
26张图,带你全面盘点2021微博热搜!
2021是最好的一年,也是很差的一年,时光如白驹过隙,匆匆溜走,还有多少热点,在你的记忆里!
这里整理了2021年全年的微博热搜数据,你想要的全在这里了!文末有全年热点排行视频,不要错过哦!

数据处理
最近在网上爬取了2021年全年的微博热搜数据,每天都是一个文件
数据比较分散,我们先整理一下
合并数据
把当前目录下的 csv 文件数据合并成同一个文件
import pandas as pd
import os
df_list = []
for i in os.listdir():
if "csv" in i:
day = i.split('.')[0].split('_')[-1]
df = pd.read_csv(i)
df['day'] = day
df_list.append(df)
df = pd.concat(df_list, axis=0)
df.to_csv("total.txt", index=0)
由于 df 数据还是不便于后面的分析使用,接下来我们对 df 进行更进一步的处理操作
数据预处理
因为抓取数据的时候,会有一些重复的数据,需要去除;同时对于热搜字段和日期也需要进行一定的处理
df_new = df.copy(deep=True) # 复制一个新的df
df_new.drop_duplicates(inplace=True) # 删除重复行
def deal_day(s):
d = s.split('-')[:2]
return '-'.join(d)
def deal_hot(s):
if '万' in s:
d = s.split('万')[0]
return int(float(d)*10000)
else:
if " " in s:
d = s.split(" ")[1]
return int(d)
else:
return int(s)
df_new['day_new'] = df_new['day'].apply(deal_day)
df_new['热度'] = df_new['热度'].apply(deal_hot)
处理之后的数据如下

总共有11万的热搜数据!
我们拿到这些数据,其实可以做很多有趣的分析,下面萝卜哥就抛砖引玉,先做一些简单的可视化分析
整体热搜分析
可视化部分使用 Pyecharts 进行
# 数据可视化
import pyecharts.options as opts
from pyecharts.charts import Line, Bar, Pie, Calendar
from pyecharts.charts import WordCloud as wc
from pyecharts.commons.utils import JsCode
