
基于 DAG 的任务编排框架/平台

- 前言 -
- 任务编排工作流 -
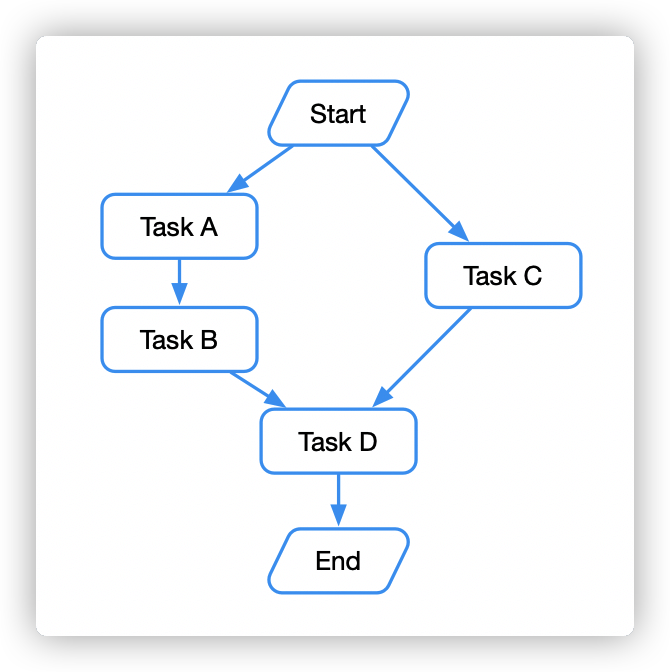
- DAG 有向无环图 -
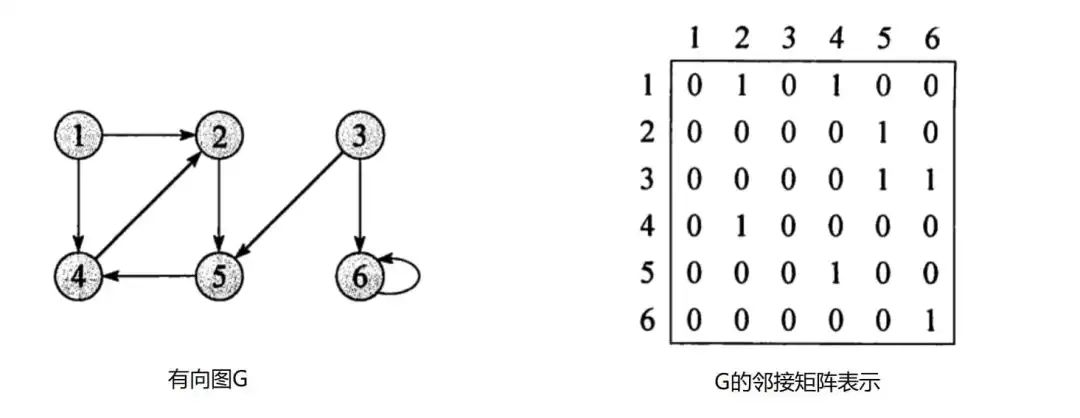
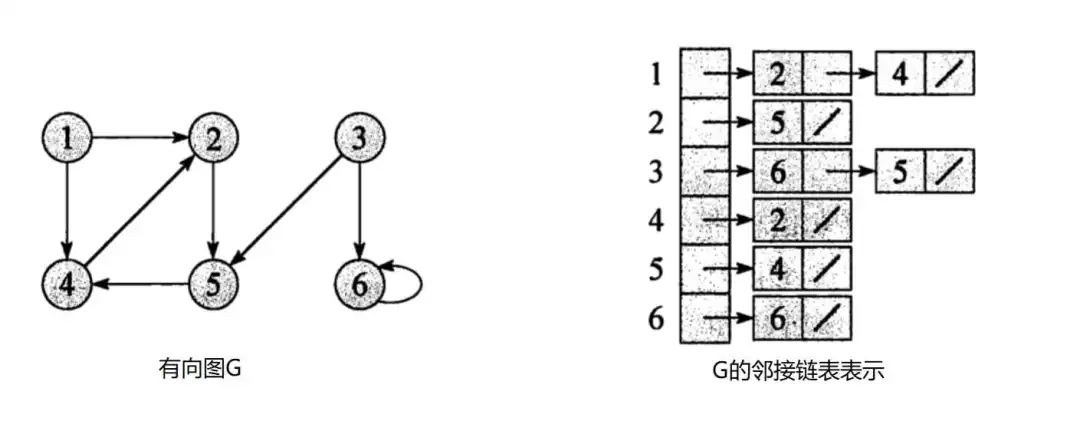
- 一个任务编排框架 -
//Dagpublic final class DefaultDag<T, R> implements Dag<T, R> {private Map<T, Node<T, R>> nodes = new HashMap<T, Node<T, R>>();...}//Nodepublic final class Node<T, R> {/*** incoming dependencies for this node*/private Set<Node<T, R>> parents = new LinkedHashSet<Node<T, R>>();/*** outgoing dependencies for this node*/private Set<Node<T, R>> children = new LinkedHashSet<Node<T, R>>();...}
public void addDependency(final T evalFirstNode, final T evalLaterNode) {Node<T, R> firstNode = createNode(evalFirstNode);Node<T, R> afterNode = createNode(evalLaterNode);addEdges(firstNode, afterNode);}private Node<T, R> createNode(final T value) {Node<T, R> node = new Node<T, R>(value);return node;}private void addEdges(final Node<T, R> firstNode, final Node<T, R> afterNode) {if (!firstNode.equals(afterNode)) {firstNode.getChildren().add(afterNode);afterNode.getParents().add(firstNode);}}
//任务编排线程池public class DefaultDexecutor <T, R> {//执行线程,和2种重试线程private final ExecutorService<T, R> executionEngine;private final ExecutorService immediatelyRetryExecutor;private final ScheduledExecutorService scheduledRetryExecutor;//执行状态private final ExecutorState<T, R> state;...}//执行状态public class DefaultExecutorState<T, R> {//底层图数据结构private final Dag<T, R> graph;//已完成private final Collection<Node<T, R>> processedNodes;//未完成private final Collection<Node<T, R>> unProcessedNodes;//错误taskprivate final Collection<ExecutionResult<T, R>> erroredTasks;//执行结果private final Collection<ExecutionResult<T, R>> executionResults;}可以看到我们的线程包括执行线程池,2 种重试线程池。我们使用 ExecutorState 来保存一些整个任务工作流执行过程中的一些状态记录,包括已完成和未完成的 task,每个 task 执行的结果等。同时它也依赖我们底层的图数据结构 DAG。
private void doProcessNodes(final Set<Node<T, R>> nodes) {for (Node<T, R> node : nodes) {//共享变量 并发等待if (!processedNodes.contains(node) && processedNodes.containsAll(node.getParents())) {Task<T, R> task = newTask(node);this.executionEngine.submit(task);...ExecutionResult<T, R> executionResult = this.executionEngine.processResult();if (executionResult.isSuccess()) {state.markProcessingDone(processedNode);}//继续执行孩子节点doExecute(processedNode.getChildren());...}}}
DefaultExecutor<String, String> executor = newTaskExecutor();executor.addDependency("A", "B");executor.addDependency("B", "D");executor.addDependency("C", "D");executor.execute();
- 任务编排平台化 -
task_idworkflow_idtask_nametask_statusresulttask_parents
task_id workflow_id task_name task_status result task_parents
1 1 A 0 -1
2 1 B 0 1
3 1 C 0 -1
4 1 D 0 2,3
作者:fredalxin
来源:fredal.xin/task-scheduling-based-on-dag

评论