
【论文解读】基于关系感知的全局注意力
标题:《Relation-Aware Global Attention for Person Re-identification》
作者:Zhizheng Zhang et al.(中科大&微软亚洲研究院)
文章:openaccess.thecvf.com/c
源码:github.com/microsoft/Re
文章收录于CVPR 2020,bib引用如下:
@article{zhang2020relation,
title={Relation-Aware Global Attention for Person Re-identification},
author={Zhang, Zhizheng and Lan, Cuiling and Zeng, Wenjun and Jin, Xin and Chen, Zhibo},
journal={CVPR},
year={2020}
}
二、论文解读
这是一篇将注意力机制应用于行人重识别(person re-identification)任务上的文章。自从注意力机制在NLP领域过渡到CV领域以来,不少文章已经提出了很多基于注意力的改进,如Non-Local[1],SE[2],cSE[3],sSE[3],CBAM[4],Dual attention[5],Criss-Cross Attention[6],Fast Attention[7]等等,笔者认为,其无外乎就是从整体-局部、空间-通道、计算量-有效性这几个维度进行改进。比如,Non-local旨在通过汇总来自所有位置的信息来增强目标位置的特征。这个计算量是庞大的,因为它计算了每个点对之间的关系:
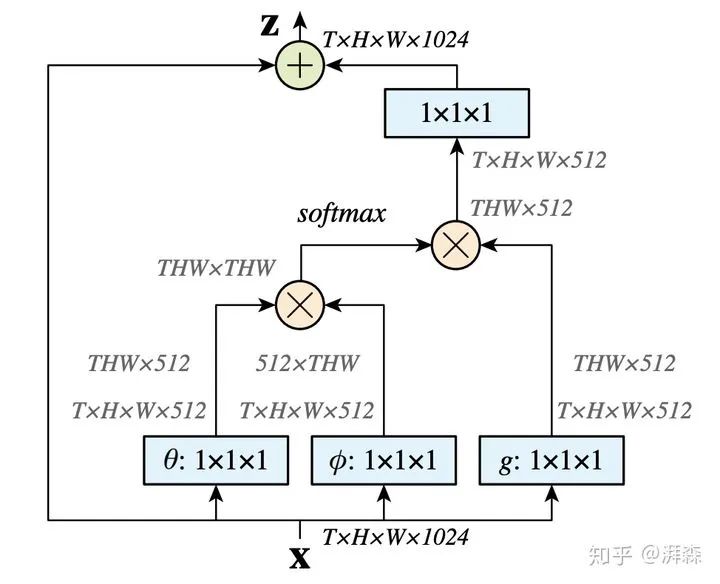
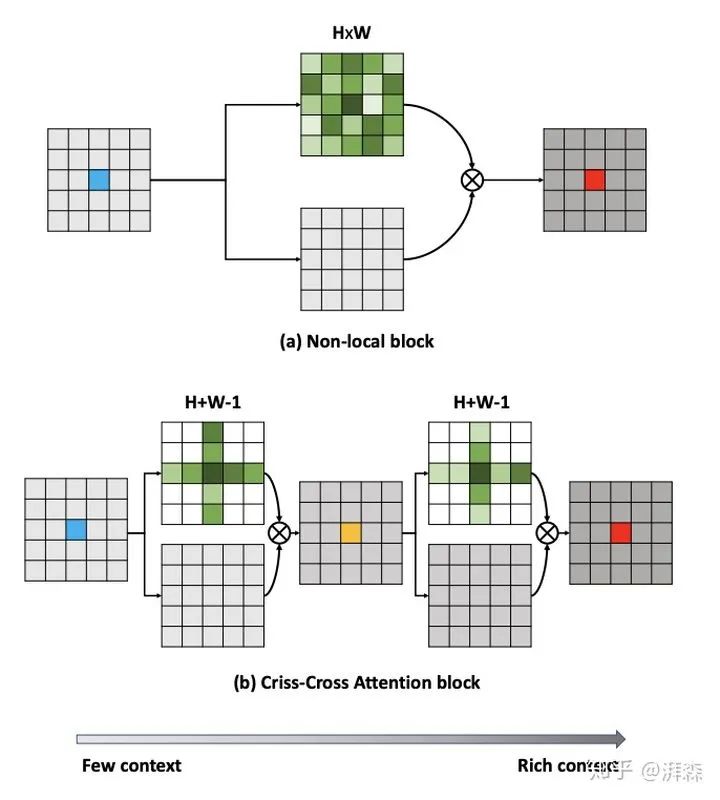
Non-Local虽然可以在特征图的空间上捕捉长距离的依赖(上下文信息),但是当我们输入的特征图尺度过大时,这显存大多数情况下会爆炸。那么如何在合理的保持全局的感受野的同时,去减少显存和运算量呢?于是很多人就往这上面改进,比如CC-Net[6],采用的是当前位置与同一行和同一列像素的之间的相关性来得到水平和垂直方向之间的远距离像素的上下文信息,并同时叠加两个相同的模块来间接的获得全局的感受野,减少了计算量。
本文的主要贡献点在于提出一个高效的“关系感知全局注意力”(Relation-aware Global attention, RGA)模块,该模块可以有效的捕获全局的结构信息,以便更好的进行注意力学习。具体来说,就是对每一个特征位置,为了更加紧凑地捕获全局的结构信息和局部的外观信息,使用RGA模块来将各种关系堆叠起来,即将所有的特征位置的成对相关性/亲和力(correlations/affinities)与特征本身一起,使用一个浅层神经网络来学习出注意力。通过应用RGA模块,可以显著的增强特征表示能力,从而学习到更具有判别力的特征。
这里简单的介绍下行人重识别的任务是做什么的:
行人重识别,简单来说就是要在不同的时间、地点或者相机上匹配到一个特定的人,属于图像检索的内容。其难点和核心便在于如何从杂乱的背景、姿态的多样性以及存在遮挡等各种复杂多变的情况下,有效地从人像图像中鉴别并提取出视觉特征(即区分出不同的人)。

