
网易面试原题|简述Yolo系列网络的发展史
点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达
今天有一位粉丝向我分享了她在面试网易的时候,被问的一道题:“简述Yolo系列的发展史!”
那么在有限的时候,如何描绘清楚这些网络的发展呢?我们给了一些参考,同时也为了让各位好好理解,我们也给出了部分代码,整文很长,建议收藏!我们直接开冲!
YOLOv1
YOLOv1是单阶段目标检测方法,不需要像Faster RCNN这种两阶段目标检测方法一样,需要生成先验框。Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测。

整个YOLO目标检测pipeline如上图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN系列算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
具体来说,YOLO将全图划分为的格子, 每个格子负责对落入其中的目标进行检测,一次性预测所有格子所含目标的边界框、置信度、以及所有类别概率向量。
网格单元(Grid Cell)
YOLO将目标检测问题作为回归问题。会将输入图像分成的网格(cell),如果一个物体的中心点落入到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,会生成两个预测框。
对于每个网格单元cell:
YOLOv1会预测两个边界框 每个边界框包含5个元素: 和 边界框的置信度得分(box confidence score) 只负责预测一个目标 预测 个条件概率类别(conditional class probabilities)
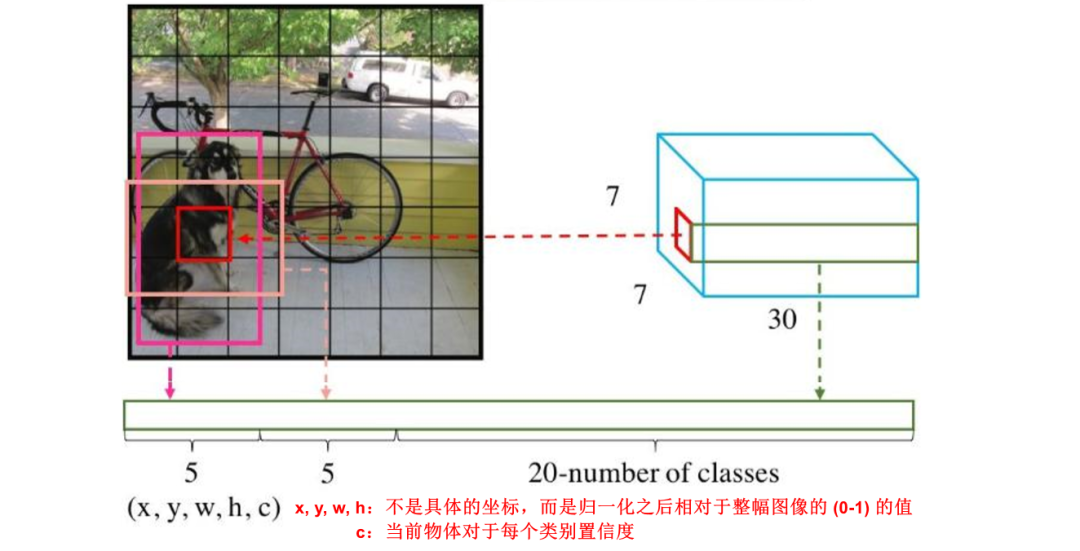
为了评估PASCAL VOC,YOLO V1使用 7×7 的网格(S×S),每个单元格回归2个边界框 和 20个条件类别概率。条件类别概率 (conditional class probability) 是检测到的目标属于特定类别的概率(每个单元对每个类别有一个概率)。
最终的预测特征由边框的位置、边框的置信度得分以及类别概率组成,这三者的含义如下:
边框位置:对每一个边框需要预测其中心坐标及宽、高这4个量, 两个边框共计8个预测值 边界框宽度w和高度h用图像宽度和高度归一化。因此 都在0和1之间。 和 是相应单元格的偏移量。 置信度得分(box confidence score) c :框包含一个目标的可能性(objectness)以及边界框的准确程度。类似于Faster RCNN 中是前景还是背景。由于有两个边框,因此会存在两个置信度预测值。 类别概率:由于PASCAL VOC数据集一共有20个物体类别,因此这里预测的是边框属于哪一个类别。
一个cell预测的两个边界框共用一个类别预测, 在训练时会选取与标签IoU更大的一个边框负责回归该真实物体框,在测试时会选取置信度更高的一个边框,另一个会被舍弃,因此整张图最多检测出49个物体。
网络结构
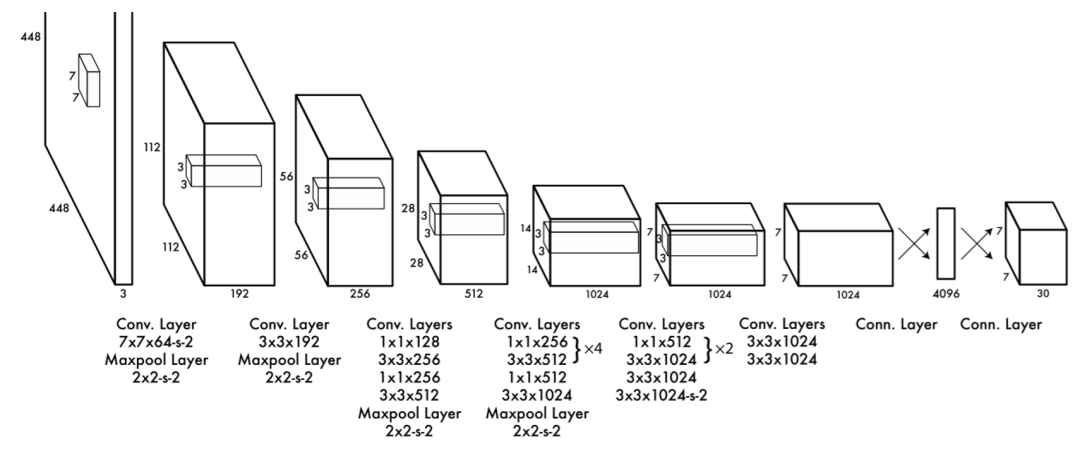
YOLO输入图像的尺寸为,经过24个卷积层,2个全连接的层(FC),最后在reshape操作,输出的特征图大小为。
