
深度学习debug沉思录!
Datawhale
共 7881字,需浏览 16分钟
·
2020-08-18 01:32
原文丨https://zhuanlan.zhihu.com/p/158739701
前言
1、在分类问题中,损失函数及其快速得下降为0.0000
2、在正则化的过程中对神经网络的偏置也进行了正则
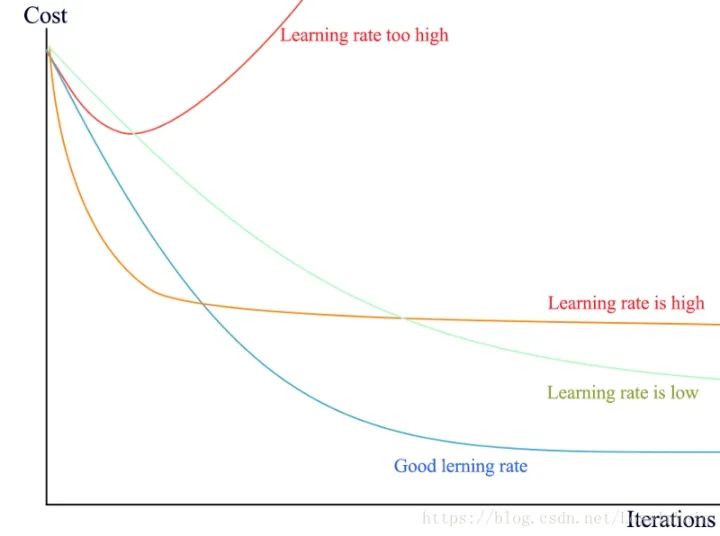
3、学习率太大导致不收敛

4、别在softmax层前面的输入施加了激活函数
5、检查原数据输入的值范围
6、别忘了对你的训练数据进行打乱
7、一个batch中,label不要全部相同
8、少用vanilla SGD优化器
9、检查各层梯度,对梯度爆炸进行截断
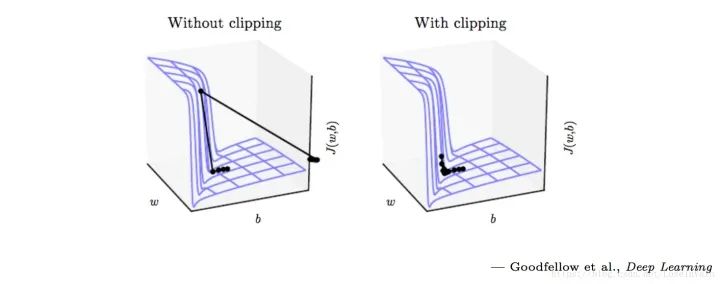
tf.clip_by_value(t,clip_value_min, # 指定截断最小值clip_value_max, # 指定截断最大值name=None)
10、检查你的样本label
11、分类问题中的分类置信度问题
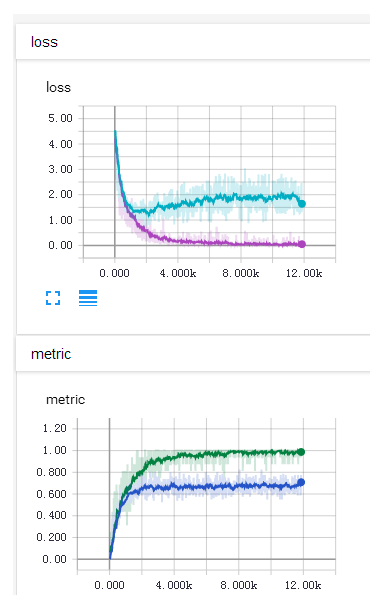
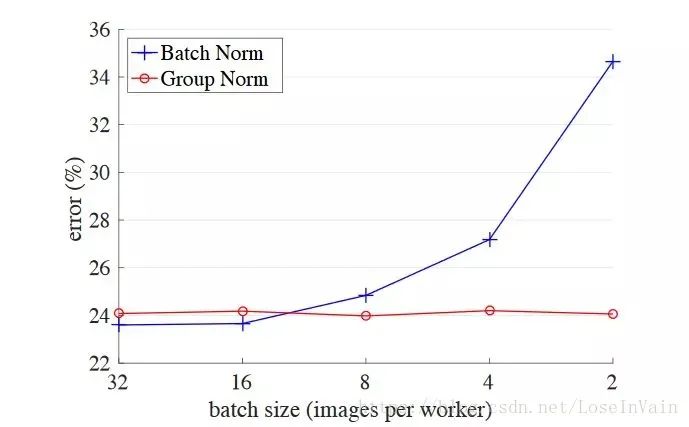
12、少在太小的批次中使用BatchNorm层
13、数值计算问题,出现Nan
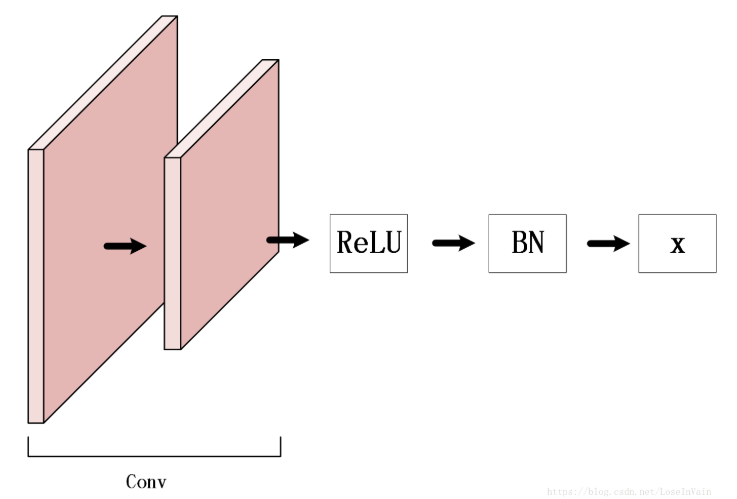
14、BN层放置的位置问题
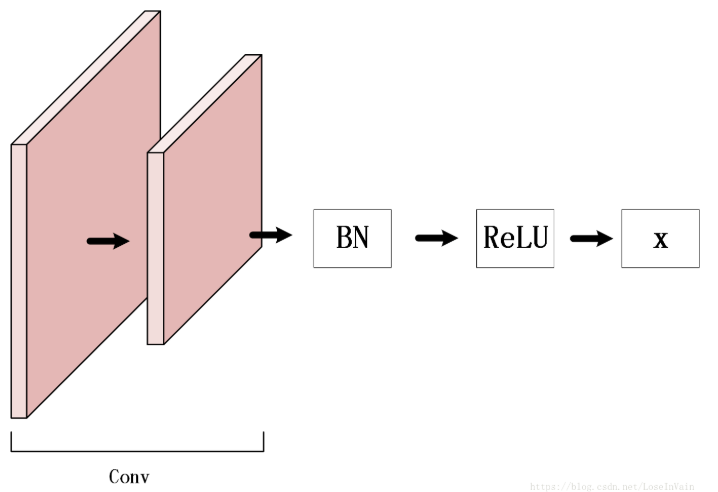
graph LRweights --> BatchNormBatchNorm --> ReLU
graph LRReLU --> BatchNorm+dropoutBatchNorm+dropout --> weights
15、dropout层应用在卷积层中可能导致更差的性能
16、较小的batch size可以提供较好的泛化
17、初始化权值不能初始化为全0
18、别忘了你的偏置
19、验证准确率远大于测试准确率
20、KL散度出现负数
softmax层的,才能保证概率和为1,不然可能会出现KL散度为负数的笑话。log_softmax而目标值需要是softmax值,也就说输入值需要进行对数操作后再转变为概率分布[27]。评论