
HDFS 为何在大数据领域经久不衰?
1 概述
1.1 简介
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS 源自于Google的GFS论文,发表于2003年,HDFS是GFS的克隆版
1.2 设计目标
filel:node1 node2 node3file2: node2 node3 node4file3: node3 node4 node5file4: node5 node6 node7
不管文件多大,都存储在一个节点,在进行数据处理时,很难进行并行处理,节点可能就成为网络瓶颈,很难进行大数据的处理 存储负载很难均衡,每个节点的利用率很低
巨大的分布式文件系统 运行在普通廉价的硬件 易扩展、为用户提供性能不错的文件存储服务
2 如何设计一个分布式文件系统
NameNode用于管理文件系统的命名空间以及调节客户访问文件 还有多个DataNode(简称DN),数据节点,作为从节点(slave server)存在 通常每个集群中的DataNode,都会被NameNode所管理,DataNode用于存储数据
NameNode,而其他集群中的机器各自运行一个DataNode实例。虽然一台机器上也可以运行多个节点,但不推荐。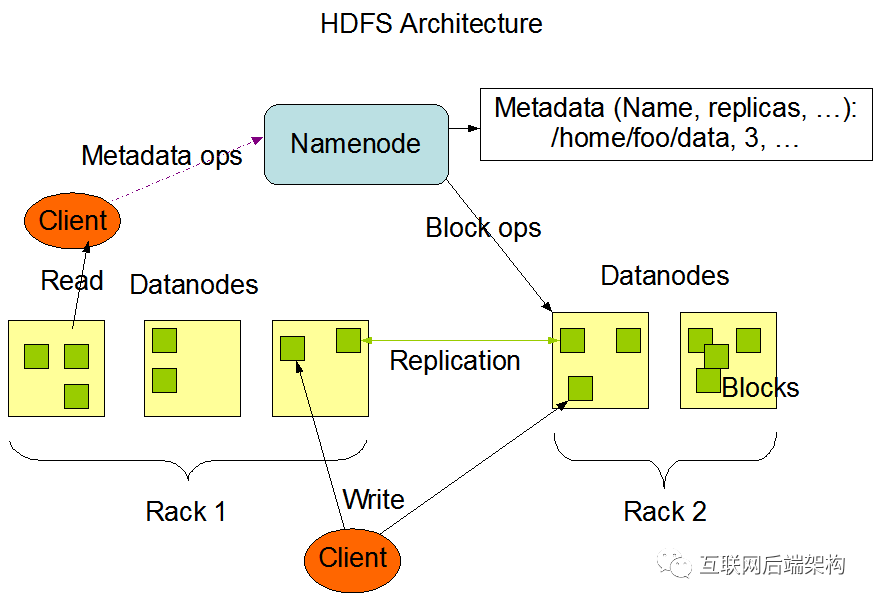
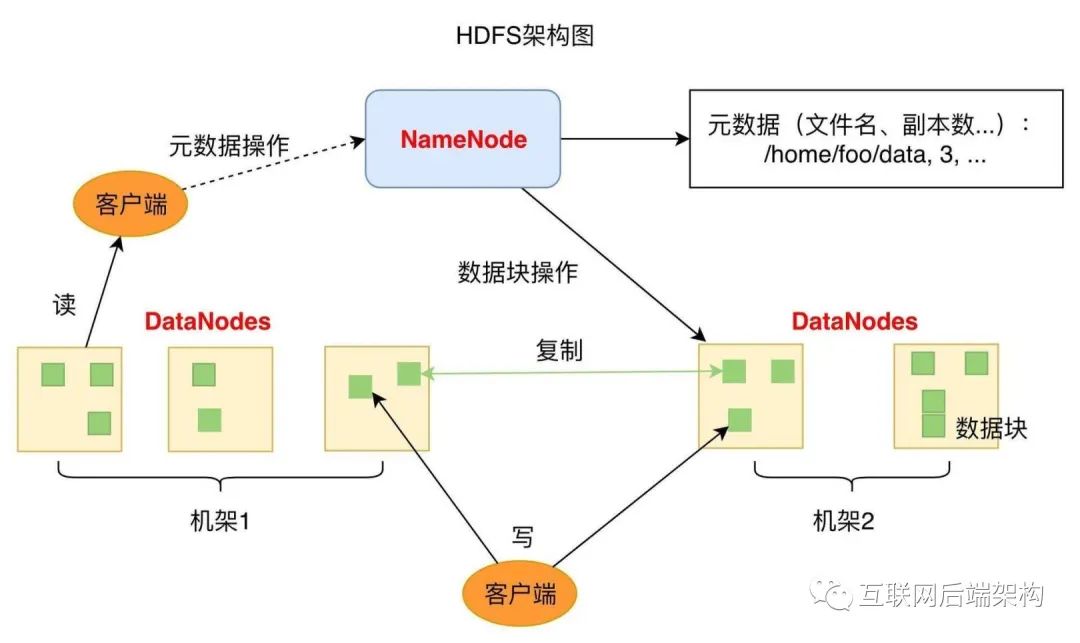
DataNode
存储用户的文件对应的数据块(Block) 会定期向NN发送心跳信息,汇报本身及其所有的block信息和健康状况
NameNode
负责客户端请求的响应 负责元数据(文件的名称、副本系数、Block存放的DN)的管理
3 S副本机制
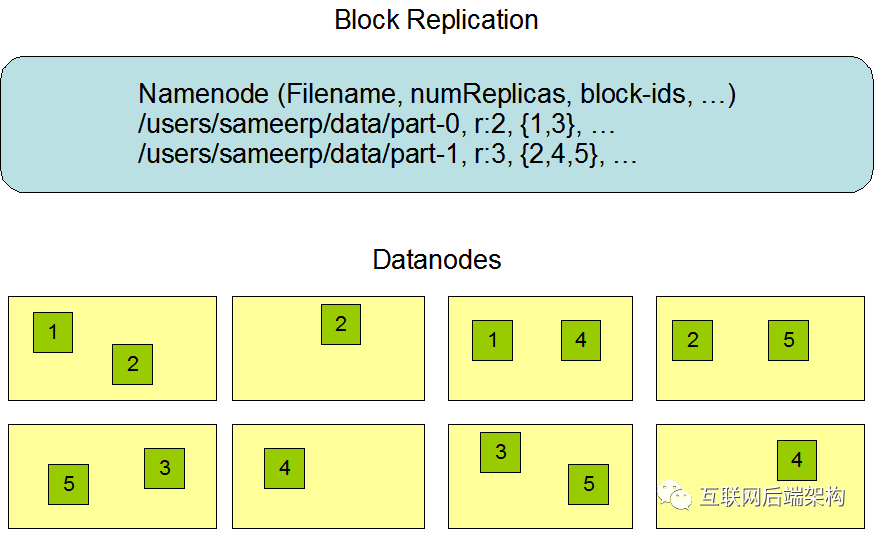
Block多份复制存储的示意图
Block1的两个备份存储在DataNode0和DataNode2两个服务器上 Block3的两个备份存储DataNode4和DataNode6两个服务器上
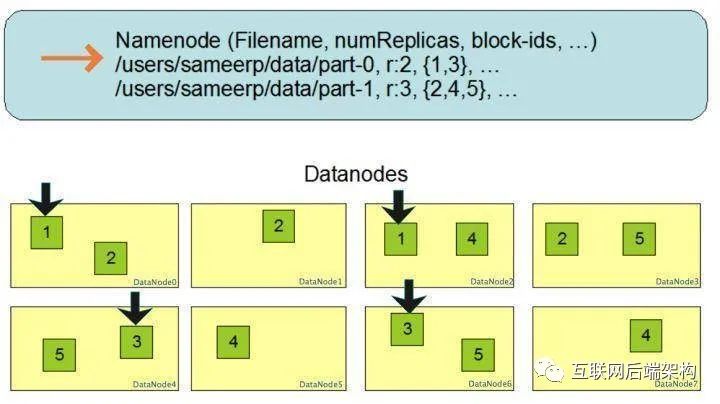
副本存放策略
第一个副本会随机选择,但是不会选择存储过满的节点 第二个副本放在和第一个副本不同且随机选择的机架 第三个和第二个放在同一机架上的不同节点 剩余副本完全随机节点
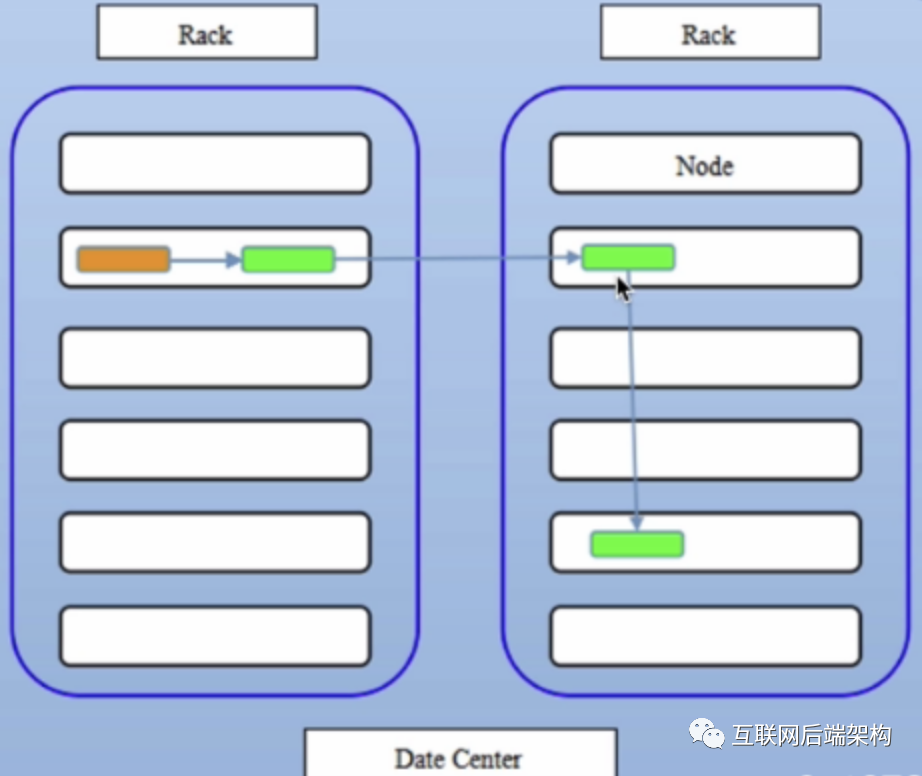
合理性分析
可靠性:block存储在两个机架 写带宽:写操作仅穿过一个网络交换机 读操作:选择其中一个机架去读 block分布在整个集群
5 HDFS的高可用设计
5.1 数据存储故障容错
5.2 磁盘故障容错
5.3 DataNode故障容错
5.4 NameNode故障容错
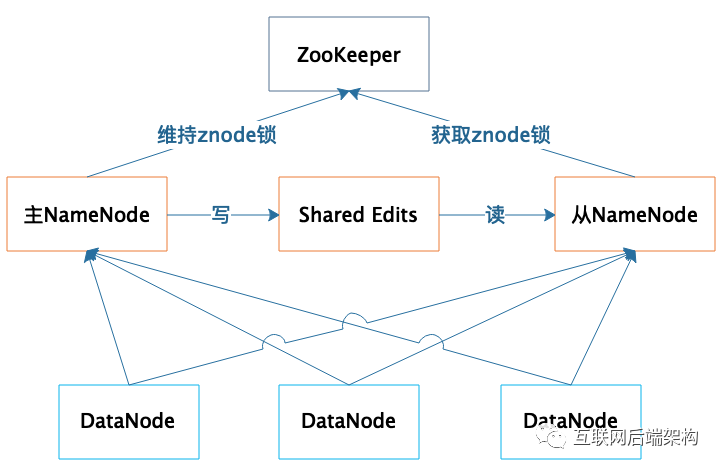
一台作为主服务器提供服务 一台作为从服务器进行热备
6 保证系统可用性的策略
冗余备份
失效转移
降级
总结
评论