YOLO主要是建立一个CNN网络生成预测 的张量, 然后使用两个全连接层执行线性回归,以进行 边界框预测。将具有高置信度得分(大于0.25)的结果作为最终预测。 在的卷积后通常会接一个通道数更低的卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。 除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU ; 在训练中使用了 Dropout 与数据增强的方法来防止过拟合。 对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。然后张量展开。使用2个全连接的层作为一种线性回归的形式,它输出 个参数,然后重新塑形为 (7, 7, 30) 。
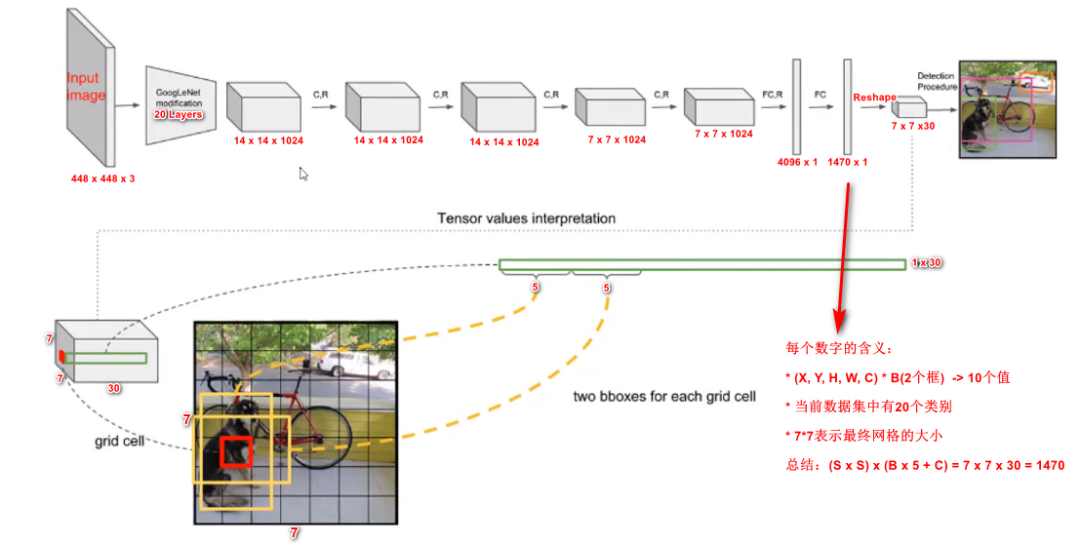
损失函数
YOLO V1每个网格单元能够预测多个边界框。为了计算true positive的损失,只希望其中一个框负责该目标,为此选择与GT具有最高IOU的那个框
YOLO正样本选择 当一个真实物体的中心点落在了某个cell内时,该cell就负责检测该物体。 具体做法是将与该真实物体有最大IoU的边框设为正样本, 这个区域的类别真值为该真实物体的类别,该边框的置信度真值为1。 YOLO负样本选择 除了上述被赋予正样本的边框,其余边框都为负样本。负样本没有类别损失与边框位置损失,只有置信度损失,其真值为0。
YOLO使用预测值和GT之间的误差平方的求和(MSE)来计算损失。损失函数包括
localization loss -> 坐标损失(预测边界框与GT之间的误差) classification loss -> 分类损失 confidence loss -> 置信度损失(框里有无目标, objectness of the box)
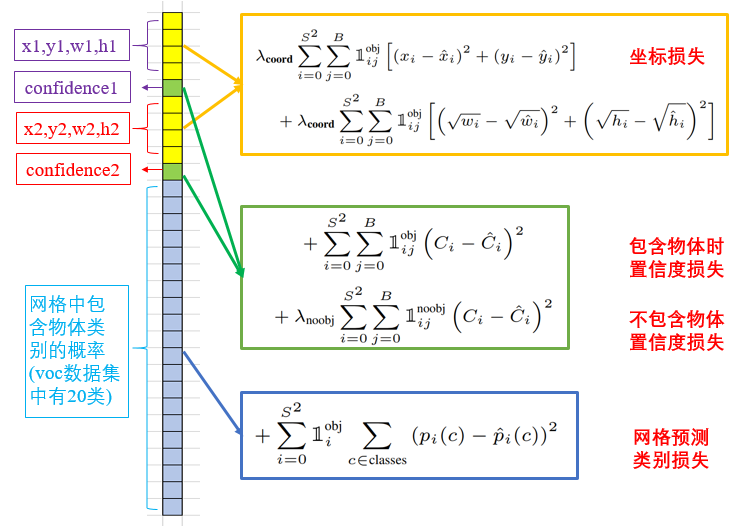
坐标损失
坐标损失也分为两部分,坐标中心误差和位置宽高的误差,其中 表示第i个网格中的第j个预测框是否负责obj这个物体的预测,只有当某个预测框对某个物体负责的时候,才会对box的coordinate error进行惩罚,而对哪个物体负责就看其预测值和GT box的IoU是不是在那个网格的所有box中最大。
我们可以看到,对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢?这里是这样的,我们先来看下图: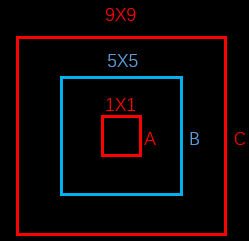 上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。而公式中的 为位置损失的权重系数,在pascal VOC训练中取5。
置信度损失
置信度也分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项代表预测框bounding box和真实标记的box之间的IoU。值越大则box越接近真实位置。
confidence是针对预测框bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。
从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。对没有物体的预测框的置信度损失,赋予小的loss weight, 记为在pascal VOC训练中取0.5。有有物体的预测框的置信度损失和类别的loss的loss weight正常取1。
类别损失
类别损失这里也用了均方误差。其中 表示有无物体的中心点落到网格i中,如果网格中包含有物体object的中心的话,那么就负责预测该object的概率。
YOLOv1的缺点由于YOLOV1的框架设计,该网络存在以下缺点:
每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。 原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。 最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。 对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病。
YOLOv2
Add BN
使用BN层提高准确度(Accuracy improvements)
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同, 那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同, 那么网络的 Batch 梯度下降算法就要在每次迭代都去学习适应不同的分布, 这样将会大大降低网络的训练速度。 解决办法是对数据都要做一个归一化预处理。YOLOv2网络通过在每一个卷积层后添加 批归一化 (batch normalization) ,极大的改善了收敛速度同时减少了对其它正则化方法的依赖(舍弃了 Dropout 优化后依然没有过拟合),使得mAP获得了2%的提升。
High Resolution Classifier [Focusing on backbone]
高分辨率分类器(High-resolution classifier )
Train on ImageNet (224 x 224) // Model trained on small images may not be good Resize & Finetune on ImageNet (448 x448) // So we finetune the model on larger images Finetune on dataset // To let the model be used to larger images We get 13 x 13 feature maps finally
所有State-Of-The-Art的检测方法都在ImageNet上对分类器进行了预训练。从AlexNet开始,多数分类器都把 输入图像Resize到 以下,这会容易丢失一些小目标的信息。
YOLOv1训练由两个阶段组成。首先,训练像VGG16这样的分类器网络。然后用卷积层替换全连接层,并端到端地重新训练以进行目标检测。YOLOv1先使用 的分辨率来训练分类网络,在训练检测网络的时候再切换到 的分辨率,这意味着YOLOv1的卷积层要重新适应新的分辨率,同时YOLOv1的网络还要学习检测网络。
直接切换分辨率,YOLOv1检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用 输入来 finetune 分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上微调之前已经适应高分辨率输入。YOLOv2 以 图片开始用于分类器训练,但是然后使用10个epoch再次用 图片重新调整分类器。让网络可以调整滤波器来适应高分辨率图像,这使得检测器训练更容易。使用高分辨率的分类网络提升了将近4%的mAP。
Fine-Grained Features
更细粒度的特征(Fine-Grained Features)
Lower features are concatenated directly to higher features A new layer is added for that purpose: reorg
浅层网络学到的是low-level信息,深层网络学到的是high-level信息。浅层信息包括预测框的位置信息,对目标的定位有很大的作用,决定是何种物体的是深层语义信息,所以需要将两种信息相结合。
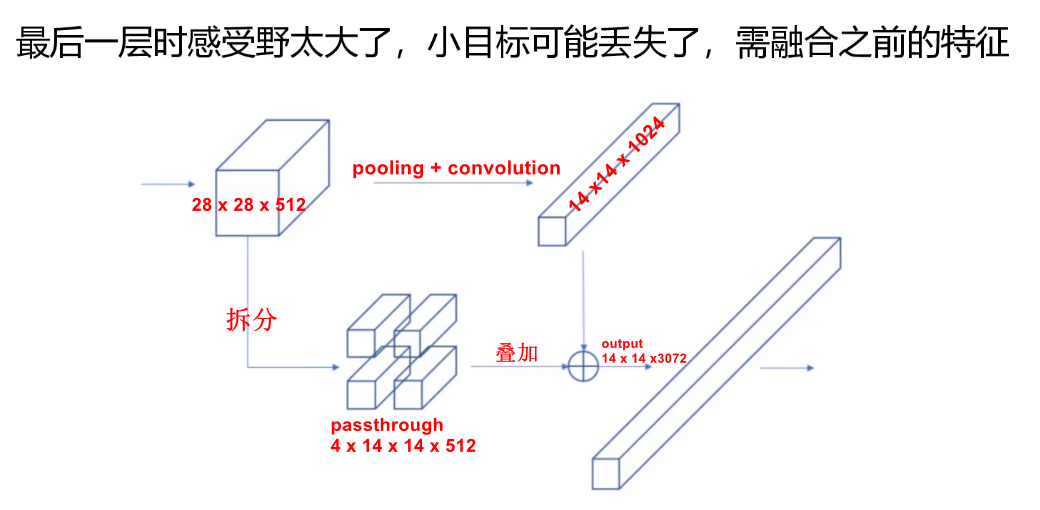
卷积层逐渐减小空间维度。随着相应的分辨率降低,检测小目标变得更加困难。其他目标检测器(如 SSD)可以从不同的特征图层中找到目标。所以每一层都专注于不同的尺度。 YOLO采用了一种称为 passthrough 的不同方法。它将层重整形为,然后将其与原始的输出层concat连接。在新的层上应用卷积滤波器来进行预测。YOLOv2使用该方法,进行特征融合,使得模型提升了1%的提升。
Multi-Scale Training
多尺度训练
Remove FC layers: Can accept any size of inputs, enhance model robustness. Size across 320, 352, ..., 608. Change per 10 batch [border % 32 = 0, decided by down sampling]
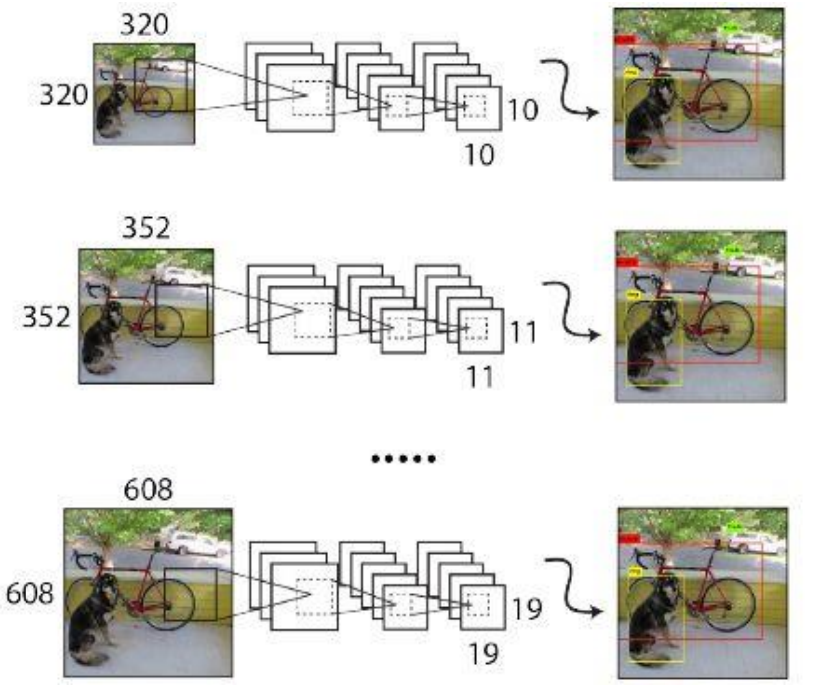
由于YOLOv2模型移除全连接层后只有卷积层和池化层,所以YOLOv2的输入可以不限于416×416大小的图片。 为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的迭代(iterations)之后改变模型的输入图片大小。 由于YOLOv2的为32倍下采样,输入图片大小选择一系列为32倍数的值:{320, 352,..., 608} ,输入图片最小为 ,此时对应的特征图大小为 ;而输入图片最大为 ,对应的特征图大小为 。 通过多尺度训练出的模型可以预测多个尺度的物体。并且,输入图片的尺度越大则精度越高,尺度越低则速度越快, 因此YOLO v2多尺度训练出的模型可以适应多种不同的场景要求。 在训练过程,每隔10个batch随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。 另外,可以使用较低分辨率的图像进行目标检测,但代价是准确度。这对于低GPU设备的速度来说是一个很好的权衡。 在288×288时,YOLO的运行速度超过90FPS,mAP几乎与Fast R-CNN一样好。在高分辨率下,YOLO在VOC 2007上实现了78.6 mAP
Anchor Boxes
聚类
在YOLO-V1中使用全连接层进行bounding box预测(要把1470×1的全连接层reshape为7×7×30的最终特征),这会丢失较多的空间信息,导致定位不准。Faster-RCNN和SSD中的先验框个数和宽高维度是手动设置不同比例(1:1;1:2;2:1)的先验框,因此很难确定设计出的一组预选框是最贴合数据集的,也就有可能为模型性能带来负面影响。
Motivation 设想能否一开始就选择更好的、更有代表性的先验框维度,那么网络就应该更容易学到准确的预测位置。 解决办法 统计学习中的 K-means聚类方法,通过对数据集中的 GT Box 做聚类,找到 GT Box 的统计规律。以聚类个数𝑘为锚定框个数,以𝑘个聚类中心Box的宽高维度为宽高的维度.
如果按照标准K-means使用欧式距离函数,大框比小框产生更多误差。但是,我们真正想要的是使得预测框与 GT框的有高的IOU得分,而与框的大小无关。因此采用了如下距离度量
IOU越大,边框距离越近。即聚类分析时选用Bbox与聚类中心Bbox之间的IOU值作为距离指标,聚类结果如下图:
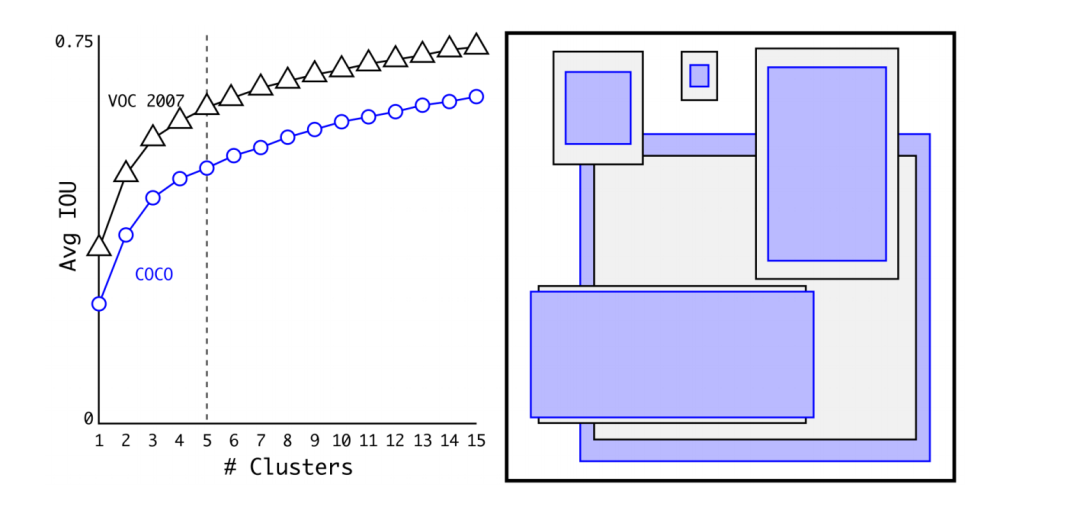 上面左图:随着𝑘的增大,IOU也在增大(高召回率),但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到𝑘值为5 。上面右图:5个聚类的中心与手动挑选的框是不同的,扁长的框较少,瘦高的框较多。作者文中的对比实验说明了 K-means 方法的生成的框更具有代表性,使得检测任务更容易学习。
上面左图:随着𝑘的增大,IOU也在增大(高召回率),但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到𝑘值为5 。上面右图:5个聚类的中心与手动挑选的框是不同的,扁长的框较少,瘦高的框较多。作者文中的对比实验说明了 K-means 方法的生成的框更具有代表性,使得检测任务更容易学习。
YOLO-V2中的anchor box可以同时预测类别和坐标。跟YOLO-V1比起来,去掉最后的池化层,确保输出的卷积特征图有更高的分辨率。缩减图片的输入尺寸,分辨率为416x416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。因为大物体通常占据了图像的中间位置,可以只用一个中心的cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测(增加计算复杂度),所以在YOLOv2 设计中要保证最终的特征图有奇数个位置。
YOLOv2使用卷积层降采样(factor=32),使得输入卷积网络的416x416的图片最终得到13x13的卷积特征图(416/32=13)。每个中心预测5种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个Cell一一对应。
YOLOv2把预测类别的机制从空间位置(Cell)中解耦,由Anchor Box同时预测类别和坐标。
YOLO v1是由每个Cell来负责预测类别,每个Cell对应的2个Bounding Box 负责预测坐标(YOLOv1中最后输出7×7×30的特征,每个Cell对应1×1×30,前10个主要是2个Bounding Box用来预测坐标,后20个表示该Cell在假设包含目标的条件下属于20个类别的概率)。 YOLO v2中,不再让类别的预测与每个Cell(空间位置)绑定一起,而是全部放到Anchor Box中。
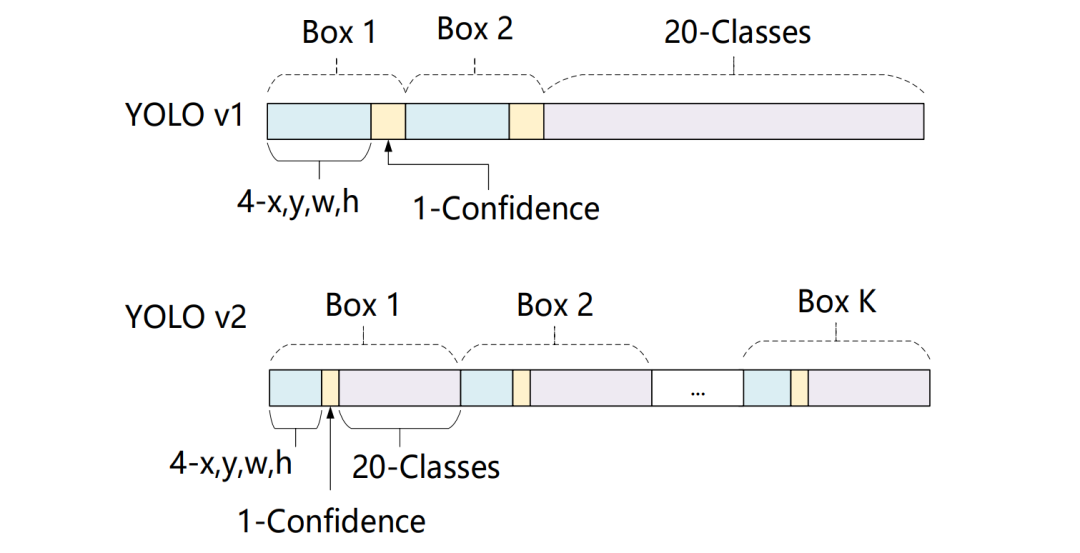
由于YOLO v2将类别预测从cell级别转移到边界框级别,在每一个区域预测5个边框,每个边框有25个预测值,因此最后输出的特征图通道数为125。其中,一个边框的25个预测值分别是20个类别预测、4个位置预测及1个置信度预测值。这里与v1有很大区别,v1是一个区域内的边框共享类别预测,而这里则是相互独立 的类别预测值。
YOLOv1只能预测98个边界框(7 × 7 × 2),而YOLOv2使用anchor boxes之后可以预测上千个边界框 (13 × 13 × 5 = 845) 。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来 的81%升至88%。
直接位置预测YOLOv2沿用v1版本的方法:预测边界框中心点相对于对应cell左上角位置的相对偏移量,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移量,这样预测值都在范围内。根据边界框预测的4个偏移值,可以使用如下公式来计算边界框实际中心位置和长宽:
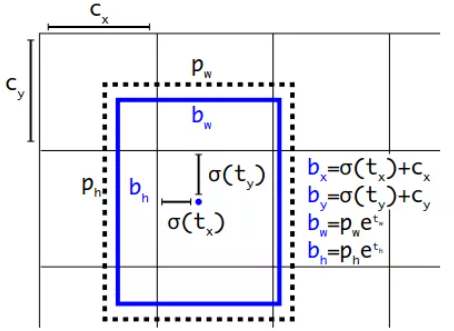 其中,为cell的左上角坐标。在上图中,当前的cell的左上角坐标为。由于sigmoid函数的处理,边界框的中心位置会被约束在当前cell的内部,防止偏移过多,然后和是先验框的宽度与高度,它们的值也是相对于特征图(这里是,我们把特征图的长宽记作H,W)大小的,在特征图中的cell长宽均为1。这样我们就可以算出边界框相对于整个特征图的位置和大小了。如果想得到边界框在原图的位置和大小,那就乘以上网络下采样的倍数。
其中,为cell的左上角坐标。在上图中,当前的cell的左上角坐标为。由于sigmoid函数的处理,边界框的中心位置会被约束在当前cell的内部,防止偏移过多,然后和是先验框的宽度与高度,它们的值也是相对于特征图(这里是,我们把特征图的长宽记作H,W)大小的,在特征图中的cell长宽均为1。这样我们就可以算出边界框相对于整个特征图的位置和大小了。如果想得到边界框在原图的位置和大小,那就乘以上网络下采样的倍数。
Darknet-19
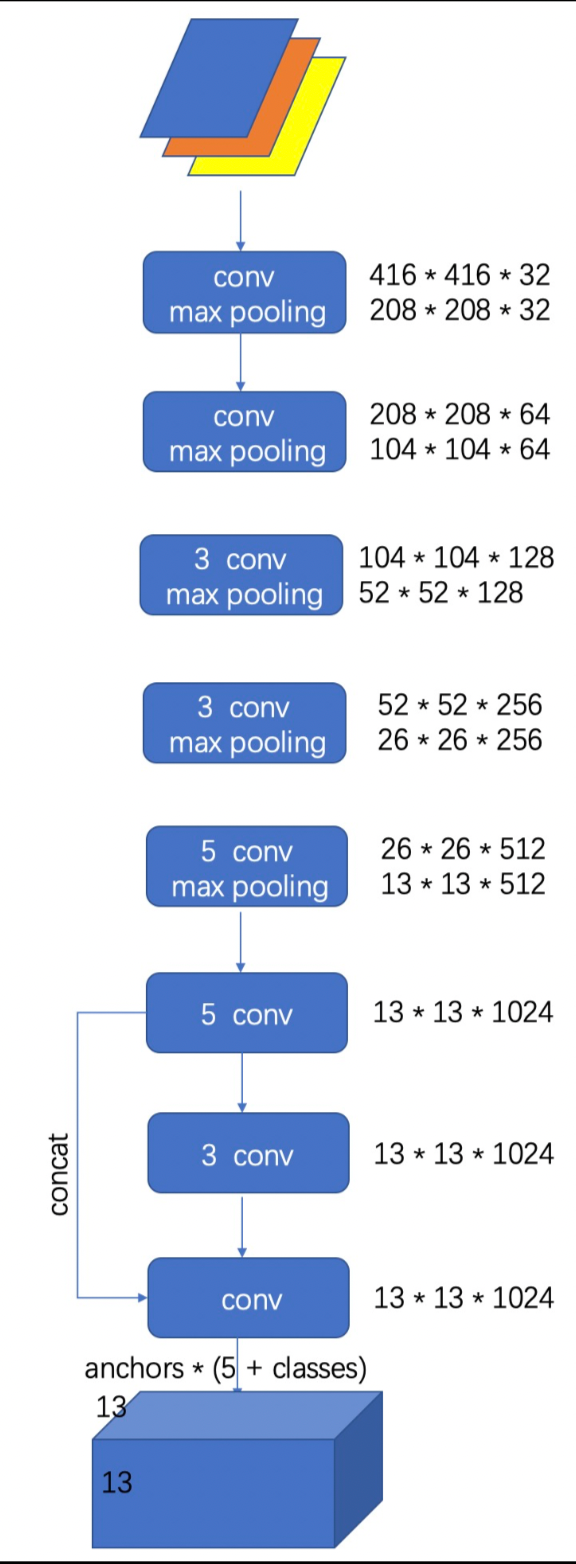
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个max pooling层。

Darknet-19 与 VGG16 模型设计原则是一致的,主要采用 卷积,采用 的最大池化层之后,特征图维度降低2倍,而同时将特征图的通道增加两倍。用连续 卷积替代了v1版本中的 卷积,这样既减少了计算量,又增加了网络深度。此外,DarkNet去掉了全连接层与Dropout层。 Darknet-19 ,包括19个卷积层 和 5个max pooling层,采用 global avg pooling+Softmax 做预测,与NIN(Network in Network)类似,并且在 卷积之间使用 卷积来压缩特征图通道以降低模型计算量和参数。 DarkNet的实际输入为 ,没有全连接层(FC层),5次降采样到 DarkNet使用了BN层,这一点带来了2%以上的性能提升。BN层有助于解决反向传播中的梯度消失与爆炸问题,可以加速模型的收敛,同时起到一定的正则化作用,降低模型过拟合。BN层的具体位置是在每一个卷积之后,激活函数LeakyReLU之前。 在ImageNet分类数据集上,Darknet-19的top-1准确度为72.9%,top-5准确度为91.2%,但是模型参数较小。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33% Passthrough层:DarkNet还进行了深浅层特征的融合,具体方法是将浅层 的特征变换为,这样就可以直接与深层 的特征进行通道拼接。这种特征融合有利于小物体的检测,也为模型带来了1%的性能提升。
YOLOv3
YOLOv3的总体网络架构图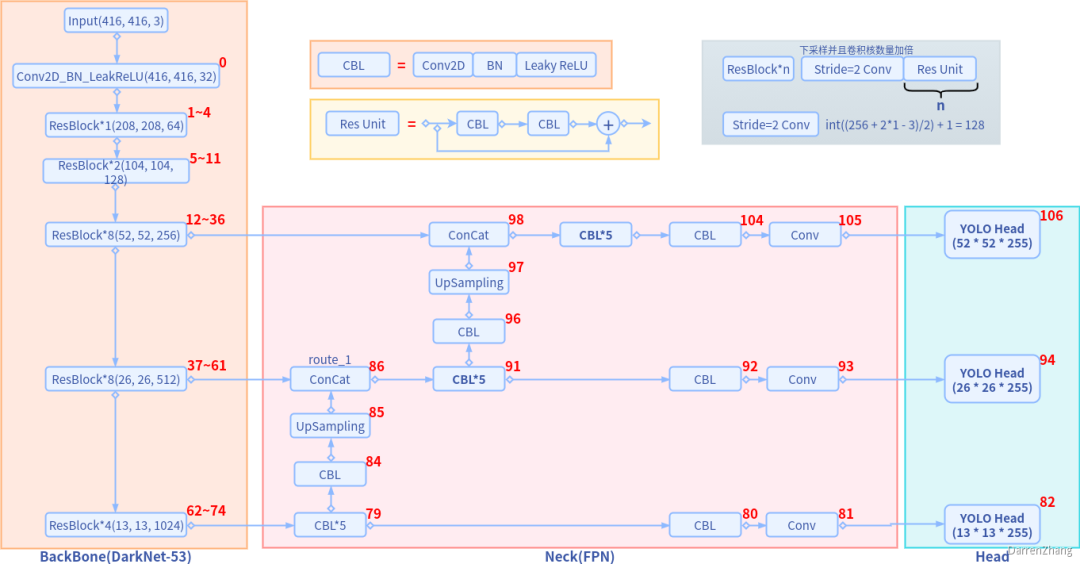 可根据官方代码中的yolov3.cfg进行一一对应,标号是第一个
可根据官方代码中的yolov3.cfg进行一一对应,标号是第一个[convolutional]
Darknet-53
和DarkNet-19一样,同样下采样32倍。但是darknet-19是通过最大池化来进行,一共有5次。而darknet-53是通过尺寸2,步长为2的卷积核来进行的,也是5次。darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53是可以和resnet-152正面刚的backbone,并且FPS大幅提升,看下表: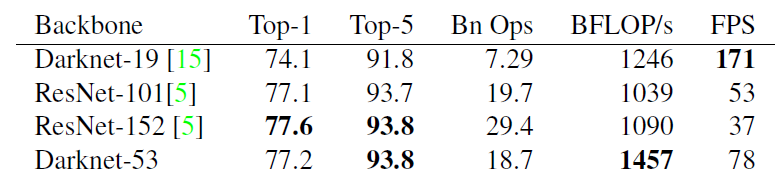
Neck层
YOLO v3中的Neck层采用FPN(feature pyramid networks)的思想,会输出了3个不同尺度的特征,然后输入到YOLO Head头中进行预测。采用多尺度来对不同大小的目标进行检测。
在YOLO v3的总体架构图中可以看出,Neck层输出的特征图空间尺寸为是第81层; 然后它后退2层,然后将其2倍上采样。然后,YOLOv3将第61层网络输出的具有更高分辨率的特征图(尺寸为),并使用concat将其与上采样特征图合并。YOLOv3在合并图上应用卷积滤波器以进行第二组预测 再次重复上一步骤,以使得到的特征图层具有良好的高级结构(语义)信息和目标位置的好的分辨率空间信息。
在YOLO v3中采用类似FPN的上采样和多尺度融合的做法(最后融合了3个尺度),在多个尺度的特征图上做检测,对于小目标的检测效果提升还是比较明显的。
Head头
为确定先验框priors,YOLOv3仍然应用k均值聚类。然后它预先选择9个聚类簇。对于COCO,锚定框的宽度和高度为。这应该是按照输入图像的尺寸是计算得到的。这9个priors根据它们的尺度分为3个不同的组。在检测目标时,给一个特定的特征图分配一个组。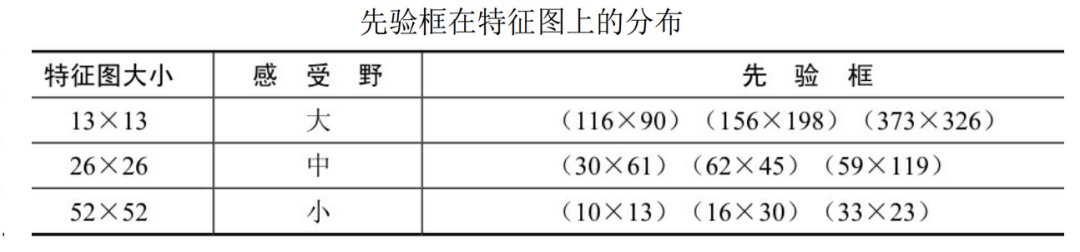
YOLO v3输出了3个大小不同的特征图,从上到下分别对应深层、中层与浅层的特征。深层的特征图尺寸小,感受野大,有利于检测大尺度物体,而浅层的特征图则与之相反,更便于检测小尺度物体。每一个特征图上的一个点只需要预测3个先验框,YOLO v2中每个grid cell预测5个边界框,其实不然。因为YOLO v3采用了多尺度的特征融合,所以边界框的数量要比之前多很多,以输入图像为为例:
YOLO v3的先验框要比YOLO v2产生的框更多。
如果使用coco数据集,其有80个类别,因此一个先验框需要80维的类别预测值、4个位置预测及1个置信度预测,3个预测框一共需要3×(80+5)=255维,也就是每一个特征图的通道数
类别预测(Class Prediction)
YOLO v3的另一个改进是使用了Logistic函数代替Softmax函数,以 处理类别的预测得分。原因在于,Softmax函数输出的多个类别预测之间会相互抑制,只能预测出一个类别,而Logistic分类器相互独立,可以实现多类别的预测。实验证明,Softmax可以被多个独立的Logistic分类器取代,并且准确率不会下降,这样的设计可以实现物体的多标签分类,例如一个物体如果是Women时,同时也属于Person这个类别。值得注意的是,Logistic类别预测方法在Mask RCNN中也被采用, 可以实现类别间的解耦。预测之后使用Binary的交叉熵函数可以进一步 求得类别损失。
边界框预测和代价函数计算 (Bounding box prediction & cost function calculation)
YOLOv3 使用逻辑回归Sigmoid预测每个边界框的置信度分数 YOLOv3改变了计算代价函数的方式。
如果边界框先验(锚定框)与GT目标的IOU比其他先验框大,则相应的目标性得分应为1。 对于重叠大于预定义阈值(默认值0.5)的其他先验框,不会产生任何代价。 每个GT目标仅与一个先验边界框相关联。如果没有分配先验边界框,则不会导致分类和定位损失,只会有目标性的置信度损失。
正样本:与GT的 IOU最大的框 负样本:与GT的 IOU<0.5的框 忽略的样本:与GT的 IOU>0.5但不是最大的值
一些YOLO的代码库都是使用配置文件配置网络结构,先提供一种使用pytorch实现的YOLOv3的code
darknet53.py
import sys
sys.path.append("..")
