程多了一步,但结构更为清晰
SPL 还能轻松实现动态数据源和数据集
报表工具使用的数据源一般事先配置好了,不能根据参数动态选择,而使用 SPL 数据源时则可以用脚本控制连接不同的数据源
另外 SPL 还能协助处理格式
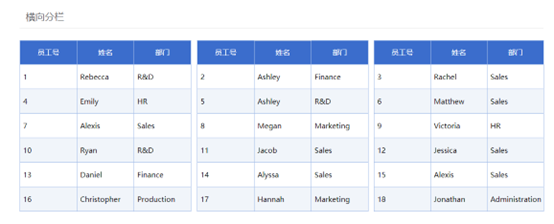
比如许多报表工具都支持纵向分栏,但很少有报表工具支持横向分栏。而用 SPL 可以将原数据集变换成横向拼接过的数据集,报表工作只要用普通的模板呈现列数更多的数据集即可
再比如带明细的分组报表要按汇总值排序,需要先分组后排序,许多报表工具无法控制这个次序,报表就无法完成了
还有个典型例子是舍位平衡,明细值四舍五入后再合计,可能会与合计值的四舍五入值不相等,会造成了报表上明细与合计数值不一致,这时需要根据合计的舍入值倒推明细的舍入值,这不是报表工具能搞定的事了
这几个运算的逻辑都很简单,但在报表工具中却很难实现,单句的 SQL 也很难写,而为了这种简单且无复用价值的运算写一段 JAVA 程序或存储过程显得很无聊,况且也不是很轻松。但是,如果采用 SPL 就会容易得多,在数据准备阶段完成计算,报表只负责呈现少量的直观计算,能有效地保持状态式计算的优势。过程多了一步,但结构更为清晰
SPL 还能轻松实现动态数据源和数据集
报表工具使用的数据源一般事先配置好了,不能根据参数动态选择,而使用 SPL 数据源时则可以用脚本控制连接不同的数据源
另外 SPL 还能协助处理格式
比如许多报表工具都支持纵向分栏,但很少有报表工具支持横向分栏。而用 SPL 可以将原数据集变换成横向拼接过的数据集,报表工作只要用普通的模板呈现列数更多的数据集即可
一致的多样性数据源支持
现代报表的数据源并不只是数据库,还可能是文本文件或 json、XML 等。这些非数据库数据源没有再计算能力,但出报表时总还是需要再进行一些过滤分组甚至多表连接等运算,报表工具本身的计算能力不足,一般都不能很好地处理 json 和 XML 数据,即使针对能进行简单处理的结构化文本,由报表工具运算也也会造成容量负担过重的问题。因此,我们经常会有一个过程把这些非数据库数据导入到数据库再去生成报表,增加开发工作量 如果采用 SPL 准备数据,则可以直接用这些非数据库数据作为数据源去生成报表,不需要导入数据库的过程,减少开发工作量 比如:json 文件存储了客户名单及其销售额,要找出销售额累计占到一半的前 n 个大客户,并按销售额从大到小排序|
|
A |
B |
|
1 |
=json(file("d:\\sales.json").read()).sort(amount:-1) |
取数并逆序排序 |
|
2 |
=A1.cumulate(amount) |
计算累计序列 |
|
3 |
=A2.m(-1)/2 |
最后的累计值即是总和 |
|
4 |
=A2.pselect(~>=A3) |
超过一半的位置 |
|
5 |
=A1(to(A4)) |
按位置取值 |
