
手把手教你使用Python网络爬虫获取王者荣耀英雄皮肤
回复“书籍”即可获赠Python从入门到进阶共10本电子书
/1 前言/
王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了。今天来教大家如何使用Python来爬取这些精美的英雄皮肤。
/2 项目目标/
创建一个文件夹, 英雄分类保存所有皮肤图片。下载成功结果显示控制台。
/3 项目准备/
软件:PyCharm
需要的库:requests、lxml、fake_useragent、json、os
网站如下:
https://www.555x.org/html/wuxiaxianxia/list_29_{}.html/4 项目分析/
1、首先打开王者荣耀官网,点击英雄资料。
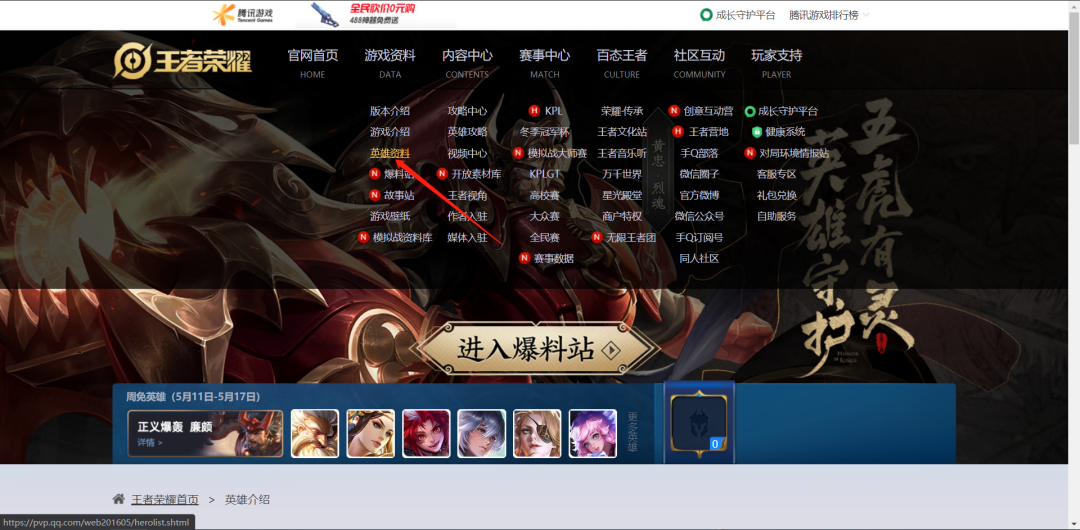
2、F12右键检查,点击英雄链接。
3、多点几个英雄链接看看网址规律。
herodetail/531.shtmlherodetail/523.shtmlherodetail/199.shtml
发现只有后面的数字在变化,最后的数字应该是控制的是哪个英雄,我们暂且认为它是英雄的编号。
4、按下F5刷新页面,点击network,找到herolist .json。(乱码没关系把herolist .json下载下来观察)如图:
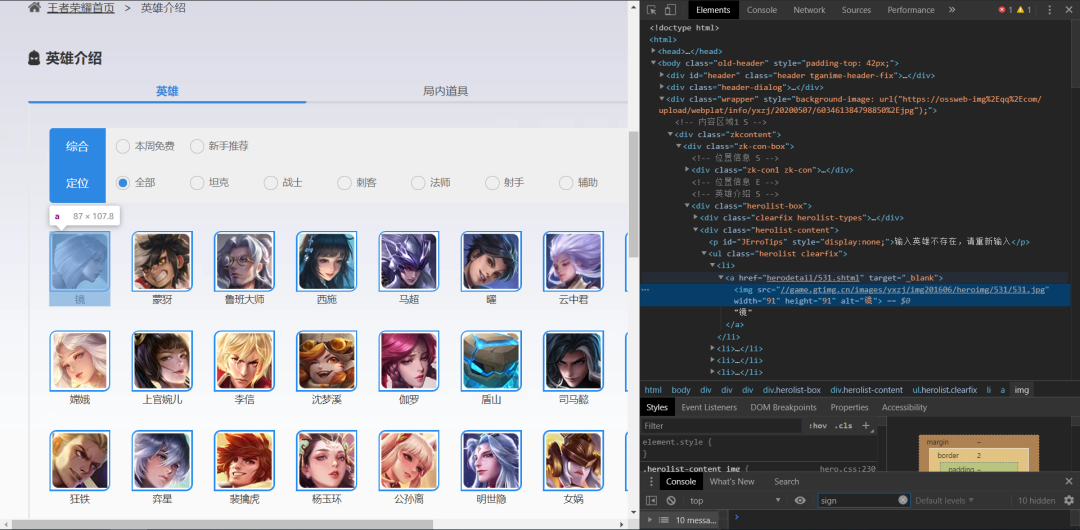
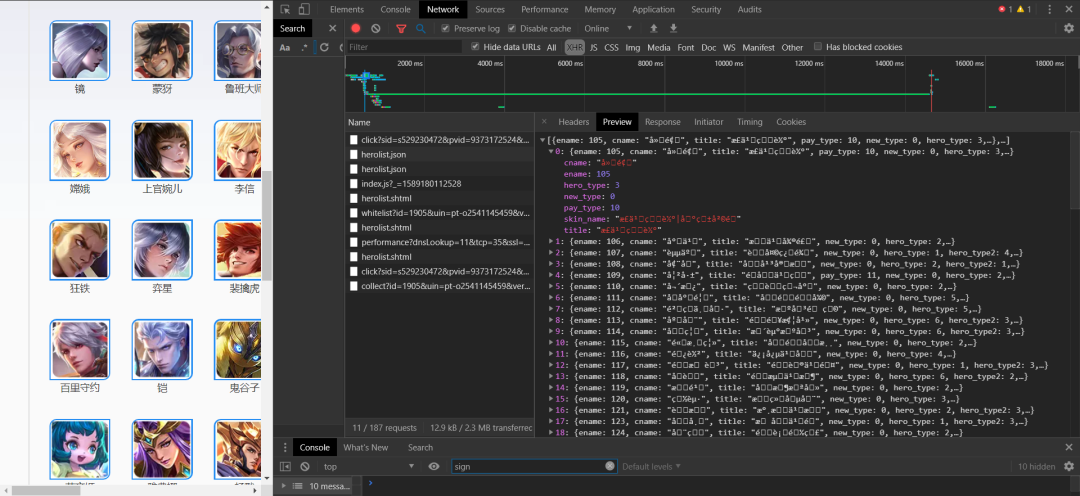

看到ename,就是对应网址后缀英雄的名称。而cname是对应英雄的名称。skin_name对应皮肤的名字。
5、点击英雄链接。观察图片地址的变化。
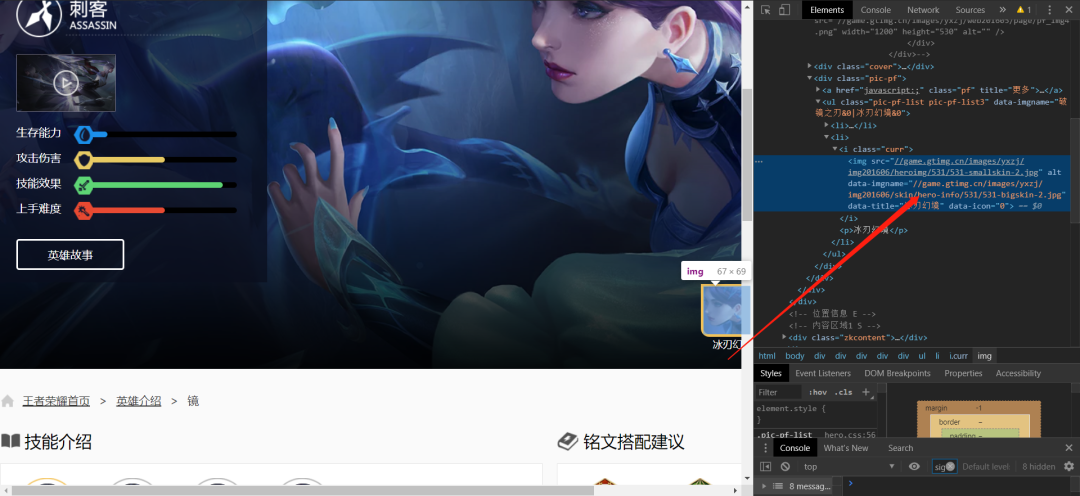
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-1.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-2.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-3.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-4.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-5.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-6.jpghttp://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-7.jpg
6、观察到同一个英雄的皮肤图片路径从1开始依次递增,我们再来看看不同英雄之间是如何区分的。会发现,107/107-这个英雄的编号不一样,获取到的图片就不一样。决定的是ename。
7、我们可以用字符串拼接的方式进行访问。
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg/5 项目实现/
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,并创建保存文件夹,代码如下所示。
import requests, json, osfrom lxml import etreefrom fake_useragent import UserAgentclass wzry(object):def __init__(self):os.mkdir("王者") # 创建王者荣耀这个文件夹 记住只有第一次运行加上,如果多次运行请注释掉本行def main(self):passif __name__ == '__main__':Siper=wzry()Siper.main()
2、创建wzry方法(),主方法(main)实现 ,对herolist .json 进行json解析。
def wzry(self):response = requests.get('https://pvp.qq.com/web201605/js/herolist.json', headers=self.headers)content = response.text # 这里后获取的是json数据类型需要 转换成Python对应类型data = json.loads(content)def main(self):self,wzry()
3、for遍历data获取需要的字段。创建对应的英雄文件夹。
for i in data:hero_number = i['ename'] # 获取英雄名字编号hero_name = i['cname'] # 获取英雄名字os.mkdir("././王者荣耀/{}".format(hero_name)) # 创建英雄对应的文件夹
4、对英雄界面发生请求,利用xpath解析数据,代码如下。
response_src = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(hero_number),headers=self.headers)hero_content = response_src.content.decode('gbk') # 返回相应的html页面hero_data = etree.HTML(hero_content) # xpath解析对象hero_img = hero_data.xpath('//div[@class="pic-pf"]/ul/@data-imgname') # 提取每个英雄的皮肤名字hero_src = hero_img[0].split('|') # 去掉每个皮肤名字中间的分隔符
5、遍历英雄src处理图片名称。
for i in range(len(hero_src)):i_num = hero_src[i].find("&")skin_name = hero_src[i][:i_num]#print(skin_name)# 皮肤图片地址请求
6、图片地址请求。
response_skin = requests.get("https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg".format(hero_number, hero_number, i + 1))skin_img = response_skin.content # 获取每个皮肤图片
7、 把皮肤图片存储到对应名字的文件里,成功显示控制台。
with open("./王者荣耀/{}/{}.jpg".format(hero_name, skin_name), "wb")as f:f.write(skin_img) # 把皮肤图片存储到对应名字的文件里print("%s.jpg 下载成功!!" % (skin_name))
/6 效果展示/
1、点击绿色小三角运行。需要注意的是创建王者荣耀这个文件夹,记住只有第一次运行加上。
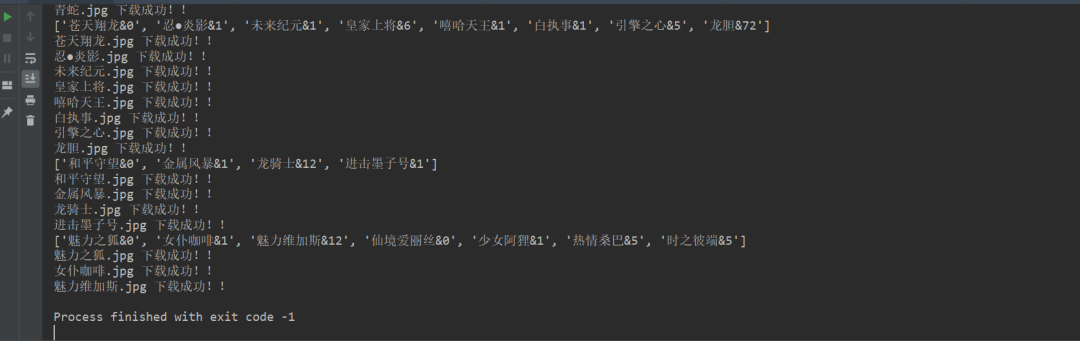
2、运行程序后,结果显示在控制台,如下图所示。
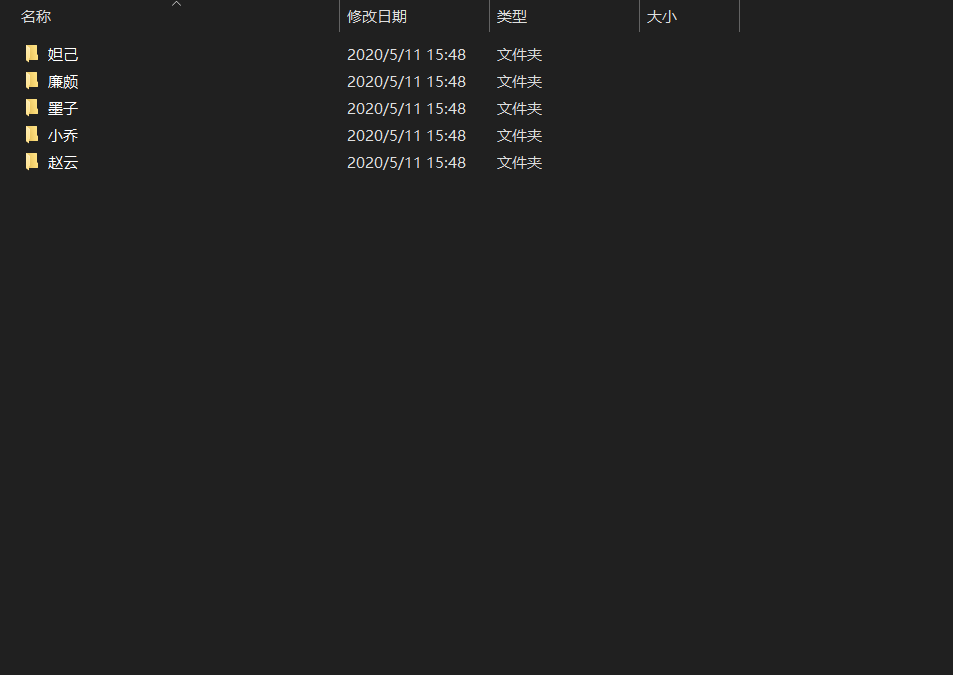
3、英雄分类列表。
4、双击文件,即可展示。
/7 小结/
------------------- 荐书 -------------------
《Python数据分析》这本书主要围绕整个数据分析方法论的常规流程,介绍了Python常用的工具包,包括科学计算库Numpy、数据分析库Pandas、数据挖掘库Scikit-Learn,以及数据可视化库Matplotlib和Seaborn的基本知识,并从数据分析挖掘的实际业务应用出发,讲解了互联网、金融及零售等行业的真实案例,比如客户分群、产品精准营销、房价预测、特征降维等,深入浅出、循序渐进地介绍了Python数据分析的全过程。

本书内容精炼、重点突出、案例丰富,适合在企业中从事数据分析、数据挖掘、机器学习等工作的人员学习使用,同样适合想从事数据分析挖掘工作的各大中专院校的学生与教师,以及其他对数据分析挖掘技术领域有兴趣爱好的各类人员。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~