注意力机制的本质就是以某种方式来探索事物的内在联系,通过不同的操作来对原始的输入进行一个要素的重分配,达到突出重要特征,抑制非重要特征的目的。作者认为,大多数的注意力只是通过在感受野有限的范围内利用卷积进行学习,这使得在一个全局的范围内很难利用到丰富的结构化信息。一种解决方案是在卷积层中使用空洞卷积,另一种解决方案是通过堆叠深度来达到一个全局信息的获取,但无疑这两种操作都会大大增加网络的规模。此外,如[8]所述,CNN的有效感受野仅占整个理论感受野的一小部分。除此之外,Non-local [1] 也被提出来通过成对的关系/亲和力来计算连接的去那种,使得神经网络能够通过从所有位置到目标位置之间的特征进行加权求和,从而捕获到全局的信息。然而,Non-local却忽略了许多丰富的全局信息探索。因为它仅仅是简单地将学习到的关系/亲和力当做权重来聚合特征。这种使用关系的确定性方式(即加权求和的方式)具备较弱的挖掘能力,并且也缺乏足够的适应性。因此,作者认为可以通过引入一种建模函数,从关系中挖掘出有效的信息,同时利用此类有价值的全局范围内的结构信息来引导注意力的学习。
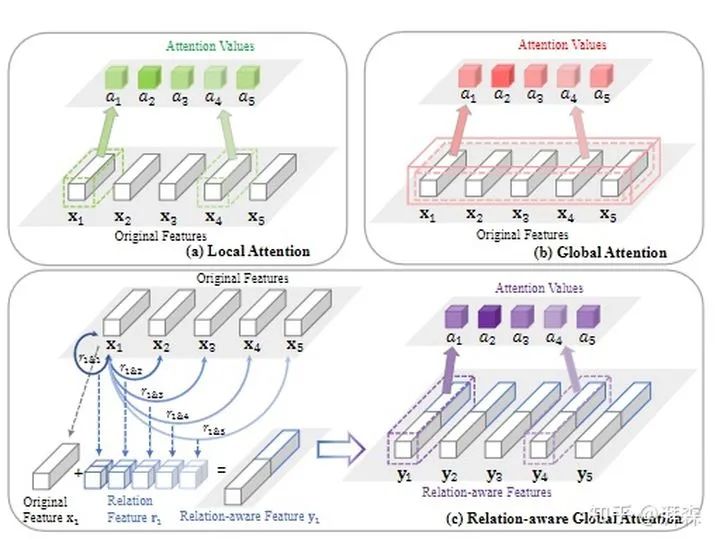
重点关注下图(c),即本文所提出来的RGA模块。RGA模块是通过同时考虑全局的关系信息来学习注意力。对于每一个特征向量i(这里取i=1为例),作者通过将当前特征向量(i=1)与其余特征向量直接进行两两的堆叠,得到  ,其代表着全局范围内的关系信息。注意到,这里
,其代表着全局范围内的关系信息。注意到,这里  。不同于图(a)的那种方式缺乏全局的感知和图(b)的那种方式没有充分不同特征向量之间的关系,所提出的RGA注意力模块,是通过一个具有全局范围关系的学习函数来确定的,其中包含作为输入的结构信息。可以看出,所提到的关系表示中的结构信息包括了亲和信息和位置信息,有助于语义学习和注意力推断。
。不同于图(a)的那种方式缺乏全局的感知和图(b)的那种方式没有充分不同特征向量之间的关系,所提出的RGA注意力模块,是通过一个具有全局范围关系的学习函数来确定的,其中包含作为输入的结构信息。可以看出,所提到的关系表示中的结构信息包括了亲和信息和位置信息,有助于语义学习和注意力推断。
方法部分梳理
给定一个特征集合  ,其中
,其中  表示特征/特征向量/特征节点,
表示特征/特征向量/特征节点,  为特征维度,
为特征维度,  为特征的数量。注意力便是要根据各个特征之间关系(也称为亲和性或者相似性)的重要程度,来为每个特征生成一个注意力系数(也称为亲和系数)。如上所示,图(a)是直接对每个特征向量都独立的进行一个注意力学习,缺乏全局的视野。一些弥补的方式便是通过利用空洞卷积或者堆叠卷积块来捕获全局的信息,但这样计算量明显是太大了。图(b)这种方式是通过将多个特征节点连接起来,然后通过全连接的方式去学习注意力。但是,当节点数量过多时,会导致计算效率低下,而且难以优化。图(c)则是本文所提出来的关系感知全局注意力模块,它有以下的两个优点:
为特征的数量。注意力便是要根据各个特征之间关系(也称为亲和性或者相似性)的重要程度,来为每个特征生成一个注意力系数(也称为亲和系数)。如上所示,图(a)是直接对每个特征向量都独立的进行一个注意力学习,缺乏全局的视野。一些弥补的方式便是通过利用空洞卷积或者堆叠卷积块来捕获全局的信息,但这样计算量明显是太大了。图(b)这种方式是通过将多个特征节点连接起来,然后通过全连接的方式去学习注意力。但是,当节点数量过多时,会导致计算效率低下,而且难以优化。图(c)则是本文所提出来的关系感知全局注意力模块,它有以下的两个优点:
更好地探索全局的结构化信息以及知识挖掘(knowledge mining);
使用一个共享(节省参数量)的变换函数来为每一个独立的特征位置去学习注意力;