更多例子可以参考: 报表工具怎样使用 Json/XML 的数据(http://c.raqsoft.com.cn/article/1640858385206)
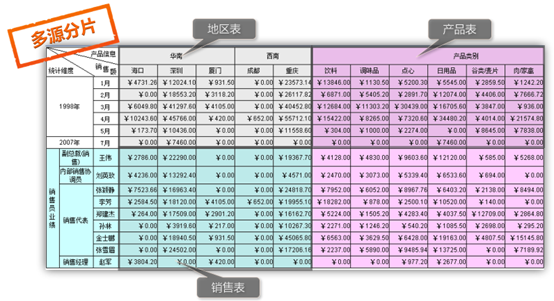
而且一般报表工具使用的数据集都是类似 SQL 返回的那种单层二维表,碰到象 json 或 XML 这类多层数据只能先转换成多个单层数据集,再在报表模板中关联运算拼接成多层报表。而 SPL 可以直接支持多层数据集计算,不需要做这个转换,减少工作量,润乾报表也可以接受 SPL 返回的多层数据集直接按层次呈现,不需要在报表中再做关联 类似地,MongoDB 也支持多层数据,也可以用 SPL 直接计算并返回给润乾报表 另外数据库还包括 NoSQL 数据库、文件包括 HDFS 文件,对于 SPL 来讲都是数据源。SPL 自有的计算能力可以使这些计算能力不一的多样性数据获得通用一致的计算能力。比如文件几乎没有计算能力,MongoDB 对 JOIN 和 GROUP 运算支持不足,各家数据库对窗口函数的支持程度不同、日期与字串处理能力也普遍不足且风格迥异。采用 SPL 后可以用相对一致的方案来计算,而这将意味着更低的移植成本以及学习难度 而且用 SPL 辅助计算后还可以保留非关系数据库原有的优势。比如 MongoDB 的对追加型日志数据的吞吐能力就远远超过普通关系数据库,但结构化计算能力较弱,用 SPL 来弥补后,数据可以继续留在 MongoDB 中,即获得其高吞吐性能也有了结构化计算能力。

优化报表应用结构
集算器 SPL 的设计初衷是提升数据准备过程的开发效率,但实际应用下来我们发现,SPL 不仅提升了数据准备的效率,同时还优化了应用的结构,这个能力,也非常有意义解释执行降低应用耦合度
我们知道,JAVA 应用大多数情况是事先编译并静态加载的,也就是要把所有模块一起编译打包后部署,在运行过程中代码就不再改变了。其实 JAVA 也有动态编译和加载的技术,但难度和复杂度都高很多,一般应用程序员很少使用。而且即使采用了动态加载技术,也不能替换已经加载进内存的类,只能不断新增新的类 这种机制下,用 JAVA 编写的报表数据准备算法就需要和主应用程序一起打包发布,这会导致报表模块与主应用之间的高耦合性 一般来讲,报表的业务稳定性要比主应用差得多,报表变动的频率远远高于主应用,一旦报表的数据来源发生变化,整个应用就得跟着重新编译,无法做到热切换,这种使用体验是很糟糕的 如果用 SPL 来实现数据准备算法,就能有效地降低主应用程序与报表功能的耦合度了 SPL 写出来的脚本也是类似报表模板的外置文件,不需要和主应用程序一起编译打包,而且它是解释执行的动态语言,在修改时不会涉及主应用程序,只要把 SPL 脚本替换就可以,天然就支持热切换
算法外置减少存储过程
