
如何设计 Feed 流系统?
说到 Feed 流,大家肯定都不陌生,我们每天刷的朋友圈,还有各种新闻类 APP,都是采用的这种方式。
那这样的系统应该如何设计呢?在开发过程中有哪些点需要注意呢?最近正好看到一篇相关的文章,分享给大家。
转载信息如下:
作者:Finley
链接:https://www.cnblogs.com/Finley/p/16857008.html
Feed 流产品在我们手机 APP 中几乎无处不在,比如微信朋友圈、新浪微博、今日头条等。只要大拇指不停地往下划手机屏幕,就有一条条的信息不断涌现出来。就像给宠物喂食一样,只要它吃光了就要不断再往里加,故此得名 Feed(饲养)。
Feed 流产品一般有两种形态,一种是基于算法推荐,另一种是基于关注关系并按时间排列。「关注页」这种按时间排序的 Feed 流也被为 Timeline。「关注页」自然的也被称为「关注 Timeline」, 存放自己发送过的 Feed 的页面被称为「个人 Timeline」 比如微博的个人页。
就是这么个 Feed 流系统让「淘金网」的工程师分成两派吵作一团,一直吵到了小明办公室。
推与拉之争
拉模型
一部分工程师认为应该在查询时首先查询用户关注的所有创作者 uid,然后查询他们发布的所有文章,最后按照发布时间降序排列。
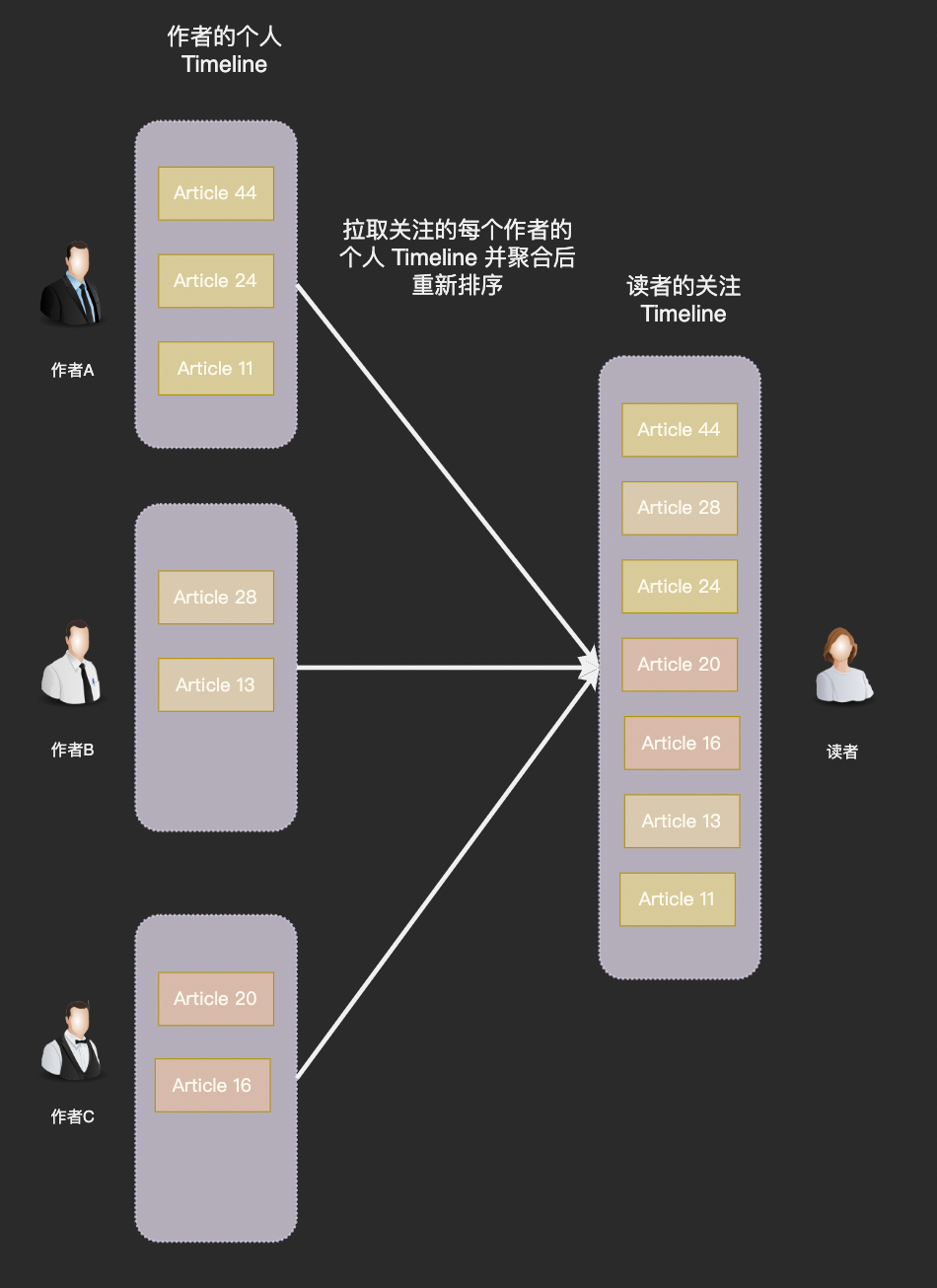
使用拉模型方案用户每打开一次「关注页」系统就需要读取 N 个人的文章(N 为用户关注的作者数), 因此拉模型也被称为读扩散。
拉模型不需要存储额外的数据,而且实现比较简单:发布文章时只需要写入一条 articles 记录,用户关注(或取消关注)也只需要增删一条 followings 记录。特别是当粉丝数特别多的头部作者发布内容时不需要进行特殊处理,等到读者进入关注页时再计算就行了。
拉模型的问题同样也非常明显,每次阅读「关注页」都需要进行大量读取和一次重新排序操作,若用户关注的人数比较多一次拉取的耗时会长到难以接受的地步。
推模型
另一部分工程师认为在创作者发布文章时就应该将新文章写入到粉丝的关注 Timeline,用户每次阅读只需要到自己的关注 Timeline 拉取就可以了:
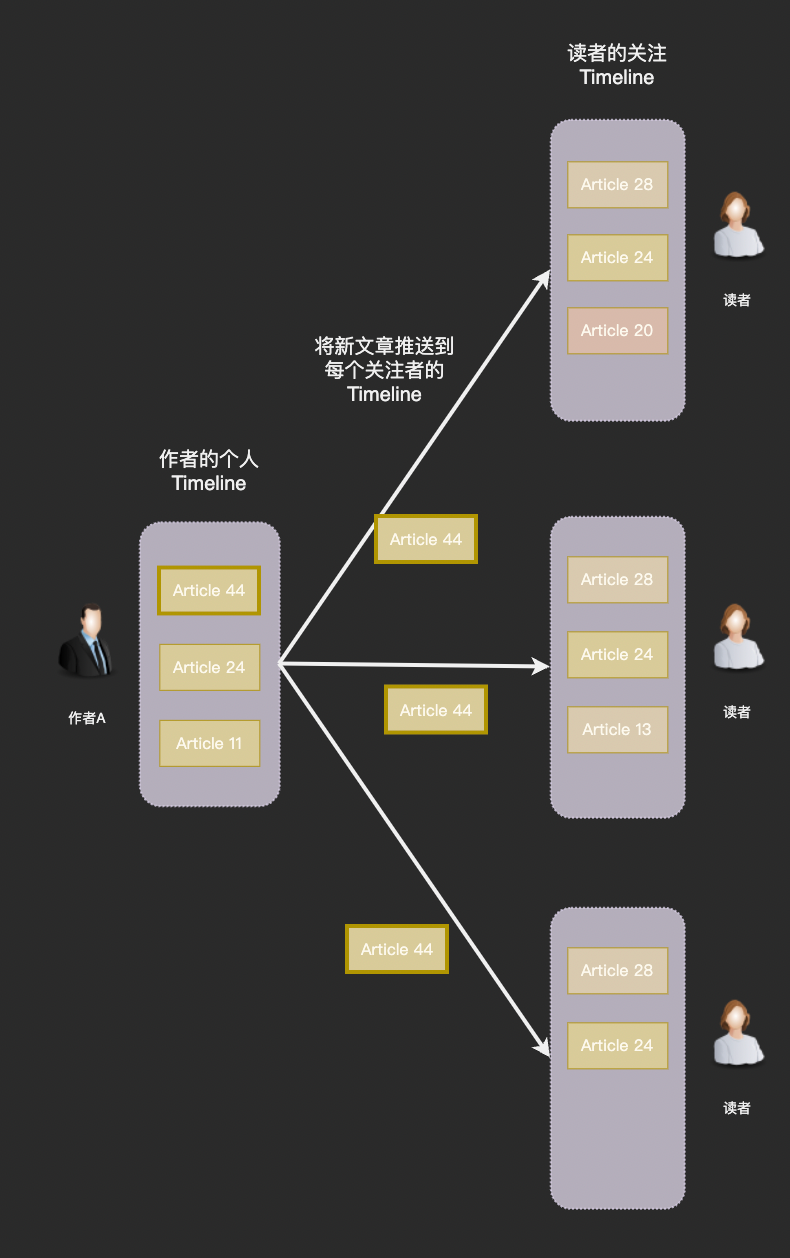
使用推模型方案创作者每次发布新文章系统就需要写入 M 条数据(M 为创作者的粉丝数),因此推模型也被称为写扩散。推模型的好处在于拉取操作简单高效,但是缺点一样非常突出。
