
三星新型存算一体 HBM2 存储器 AI 性能达 1.2 TFLOPS
共 1943字,需浏览 4分钟
·
2021-02-18 18:37

作者 | 包永刚
雷锋网按,存算一体或者叫存内计算技术随着AI的火热再一次成为业内关注的焦点,存储和计算的融合有望解决AI芯片内存墙的限制,当然,实现的方法也各不相同。雷锋网此前介绍过知存科技基于NOR FLASH存内计算,还有清华大学钱鹤、吴华强教授团队基于忆阻器的存算一体单芯片算力可能高达1POPs。三星基于HMB的存内计算芯片又有何亮点?
三星最新发布的基于HBM2的新型内存具有集成的AI处理器,该处理器可以实现高达1.2 TFLOPS的计算能力,从而使内存芯片能够处理通常需要CPU、GPU、ASIC或FPGA的任务。
新型HBM-PIM(Processing-in-memory,存内计算)芯片将AI引擎引入每个存储库,从而将处理操作转移到HBM。新型的内存旨在减轻在内存和处理器之间搬运数据的负担,数据的搬运耗费的功耗远大于计算。

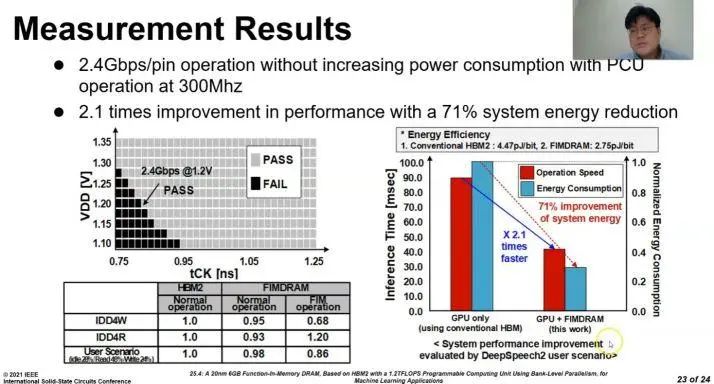
三星表示,将其应用于现有的HBM2 Aquabolt内存后,该技术可以提供2倍的系统性能,同时将能耗降低70%以上。该公司还声称,新存储器不需要对软件或硬件进行任何更改(包括对内存控制器),可以让早期采用者更快实现产品的上市。
三星表示,这种存储器已经在领先的AI解决方案提供商的AI加速器中进行了试验。三星预计所有验证工作都将在今年上半年完成,这标志着产品上市进入快车道。
三星在本周的国际固态电路会议(ISSCC)上展示了其新存储器架构的详细信息。

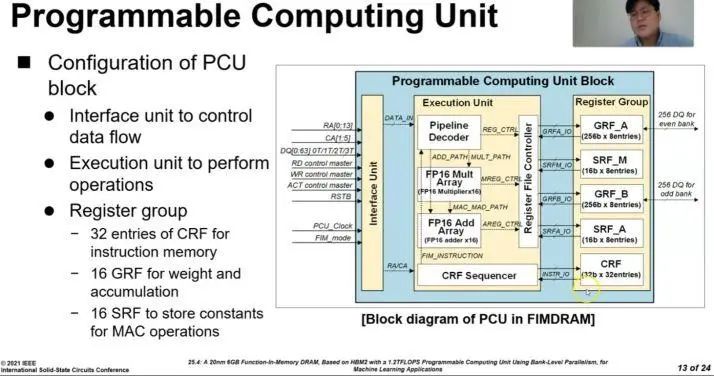
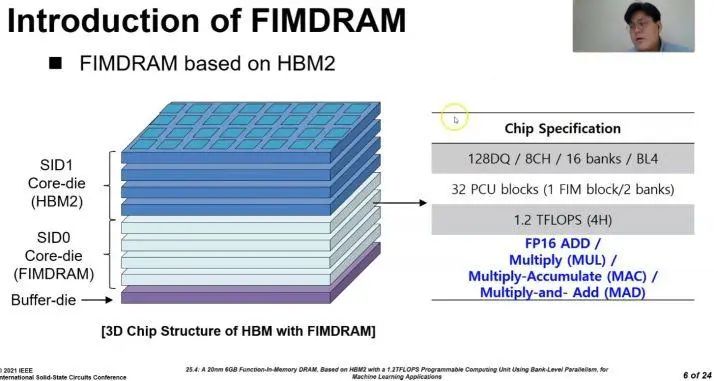
如您在上面的幻灯片中看到的,每个存储库都有一个嵌入式可编程计算单元(PCU),其运行频率为300 MHz,每个裸片上总共32个PCU。这些单元通过来自主机的常规存储命令进行控制,以启用DRAM中的处理功能,不同的是,它们可以执行FP16的计算。
该存储器还可以在标准模式下运行,这意味着新型的存储器既可以像普通HBM2一样运行,也可以在FIM模式下运行以进行存内数据处理。
自然地,在存储器中增加PCU单元会减少内存容量,每个配备PCU的内存芯片的容量(每个4Gb)是标准8Gb HBM2存储芯片容量的一半。为了解决该问题,三星将4个有PCU的4Gb裸片和4个没有PCU的8Gb裸片组合在一起,实现6GB堆栈(与之相比,普通HBM2有8GB堆栈)。
值得注意的是,上面的论文和幻灯片将这种技术称为功能内存DRAM(FIMDRAM,Function-In Memory DRAM),但这是该技术的内部代号,这个技术现在的名称是HBM-PIM。三星展示的是基于20nm原型芯片,该芯片在不增加功耗的情况下可实现每pin 2.4 Gbps的吞吐量。
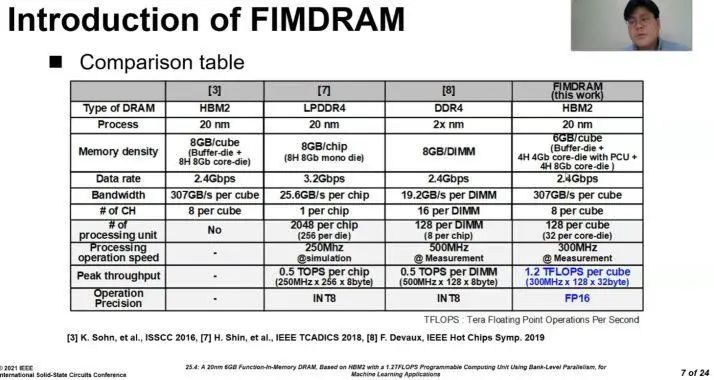
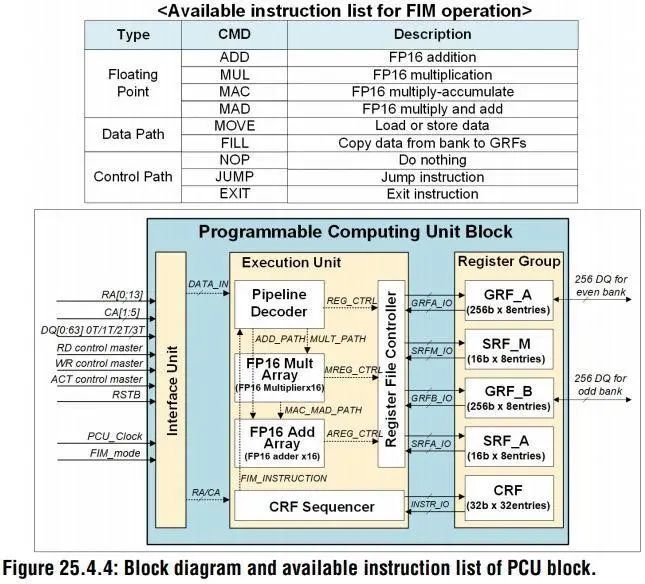
论文将基础技术描述为功能内存DRAM(FIMDRAM),该功能在存储库中集成了16宽单指令多数据引擎,并利用存储库级并行性提供了比片外存储高4倍的处理带宽。另外,可以看到的是这种芯片存储解决方案无需对常规存储器控制器及其命令协议进行任何修改,这使得FIMDRAM可以更快在实际应用中使用。
不幸的是,至少在目前看来,我们不会在最新的游戏GPU中看到这些功能。三星指出,这种新内存要满足数据中心、HPC系统和支持AI的移动应用程序中的大规模处理需求。
与大多数存内计算技术一样,希望这项技术能够突破存储芯片散热的限制,尤其是考虑到HBM芯片通常部署在堆栈中,而这些堆栈并不都有利于散热。三星的演讲者没有分享HBM-PIM如何应对这些挑战。
三星电子存储器产品计划高级副总裁Kwangil Park表示:“我们开创性的HBM-PIM是业内首个针对各种AI驱动的工作负载(如HPC,训练和推理)量身定制的可编程PIM解决方案。我们计划通过与AI解决方案提供商进一步合作以开发更高级的PIM驱动的应用。”

往期推荐