在体系结构方面用存储过程准备报表数据和用 JAVA 程序是类似的,也会造成耦合度高的问题,只是从报表模块与主程序之间的耦合变成的报表模块与数据库之间的耦合 存储过程存放在数据库中,报表模板放在文件系统中,保持两者同步修改依然很麻烦,而且存储过程修改时需要申请一定级别的管理员权限做重编译,虽然不象 JAVA 那样难以做到热切换,但数据库高权限的频繁使用又会带来安全隐患 比 JAVA 更糟糕的是,数据库及其中的存储过程可能被多个应用共享,如果管理不善,很容易造成多个应用之间的高耦合,时间长了会搞不清楚某个存储过程在被哪些应用调用,越来越混乱 同样地,采用 SPL 也可以极大程度地减少数据库中的存储过程,算法外置后与报表模板一起存放管理,完全归属于报表模块,不仅降低与应用其它部分的耦合,更不会造成与其它应用的耦合 实际上,存储过程本身编写难度并不小,遍历式计算代码的性能也不佳,而且可移植性很差,原则上在报表业务中应当尽量少用存储过程数据外置减少中间表
数据量巨大或计算过程太复杂时,我们经常会事先对原始数据做些处理后形成中间结果,再基于这些中间结果开发报表。这些中间结果一般是以数据库表的形式存在的,也就是这里所谓的中间表 一个运行时间较长的系统中,中间表的数量往往会远远大于原始表。某些移动公司的数据库中有上万个表,即使很复杂的业务用五百个表也基本能描述了,这些上万的表中绝大多数都是为报表服务的中间表,这肯定是数据库厂商都没想到过的情况 与存储过程类似,大量的中间表也会造成数据库管理的混乱 数据库中的表是以线状方式存储的,相当于没有分类,而数据库被各个应用共享,中间表都混到一起,很难搞清楚。这需要项目组有很强的管理控制能力才能理清,比如规定中间表的命名规则并保证得到执行,但强化管理常常是以牺牲开发效率为代价的,项目时间一紧张就顾不得这些规矩了 管理能力不够好其实是常态,这就会导致中间表越来越多,积累到上万可能是有点极端,但总归不是个小数目。这些中间表可能有相当多已经没有用了,但因为不清楚有哪些应用还在使用而只能先留着,相应的 ETL 过程也仍然要无意义地浪费计算资源继续更新数据 那么为什么要把这些中间结果存到数据库中,而不能存放到文件系统中呢?
这是因为我们不可能为每个报表的每种参数组合事先计算中间结果,在生成报表时还需要根据参数进行计算,也就是要求这些中间结果仍有计算能力,而目前只有数据库有这种计算能力,文件是没有计算能力的,于是中间数据就只能变成中间表
中间数据一般都是由不再改变的历史数据计算出来的,完全不需要数据库的事务一致性能力,因为都是导出的冗余数据,也不需要很高的稳定要求,数据坏了重算一次就行了,存放在数据库中仅仅为了获得计算能力,实在是划不来的
有了 SPL 后,就可以将中间数据外置到文件系统中,由 SPL 提供针对文件的计算能力,可以有效地减少中间表,不必再让这些冗余数据继续占用昂贵并且低效的数据库空间
外置的中间数据文件还可以使用文件系统的树形结构管理,与报表模板及数据准备算法统一存储。这不仅管理简单方便,而且,由于不考虑写入和一致性的需求,文件还会比数据库有更好的 IO 吞吐性能,整体提高报表的运算速度
那么为什么要把这些中间结果存到数据库中,而不能存放到文件系统中呢?
这是因为我们不可能为每个报表的每种参数组合事先计算中间结果,在生成报表时还需要根据参数进行计算,也就是要求这些中间结果仍有计算能力,而目前只有数据库有这种计算能力,文件是没有计算能力的,于是中间数据就只能变成中间表
中间数据一般都是由不再改变的历史数据计算出来的,完全不需要数据库的事务一致性能力,因为都是导出的冗余数据,也不需要很高的稳定要求,数据坏了重算一次就行了,存放在数据库中仅仅为了获得计算能力,实在是划不来的
有了 SPL 后,就可以将中间数据外置到文件系统中,由 SPL 提供针对文件的计算能力,可以有效地减少中间表,不必再让这些冗余数据继续占用昂贵并且低效的数据库空间
外置的中间数据文件还可以使用文件系统的树形结构管理,与报表模板及数据准备算法统一存储。这不仅管理简单方便,而且,由于不考虑写入和一致性的需求,文件还会比数据库有更好的 IO 吞吐性能,整体提高报表的运算速度
混合运算实现 T+0 报表
关系数据库的事务一致性能力目前尚没有有效的替代者,交易系统仍然有必要使用关系数据库来建设 这种情况下,要实现 T+0 全数据量的实时报表,我们就得把历史数据继续存放在当期的交易数据库中一起计算,历史数据常常要庞大得多,这会要求我们建设更大容量的数据库,成本当然会很高。而且即使愿意支付成本,这个数据量也不可能一直增长,太大了会影响到交易业务的性能,这就不可容忍了 通常的办法是把部分历史数据被移出来做个分数据库,这样可以保证交易系统的正常运转,但要实现 T+0 报表就麻烦得多,会涉及到跨库运算 许多数据库都支持跨库运算,但一般都要求同类型的数据库,但历史数据和当期交易数据的要求不同,数据量更大但不要求事务一致性,很可能使用另一种数据仓库来存储 而且,即使是同构的数据库,数据库的跨库运算的方法一般也是将另一个库中的数据表映射成本库数据表,实际运算还是一个数据库在做,而且还多出许多数据传递的通讯成本,性能和稳定性都不好 使用 SPL 就可以很好地完成这个混合计算任务了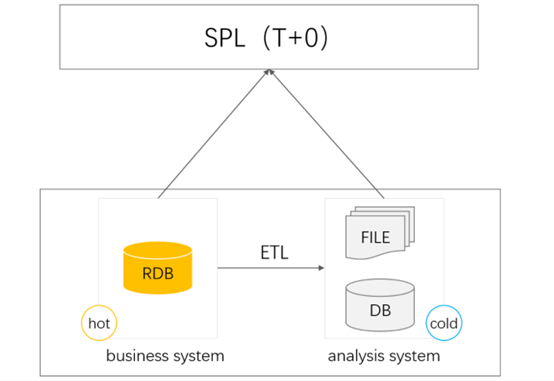 SPL 自己有计算引擎,不依赖于数据库,各个数据库内的数据计算仍由各库进行。SPL 可以使用多线程向各数据库同时发出 SQL 语句,由这些数据库并行执行,将各自的运算结果返回到 SPL 再汇总处理后传给报表工具去呈现
显然,这种机制还方便横向扩展,历史库可以有多个,是否同类型的也无所谓
而且,SPL 还有服务器方式的集群运行模式,在集算服务器的支持下,历史数据不必一定存放到数据库中,还可以存储在 IO 性能更好的文件系统中,配合集群计算,可以在更低的成本下获得更好的性能
具体 T+0 实例可以参考:
开源 SPL 轻松应对 T+0 (http://c.raqsoft.com.cn/article/1649513370929)
SPL 自己有计算引擎,不依赖于数据库,各个数据库内的数据计算仍由各库进行。SPL 可以使用多线程向各数据库同时发出 SQL 语句,由这些数据库并行执行,将各自的运算结果返回到 SPL 再汇总处理后传给报表工具去呈现
显然,这种机制还方便横向扩展,历史库可以有多个,是否同类型的也无所谓
而且,SPL 还有服务器方式的集群运行模式,在集算服务器的支持下,历史数据不必一定存放到数据库中,还可以存储在 IO 性能更好的文件系统中,配合集群计算,可以在更低的成本下获得更好的性能
具体 T+0 实例可以参考:
开源 SPL 轻松应对 T+0 (http://c.raqsoft.com.cn/article/1649513370929)
提升报表运算性能
报表的呈现周期中,大致可以分为下图的 4 个环节,4 个环节都有可能造成报表的性能问题,但概率较高的是前两个环节,数据准备和数据传输(图中黄色电池电量图,代表了出问题的程度)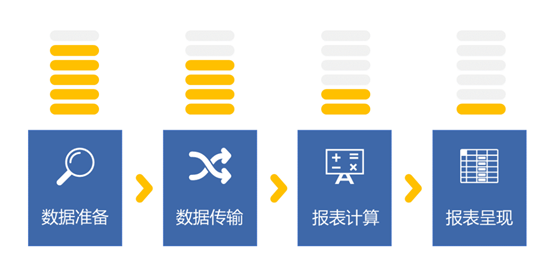 而恰恰这两个环节又都是报表工具无能为力的地方
而恰恰这两个环节又都是报表工具无能为力的地方
提升数据准备的性能
前面我们已经说到,在数据准备方面,很多场景下 SPL 比大段的 SQL,存储过程以及 JAVA 要写起来更容易,降低了数据准备的开发难度 事实上,SPL 不仅可以降低开发难度,还可以提升数据准备的效率和性能 我们通过一个简单小例来看一下 SPL 比 SQL 的算法高效在哪里 比如要在 1 亿条数据中取出前 10 名,用 SQL 算就会涉及大排序,大排序就会影响性能, 其实我们是可以想出不用大排序的算法的,但 SQL 无法描述,那就只能指望数据库优化器了,简单情况下,很多商用数据库确实都能优化,使用不必大排序的算法,性能通常也很好,但情况稍微变复杂一些,比如要在每个分组中取前 10 名,要用到窗口函数和子查询,这时候优化器就又无能为力了,又得乖乖去大排序,慢慢的算了 SPL 则不然,SPL 离散数据集中有普遍集合的概念,TopN 这种运算被认为是和 SUM 和 COUNT 一样的聚合运算,只不过返回值是个集合,用 SPL 去做个这个计算的时候就不需要做大排序了 这只是一个简单的例子,其他的 SPL 比 SQL 性能好的高级函数还有很多 除了新的高效的算法以外,数据的存储对于性能也非常重要,好算法要有合适的存储机制配合才能生效,SPL 也有自己更高效的存储方式,高性能二进制文件存储,相对于普通的数据库存储,SPL 的二进制存储和 SPL 的高效算法配合,性能会更好,使用 SPL 存储后,可以把原来需要缓存的计算过程变成不需要了,原来要遍历多遍的运算变成只遍历一次甚至不用遍历了,减少硬盘访问量也是非常有效的性能提升手段 报表涉及的数据,基本都是历史数据,必要的时候,把这些数据换一种更高效的方式存储,可行性也是很大的
下面是几个用 SPL 来优化数据准备的实际案例,有需要的可以详细看一下
开源 SPL 提速资产负债表 60 倍
报表涉及的数据,基本都是历史数据,必要的时候,把这些数据换一种更高效的方式存储,可行性也是很大的
下面是几个用 SPL 来优化数据准备的实际案例,有需要的可以详细看一下
开源 SPL 提速资产负债表 60 倍
提升数据传输的性能
报表项目大部分都是 JAVA 应用,基本都得通过 JDBC 来取数、做数据传输,有时候我们会发现,SQL 很简单,数据库负担也很轻,但数据传输到报表却需要很长时间,传输完成后,报表也算的很快,那就可以判定,就是有些数据库的 JDBC 取数太慢,导致了性能问题 我们动不了厂商的 JDBC,那就只能曲线救国,单线程取的慢,如果数据库允许,我们可以尝试多线程并行取,但由于并行取数涉及的数据分段方法和数据库及取数语法需要较复杂代码控制,也不容易做成报表功能,所以目前的报表工具基本都不支持并行取数 但在 SPL 中,这却是一个非常普通的功能,下面就是一段 SPL 并行取数的代码,写起来还是很简单的,也容易理解|