这里相当于就是利用局部的卷积运算操作来间接的等效替代全局的运算。主要的思想是分别挖掘出当前特征节点与所有的特征节点之间的一个对与对之间的关系,并通过将这些关系对堆叠起来,来表示当前特征节点的一个全局结构化信息。具体来说,用  来表示第
来表示第  个特征和第
个特征和第  个特征之间的亲和性(affinity),对于特征节点
个特征之间的亲和性(affinity),对于特征节点  ,其亲和/关系向量为
,其亲和/关系向量为  。随后,利用当前特征本身与这些关系对,并通过一个可学习的变换函数(learned transformation function)来推断出注意力
。随后,利用当前特征本身与这些关系对,并通过一个可学习的变换函数(learned transformation function)来推断出注意力  ,这里
,这里  包含了全局的信息。从数学角度,作者这里通过一个图
包含了全局的信息。从数学角度,作者这里通过一个图  定义了特征的集合以及特征与特征之间的关系,其中便包含这 个特征的一个节点结合
定义了特征的集合以及特征与特征之间的关系,其中便包含这 个特征的一个节点结合  以及一个边缘集合
以及一个边缘集合  。于是,我们便可以将所有节点的关系对表示为一个亲和矩阵
。于是,我们便可以将所有节点的关系对表示为一个亲和矩阵  ,这里令
,这里令  。对于每一个
。对于每一个  ,令
,令  定义为第R个节点的第 行,
定义为第R个节点的第 行,  定义为第R个节点的第 列。
定义为第R个节点的第 列。
对于第 个特征节点 ,它相应的关系向量  提供了一个紧凑的表示来捕获全局结构信息,比如包含了所有特征节点的位置信息和关系信息。每一个关系对定义了所有的节点与当前节点的一个相似性,而当它们在关系向量中的位置表示特征节点的位置(即索引)时,关系向量反映了所有节点相对于当前节点的一种聚类状态和模式,而这将有利于整体确定 的相对重要性(注意力)。
提供了一个紧凑的表示来捕获全局结构信息,比如包含了所有特征节点的位置信息和关系信息。每一个关系对定义了所有的节点与当前节点的一个相似性,而当它们在关系向量中的位置表示特征节点的位置(即索引)时,关系向量反映了所有节点相对于当前节点的一种聚类状态和模式,而这将有利于整体确定 的相对重要性(注意力)。
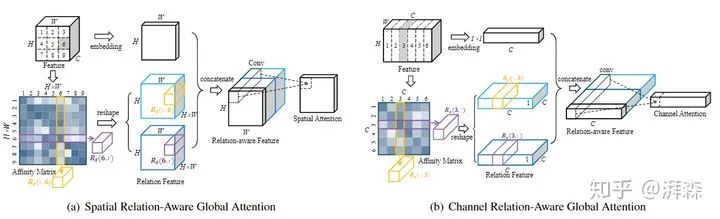
基于空间的关系感知全局注意力 ( Spatial Relation-Aware Global Attention )
给定一个中间的特征张量  ,这里
,这里  为CNN的某一层输出特征图,作者这里设计了一个RGA-S来学习一个尺度大小为
为CNN的某一层输出特征图,作者这里设计了一个RGA-S来学习一个尺度大小为  的空间关系图。这里按通道的划分方式将每个空间位置处
的空间关系图。这里按通道的划分方式将每个空间位置处  维特征向量作为特征节点。所有空间位置形成
维特征向量作为特征节点。所有空间位置形成  个节点的图
个节点的图 。如图(a)所示,对空间位置进行光栅扫描,并将其标识号指定为1,···,N。然后,计算出每个节点对之间的关系,这里利用点积的方式求出:
。如图(a)所示,对空间位置进行光栅扫描,并将其标识号指定为1,···,N。然后,计算出每个节点对之间的关系,这里利用点积的方式求出:
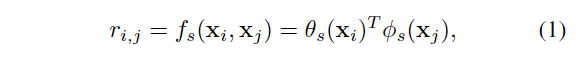
这里  和
和  为两个嵌入函数(其实就是通过一个1x1的卷积+BN+ReLU来实现)。同理,我们也可以通过同样的方式来计算出
为两个嵌入函数(其实就是通过一个1x1的卷积+BN+ReLU来实现)。同理,我们也可以通过同样的方式来计算出  。于是,我们便可以利用关系对
。于是,我们便可以利用关系对  来描述 和
来描述 和  之间的双向关系。最后,以此类推,我们便可以计算出所有节点之间的关系对,从而得到一个亲和矩阵 。然后,我们将这个关系对与原来的输入特征节点联结起来,通过一个全局平均池化求出相应的权重值,最后再通过Sigmoid激活函数来生成相应的权重图。
之间的双向关系。最后,以此类推,我们便可以计算出所有节点之间的关系对,从而得到一个亲和矩阵 。然后,我们将这个关系对与原来的输入特征节点联结起来,通过一个全局平均池化求出相应的权重值,最后再通过Sigmoid激活函数来生成相应的权重图。
基于通道的关系感知全局注意力 ( Channel Relation-Aware Global Attention )
跟上面差不多,只不过计算方式不一样。
总结
本文提倡的观点是,要直观地判断一个特征节点是否重要,就应该知道全局范围的特性,这样便可以通过得到进行决策所需要的关系信息,来更好地探索每个特征节点各自的全局关系,从而更好地学习注意力。整篇文章给人的感觉可读性非常差,作者在里面对一些名称的定义并没有进行一个统一,读起来云里雾里,涉嫌过度包装的成分,缺乏严谨性。感觉逻辑性并没有特别强,文章的核心很难get到,很疑惑审稿人真的有认真的去研究过这篇文章是不是真的能work?不过仔细想想也能体谅,毕竟现在注意力这块想发表到顶会上的难度越来越大,各个维度都被人魔改成不成样,很难找到一个标新立异的点切进去,所以只能靠花样的包装来刺激审稿人的神经。整体来说,创新性不是非常强,说白了还是在讲故事,还是没有从本质上创新,有点在玩改造积木的感觉。注意力方式跟其他注意力之间没啥大的区别,结合不同特征图的信息,然后合并起来,通过一个全连接或者普通的1x1或者3x3操作,最后再通过一个GAP和Sigmoid/Softmax输出。至于为什么能有效的降低计算量,只不过这里将一些计算量大(Fully connection)的操作换成小的操作(Conv 1×1)。(全连接>3×3卷积>1×1卷积)
套路还是那个套路,只不过看谁的故事讲的好。
Reference:
[1] Non-local Neural Networks. (CVPR2018)
[2] Squeeze-and-Excitation Networks. (CVPR2018)
[3] Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks. (MICCAI 2018)
[4] CBAM: Convolutional Block Attention Module. (ECCV 2018)
[5] Dual AttentionNetwork for Scene Segmentation. (CVPR 2019)
[6] CCNet: Criss-Cross Attention for Semantic Segmentation. (ICCV 2019)
[7] Real-time Semantic Segmentation with Fast Attention. (arxiv)
[8] Understanding the effective receptive field in deep convolutional neural networks. (NeurIPS 2016)

往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: