
万字长文说透分布式锁
“分布式锁”这个问题快被说烂了,奈何笔者实在没有找到一个满意的答案,故记录自己寻找答案、总结的过程。分布式锁的设计涉及了许多分布式系统相关的问题,许多地方值得推敲,非常有意思。
TL; DR
太长不看?没关系,我已经做好了思维导图,点个分享再收藏,支持一下,也方便以后查阅。
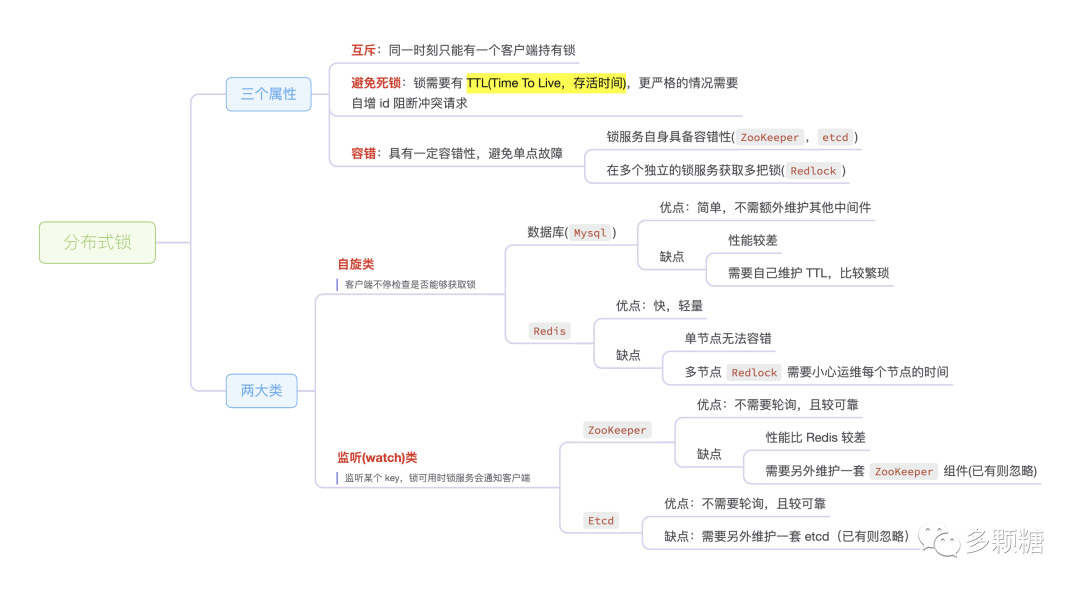
分布式锁三个属性和两大类
多线程编程通常使用 mutex 或信号量等方式进行同步;在同一个操作系统下的多进程也能通过共享内存等方式同步;但在分布式系统多进程之间的资源争抢,例如下单抢购,就需要额外的分布式锁。
分布式锁大多都是 Advisory lock,即在访问数据前先获取锁信息,再根据信息决定是否可以访问;相对的是 mandatory lock,未授权访问锁定的数据时会产生异常。
分布式锁属于分布式互斥问题(distributed mutual exclusion),实际上 Lamport 在那篇经典论文 "Time, clocks, and the ordering of events in a distributed system" 中早就证明了使用状态机能够去中心化解决多进程互斥问题,而共识算法就能实现这样的状态机。但大多时候我们还是会使用一个分布式锁而不是构建一个共识库,主要因为:
很多(业务)系统很难改造成使用共识算法,锁服务更易于保持已存在的程序结构和通信模式;
基于锁的接口更为程序员所熟悉。虽然可能只是表面熟悉 :),但肯定好过使用一个共识库;
锁服务能减少客户端系统运行的服务器数目。一个共识算法需要 quorum 做决策,即我们常说的超过半数节点可用,每个客户端都构建成 quorum 需要大量的服务器,而一套分布式锁服务可以安全地服务多个客户端。
因此,相比于客户端实现一个共识库,使用分布式锁服务耦合更松、更易用、也更节省资源。
提起分布式锁,大家可能马上会想到各种实现方式,以及一场关于基于 Redis 实现的分布式锁是否安全的论战,这些文章可能很多地方都能搜到。但在开始讨论这些东西之前,我们首先要思考,一个分布式锁到底需要具备哪些性质?
总的来说,分布式锁服务有三个必备的性质:
互斥(Mutual Exclusion),这是锁最基本的功能,同一时刻只能有一个客户端持有锁;
避免死锁(Dead lock free),如果某个客户端获得锁之后花了太长时间处理,或者客户端发生了故障,锁无法释放会导致整个处理流程无法进行下去,所以要避免死锁。最常见的是通过设置一个 TTL(Time To Live,存活时间) 来避免死锁。假设设置 TTL 为 3 秒,如果 3 秒过后锁还没有被释放,系统也会自动释放该锁(TTL 的设置要非常小心!这个时长取决于你的业务逻辑)。可是这也存在一个问题,假如进程1获取了锁,然后由于某些原因(下面会说到)没有来得及更新 TTL;3秒后进程2来获取锁,由于 TTL 已过,进程2可以获得锁并开始处理,此时同时有两个客户端持有锁,可能会产生意外行为。所以我们不能只有 TTL,还需要给锁附加一个唯一 ID (或 fencing token)来标识锁。上述逻辑中,当进程 1 获取到锁后记为 LOCK_1;TTL 过后进程 2 获取到的锁记为 LOCK_2。之后,我们可以在应用层面或锁服务层面检查该 id,来阻断旧的请求。
容错(Fault tolerance),为避免单点故障,锁服务需要具有一定容错性。大体有两种容错方式,一种是锁服务本身是一个集群,能够自动故障切换(ZooKeeper、etcd);另一种是客户端向多个独立的锁服务发起请求,其中某个锁服务故障时仍然可以从其他锁服务读取到锁信息(Redlock),代价是一个客户端要获取多把锁,并且要求每台机器的时钟都是一样的,否则 TTL 会不一致,可能有的机器会提前释放锁,有的机器会太晚释放锁,导致出现问题。
值得注意的是,容错会以性能为代价,容错性取决于你的系统级别,如果你的系统可以承担分布式锁存在误差,那么单节点或者简单的主从复制也许就能满足;如果你的系统非常严格,例如金融系统或航天系统,那么就要考虑每个 corner case——本文更倾向于讨论后者。
我们会拿着这三个属性逐一分析各种分布式锁的实现。在此之前,先把分布式锁分为两大类:自旋类和监听类。
自旋类包括基于数据库的实现和基于 Redis 的实现,这类实现需要客户端不停反复请求锁服务查看是否能够获取到锁;
监听类主要包括基于 ZooKeeper 或 etcd 实现的分布式锁,这类实现客户端只需监听(watch) 某个 key,当锁可用时锁服务会通知客户端,无需客户端不停请求锁服务。
因此,本文默认读者大概了解 Redis、ZooKeeper 和 etcd 是什么。
如此,我们在头脑中已经有了一个很好的框架,现在开始往思维导图中填充知识。
基于数据库的实现
最简单的,我们想到通过某个独立的数据库(或文件),当获取到数据时,往数据库中插入一条数据。之后的进程想要获取数据,会先检查数据库是否存在记录,就能够知道是否有别的进程持有锁,这便实现了分布式锁的互斥性。
数据库可以通过主从同步复制来实现容错,虽然主从复制切换时不会非常轻松,可能需要管理员参与。
为了避免死锁,我们需要增加时间戳字段和自增 id 字段,同时在后台启动一个线程定时释放和清理过期的锁。
| 字段 | 作用 |
|---|---|
| id | 自增 id,唯一标识锁 |
| key | 锁名称 |
| value | 自定义字段 |
| ttl | 存活时间,定时清理,避免死锁 |
可见基于数据库的实现较为繁琐,要自己维护锁的 TTL;除非使用分布式数据库,否则主从复制的故障切换并不轻松。
除了麻烦之外,如果经常用数据库你也知道,在高并发常见下数据库读写是非常缓慢的,会导致我们的系统性能存在瓶颈。如果采用多个独立数据库进行容错,那性能就更差了。
于是,为了分布式锁的性能,开始转向基于 Redis 或者 memcache 等内存存储系统来实现分布式锁。
基于 Redis 的实现
分布式锁最多的恐怕就是基于 Redis 的实现。首先我们从单节点 Redis 开始。
基于单节点 Redis 的分布式锁
总的来说就是一条命令实现写 key + 设置过期时间,否则原子性无法保证可能出现死锁。于是就有了以下命令:
set key value nx px 10000
set 命令后的 5 个参数分别是:
第一个为 key 作为锁名;
第二个为 value,一般传入一个唯一 id,例如一个随机数或者客户端 mac 地址 + uuid;
第三个为 NX,意思是 SET IF NOT EXIST,即只有 key 不存在时才进行
set操作;若 key 已经存在(锁已被占),则不做任何操作;第四个为 PX,作用是给这个 key 加一个过期时间,具体时间长短由第五个参数决定;
第五个为具体的过期时间,对应第四个参数 PX 是毫秒,EX 是秒;
这个方案在互斥性和避免死锁上性能良好,且非常轻量。但单节点的 Redis 存在单点故障。注意,Redis 主从复制是异步的,所以加入从节点会增加破坏互斥性的风险。为了实现容错性,就有了基于多节点 Redis 的分布式锁,即 Redlock。
基于多节点 Redis 的分布式锁
Redlock 用到多个独立的 Redis 节点,其思想简而言之,是在多个 Redis 实际都获取锁,其中一个宕机了,只要还有超过半数节点可用,就可以继续提供锁服务。
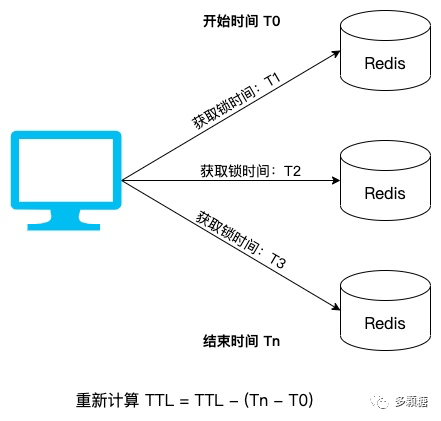
如图所示,Redlock 获取锁的大致步骤如下,:
依次对多个 Redis 实例进行加锁(一般是3个或5个),加锁命令使用单实例 Redis 的加锁命令;
为了避免在某个节点长时间获取不到锁而阻塞,每次获取锁操作也有一个超时时间,远小于 TTL,超过超时时间则认为失败,继续向下一个节点获取锁;
计算整个获取多把锁的总消耗时间,只有在超过半数节点都成功获取锁,并且总消耗时间小于 TTL,则认为成功持有锁;
成功获取锁后,要重新计算 TTL = TTL - 总消耗时间;
如果获取锁失败,要向所有 redis 实例发送释放锁的命令。
释放锁操作就是向所有实例都发送删除 key 命令。
Redlock 容错性依赖于一个时间戳的计算,这在分布式系统中并不受待见,于是有了一场著名的论战。
Redlock 论战

DDIA 的作者 Martin Kleppmann 大佬发表了著名的文章《How to do distributed locking》,表示 Redlock 并不可靠,该文章主要阐述了两个观点:
Redis 命令避免了死锁但可能会不满足互斥性,因为没有自增 id 或 fencing token 来阻断同时获得锁的两个客户端;
Redlock 基于时间戳的合理性值得怀疑,多台服务器难以保证时间一致;
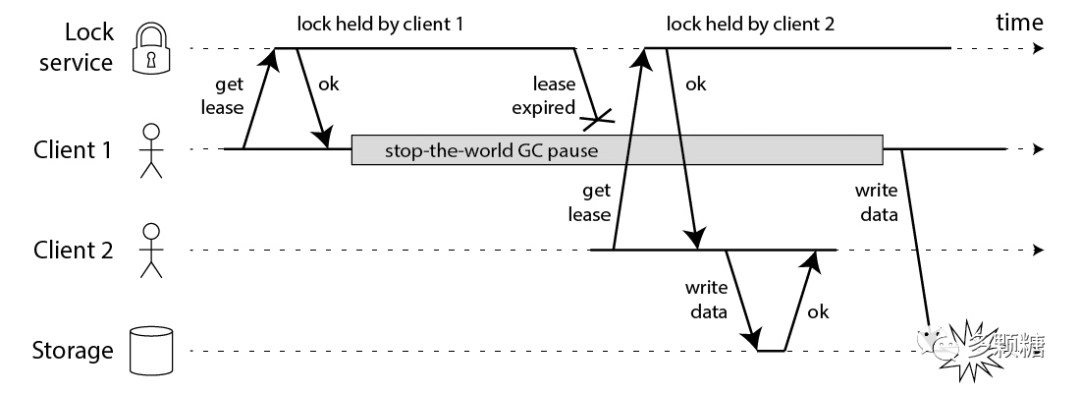
第一点如下图所示,Client 1 获取锁后发生了 STW GC(或缺页等问题),TTL 过期后 Client 2 获取了锁,此时两个客户端持有锁,违反了互斥性。后续写操作自然就可能存在问题。
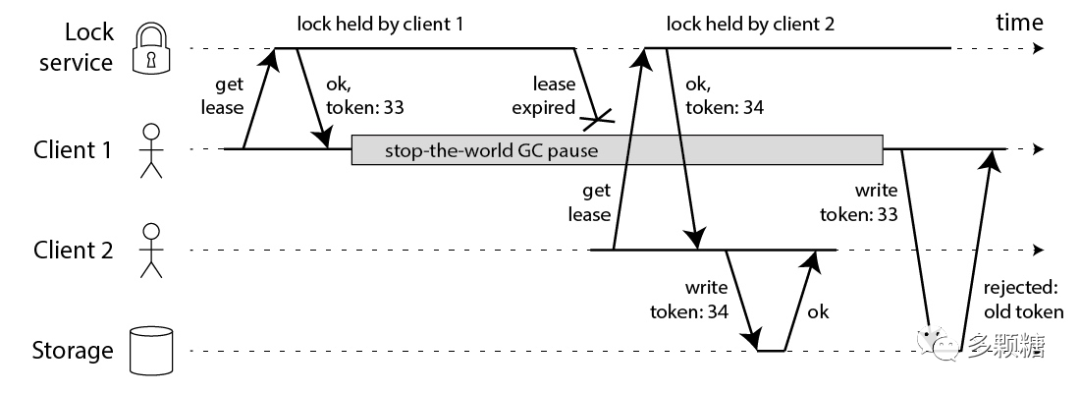
我们在避免死锁时提到,需要另外用单调递增 id (Martin 称之为 fencing token,也叫序列号)来标识每一个锁。增加 id 后逻辑如下图所示,最后的 Client 1 的写请求因为 token 是旧的,会被存储系统拒绝。
第二点 Martin 认为,Redlock 的时间戳计算方式不可靠,每台服务器的走时并不绝对准确,例如 NTP 进行同步时系统会发生时钟漂移,即当前服务器的时间戳突然变大或变小,这都会影响 Redlock 的计算。
Martin 的这篇文章引起了大家对分布式锁广泛讨论。Redis 作者 antirez 也不甘示弱,发表文章《Is Redlock safe?》进行反驳,回应了上述两个问题,我总结了 antirez 的论点:
针对第一点,虽然 Redlock 提供不了自增 id 这样的字段,但是由客户端指定的字段 value 也可以实现唯一标识,并通过 read-modify-write 原子操作来进行检查;
时钟发送漂移肯定会影响 Redlock 安全性,可是通过恰当的运维,例如不要随意人为修改时钟、将一次大的 NTP 时钟调整转换成多次微小的调整等方式,使时钟修改不超过某个范围就不会对 Redlock 产生影响。
非常推荐阅读争论的两篇文章,但篇幅所限我只提取了观点。关于争论的详细内容张铁蕾老师的文章《基于Redis的分布式锁到底安全吗(下)?》也有着比较完整的中文回顾。
对于这两个问题,我想谈谈我的理解。
对于第一个问题,文章开头“三大属性”我们就分析过,增加 TTL 来避免死锁就会对互斥性产生影响,无论基于 Redis 还是基于 Zookeeper 实现都会存在该问题。antirez 观点是 Redlock 也可以用 value 作为唯一标识来阻断操作,这确实没问题,我也挑不出毛病。但我们可以思考下,实际编程中读者您觉得使用一个自增 id 进行判断容易还是使用 read-modify-write 操作更容易呢?(实际上,一开始我都不怎么理解什么是 read-modify-write 操作)
我认为 fencing token 是一个更好的解决方案,一个单调自增的 id 更符合我们的直觉,同时也更好进行 debug。
作为 fencing token 的一个实际参考,Hazelcast 的文章 "Distributed Locks are Dead; Long Live Distributed Locks!" 给出了一个 FencedLock 解决方案,并且通过了 Jepsen 测试。
第二个问题,时钟漂移是否应该引起注意呢?antirez 的观点是时钟确实会影响 Redlock,但可以通过合理运维避免。
Julia Evans(也是很出名的技术博主)也写了一篇后续文章 "TIL: clock skew exists",来讨论时钟漂移的问题是否真的值得引起注意。最终得出的结论是:有界的时钟漂移不是一个安全的假设。
事实上,时钟问题并不罕见,例如:
Nelson Minar 在1999年发表了论文,通过调查发现,NTP 服务器经常提供不正确的时间;
aphyr 的文章《The trouble with timestamps》也总结了时间戳在分布式系统中的麻烦;
Google 在 Spanner 中投入大量精力来处理时间问题,并发明了 TrueTime 这一授时系统;
闰秒也会导致时钟漂移,不过闰秒确实非常罕见(即使是现在,闰秒依然会导致许多问题,以后我们会专门谈谈)。
通过上述例子,时钟问题是真实存在的,如果你的系统对分布式锁的安全性要求严格,不想造成任何系统和金钱上的损失,那么你应该考虑所有的边缘情况。
Martin Kleppmann 没有回复任何 Hacker News 的评论,他觉得自己想要表达的都已经说完了,他不想参与争论,他认为实际上一个分布式系统到底该怎么做取决于你如何管理你的系统。
本文想表达的也是这样的观点,软件工程没有银弹,这些 trade-off 取决于你系统的重要级别,你怎么管理你的分布式系统。
只不过分布式系统研究人员通常会非常关注那些看似非常不可能在你的电脑上发生的事情(例如:时钟偏移),原因是:
需要找出某个算法来解决此类问题,因此需要考虑所有 corner case;
分布式系统中会有成千上万的机器,那么不大可能发生的事情会变得极有可能;
其中一些问题其实是很常见的(例如:网络分区)。
基于 ZooKeeper 实现
除了 Redlock,还有哪些既能容错又能避免死锁的方式呢?
容错性当然离不开我们的老朋友共识算法,我们不再让客户端依次上多个锁,而是让锁服务器通过共识算法复制到多数派节点,然后再回复客户端。由于共识算法本身不依赖系统时间戳而是逻辑时钟(Raft 的任期或 Paxos 的 epoch),故不存在时钟漂移问题。
其次,死锁避免问题依然需要 TTL 和自增 id 等手段,我们通过锁服务给每次加锁请求标识上单调递增 id。
通过以上两种方法,我们可以得到一个更可靠的分布式锁。代价是,我们需要一个实现共识算法的第三方组件。下文主要介绍三个此类实现:ZooKeeper、etcd 和 Chubby。
ZooKeeper 是一个分布式协调服务,参见:《ZooKeeper 设计原理》。
基于 ZooKeeper 实现的分布式锁依赖以下两个节点属性:
sequence:顺序节点,ZooKeeper 会将一个10位带有0填充的序列号附加到客户端设置的 znode 路径之后。例如locknode/guid-lock-会返回locknode/guid-lock-0000000001;ephemeral:临时节点,当客户端和 ZooKeeper 连接断开时,临时节点会被删除,能够避免死锁。但这个断开检测依然有一定心跳延迟,所以仍然需要自增 id 来避免互斥性被破坏。
ZooKeeper 官方文档有提供现成的分布式锁实现方法:
首先调用
create(),锁路径例如locknode/guid-lock-,并设置sequence和ephemeral标志。guid是客户端的唯一标识,如果create()创建失败可以通过guid来进行检查,下面会提到;调用
getChildren()获取子节点列表,不要设置 watch 标志(很重要,可以避免 Herd Effect,即惊群效应);检查 2 中的子节点列表,如果步骤 1 中创建成功并且返回的序列号后缀是最小的,则客户端持有该分布式锁,到此结束;
如果发现序列不是最小的,则从子节点列表中选择比当前序列号小一位的节点记为 p,客户端调用
exist(p, watch=true),即监听 p,当 p 被删除时收到通知(该节点只有比自己小一位的节点释放时才能获得锁);如果
exist()返回 null,即前一个分布式锁被释放了,转到步骤 2;否则需要一直等待步骤 4 中 watch 的通知。
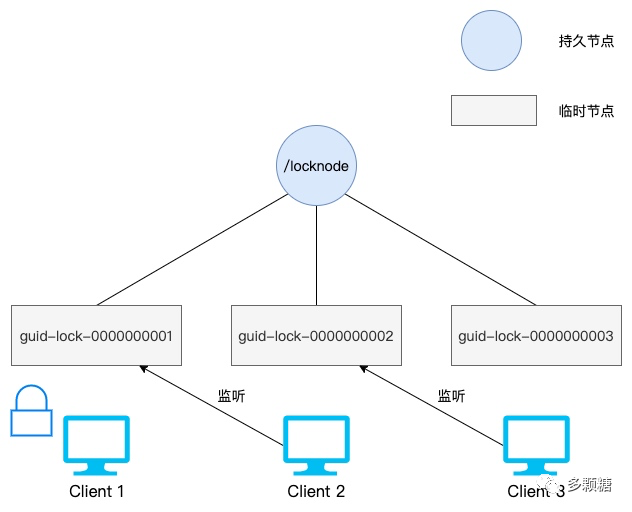
如上图所示,每个客户端只监听比自己小的 znode,可以避免惊群效应。
获取锁的伪代码如下:
n = create(l + “/guid-lock-”, EPHEMERAL|SEQUENTIAL)
C = getChildren(l, false)
if n is lowest znode in C, exit
p = znode in C ordered just before n
goto 2
释放锁非常简单:客户端直接删除他们在步骤 1 创建的 znode 节点。
有几点需要注意:
删除一个 znode 只会导致一个客户端被唤醒,因为每个节点正好被一个客户端 watch 着,通过这种方式,可以避免惊群效应;
没有轮询或超时;
如果在调用
create()时 ZooKeeper 创建锁成功但没有返回给客户端就失败了,客户端收到错误响应后,应该先调用getChildren()并检查该路径是否包含 guid 来避免这一问题。
当然,虽然 ZooKeeper 的实现看起来更为可靠,但根据你实现锁的方式,可能还是会有大量的锁逻辑调试、锁争抢等问题。
基于 ZooKeeper 的分布式锁性能介于基于 Mysql 和基于 Redis 的实现之间,性能上当然不如单节点 Redis。
ZooKeeper 的另一个缺点是需要另外维护一套 ZooKeeper 服务(已有则忽略)。
etcd
Etcd 是著名的分布式 key-value 存储结构,因在 Kubernetes 中使用而闻名。etcd 同样可以用来实现分布式锁,官方也很贴心的提供了 clientv3 包给开发者快速实现分布式锁。
我们来看下 etcd 是如何解决分布式锁“三大问题”的:
互斥:etcd 支持事务,通过事务创建 key 和检查 key 是否存在,可以保证互斥性;
容错:etcd 基于 Raft 共识算法,写 key 成功至少需要超过半数节点确认,这就保证了容错性;
死锁:etcd 支持租约(Lease)机制,可以对 key 设置租约存活时间(TTL),到期后该 key 将失效删除,避免死锁;etc 也支持租约续期,如果客户端还未处理完可以继续续约;同时 etcd 也有自增 id,在下文介绍。
为了帮助开发者快速实现分布式锁,etcd 给出了 clientv3 包,其中分布式锁在 concurrency 包中。按照官方文档给出的案例1,首先创建一个新的会话(session)并指定租约的 TTL,然后实例化一个 NewMutex() 之后就可以调用 Lock() 和 Unlock() 进行抢锁和释放锁。代码如下:
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
s, err := concurrency.NewSession(cli, concurrency.WithTTL(10))
if err != nil {
log.Fatal(err)
}
defer s.Close()
m := concurrency.NewMutex(s, "/my-lock/")
if err := m.Lock(context.TODO()); err != nil {
log.Fatal(err)
}
fmt.Println("acquired lock for s")
if err := m.Unlock(context.TODO()); err != nil {
log.Fatal(err)
}
fmt.Println("released lock for s")
其中 Lock() 函数的源代码很容易找到,由于篇幅我就不放出来了,但源代码中可以看到的一些其他机制包括:
Revision 机制。一个全局序列号,跟 ZooKeeper 的序列号类似,可以用来避免 watch 惊群;
Prefix 机制。即上述代码中 etcd 会创建一个前缀为
/my-lock/的 key(/my-lock/+ LeaseID),分布式锁由该前缀下 revision 最小(最早创建)的 key 获得;Watch 机制。跟 ZooKeeper 一样,客户端会监听 revision 比自己小的 key,当比自己小的 key 释放锁后,尝试去获得锁。
本质上 etcd 和 ZooKeeper 对分布式锁的实现是类似的。
选择 etcd 的原因可能有:
生产环境中已经大规模部署了 etcd 集群;
etcd 在保证强一致性的同时真的够快,性能介于 Redis 和 ZooKeeper 之间;
许多语言都有 etcd 的客户端库,很容易使用;
Chubby
最后简要谈一下 Chubby。由于 Chubby 没有开源,没法直接使用,细节也难以得知,很少会有造一个 Chubby 的需求(虽然我老东家真的用 C++ 造了一个)。因此,Chubby 部分只是 Paper 读后感,不感兴趣的读者可以跳过。
Chubby 是 Google 研发的松耦合分布式锁服务,此外 GFS 和 BigTable 使用 Chubby 来存储一些元数据。Chubby 有以下几大特点:
粗粒度(Coarse-grained)。相对于细粒度(Fine-grained),粗粒度锁会持续几小时或几天;
可用性、可靠性;
可以存储一些元数据;
大量廉价机器部署;
Chubby 依赖于 Paxos 共识算法来实现容错,数据以 UNIX 文件系统方式进行组织(称为 Node),同样有 Ephemeral 类型的临时节点,断开连接后会被删除;支持监听某个 Node——总而言之,我们可以从 ZooKeeper 上看到许多 Chubby 的影子,ZooKeeper 和 Chubby 解决的问题是比较类似的,因此很多人认为 ZooKeeper 是 Chubby 的开源实现,不过两者的具体架构还是略有不同。

为了容错,一个 Chubby 集群包含 5 个节点,组成一个 Chubby cell。这 5 个节点只有一个是 master 其余都是 replicas,只有 Master 能够处理请求和读写文件,其它副本节点通过 Paxos 算法复制 Master 的行为来容错。
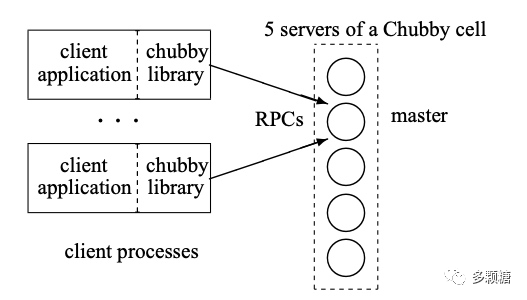
Chubby 还支持:
Sequencer:锁的序列号(更好的避免死锁和 watch);Session:客户端会话,包括租约时间;KeepAlive:在租约快要过期时可以发送KeepAlive续约;Cache:锁服务支持大量的客户端,为了减少读请求支持客户端无感知的缓存;
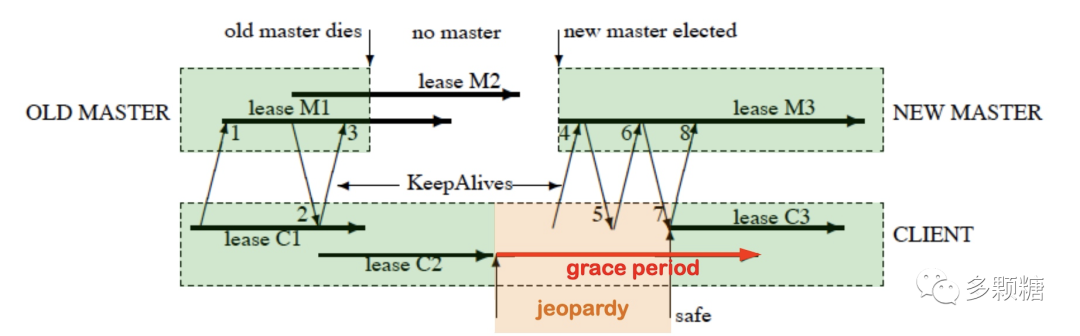
比较有意思的是 Chubby 的故障恢复。当 Master 发生故障,其内存的 session 和锁信息会丢失,session 中最重要的租约信息,Paxos 算法会选举出新的 Master,然后:
选择新的 epoch,可以理解为 Raft 中的任期,小于 epoch 的客户端请求会被拒绝,保证了 Master 不会响应旧 Master 的请求;
根据数据库(持久化存储)中的数据恢复出 session 和锁相关信息,并将 session 租约延长到一个可能的最大期限;
只接受 KeepAlive 请求;下图步骤 4 中第一个 KeepAlive 请求会由于epoch错误而被 Maser 拒绝,但客户端也因此获得了最新的 epoch;步骤 6 中第二个 KeepAlive 成功,由于上一步延长的租约够长,步骤 7 的响应会延长客户端本地的租约时间;接着恢复正常的通信。
从新请求中发现老 Master 创建的 Handle 时,新 Master 也需要重建,一段时间后(一般是一分钟),删除没有 Handle 的临时节点。
整个过程如图所示。其中绿色都是安全时期,橙色部分是危险时期,Chubby 集群切换到新的 Master。
Chubby 我不想太过深入,我想大家没有再造一个 Chubby 的动力了。
结语
写这篇文章的时候内心是忐忑的,为了 ego 和不被大家骂我尽量不犯错,但错误实在难免,并且随着时间推移可能两三年后一些解决方案并不适用。这篇文章实在花了我许多时间和精力。
想要深入分布式锁问题的同学,我推荐好好看一遍 Lamport 的 "Time, clocks, and the ordering of events in a distributed system",当然我的新书里也有对该论文的剖析,下半年会跟大家见面。
最后,本文如有不妥之处,希望读者能够留言指出,我会积极改正。
Reference
1. Lamport, Leslie. "Time, clocks, and the ordering of events in a distributed system." Concurrency: the Works of Leslie Lamport. 2019. 179-196.
2. How to do distributed locking, https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
3. Is Redlock safe?, http://antirez.com/news/101
4. Distributed Locks are Dead; Long Live Distributed Locks! https://hazelcast.com/blog/long-live-distributed-locks/
5. TIL: clock skew exists,http://jvns.ca/blog/2016/02/09/til-clock-skew-exists/
6. A Survey of the NTP Network, http://alumni.media.mit.edu/~nelson/research/ntp-survey99/
7. The trouble with timestamps, https://aphyr.com/posts/299-the-trouble-with-timestamps
8. Corbett, James C., et al. "Spanner: Google’s globally distributed database." ACM Transactions on Computer Systems (TOCS) 31.3 (2013): 1-22.
9. Hunt, Patrick, et al. "ZooKeeper: Wait-free Coordination for Internet-scale Systems." USENIX annual technical conference. Vol. 8. No. 9. 2010.
10. ZooKeeper 实现分布式锁官方文档, https://zookeeper.apache.org/doc/r3.7.0/recipes.html#sc_recipes_Locks
11. etcd 实现分布式锁官方案例,https://github.com/etcd-io/etcd/blob/main/tests/integration/clientv3/concurrency/mutex_test.go
12. Burrows, Mike. "The Chubby lock service for loosely-coupled distributed systems." Proceedings of the 7th symposium on Operating systems design and implementation. 2006.
推荐阅读