from pyecharts.globals import SymbolType
import datetime
import random
热搜日历
先来看看微博热点日历,这一年,微博运维小哥哥,哪一天最忙呢
searchcount_value = df_new.groupby('day')['热度'].sum().values.tolist()
searchcount_index = df_new.groupby('day')['热度'].sum().index.tolist()
search_data = list(zip(searchcount_index, searchcount_value))
def calendar_base(data) -> Calendar:
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
c = (
Calendar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add("", data, calendar_opts=opts.CalendarOpts(range_="2021", pos_right="5%", pos_left="8%"))
.set_global_opts(
title_opts=opts.TitleOpts(title="微博热搜日历"),
visualmap_opts=opts.VisualMapOpts(
max_=400000000,
min_=0,
orient="horizontal",
is_piecewise=True,
pos_top="230px",
pos_left="100px",
),
)
)
return c
calendar_base(search_data).render_notebook()
Output:
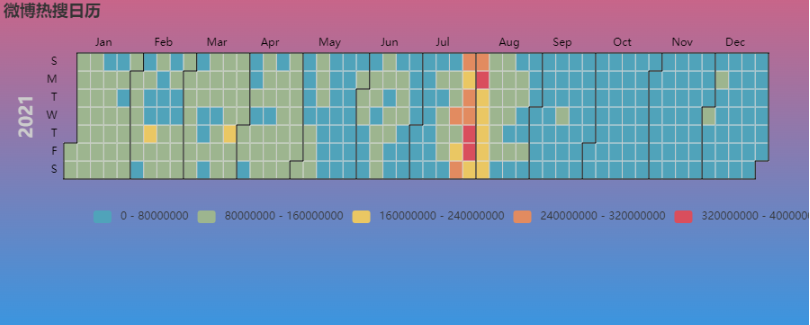
可以看到,7月末,8月初是热搜最为密集的时期,毕竟是奥运会期间嘛。然后总体来看,上半年要比下半年热搜更多,看来开年是各种热门事件的集中爆发时间啊
而热搜最高的就是2021-07-29这一天,我们来单独看看这一天的情况
热搜总量最高
df_07_29 = df_new[df_new['day'] == '2021-07-29']
df_07_29 = df_07_29.sort_values(by='热度', ascending=False)
def bar_chart(x, y) -> Bar:
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
c = (
Bar(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
#Bar()
.add_xaxis(x)
# .add_xaxis(searchcount.index.tolist()[:10])
.reversal_axis()
.add_yaxis("", y,
label_opts=opts.LabelOpts(position='inside', formatter="{b} {c}"),
color='plum',
)
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30,),
axisline_opts=opts.AxisLineOpts(is_show=False),),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(is_show=False,),
axisline_opts=opts.AxisLineOpts(is_show=False),
axistick_opts=opts.AxisTickOpts(
is_show=False,
length=25,
linestyle_opts=opts.LineStyleOpts(color="#ffffff1f"),
),)
)
.set_series_opts(
itemstyle_opts={
"normal": {
"color": JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0,
color: 'rgba(255,100,97,.5)'
}, {
offset: 1,
color: 'rgba(221,160,221)'
}], false)"""),
"barBorderRadius": [30, 30, 30, 30],
"shadowColor": 'rgb(0, 160, 221)',
}}
)
)
return c
bar_chart(df_07_29['标题'].values.tolist()[:10], df_07_29['热度'].values.tolist()[:10]).render_notebook()
Output:

这一天的高量热搜基本被奥运会相关的话题占据了,而乒乓球又是热搜中的热搜
我们再通过一个词云图来看看这一天出现的词汇情况
import jieba
from wordcloud import WordCloud
from PIL import Image
import numpy as np
weibo_title = df_new['标题'].values.tolist()
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"被", "@", "我", "她", "你", "他", "了", "的", "吧", "吗", "在", "啊", "不", "也", "还", "是",
"说", "都", "就", "没", "做", "人", "被", "不是", "现在", "什么", "这", "呢", "知道", "邓", "我们", "他们", "和", "有", "", "",
"要", "就是", "但是", "而", "为", "自己", "中", "问题", "一个", "没有", "到", "这个", "并", "对"}
# STOPWORDS = {}
def wordcloud(data, name, pic=None):
comment = jieba.cut(str(data), cut_all=False)
words = ' '.join(comment)
img = Image.open(pic)
img_array = np.array(img)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file(name + '.png')
wordcloud(weibo_title, '0729', "1.PNG")
Output:

全年热点排行
我们再来看看2021全年热搜的排行榜
Top10
bar_chart(df_new_sort['标题'].values.tolist()[:10], df_new_sort['热度'].values.tolist()[:10]).render_notebook()
Output:

可以看到,赵英俊的意外离世还是引起了很大的波动,而赵丽颖冯绍峰的离婚也是赚足了吃瓜群众的眼球
Top20
我们把榜单延长至 top20,来看看还有哪些热点被广大网友关注呢
bar_chart(df_new_sort['标题'].values.tolist()[11:20], df_new_sort['热度'].values.tolist()[11:20]).render_notebook()
Output:

每月最高热搜
我们还是通过时间线图的方式来展示每个月最高热搜情况
month = ['2021-01', '2021-02', '2021-03', '2021-04', '2021-05', '2021-06',
'2021-07', '2021-08', '2021-09', '2021-10', '2021-11', '2021-12']
result_dict = {}
for i in month:
dd = df_new[df_new['day_new'] == i]