首先,在每篇文章要写入 M 条数据,在如此恐怖的放大倍率下关注 Timeline 的总体数据量将达到一个惊人数字。而粉丝数有几十万甚至上百万的头部创作者每次发布文章时巨大的写入量都会导致服务器地震。
通常为了发布者的体验文章成功写入就向前端返回成功,然后通过消息队列异步地向粉丝的关注 Timeline 推送文章。

其次,推模型的逻辑要复杂很多,不仅发布新文章时需要实现相关逻辑,新增关注或者取消关注时也要各自实现相应的逻辑,听上去就要加很多班。
在线推,离线拉
在做出最终决定之前我们先来对比一下推拉模型:
| 优点 | 缺点 | |
|---|---|---|
| 推 | 读取操作快 | 逻辑复杂,消耗大量存储空间,粉丝数多的时候会是灾难 |
| 拉 | 逻辑简单,节约存储空间 | 读取效率低下,关注人数多的时候会出现灾难 |
虽然乍看上去拉模型优点多多,但是 Feed 流是一个极度读写不平衡的场景,读请求数比写请求数高两个数量级也不罕见,这使得拉模型消耗的 CPU 等资源反而更高。
此外推送可以慢慢进行,但是用户很难容忍打开页面时需要等待很长时间才能看到内容(很长:指等一秒钟就觉得卡)。因此拉模型读取效率低下的缺点使得它的应用受到了极大限制。
我们回过头来看困扰推模型的这个问题「粉丝数多的时候会是灾难」,我们真的需要将文章推送给作者的每一位粉丝吗?
仔细想想这也没有必要,我们知道粉丝群体中活跃用户是有限的,我们完全可以只推送给活跃粉丝,不给那些已经几个月没有启动 App 的用户推送新文章。
至于不活跃的用户,在他们回归后使用拉模型重新构建一下关注 Timeline 就好了。因为不活跃用户回归是一个频率很低的事件,我们有充足的计算资源使用拉模型进行计算。
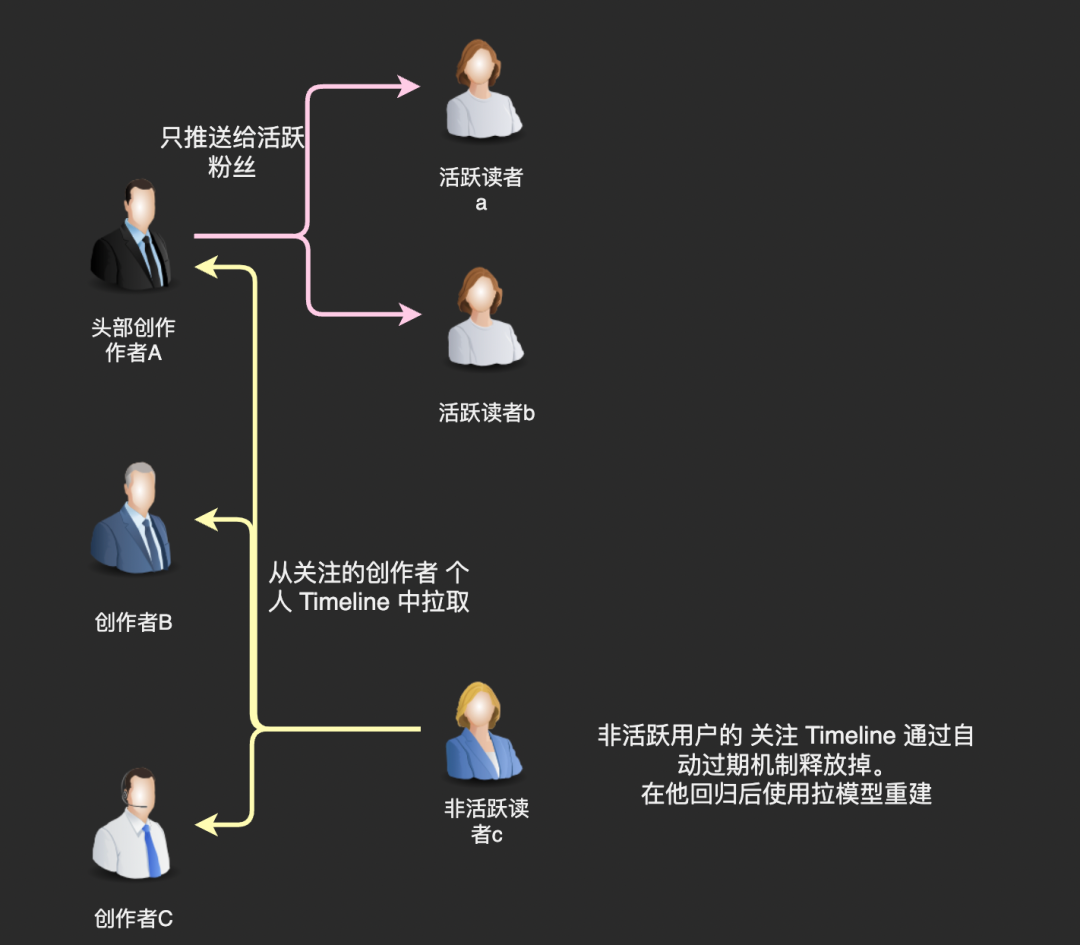
因为活跃用户和不活跃用户常常被叫做「在线用户」和「离线用户」,所以这种通过推拉结合处理头部作者发布内容的方式也被称为「在线推,离线拉」。
优化存储
在前面的讨论中不管是「关注 Timeline」还是关注关系等数据我们都存储在了 MySQL 中。拉模型可以用 SQL 描述为:
SELECT *
FROM articles
WHERE author_uid IN (
SELECT following_uid
FROM followings
WHERE uid = ?
)
ORDER BY create_time DESC
LIMIT 20;
通过查看执行计划我们发现,临时表去重+Filesort、这个查询叠了不少 debuff:
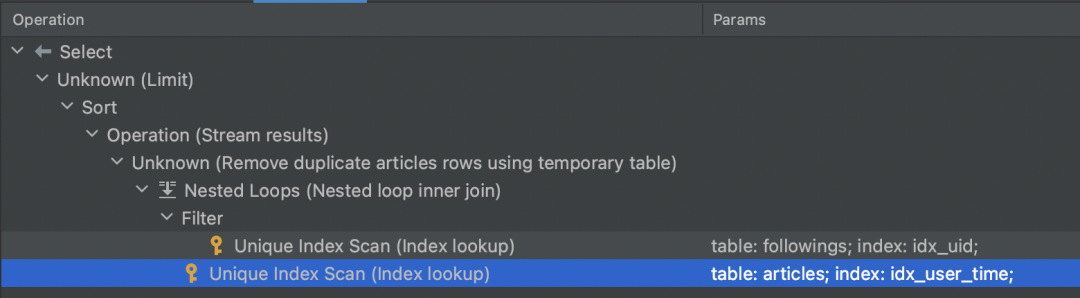
至于推模型,关注 Timeline 巨大的数据量和读写负载就不是 MySQL 能扛得住的。
遇事不决上 Redis
显然关注 Timeline 的数据是可以通过 articles 和 followings 两张表中数据重建的,其存在只是为了提高读取操作的效率。这有没有让你想起另外一个东西?
没错!就是缓存,关注 Timeline 实质上就是一个缓存,也就是说关注 Timeline 与缓存一样只需要暂时存储热门数据。
我们可以给关注 Timeline 存储设置过期时间,若用户一段时间没有打开 App 他的关注 Timeline 存储将被过期释放,在他回归之后通过拉模型重建即可。
在使用「在线推,离线拉」策略时我们需要判断用户是否在线,在为 Timeline 设置了过期时间后,Timeline 缓存是否存在本身即可以作为用户是否在线的标志。
就像很少有人翻看三天前的朋友圈一样,用户总是关心关注页中最新的内容,所以关注 Timeline 中也没有必要存储完整的数据只需要存储最近一段时间即可,旧数据等用户翻阅时再构建就行了。
鲁迅有句话说得好 ——「遇事不决上 Redis」,既然是缓存那么就是 Redis 的用武之地了。

Redis 中有序数据结构有列表 List 和有序集合 SortedSet 两种,对于关注 Timeline 这种需要按时间排列且禁止重复的场景当然闭着眼睛选 SortedSet。
将 article_id 作为有序集合的 member、发布时间戳作为 score, 关注 Timeline 以及个人 Timeline 都可以缓存起来。
在推送新 Feed 的时候只需要对目标 Timeline 的 SortedSet 进行 ZAdd 操作。若缓存中没有某个 Timeline 的数据就使用拉模型进行重建。
在使用消息队列进行推送时经常出现由于网络延迟等原因导致重复推送的情况,所幸 article_id 是唯一的,即使出现了重复推送 Timeline 中也不会出现重复内容。
这种重复操作不影响结果的特性有个高大上的名字 ——— 幂等性
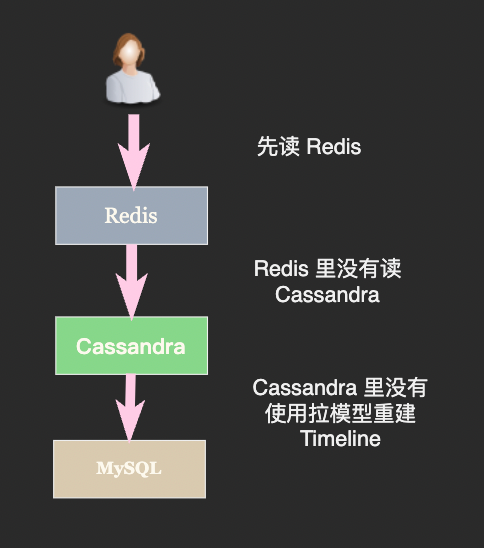
当 Redis 中没有某个 Timeline 的缓存时我们无法判断是缓存失效了,还是这个用户的 Timeline 本来就是空的。我们只能通过读取 MySQL 中的数据才能进行判断,这就是经典的缓存穿透问题。
对于时间线这种集合式的还存在第二类缓存穿透问题,正如我们刚刚提到的 Redis 中通常只存储最近一段时间的 Timeline,当我们读完了 Redis 中的数据之后无法判断数据库中是否还有更旧的数据。
这两类问题的解决方案是一样的,我们可以在 SortedSet 中放一个 NoMore 的标志,表示数据库中没有更多数据了。对于 Timeline 本来为空的用户来说,他们的 SortedSet 中只有一个 NoMore 标志:

最后一点:拉取操作要注意保持原子性不要将重建了一半的 Timeline 暴露出去:
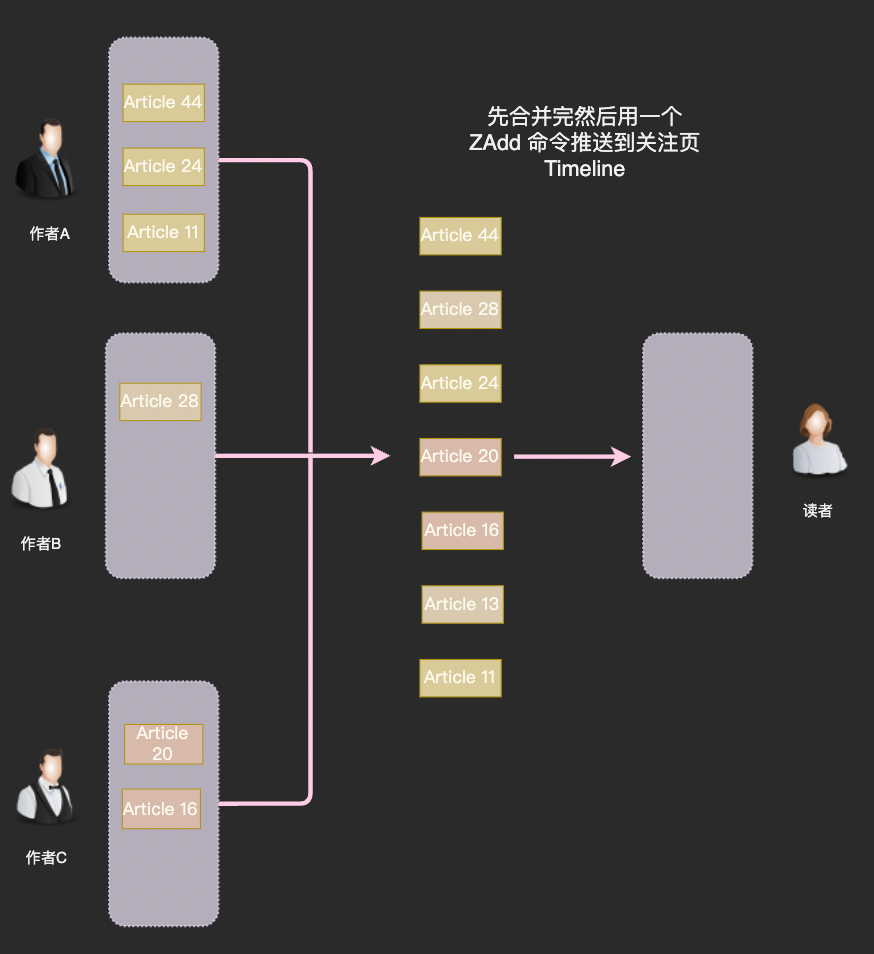
总结一下使用 Redis 做关注时间线的要点:
使用 SortedSet 结构存储,Member 为 FeedID,Score 为时间戳 给缓存设置自动过期时间,不活跃用户的缓存会自动被清除。使用「在线推,离线拉」时只给 Timeline 缓存未失效的用户推送即可 需要在缓存中放置标志来防止缓存击穿
一层缓存不够再来一层
虽然 Redis 可以方便的实现高性能的关注 Timeline 系统,但是内存空间总是十分珍贵的,我们常常没有足够的内存为活跃用户缓存关注 Timeline。
缓存不足是计算机领域的经典问题了,问问你的 CPU 它就会告诉你答案 —— 一级缓存不够用就做二级缓存,L1、L2、L3 都用光了我才会用内存。
只要是支持有序结构的 NewSQL 数据库比如 Cassandra、HBase 都可以胜任 Redis 的二级缓存:
附上一条 Cassandra 的表结构描述:
-- Cassandra 是一个 Map<PartionKey, SortedMap<ClusteringKey, OtherColumns>> 结构
-- 必须指定一个 PartionKey,顺序也只能按照 ClusteringKey 的顺序排列
-- 这里 PartionKey 是 uid, ClusteringKey 是 publish_time + article_id
-- publish_time 必须写在 ClusteringKey 第一列才能按照它进行排序
-- article_id 也写进 ClusteringKey 是为了防止 publish_time 出现重复
CREATE TABLE taojin.following_timelins (
uid bigint,
publish_time timestamp,
article_id bigin,
PRIMARY KEY (uid, publish_time, article_id)
) WITH default_time_to_live = 60 * 24 * 60 * 60;
这里还是要提醒一下,每多一层缓存便要多考虑一层一致性问题,到底要不要做多级缓存需要仔细权衡。
还有一些细节要优化
分页器
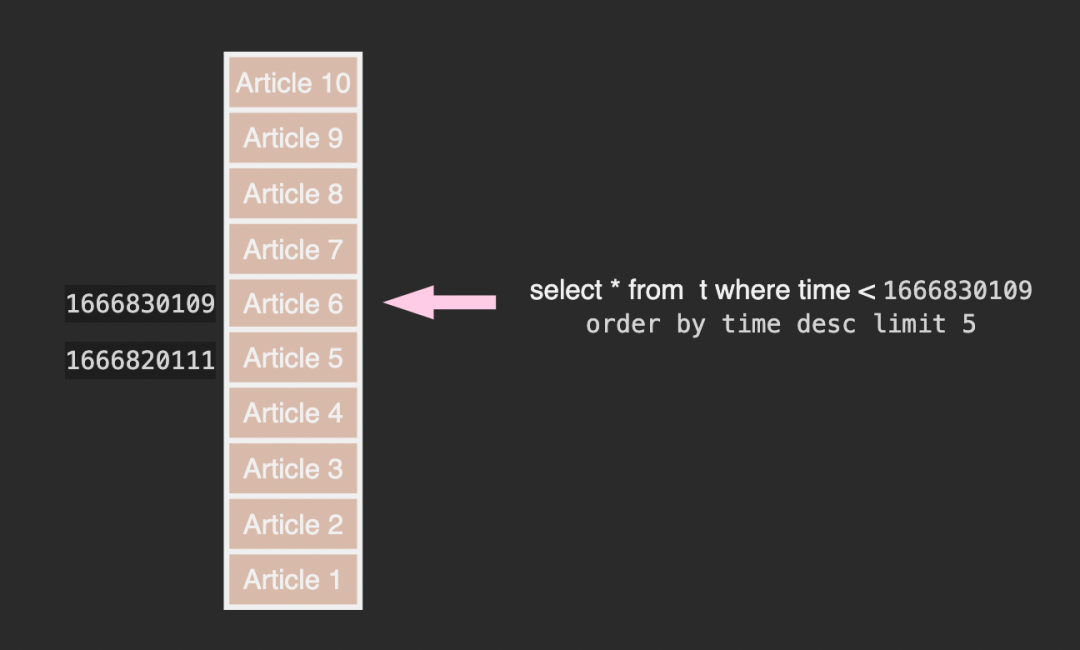
Feed 流是一个动态的列表,列表内容会随着时间不断变化。传统的 limit + offset 分页器会有一些问题:

在 T1 时刻读取了第一页,T2时刻有人新发表了 article 11 ,如果这时来拉取第二页,会导致 article 6 在第一页和第二页都被返回了。
解决这个问题的方法是根据上一页最后一条 Feed 的 ID 来拉取下一页:

使用 Feed ID 来分页需要先根据 ID 查找 Feed,然后再根据 Feed 的发布时间读取下一页,流程比较麻烦。若作为分页游标的 Feed 被删除了,就更麻烦了。
笔者更倾向于使用时间戳来作为游标:
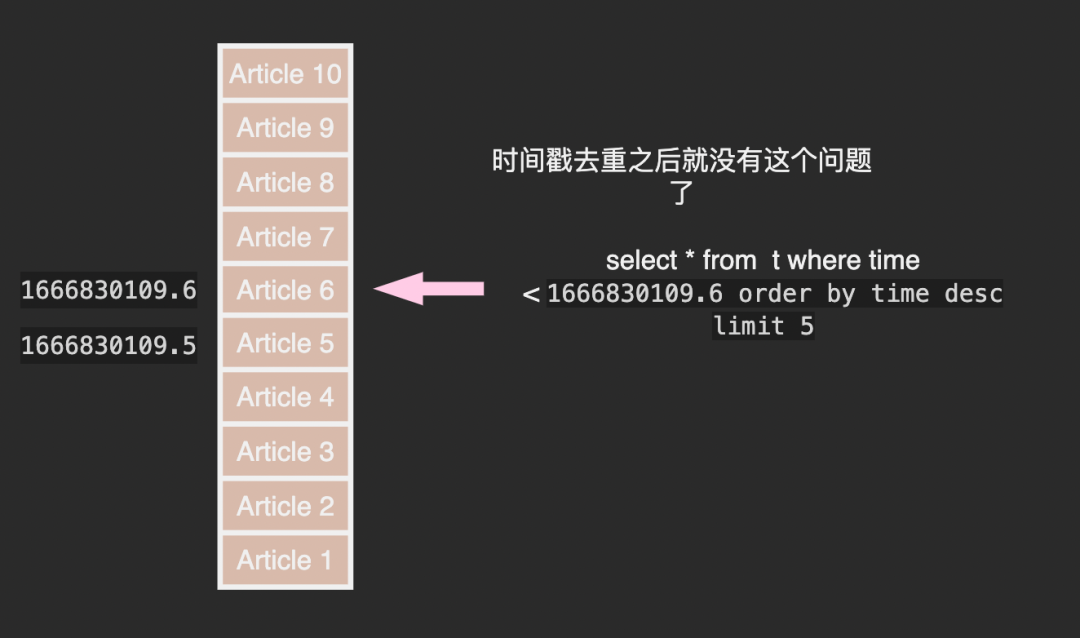
使用时间戳不可避免的会出现两条 Feed 时间戳相同的问题, 这会让我们的分页器不知所措。

这里有个小技巧是将 Feed id 作为 score 的小数部分,比如 article 11 在 2022-10-27 13:55:11 发布(时间戳 1666850112), 那么它的 score 为 1666850112.11 小数部分既不影响按时间排序又避免了重复。
大规模推送
虽然我们已经将推送 Feed 的任务转移给了 MQ Worker 来处理,但面对将 Feed 推送给上百万粉丝这样庞大的任务, 单机的 Worker 还是很难处理。而且一旦处理中途崩溃就需要全部重新开始。
我们可以将大型推送任务拆分成多个子任务,通过消息队列发送到多台 MQ Worker 上进行处理。

因为负责拆分任务的 Dispatcher 只需要扫描粉丝列表负担和故障概率大大减轻。若某个推送子任务失败 MQ 会自动进行重试,也无需我们担心。
总结
至此,我们完成了一个关注 Feed 流系统的设计。总结一下本文我们都讨论了哪些内容:
基本模型有两种。推模型:发布新 Feed 时推送到每个粉丝的 Timeline;拉模型:打开 Timeline 时拉取所有关注的人发布的 Feed,重新聚合成粉丝的 Timeline。推模型读取快,但是推送慢,粉丝数多的时候峰值负载很重。拉模型没有峰值问题,但是读取很慢用户打开 Timeline 时要等待很久,读极多写极少的环境中消耗的计算资源更多。 头部用户的几十上百万粉丝中活跃用户比例很少,所以我们可以只将他们的新 Feed 推送给活跃用户,不活跃用户等回归时再使用拉模型重建 Timeline。即通过「在线推、离线拉」的模式解决推模型的峰值问题。 虽然关注 Timeline 数据很多但实际上是一种缓存,没必要全部存储。我们按照缓存的思路只存储活跃用户、最近一段时间的数据即可,没有缓存的数据在用户阅读时再通过拉模型重建。 Timeline 推荐使用 Redis 的 SortedSet 结构存储,Member 为 FeedID,Score 为时间戳。给缓存设置自动过期时间,不活跃用户的缓存会自动被清除。使用「在线推,离线拉」时只给 Timeline 缓存未失效的用户推送即可。 在 Redis 内存不足时可以使用 Cassandra 作为 Redis 的二级缓存。
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
推荐阅读: