
9个提高代码运行效率的小技巧你知道几个?
我们写程序的目的就是使它在任何情况下都可以稳定工作。一个运行的很快但是结果错误的程序并没有任何用处。在程序开发和优化的过程中,我们必须考虑代码使用的方式,以及影响它的关键因素。通常,我们必须在程序的简洁性与它的运行速度之间做出权衡。今天我们就来聊一聊如何优化程序的性能。
1. 减小程序计算量
1.1 示例代码
1.2 分析代码
1.3 改进代码
2. 提取代码中的公共部分
2.1 示例代码
2.2 分析代码
2.3 改进代码
3. 消除循环中低效代码
3.1 示例代码
3.2 分析代码
3.3 改进代码
4. 消除不必要的内存引用
4.1 示例代码
4.2 分析代码
4.3 改进代码
5. 减小不必要的调用
5.1 示例代码
5.2 分析代码
5.3 改进代码
6. 循环展开
6.1 示例代码
6.2 分析代码
6.3 改进代码
7. 累计变量,多路并行
7.1 示例代码
7.2 分析代码
7.3 改进代码
8. 重新结合变换
8.1 示例代码
8.2 分析代码
8.3 改进代码
9 条件传送风格的代码
9.1 示例代码
9.2 分析代码
9.3 改进代码
10. 总结
1. 减小程序计算量
1.1 示例代码
for (i = 0; i < n; i++) {
int ni = n*i;
for (j = 0; j < n; j++)
a[ni + j] = b[j];
}
1.2 分析代码
代码如上所示,外循环每执行一次,我们要进行一次乘法计算。i = 0,ni = 0;i = 1,ni = n;i = 2,ni = 2n。因此,我们可以把乘法换成加法,以n为步长,这样就减小了外循环的代码量。
1.3 改进代码
int ni = 0;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++)
a[ni + j] = b[j];
ni += n; //乘法改加法
}
计算机中乘法指令要比加法指令慢得多。
2. 提取代码中的公共部分
2.1 示例代码
想象一下,我们有一个图像,我们把图像表示为二维数组,数组元素代表像素点。我们想要得到给定像素的东、南、西、北四个邻居的总和。并求他们的平均值或他们的和。代码如下所示。
up = val[(i-1)*n + j ];
down = val[(i+1)*n + j ];
left = val[i*n + j-1];
right = val[i*n + j+1];
sum = up + down + left + right;
2.2 分析代码
将以上代码编译后得到汇编代码如下所示,注意下3,4,5行,有三个乘以n的乘法运算。我们把上面的up和down展开后会发现四格表达式中都有i*n + j。因此,可以提取出公共部分,再通过加减运算分别得出up、down等的值。
leaq 1(%rsi), %rax # i+1
leaq -1(%rsi), %r8 # i-1
imulq %rcx, %rsi # i*n
imulq %rcx, %rax # (i+1)*n
imulq %rcx, %r8 # (i-1)*n
addq %rdx, %rsi # i*n+j
addq %rdx, %rax # (i+1)*n+j
addq %rdx, %r8 # (i-1)*n+j
2.3 改进代码
long inj = i*n + j;
up = val[inj - n];
down = val[inj + n];
left = val[inj - 1];
right = val[inj + 1];
sum = up + down + left + right;
改进后的代码的汇编如下所示。编译后只有一个乘法。减少了6个时钟周期(一个乘法周期大约为3个时钟周期)。
imulq %rcx, %rsi # i*n
addq %rdx, %rsi # i*n+j
movq %rsi, %rax # i*n+j
subq %rcx, %rax # i*n+j-n
leaq (%rsi,%rcx), %rcx # i*n+j+n
...
对于GCC编译器来说,编译器可以根据不同的优化等级,有不同的优化方式,会自动完成以上的优化操作。下面我们介绍下,那些必须是我们要手动优化的。
3. 消除循环中低效代码
3.1 示例代码
程序看起来没什么问题,一个很平常的大小写转换的代码,但是为什么随着字符串输入长度的变长,代码的执行时间会呈指数式增长呢?
void lower1(char *s)
{
size_t i;
for (i = 0; i < strlen(s); i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
3.2 分析代码
那么我们就测试下代码,输入一系列字符串。
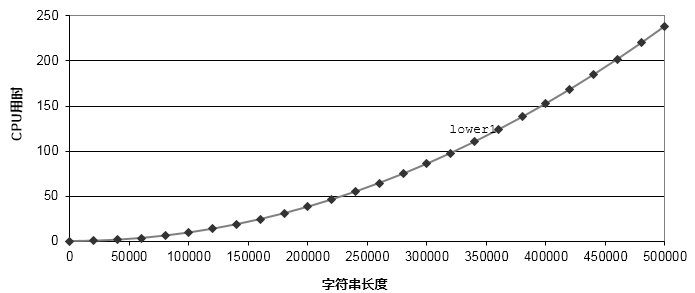
当输入字符串长度低于100000时,程序运行时间差别不大。但是,随着字符串长度的增加,程序的运行时间呈指数时增长。
我们把代码转换成goto形式看下。
void lower1(char *s)
{
size_t i = 0;
if (i >= strlen(s))
goto done;
loop:
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
i++;
if (i < strlen(s))
goto loop;
done:
}
以上代码分为初始化(第3行),测试(第4行),更新(第9,10行)三部分。初始化只会执行一次。但是测试和更新每次都会执行。每进行一次循环,都会对strlen调用一次。
下面我们看下strlen函数的源码是如何计算字符串长度的。
size_t strlen(const char *s)
{
size_t length = 0;
while (*s != '\0') {
s++;
length++;
}
return length;
}
strlen函数计算字符串长度的原理为:遍历字符串,直到遇到‘\0’才会停止。因此,strlen函数的时间复杂度为O(N)。lower1中,对于长度为N的字符串来说,strlen 的调用次数为N,N-1,N-2 ... 1。对于一个线性时间的函数调用N次,其时间复杂度接近于O(N2)。
3.3 改进代码
对于循环中出现的这种冗余调用,我们可以将其移动到循环外。将计算结果用于循环中。改进后的代码如下所示。
void lower2(char *s)
{
size_t i;
size_t len = strlen(s);
for (i = 0; i < len; i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
将两个函数对比下,如下图所示。lower2函数的执行时间得到明显提升。
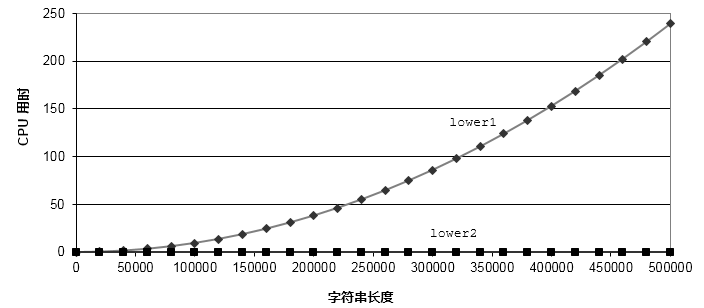
4. 消除不必要的内存引用
4.1 示例代码
以下代码作用为,计算a数组中每一行所有元素的和存在b[i]中。
void sum_rows1(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
b[i] = 0;
for (j = 0; j < n; j++)
b[i] += a[i*n + j];
}
}
4.2 分析代码
汇编代码如下所示。
# sum_rows1 inner loop
.L4:
movsd (%rsi,%rax,8), %xmm0 # 从内存中读取某个值放到%xmm0
addsd (%rdi), %xmm0 # %xmm0 加上某个值
movsd %xmm0, (%rsi,%rax,8) # %xmm0 的值写回内存,其实就是b[i]
addq $8, %rdi
cmpq %rcx, %rdi
jne .L4
这意味着每次循环都需要从内存中读取b[i],然后再把b[i]写回内存 。b[i] += b[i] + a[i*n + j]; 其实每次循环开始的时候,b[i]就是上一次的值。为什么每次都要从内存中读取出来再写回呢?