dd = dd.sort_values(by='热度', ascending=False)
dd_list = dd.iloc[0].values.tolist()
result_dict[dd_list[-1]] = dd_list[0] + ',' + str(dd_list[1])
df_2021 = pd.DataFrame.from_dict(result_dict, orient='index',columns=['标题'])
df_2021 = df_2021.reset_index().rename(columns = {'index':'day_new'})
y = gen_y(df_2021)
myLine(y).render_notebook()
Output:
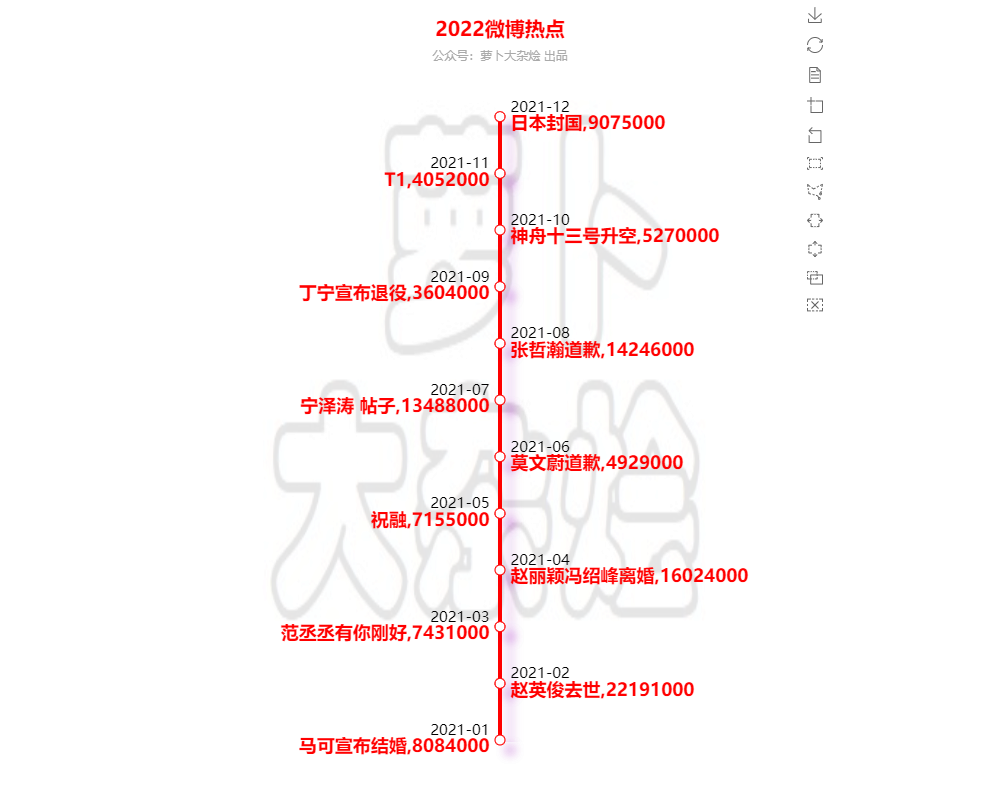
可以看出,微博的吃瓜群众们,关心的事情还真的是多姿多彩,既有家国大事,也有娱乐八卦;既有游戏体育,也有生活民生。可谓一个全方位吃瓜~
全年热搜之王
下面我们把热搜标题进行细分,从不同的词汇上来探索下这一年的热搜情况
首先进行 jieba 分词处理,并提取出人名、名词和动词三类
import jieba.posseg as psg
name_list = []
noun_list = []
verb_list = []
for i in weibo_title:
result = psg.cut(i)
for x in result:
if x.flag == 'nr':
name_list.append(x.word)
elif x.flag == 'n':
noun_list.append(x.word)
elif x.flag == 'v':
verb_list.append(x.word)
热搜之王-人物
我们先来统计人物的热搜情况
# 热搜之王-人物
name_counts = {}
stopword = ['陈', '李', '杨', '王', '郭', '吴', '周', '明星', '辟谣', '石家庄', '阿富汗', '晋级', '官宣']
for w in name_list:
if w not in stopword:
name_counts[w] = name_counts.get(w, 0) + 1
sort_counts = sorted(name_counts.items(), key=lambda item: item[1], reverse=True)
bar_total([x[0] for x in sort_counts[:20]], [x[1] for x in sort_counts[:20]], "热点人物").render_notebook()
Output:
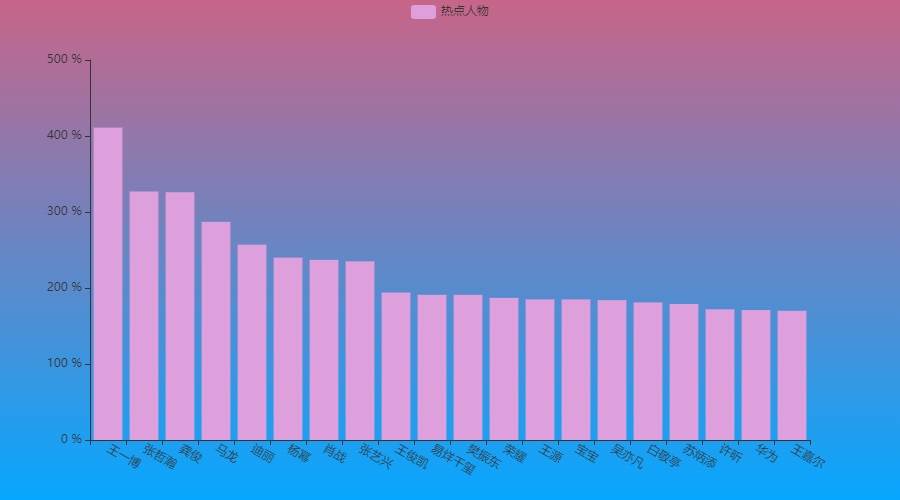
可以看到王一博成为了全年上热搜最多的那个人,强!而那个以一己之力重新定义牙签的男人也在热搜榜单
下面我们就来分别看下他们的热搜具体情况
热搜-王一博
wangyibo = df_new[df_new['标题'].str.contains('王一博')].sort_values(by='热度', ascending=False)
bar_chart(wangyibo['标题'].values.tolist()[:10], wangyibo['热度'].values.tolist()[:10]).render_notebook()
Output:

嗯,不做评论了,毕竟不是很熟悉~
热搜-吴签
wuyifan = df_new[df_new['标题'].str.contains('吴亦凡')].sort_values(by='热度', ascending=False)
bar_chart(wuyifan['标题'].values.tolist()[:10], wuyifan['热度'].values.tolist()[:10]).render_notebook()
Output:

哈哈哈,这对于签哥来说应该是冰火两重天的一年,前面好好的上热搜,走流量,后面突然就凉了,也不知道现在是啥情况了~
人物-词云
再通过词云的方式来整体看下全年的热搜名人榜
# 热点之王词云
def wordcloud_base(words) -> wc:
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
c = (
wc(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add("", words, word_size_range=[20, 100], shape="star")
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
return c
wordcloud_base(zip([x[0] for x in sort_counts[:100]], [x[1] for x in sort_counts[:100]])).render_notebook()
Output:

热搜之王-名词
bar_total([x[0] for x in sort_noun[:20]], [x[1] for x in sort_noun[:20]], "热门名词").render_notebook()
Output:
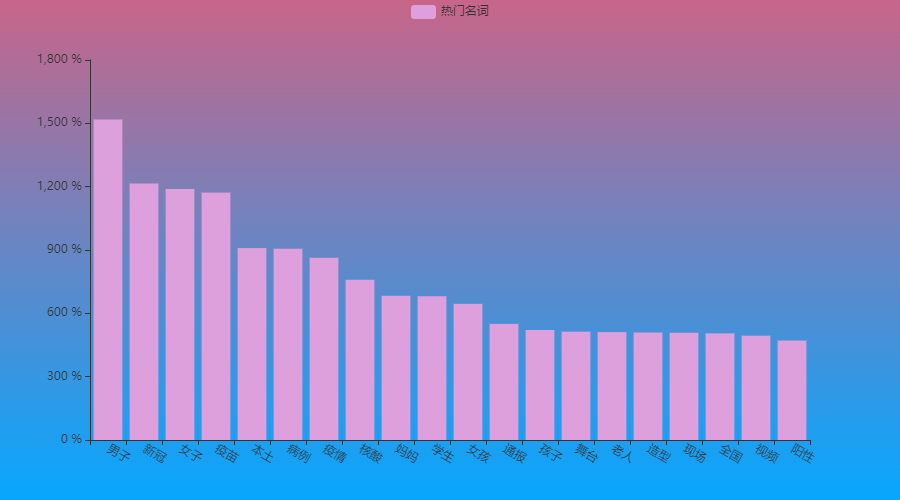
