
认真的聊一聊决策树和随机森林
共 2661字,需浏览 6分钟
·
2021-02-01 22:10
随机森林是一种简单又实用的机器学习集成算法。
“随机“表示2种随机性,即每棵树的训练样本、训练特征随机选取。
多棵决策树组成了一片“森林”,计算时由每棵树投票或取均值的方式来决定最终结果,体现了三个臭皮匠顶个诸葛亮的中国传统民间智慧。
那我们该如何理解决策树和这种集成思想呢?
01 决策树
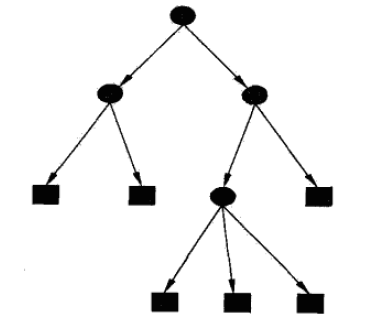
以分类任务为代表的决策树模型,是一种对样本特征构建不同分支的树形结构。
决策树由节点和有向边组成,其中节点包括内部节点(圆)和叶节点(方框)。内部节点表示一个特征或属性,叶节点表示一个具体类别。
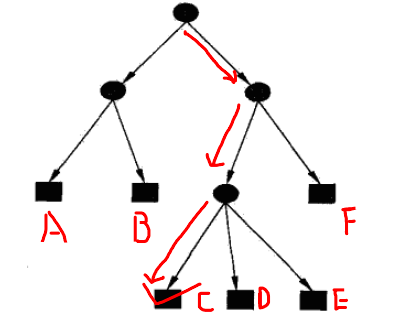
预测时,从最顶端的根节点开始向下搜索,直到某一个叶子节点结束。下图的红线代表了一条搜索路线,决策树最终输出类别C。
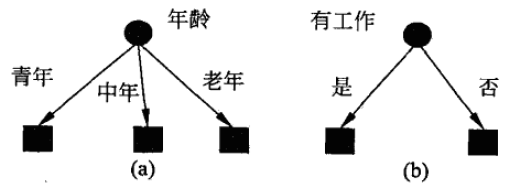
决策树的特征选择
假如有为青年张三想创业,但是摸摸口袋空空如也,只好去银行贷款。
银行会综合考量多个因素来决定张三是不是一个骗子,是否给他放贷。例如,可以考虑的因素有性别、年龄、工作、是否有房、信用情况、婚姻状况等等。
这么多因素,哪些是重要的呢?
这就是特征选择的工作。特征选择可以判别出哪些特征最具有区分力度(例如“信用情况”),哪些特征可以忽略(例如“性别”)。特征选择是构造决策树的理论依据。
不同的特征选择,生成了不同的决策树。
决策树的特征选择一般有3种量化方法:信息增益、信息增益率、基尼指数。
信息增益
在信息论中,熵表示随机变量不确定性的度量。假设随机变量X有有限个取值,取值
如果某件事一定发生(太阳东升西落)或一定不发生(钓鱼岛是日本的),则概率为1或0,对应的熵均为0。
如果某件事可能发生可能不发生(天要下雨,娘要嫁人),概率介于0到1之间,熵大于0。
由此可见,熵越大,随机性越大,结果越不确定。
我们再来看一看条件熵
明确了这两个概念,理解信息增益就比较方便了。现在我们有一份数据集D(例如贷款信息登记表)和特征A(例如年龄),则A的信息增益就是D本身的熵与特征A给定条件下D的条件熵之差,即:
数据集D的熵是一个常量。信息增益越大,表示条件熵
所以要优先选择信息增益大的特征,它们具有更强的分类能力。由此生成决策树,称为ID3算法。
信息增益率
当某个特征具有多种候选值时,信息增益容易偏大,造成误差。引入信息增益率可以校正这一问题。
信息增益率
同样,我们优先选择信息增益率最大的特征,由此生成决策树,称为C4.5算法。
基尼指数
基尼指数是另一种衡量不确定性的指标。
假设数据集D有K个类,样本属于第K类的概率为
其中
如果数据集D根据特征A是否取某一可能值a被分割成
容易证明基尼指数越大,样本的不确定性也越大,特征A的区分度越差。