|
A |
B |
|
1 |
=now() |
//记录开始时间 |
|
2 |
=connect("oracle").query@1x("SELECT COUNT(*) FROM CUSTOMER") |
|
|
3 |
>n=12 |
//设置并行数,根据电脑的物理CPU核数决定 |
|
4 |
=n.(range(1,A2+1,~:n)) |
//按总记录数和并行数分段,记录本段开头和下段开头数字 |
|
5 |
fork A4 |
=connect("oracle") |
|
6 |
|
=B5.query@x("SELECT * FROM CUSTOMER WHERE C_CUSTKEY>=? AND C_CUSTKEY<?",A5(1),A5(2)) |
|
7 |
=A5.conj() |
//合并取数结果 |
|
8 |
=interval@s(A1,now()) |
//计算运行时间 |
在数据库负担不重时,并行取数几乎可以让传输效率得到线性的提升
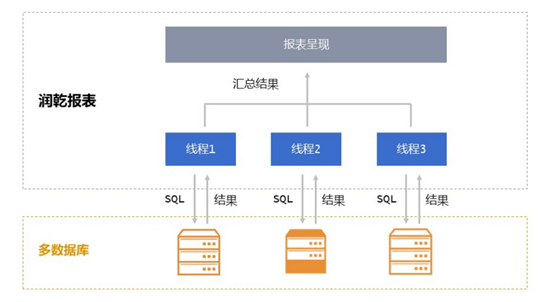 SPL 不仅可以优化前两个环节,对报表工具本身的计算能力也可以起到辅助提升的作用
SPL 不仅可以优化前两个环节,对报表工具本身的计算能力也可以起到辅助提升的作用
辅助报表计算提升性能
报表内的计算,主要得依靠报表工具的基本功,基本功好,可以保证大部分表内计算都不出问题,但万事总有例外,即使是以性能见长的润乾报表,也会遇到跑不快的情况 举个最简单的例子,比如要在报表里做多源关联,我们需要写一个类似这样的表达式 ds2.select(ID==ds1.ID),表达式很简单,但是计算复杂度却是平方级的,数据量不大时,都没问题,数据量稍大时,到几千行,那性能就会急剧下降了,再好的工具处理这样的运算也会有问题 但如果把这个关联放到报表外来做,用 SPL 来做,则可以使用低复杂的 HASH 算法(而在报表工具中无法对多个数据源先统一处理,实现不了这种算法),那性能就会大幅度的提升了 以下是我们在数据量比较大时,用润乾报表单独运算和 SPL+ 润乾报表协同运算的性能对比,可以看出,报表内的计算性能问题,如果挪到外部计算引擎解决,效果是非常好的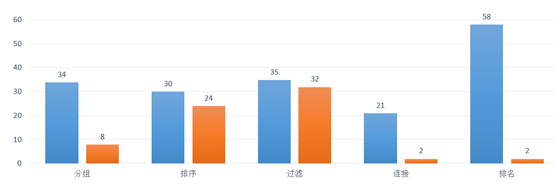 (蓝色是润乾报表单独运算的时间,橙色是 SPL+ 润乾报表协同运算的时间)
另外前面提到的,有时候报表设计中会多出很多用于保存中间结果的隐藏格,这些隐藏格在计算的时候也会占用很多内存,数据量小的时候感觉不到,量一大就卡了
使用 SPL 去做这些过程计算,则可以避免这样的问题
还有缓存
使用缓存能够有效地改善报表响应的用户体验,高端的报表工具一般都提供缓存功能。但报表工具的缓存机制比较死板,只能针对整个报表,不能只缓存报表的某个部分,两个报表有共同部分也无法复用缓存,也没法分别指定不同报表缓存在不同参数下的不同生存周期。因为报表工具采用可视化的配置方案,虽然使用简单,但很难设置过多复杂的参数
用 SPL 准备数据时就可以实现可控缓存的效果,SPL 是程序代码,可以由开发者灵活决定使用缓存的时刻及范围的策略,这样就可以实现报表的部分缓存、多个报表之间缓存复用、以及不同缓存的不同生存周期
(蓝色是润乾报表单独运算的时间,橙色是 SPL+ 润乾报表协同运算的时间)
另外前面提到的,有时候报表设计中会多出很多用于保存中间结果的隐藏格,这些隐藏格在计算的时候也会占用很多内存,数据量小的时候感觉不到,量一大就卡了
使用 SPL 去做这些过程计算,则可以避免这样的问题
还有缓存
使用缓存能够有效地改善报表响应的用户体验,高端的报表工具一般都提供缓存功能。但报表工具的缓存机制比较死板,只能针对整个报表,不能只缓存报表的某个部分,两个报表有共同部分也无法复用缓存,也没法分别指定不同报表缓存在不同参数下的不同生存周期。因为报表工具采用可视化的配置方案,虽然使用简单,但很难设置过多复杂的参数
用 SPL 准备数据时就可以实现可控缓存的效果,SPL 是程序代码,可以由开发者灵活决定使用缓存的时刻及范围的策略,这样就可以实现报表的部分缓存、多个报表之间缓存复用、以及不同缓存的不同生存周期
大数据量报表
报表性能问题们还有一个场景需要注意,就是大清单式报表,比如电信行业,要查看当月所有的充值记录,这样的报表,格式简单,但是数据量极大,有的可达到千万级以上,这类大数据量的报表呈现时如果等着把这些记录全部检索出来再生成报表,那会需要很长时间,用户体验自然会非常恶劣,而且报表一般采用内存运算机制,大多数情况下内存里也装不下这么多数据,所以我们一般都会使用分页呈现的方式,尽量快速地呈现出第一页,之后再通过翻页来加载后面的 这种分页呈现的方式通常是利用数据库的分页机制来实现,但数据库分页不仅有如下这些弊端,而且程序代码和对应的数据库是强耦合的,万一换了数据源,那还得重新做一遍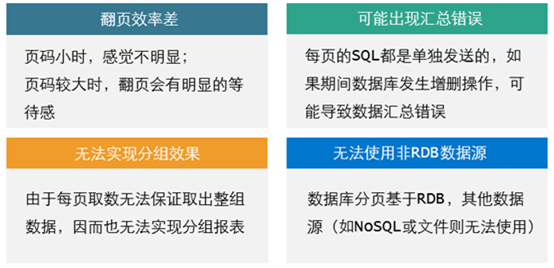 更好的方式是,取数和呈现做成两个异步线程,取数线程发出 SQL 后就不断取出数据后缓存到本地存储中,呈现线程根据页数计算出行数到本地缓存中去获取数据显示,如下图所示
更好的方式是,取数和呈现做成两个异步线程,取数线程发出 SQL 后就不断取出数据后缓存到本地存储中,呈现线程根据页数计算出行数到本地缓存中去获取数据显示,如下图所示
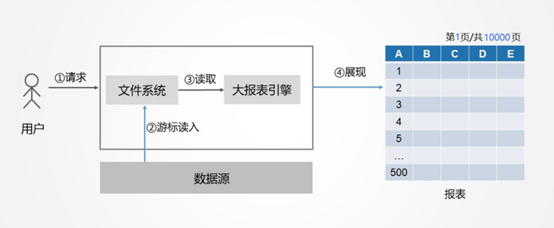 通过这样的方式,就可以很好的解决大数据量清单式报表的性能难题了具体如何实现可以参考:
通过这样的方式,就可以很好的解决大数据量清单式报表的性能难题了具体如何实现可以参考:大清单报表该怎么做?
总结
报表工具的两次革命: 第一次革命,解决了国外报表工具不好用,做不了复杂报表的难题,重新定义了报表工具的标准,让用户张口就能问:能不能做中国式复杂报表,有没有非线性报表模型,也让国产软件在报表这个领域一直以碾压式的优势走到现在 第二次革命,解决了报表外围的数据准备过程 SQL、存储过程、JAVA 难写以及性能低下的难题,同时还优化了报表应用的结构,再一次重新定义了报表工具的标准,让业界都认可报表工具要有一个计算层,也让整个报表的解决方案更完整,有了质的提升
感兴趣的小伙伴,请识别右侧二维码与我们联系
微信号|RUNQIAN_RAQSOFT