出乎意料,2021年热搜名词最高的竟然是“男子”这个词汇,要知道,我以前也分析过2019年的热搜,当时的最高词汇可是“女生”
玫瑰饼图
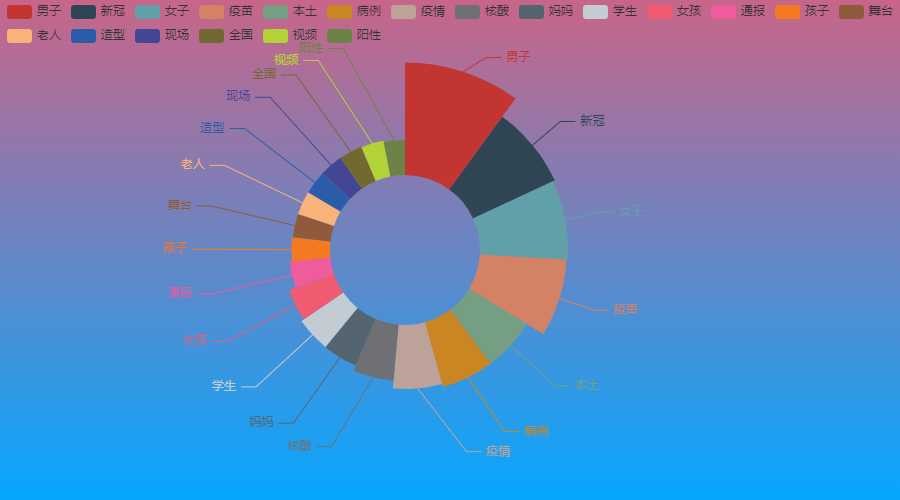
下面我们就来探究下,到底“男子”这个词汇为什么出现频率这么高
男子与女子
# 男子和女子
nanzi = df_new[df_new['标题'].str.contains('男子')].sort_values(by='热度', ascending=False)
nvzi = df_new[df_new['标题'].str.contains('女子')].sort_values(by='热度', ascending=False)
bar_chart(nanzi['标题'].values.tolist()[:20], nanzi['热度'].values.tolist()[:20]).render_notebook()
bar_chart(nvzi['标题'].values.tolist()[:20], nvzi['热度'].values.tolist()[:20]).render_notebook()
Output:
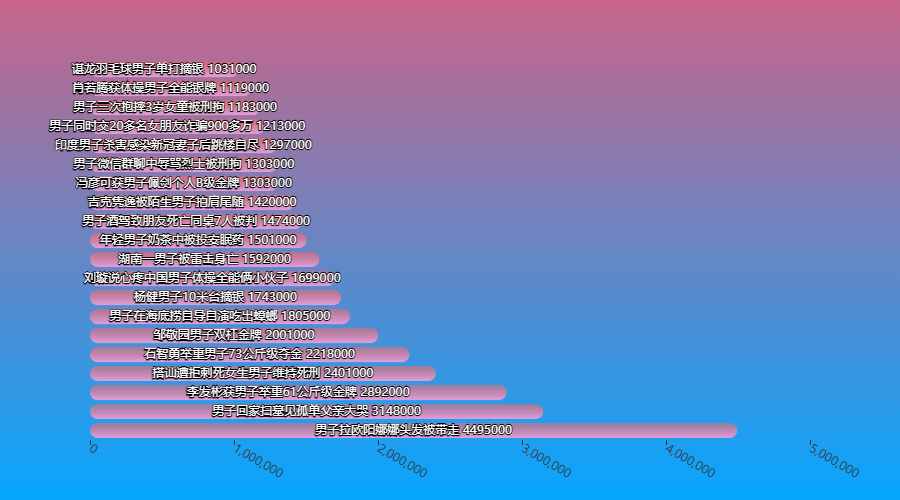
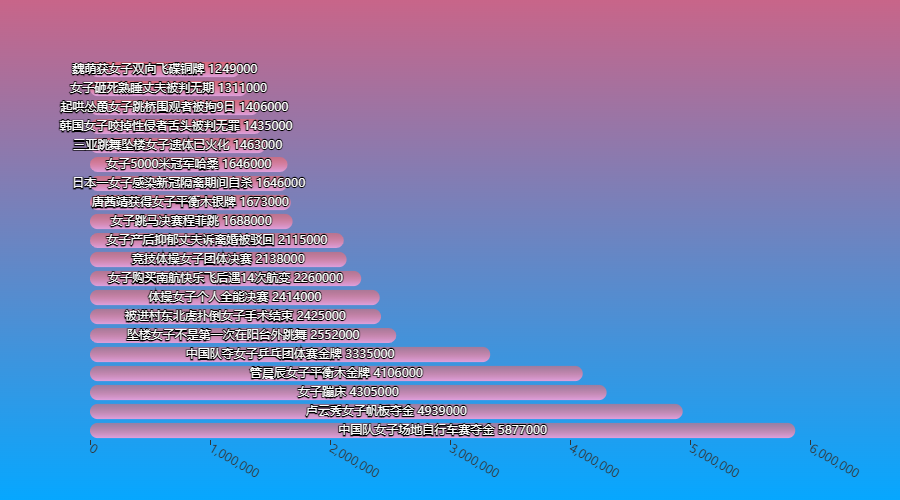
原来2021年是奥运年,各种男女子项目都纷纷进入热搜了~
名词-词云
wordcloud_base(zip([x[0] for x in sort_noun[:100]], [x[1] for x in sort_noun[:100]])).render_notebook()
Output:

可以看到,新冠,疫苗,病例,本土等和疫情相关的词汇依然是2021年的热点词汇,只能说疫情还未结束,我们仍需努力!
热搜之王-动词
最后来看下热门的动词情况
# 热门动词
bar_total([x[0] for x in sort_verb[:20]], [x[1] for x in sort_verb[:20]], "热门动词").render_notebook()
Output:
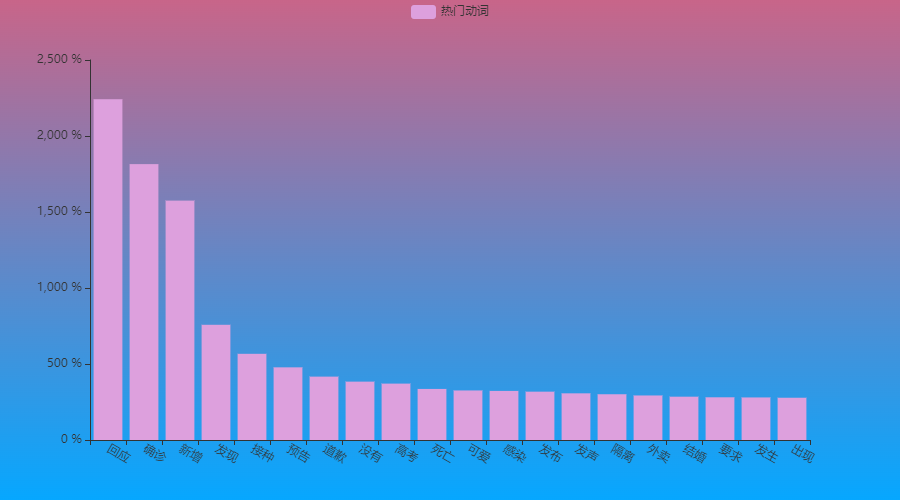
不出意外,“回应”仍然是微博的最热动词,这很“微博”
回应啥
我们来看看热度最高的几个回应都是啥
huiying = df_new[df_new['标题'].str.contains('回应')].sort_values(by='热度', ascending=False)
bar_chart(huiying['标题'].values.tolist()[:20], huiying['热度'].values.tolist()[:20]).render_notebook()
Output:
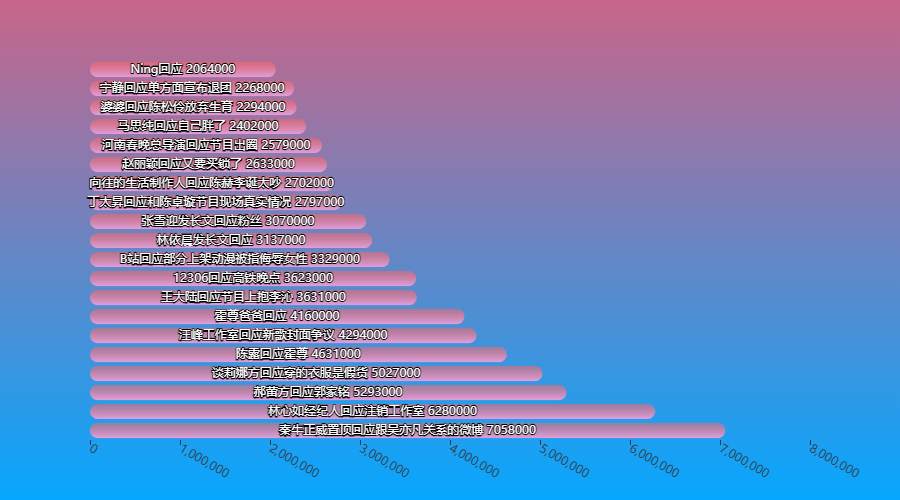
基本都是娱乐圈的那些事,回应有时候代表一种态度,可能是直面责难,勇于承担;也可能是据理力争,不惧舆论
其他热门动词
否认
否认就是正面硬刚了,我没有,我不是,我不知道,否认三连搞起来
fouren = df_new[df_new['标题'].str.contains('否认')].sort_values(by='热度', ascending=False)
bar_chart(fouren['标题'].values.tolist()[:20], fouren['热度'].values.tolist()[:20]).render_notebook()
Output:
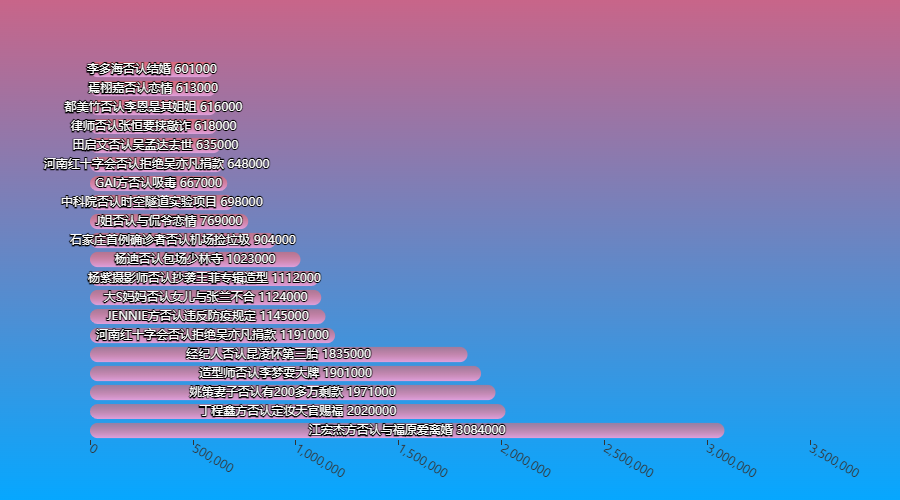
道歉
当然还有心真道歉的,痛彻心扉的文字,声泪俱下的表述,让你没办法硬起心肠,没办法不选择原谅
daoqian = df_new[df_new['标题'].str.contains('道歉')].sort_values(by='热度', ascending=False)
bar_chart(daoqian['标题'].values.tolist()[:20], daoqian['热度'].values.tolist()[:20]).render_notebook()
Output:
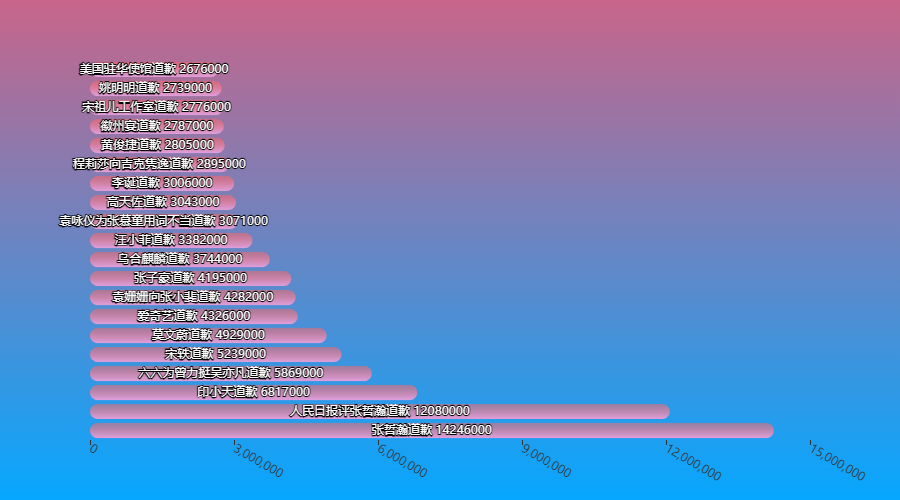
离婚&分手
fenli = df_new[df_new['标题'].str.contains('离婚|分手')].sort_values(by='热度', ascending=False)
bar_chart(fenli['标题'].values.tolist()[:20], fenli['热度'].values.tolist()[:20]).render_notebook()
Output:
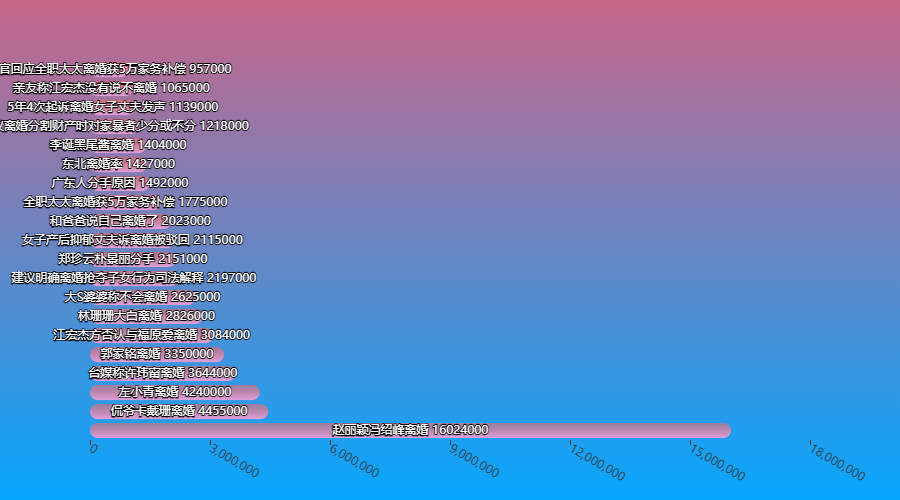
赵丽颖和冯绍峰的离婚绝对属于年度大瓜了~
动词-词云
wordcloud_base(zip([x[0] for x in sort_verb[:100]], [x[1] for x in sort_verb[:100]])).render_notebook()
Output:

全年热搜视频
熟悉我的小伙伴应该知道,写这类文章,最后我一般都会制作一个动态条形视频,这次也不例外,2021全年,每个热点事件动态展示视频
好了,以上就是今天分享的所有内容,如果对你有帮助,帮忙点赞和在看支持哦~
完整的微博热搜数据获取代码,公众号:jackcui-ai,后台回复「微博」,即可获取!
