
谨慎使用!从入门到精通,一文带你学会Python面向监狱爬虫
共 3524字,需浏览 8分钟
·
2021-01-28 12:57
网络爬虫简单来说,就是从网络中批量获取自己想要的数据。
网上爬取数据有两种方法可以实现:
使用官方 API
网络抓取
API (应用程序接口)是为了以标准的方式在不同的系统之间交换数据。但是,大多数时候,网站所有者并不提供任何 API。在这种情况下,我们只能使用 web 抓取提取数据了。
基本上,每个 web 页面都以 HTML 格式从服务器返回,这意味着我们的实际数据被很好地包装在 HTML 元素中。这使得检索特定数据的整个过程非常简单和直接。
本教程将是一个自始至终的指南,让你可以尽可能简单的使用 Python学习爬虫。首先,我将向你介绍一些基本的示例,让你熟悉 web 抓取。稍后,我们将使用这些知识从 Livescore.cz 中提取足球比赛的数据。
开始
为了让我们开始,你需要启动一个新的 Python3 项目,并安装 Scrapy (一个用于 Python 的 web 爬虫库)。我在本教程中使用了 pipenv,但是你也可以使用 pip 和 venv,或 conda。
pipenv install scrapy # Pipenv 安装 scrap现在,你已经有了 Scrapy,但是你仍然需要创建一个新的 web 抓取项目,为此 Scrapy 提供了一个命令行,可以为我们完成这项工作。
现在,让我们使用 scrapy clii 创建一个名为 web _ scraper 的新项目。
如果你像我一样使用 pipenv,请使用:
pipenv run scrapy startproject web_scraper或者在你自己的虚拟环境中,使用:
scrapy startproject web_scraper这将在工作目录中创建一个基本项目,其结构如下:


首先,我们导入了 Scrapy 库,因为我们需要它的功能来创建一个Python web spider。这个爬虫随后将用于抓取指定的网站和提取有用的信息。
我们创建了一个类,并将其命名为LiveCodeStreamSpider。基本上,它继承了 scrapy。这就是为什么我们把它作为一个参数来传递。
现在,重要的一步是使用一个名为 name 的变量为你的 spider 定义一个唯一的名称。请记住,不允许使用现有 spider 的名称。同样,不能使用此名称创建新的爬行器。它必须在整个项目中是独一无二的。
之后,我们使用 start_urls list 传递网站 URL 。
parse() 的方法,该方法将在 HTML 代码中定位标记并提取其文本。在 Scrapy,有两种方法可以在源代码中找到 HTML 元素。这些都在下面提到:
CSS 和 XPath
pipenv run scrapy crawl lcs -o lcs.json scrapy crawl lcs -o lcs.json[ {"logo": "Live Code Stream"} ]比赛名称 比赛时间 A队队名 A队进球数 B队队名 B队进球数 etc. 等等

像往常一样,导入 Scrapy 创建一个类,该类继承 scrapy.Spider 给我们的爬虫取一个独一无二的名字 LiveScoreT 提供 livescore.cz 的URL 最后,用 parse() 函数遍历所有匹配的包含竞赛名称的元素,并使用 yield 将其连接在一起。最后,我们会收到今天有比赛的所有比赛名称。需要注意的一点是,这次我使用了 CSS 而不是XPath。
pipenv run scrapy crawl LiveScoreT -o ls_t.json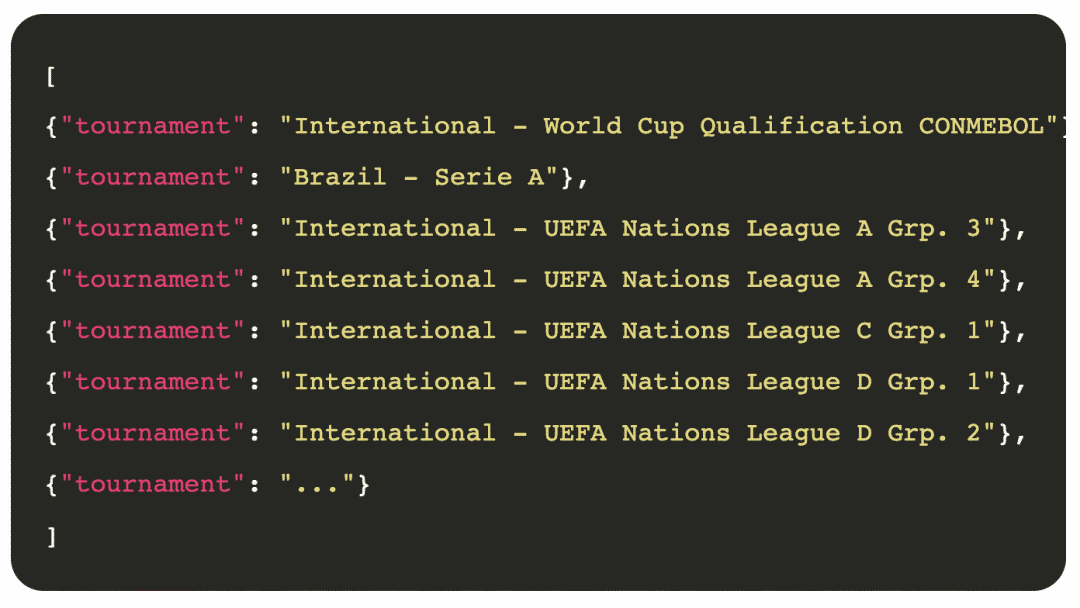

pipenv run scrapy crawl LiveScore -o ls.json
https://thenextweb.com/syndication/2020/11/23/a-beginners-guide-to-web-scraping-with-python-and-scrapy/
恋习Python 关注恋习Python,Python都好练 好文章,我在看❤️