我们优先选择基尼指数最小的特征,由此生成决策树,称为CART算法。
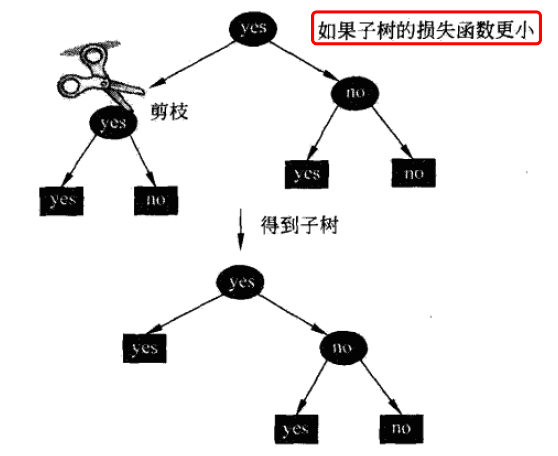
决策树剪枝
决策树生成算法递归产生一棵决策树,直到结束划分。什么时候结束呢?
样本属于同一种类型 没有特征可以分割
这样得到的决策树往往对训练数据分类非常精准,但是对于未知数据表现比较差。
原因在于基于训练集构造的决策树过于复杂,产生过拟合。所以需要对决策树简化,砍掉多余的分支,提高泛化能力。
决策树剪枝一般有两种方法:
预剪枝:在树的生成过程中剪枝。基于贪心策略,可能造成局部最优 后剪枝:等树全部生成后剪枝。运算量较大,但是比较精准
决策树剪枝往往通过极小化决策树整体的损失函数实现。
假设树T有|T|个叶子节点,某一个叶子节点t上有
其中熵为:
损失函数第一项为训练误差,第二项为模型复杂度,用参数
CART算法
CART表示分类回归决策树,同样由特征选择、树的生成及剪枝组成,可以处理分类和回归任务。
相比之下,ID3和C4.5算法只能处理分类任务。
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,依次递归地二分每个特征。
CART 对回归树采用平方误差最小化准则,对分类树用基尼指数最小化准则。
02 bagging集成
机器学习算法中有两类典型的集成思想:bagging和bossting。
bagging是一种在原始数据集上,通过有放回抽样分别选出k个新数据集,来训练分类器的集成算法。分类器之间没有依赖关系。
随机森林属于bagging算法。通过组合多个弱分类器,集思广益,使得整体模型具有较高的精确度和泛化性能。
03 随机森林
我们将使用CART决策树作为弱学习器的bagging方法称为随机森林。
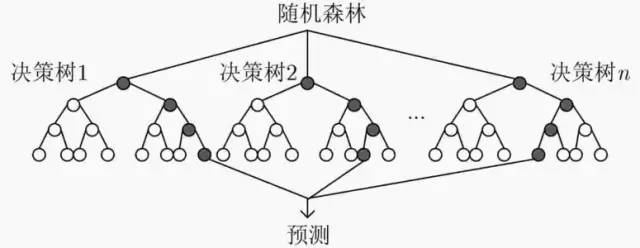
由于随机性,随机森林对于降低模型方差效果显著。故随机森林一般不需要额外剪枝,就能取得较好的泛化性能。
相对而言,模型对于训练集的拟合程度就会差一些,相比于基于boosting的GBDT模型,偏差会大一些。
另外,随机森林中的树一般会比较深,以尽可能地降低偏差;而GBDT树的深度会比较浅,通过减少模型复杂度来降低方差。(面试考点)
最后,我们总结一下随机森林都有哪些优点:
采用了集成算法,精度优于大多数单模型算法 在测试集上表现良好,两个随机性的引入降低了过拟合风险 树的组合可以让随机森林处理非线性数据 训练过程中能检测特征重要性,是常见的特征筛选方法 每棵树可以同时生成,并行效率高,训练速度快 可以自动处理缺省值
推 荐 阅 读
2021-01-18

2021-01-19

2021-01-26


参考资料
https://www.jianshu.com/p/a779f0686acc
原创不易,有收获的话请帮忙点击分享、点赞、在看吧🙏