
语雀 P0 事故复盘,这 9 个字亮了!
大家好,我是鱼皮。
最近语雀不是出了个号称 “载入史册” 的 P0 级事故嘛 —— 连续宕机 7 个多小时无法使用,作为一个大厂知名产品,这个修复速度属实让人无法理解。要命的是我们公司的知识库也是放在语雀上的,导致那天下午大家摸鱼很愉快。
很快,官方就发布了《故障公告》。有一说一,这个公告写得还是挺不错的,时间线梳理的很清楚。而且起码没有把责任归咎于 “网络原因”,还以为又是某个地区的网线被挖断了呢。
故障公告原文:https://mp.weixin.qq.com/s/WFLLU8R4bmiqv6OGa-QMcw
也有同学看了的语雀故障公告文章,发现改进措施这一段中提到了 “可监控,可灰度,可回滚” 这 9 个字,我觉得这确实是全文的核心亮点了,把事故复盘总结地很精辟。
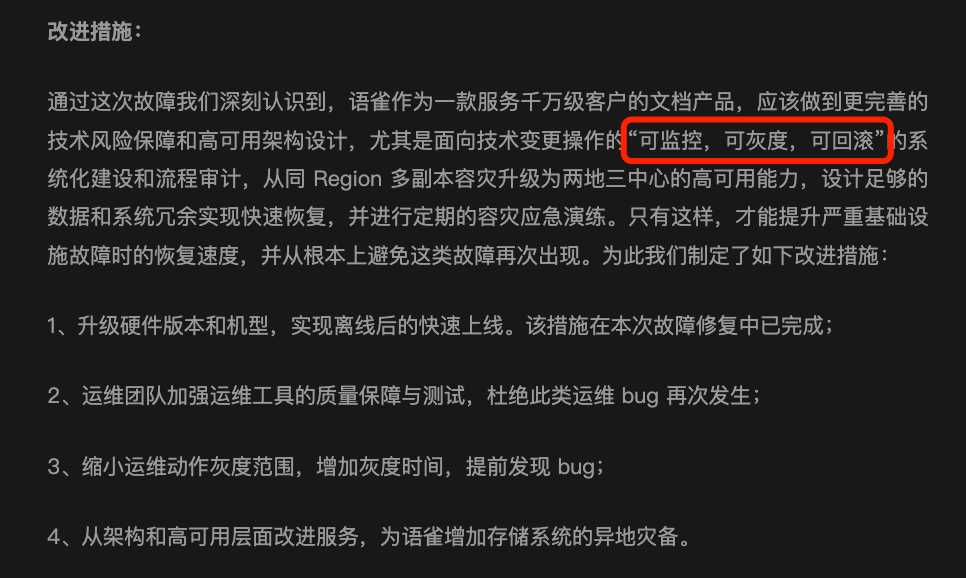
但是这 9 个字到底是什么意思呢?鱼皮给大家解读一下。
如何保证系统发布的稳定性?
首先,这几点都是企业正式线上项目需要重点关注的能力,所以大家在校自学时一般是很少能接触到的。
但如果你知道并实践过这些,前途不可限量啊!
可监控
可监控是指能够实时地收集和展示系统运行时的数据和指标,以便开发和运维同学可以及时发现系统问题、更快进行故障排查和性能调优。需要监控的信息可以包括系统性能指标(内存、CPU、带宽等)、业务日志、错误信息等。
还有一个与之相关的术语 “可观测性”,就是指一个系统状态对开发维护者的透明程度。举个例子,我不需要每次打开服务器看日志或者用什么 jmap 命令分析 gc,而是直接通过一个面板整体查看系统的状态,甚至是自动提示问题和解决方案。
AIOps 智能运维也是现在很流行的一种技术,用 AI 帮忙运维诊断系统,大大提高开发运维效率。
可灰度
指灰度发布能力(又叫金丝雀发布)。将系统的新版本全量部署给所有用户之前,先仅对一小部分用户进行试用。这样可以通过收集这部分用户的反馈和监控数据就能评估新版本的稳定性,并及时进行调整和修复,从而减少对全体用户的潜在风险。
灰度发布又有很多策略。比如经典的按流量阶段性发布,先随机给 5% 的用户使用新版本,验证没问题后,再给 20%、50%、75% 的用户使用新版本逐渐放量,直到覆盖 100% 的用户。
还有很多策略,列举几个常见的:
1)按照用户的业务属性灰度,比如 VIP 用户先用、老用户先用。
2)按人群灰度,比如特定地域、特定年龄、特定偏好、特定客户端的用户。
3)按渠道灰度,比如通过某平台注册的用户先体验等等。
灰度做的好,可以避免很多线上问题,及时控制影响。因此很多知名产品发布时都会采用灰度或者内测的策略,这也就是为什么有些同学能第一时间体验到微信新功能,有些同学却没有。
可回滚
就像 Git 版本控制系统回滚写错的代码一样,系统的版本也是可以回滚的。
线上系统出现问题时,可以将已经部署的新版本回退到之前的稳定版本。这样做可以快速恢复系统,减少对用户的影响,并给开发同学足够的时间来排查和修复问题。而不是线上一直故障,每分钟都是损失。
最后
咱也不是阿里内部的同学,说实话我不相信阿里内部没有统一的监控平台、灰度发布和部署管理平台。估计是部门自治或者人员不规范的操作导致的吧。(毕竟一个实习生说不定就能干崩一家公司)
总之,上面讲的这些特性都是为了在软件开发和发布过程中提高系统的稳定性、可靠性和可维护性。
想要实践上面这几点其实也很简单,直接用微信云托管平台就好了。我之前直播时录制过一套微信云托管的实践教程,大家如果需要的话,可以评论 “需要教程” 让我看看大家对这方面的需求,有必要的话回头给大家发出来
👇🏻 点击下方阅读原文,获取鱼皮往期编程干货
往期推荐