4.3 改进代码
/* Sum rows is of n X n matrix a
and store in vector b */
void sum_rows2(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
double val = 0;
for (j = 0; j < n; j++)
val += a[i*n + j];
b[i] = val;
}
}
汇编如下所示。
# sum_rows2 inner loop
.L10:
addsd (%rdi), %xmm0 # FP load + add
addq $8, %rdi
cmpq %rax, %rdi
jne .L10
改进后的代码引入了临时变量来保存中间结果,只有在最后的值计算出来时,才将结果存放到数组或全局变量中。
5. 减小不必要的调用
5.1 示例代码
为了方便举例,我们定义一个包含数组和数组长度的结构体,主要是为了防止数组访问越界,data_t可以是int,long等类型。具体如下所示。
typedef struct{
size_t len;
data_t *data;
} vec;

get_vec_element函数的作用是遍历data数组中元素并存储在val中。
int get_vec_element (*vec v, size_t idx, data_t *val)
{
if (idx >= v->len)
return 0;
*val = v->data[idx];
return 1;
}
我们将以以下代码为例开始一步步优化程序。
void combine1(vec_ptr v, data_t *dest)
{
long int i;
*dest = NULL;
for (i = 0; i < vec_length(v); i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest * val;
}
}
5.2 分析代码
get_vec_element函数的作用是获取下一个元素,在get_vec_element函数中,每次循环都要与v->len作比较,防止越界。进行边界检查是个好习惯,但是每次都进行就会造成效率降低。
5.3 改进代码
我们可以把求向量长度的代码移到循环体外,同时抽象数据类型增加一个函数get_vec_start。这个函数返回数组的起始地址。这样在循环体中就没有了函数调用,而是直接访问数组。
data_t *get_vec_start(vec_ptr v)
{
return v-data;
}
void combine2 (vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = NULL;
for (i=0;i < length;i++)
{
*dest = *dest * data[i];
}
}
6. 循环展开
6.1 示例代码
我们在combine2的代码上进行改进。
6.2 分析代码
循环展开是通过增加每次迭代计算的元素的数量,减少循环的迭代次数。
6.3 改进代码
void combine3(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc = NULL;
/* 一次循环处理两个元素 */
for (i = 0; i < limit; i+=2) {
acc = (acc * data[i]) * data[i+1];
}
/* 完成剩余数组元素的计算 */
for (; i < length; i++) {
acc = acc * data[i];
}
*dest = acc;
}
在改进后的代码中,第一个循环每次处理数组的两个元素。也就是每次迭代,循环索引i加2,在一次迭代中,对数组元素i和i+1使用合并运算。一般我们称这种为2×1循环展开,这种变换能减小循环开销的影响。
注意访问不要越界,正确设置limit,n个元素,一般设置界限n-1
7. 累计变量,多路并行
7.1 示例代码
我们在combine3的代码上进行改进。
7.2 分析代码
对于一个可结合和可交换的合并运算来说,比如说整数加法或乘法,我们可以通过将一组合并运算分割成两个或更多的部分,并在最后合并结果来提高性能。
特别注意:不要轻易对浮点数进行结合。浮点数的编码格式和其他整型数等都不一样。
7.3 改进代码
void combine4(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc0 = 0;
data_t acc1 = 0;
/* 循环展开,并维护两个累计变量 */
for (i = 0; i < limit; i+=2) {
acc0 = acc0 * data[i];
acc1 = acc1 * data[i+1];
}
/* 完成剩余数组元素的计算 */
for (; i < length; i++) {
acc0 = acc0 * data[i];
}
*dest = acc0 * acc1;
}
上述代码用了两次循环展开,以使每次迭代合并更多的元素,也使用了两路并行,将索引值为偶数的元素累积在变量acc0中,而索引值为奇数的元素累积在变量acc1中。因此,我们将其称为”2×2循环展开”。运用2×2循环展开。通过维护多个累积变量,这种方法利用了多个功能单元以及它们的流水线能力
8. 重新结合变换
8.1 示例代码
我们在combine3的代码上进行改进。
8.2 分析代码
到这里其实代码的性能已经基本接近极限了,就算做再多的循环展开性能提升已经不明显了。我们需要换个思路,注意下combine3代码中第12行的代码,我们可以改变下向量元素合并的顺序(浮点数不适用)。重新结合前combine3代码的关键路径如下图所示。
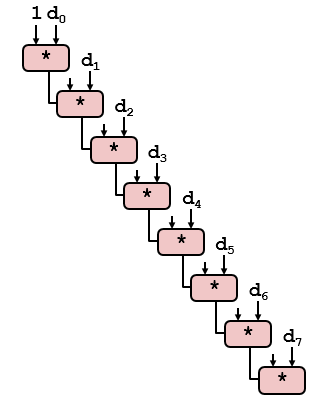
8.3 改进代码
void combine7(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
/* Combine 2 elements at a time */
for (i = 0; i < limit; i+=2) {
acc = acc OP (data[i] OP data[i+1]);
}
/* Finish any remaining elements */
for (; i < length; i++) {
acc = acc OP data[i];
}
*dest = acc;
}
重新结合变换能够减少计算中关键路径上操作的数量,这种方法增加了可以并行执行的操作数量了,更好地利用功能单元的流水线能力得到更好的性能。重新结合后关键路径如下所示。
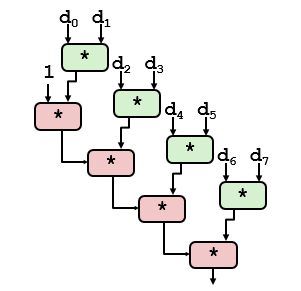
9 条件传送风格的代码
9.1 示例代码
void minmax1(long a[],long b[],long n){
long i;
for(i = 0;i,n;i++){
if(a[i]>b[i]){
long t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
9.2 分析代码
现代处理器的流水线性能使得处理器的工作远远超前于当前正在执行的指令。处理器中的分支预测在遇到比较指令时会进行预测下一步跳转到哪里。如果预测错误,就要重新回到分支跳转的原地。分支预测错误会严重影响程序的执行效率。因此,我们应该编写让处理器预测准确率提高的代码,即使用条件传送指令。我们用条件操作来计算值,然后用这些值来更新程序状态,具体如改进后的代码所示。
9.3 改进代码
void minmax2(long a[],long b[],long n){
long i;
for(i = 0;i,n;i++){
long min = a[i] < b[i] ? a[i]:b[i];
long max = a[i] < b[i] ? b[i]:a[i];
a[i] = min;
b[i] = max;
}
}
在原代码的第4行中,需要对a[i]和b[i]进行比较,再进行下一步操作,这样的后果是每次都要进行预测。改进后的代码实现这个函数是计算每个位置i的最大值和最小值,然后将这些值分别赋给a[i]和b[i],而不是进行分支预测。
10. 总结
我们介绍了几种提高代码效率的技巧,有些是编译器可以自动优化的,有些是需要我们自己实现的。现总结如下。
消除连续的函数调用。在可能时,将计算移到循环外。考虑有选择地妥协程序的模块性以获得更大的效率。
消除不必要的内存引用。引入临时变量来保存中间结果。只有在最后的值计算出来时,才将结果存放到数组或全局变量中。
展开循环,降低开销,并且使得进一步的优化成为可能。
通过使用例如多个累积变量和重新结合等技术,找到方法 提高指令级并行。
用功能性的风格重写条件操作,使得编译采用条件数据传送。