
一次奇怪的服务器响应延时分析
摘要:这是一份基于netinside系统进行“预见”性巡检的工作日志,基于netinside系统提供的潜在问题线索,结合wireshark工具使用,探究表面现象下的本质,建立不同业务下TCP协议的使用模型,是为高质量运维的关键因素。
一、预见性巡检
基于netinside系统,进行“预见”性巡检。在检查到主机时,发现有台主机表现有些奇怪。如下:

43这台关键主机,服务器的响应延时竟然有1秒多。因为表单中看到的数据是个平均值,所以时延分布情况,需要时一步确认。在单个IP最终用户体验分析中,搜索43的主机,情况如下:

发现这台主机的服务器响应延时都在秒级波动,最高值达到4秒,基于采样时间原因,我们有理由相信真实延时肯定会更大,且在同时间段,几乎没有流量,那么这个现象就比较奇怪了。
没有连接失败请求,没有多大流量,但服务器响应延时较大,因为生产网都是千M网络,看上去根本不存在影响时延的因素,所以什么原因导致此情况,值得探究。
为了进一步分析,我们在netinside系统里面,把这台主机在时间点13:36前后的数据包下载下来(按时间点下载主要是为了减少数据包的大小,更精准分析问题),导入wireshark,一探究竟。
二、探究真像
因为服务器的响应时间,本质上就是RTT(RoundTrip Time),即往返时间。测量方法是发送一个特定序号的字节,并记录时间。
当收到确认的ACK之后,把ACK的时间,减掉之前记录的发送时间,就可以得到RTT值,该值比较大时,通常会被专家系统诊断为“网络或服务器繁忙“。
2.1,配置wireshark
数据包导入wireshark后,分析RTT需要先进行简单配置,如下:

该步骤是开启TCP会话时间戳计算,默认可能已经开启,如果没有开启的话,手动按上面方法开启即可,然后按以下方法,把RTT应用为列:

列的名字,可以自行修改。需要注意的是,这个时间戳是由发送端系统依据自己的时钟打上去的,如果系统时间本身有误,则会给分析带来困扰,所以分析之前,先要确认各系统,包括抓包系统的时间没有问题。
2.2,RTT分析
经过上个步骤的配置,在wireshark中分析RTT就很简单了,只要在“应用显示过滤器”中,输入“tcp.analysis.ack_rtt > 4”,然后回车就可以了。
里面的“4”,就是我们在netinside系统中看到的4秒延迟,因为我们确定实际延迟比会比这个大,所以我们只要">4"即可,结果如下图:

通过过滤,我们可以快速找到RTT>4数据包,因为我们之前是精确定位下载,所以可以看到有一个数据包的RTT值是9秒多,这与我们推测符合。
很显然,光看一个数据看不出什么情况,此时我们就需要把绿色框中“86”记下,并通过这个流ID,把这个数据包相关的流过滤出来进行分析,如下图:

把TCP流过滤出来后,发现个奇怪地方,即>4的RTT好像有三个(红框),而我们刚才过滤时,只看到了9.99的这个,那么为什么10秒的就不算RTT呢?
这个是不是wireshark有问题?请注意绿框,数据长度为0的ACK,我们先把TCP流图打开看下,如下图:

通过上图,我们可以看到两个间隔10秒,都是由43产生的,并非是一个有效的交互,上下两个报文的seq及ACK都相同。
这种现象原因是,上面playload长度为0的ACK仅仅是通知对端滑窗,因为没有传数据,所以对端不再响应,处于等待状态。
而后43开始正常发送数据时,接着使用相同的SEQ与ACK,这样就把TCP的交互继续流动起来。所以,这个10秒是由43本身等待造成,不算是RTT,而真正算RTT的就是绿框标注的,即9秒的那个交互。
由此产生的一个疑问就是,43到底在干什么,在一个TCP的交互中,总是会停下来休息一伙?我们接着查看触码内容,如下图:

基于解码内容,基本可以推断,这可能是一个操作mongoDB的定时任务,这样话,前面的间隔10秒与第三条间隔9秒的,本质上没有太大区别,都属于43向170的请求。
也就是说43主机每间隔差不多10秒左右就会发一个请求给170。因为是请求间隔,所以我们基本认为,这种延迟理论上不影响实际业务。
不过需要注意的是,netinsdie系统里面看到是43这台服务器的响应延时,而我们分析的实际情况是43服务器的请求延时,这明明就是两个概念,这两种不同的延时对是否存在问题的判断是有显著区别的,那这是什么问题呢?
实际上,在一个TCP流里面,其实是无法区别应用请求方向的,TCP的主动打开还是被动打开,并不能决定应用层哪个是请求,哪个是响应,所以站点TCP层的角度,方向是可以切换分析,如下图:

从43往170这个方向看,服务器延时(RTT)在0.3MS左右,所以很显然,170的响应延时挺正常。而如果我们切换方向,则会如下:

从上可以看到,切换方向后,就有一个近10秒的延迟,而从TCP层看,这个延迟是由43来响应产生的,而我们通过上面的分析也就知道,这其实是43的请求间隔,而非响应延迟。
所以,如果站在43是台服务器的角度,把这个10秒延迟归到服务器响应延迟里面,从TCP的角度是完全没有问题的。
三、在netinside系统中,把“预见”进行到底
从刚才的分析中,我们在wireshark里面对问题抽丝剥茧,进行了透视,得出明确的结论。那么,我们是否可以在netinside里面,预见到更一步的信息或问题边界呢?
比如,RTT值,会包含网络、服务器及应用对业务请求的响应的总体延时,那么是否可直接在netinside里面界定边界,确认问题方向,减少wireshark的使用或使用复杂度呢?
这当然是可以的,通过简单配置,我们可以在netinside的数据分析里面建立一个基于分析目标的简易模型,我们一起来看下netinside的强大,如下图:
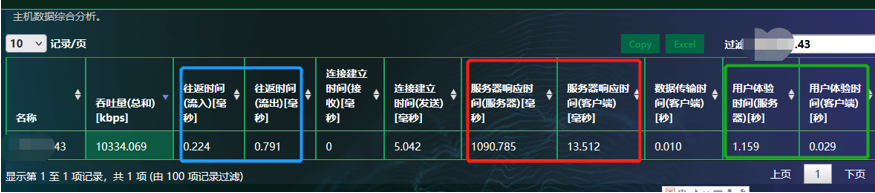
在netinside系统里面,把RTT分成了两种情况,一种是不带业务请求的,直接称之为往返时间,见蓝框,一种是带业务请求的,叫服务器响应时间,见红框。
一般情况下,不带业务请求的,通常是在三次握的时候,所以也被叫做IRTT,这个时间,基本只包含网络与服务器内核响应延时,所以会当做业务分析延时的一个基准。
在wireshark里面,如果你抓包有抓到三次握手,那么它会聪明的把这两个时间放在一起,供我们分析,如下图:
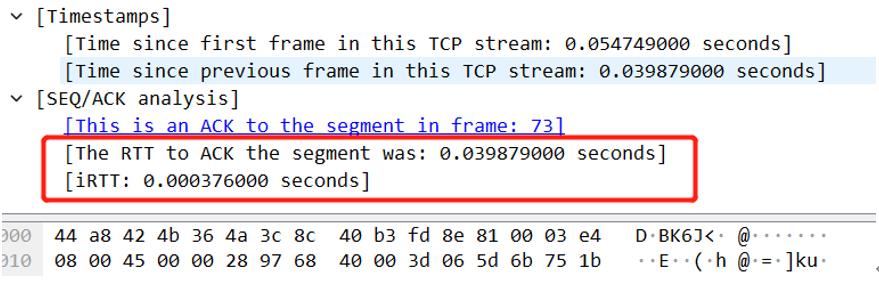
所以,基于这两个数值的对比,我们就可以大概率确定,问题所在方向,是应用还是网络或服务器本身。而且通过服务器响应延时的方向,即服务端或者客户端,我们也可以看到与wireshark中切换方向看到的同一效果。
到这阶段,我们基本上可以预见,应用可能存在问题,只不过,这种问题,对于业务来讲,是正常还是不正常,我们就得看业务逻辑了,而这个时候,就只能导到wireshark中去解个码。
四、结语
通过netinside预见性巡检,我们识别到特定服务器响应延时存在异常,基于TCP交互的理解,认为这里面可能存在潜在问题。但经过使用wireshark更细致分析,我们发现延时产生的原因,来自定时任务,也就是说业务实质上没有问题。
从这里我们可以看到,基于TCP层的性能分析,需要结合到实际的业务场景中,不同的业务特性,对TCP的使用,有不同的表现,不一定都是性能问题。
虽然本次巡检并没有挖掘出直正的潜在问题,但对于内部不同业务场景下,对TCP的使用建立模型,标定基线,是后续进一步高效运维,快速发现并排除潜在业务影响的关键基础。
jansen@FuZhou
jingshne#outlook.com
qjs@netinside.com.cn