import torch.nn as nn
from model.layers.conv_module import Convolutional
from model.layers.blocks_module import Residual_block
class Darknet53(nn.Module):
def __init__(self):
super(Darknet53, self).__init__()
# 416*416*3 --> 416*416*32
self.__conv = Convolutional(filters_in=3, filters_out=32, kernel_size=3, stride=1, pad=1, norm='bn',
activate='leaky')
# 416*416*32 -> 208*208*64
self.__conv_5_0 = Convolutional(filters_in=32, filters_out=64, kernel_size=3, stride=2, pad=1, norm='bn',
activate='leaky')
# 208*208*64 -> 208*208*32 -> 208*208*64
self.__rb_5_0 = Residual_block(filters_in=64, filters_out=64, filters_medium=32)
# 208*208*64 -> 104*104*128
self.__conv_5_1 = Convolutional(filters_in=64, filters_out=128, kernel_size=3, stride=2, pad=1, norm='bn',
activate='leaky')
# 104*104*128 -> 104*104*64 -> 104*104*128
self.__rb_5_1_0 = Residual_block(filters_in=128, filters_out=128, filters_medium=64)
# 104*104*128 -> 104*104*64 -> 104*104*128
self.__rb_5_1_1 = Residual_block(filters_in=128, filters_out=128, filters_medium=64)
# 104*104*128 -> 52*52*256
self.__conv_5_2 = Convolutional(filters_in=128, filters_out=256, kernel_size=3, stride=2, pad=1, norm='bn',
activate='leaky')
# 52*52*256 -> 52*52*128 -> 52*52*256
self.__rb_5_2_0 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_1 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_2 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_3 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_4 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_5 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_6 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
self.__rb_5_2_7 = Residual_block(filters_in=256, filters_out=256, filters_medium=128)
# 52*52*256 -> 26*26*512
self.__conv_5_3 = Convolutional(filters_in=256, filters_out=512, kernel_size=3, stride=2, pad=1, norm='bn',
activate='leaky')
# 26*26*512 -> 26*26*256 -> 26*26*512
self.__rb_5_3_0 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_1 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_2 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_3 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_4 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_5 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_6 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
self.__rb_5_3_7 = Residual_block(filters_in=512, filters_out=512, filters_medium=256)
# 26*26*512 -> 13*13*1024
self.__conv_5_4 = Convolutional(filters_in=512, filters_out=1024, kernel_size=3, stride=2, pad=1, norm='bn',
activate='leaky')
# 13*13*1024 -> 13*13*512 -> 13*13*1024
self.__rb_5_4_0 = Residual_block(filters_in=1024, filters_out=1024, filters_medium=512)
self.__rb_5_4_1 = Residual_block(filters_in=1024, filters_out=1024, filters_medium=512)
self.__rb_5_4_2 = Residual_block(filters_in=1024, filters_out=1024, filters_medium=512)
self.__rb_5_4_3 = Residual_block(filters_in=1024, filters_out=1024, filters_medium=512)
def forward(self, x):
x = self.__conv(x)
x0_0 = self.__conv_5_0(x)
x0_1 = self.__rb_5_0(x0_0)
x1_0 = self.__conv_5_1(x0_1)
x1_1 = self.__rb_5_1_0(x1_0)
x1_2 = self.__rb_5_1_1(x1_1)
x2_0 = self.__conv_5_2(x1_2)
x2_1 = self.__rb_5_2_0(x2_0)
x2_2 = self.__rb_5_2_1(x2_1)
x2_3 = self.__rb_5_2_2(x2_2)
x2_4 = self.__rb_5_2_3(x2_3)
x2_5 = self.__rb_5_2_4(x2_4)
x2_6 = self.__rb_5_2_5(x2_5)
x2_7 = self.__rb_5_2_6(x2_6)
x2_8 = self.__rb_5_2_7(x2_7) # small
x3_0 = self.__conv_5_3(x2_8)
x3_1 = self.__rb_5_3_0(x3_0)
x3_2 = self.__rb_5_3_1(x3_1)
x3_3 = self.__rb_5_3_2(x3_2)
x3_4 = self.__rb_5_3_3(x3_3)
x3_5 = self.__rb_5_3_4(x3_4)
x3_6 = self.__rb_5_3_5(x3_5)
x3_7 = self.__rb_5_3_6(x3_6)
x3_8 = self.__rb_5_3_7(x3_7) # medium
x4_0 = self.__conv_5_4(x3_8)
x4_1 = self.__rb_5_4_0(x4_0)
x4_2 = self.__rb_5_4_1(x4_1)
x4_3 = self.__rb_5_4_2(x4_2)
x4_4 = self.__rb_5_4_3(x4_3) # large
return x2_8, x3_8, x4_4
##### Test Code #####
# import torch
# from torchsummary import summary
#
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# model = Darknet53().to(device=device)
# summary(model, (3, 416, 416))
yolo_fpn
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.layers.conv_module import Convolutional
class Upsample(nn.Module):
def __init__(self, scale_factor=1, mode='nearest'):
super(Upsample, self).__init__()
self.scale_factor = scale_factor
self.mode = mode
def forward(self, x):
return F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)
class Route(nn.Module):
def __init__(self):
super(Route, self).__init__()
def forward(self, x1, x2):
"""
x1 means previous output; x2 means current output
"""
out = torch.cat((x2, x1), dim=1)
return out
class FPN_YOLOV3(nn.Module):
"""
FPN for yolov3, and is different from original FPN or retinanet' FPN.
"""
def __init__(self, fileters_in, fileters_out):
super(FPN_YOLOV3, self).__init__()
fi_0, fi_1, fi_2 = fileters_in
fo_0, fo_1, fo_2 = fileters_out
# large 输入:13*13*1024
self.__conv_set_0 = nn.Sequential(
Convolutional(filters_in=fi_0, filters_out=512, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=512, filters_out=1024, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=1024, filters_out=512, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=512, filters_out=1024, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=1024, filters_out=512, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
)
self.__conv0_0 = Convolutional(filters_in=512, filters_out=1024, kernel_size=3, stride=1,
pad=1, norm="bn", activate="leaky")
self.__conv0_1 = Convolutional(filters_in=1024, filters_out=fo_0, kernel_size=1, stride=1, pad=0)
# 输出 13*13*3*(20+5)
# 上采样准备与24*24*512的中等scale进行融合
self.__conv0 = Convolutional(filters_in=512, filters_out=256, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky")
self.__upsample0 = Upsample(scale_factor=2)
self.__route0 = Route()
# medium 输入26*26*512
self.__conv_set_1 = nn.Sequential(
Convolutional(filters_in=fi_1 + 256, filters_out=256, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=256, filters_out=512, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=512, filters_out=256, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=256, filters_out=512, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=512, filters_out=256, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
)
self.__conv1_0 = Convolutional(filters_in=256, filters_out=512, kernel_size=3, stride=1,
pad=1, norm="bn", activate="leaky")
self.__conv1_1 = Convolutional(filters_in=512, filters_out=fo_1, kernel_size=1,
stride=1, pad=0)
# 输出 26*26*3*(20+5)
# 上采样,准备与56*56*256的小scale进行融合
self.__conv1 = Convolutional(filters_in=256, filters_out=128, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky")
self.__upsample1 = Upsample(scale_factor=2)
self.__route1 = Route()
# small
self.__conv_set_2 = nn.Sequential(
Convolutional(filters_in=fi_2 + 128, filters_out=128, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=128, filters_out=256, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=256, filters_out=128, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
Convolutional(filters_in=128, filters_out=256, kernel_size=3, stride=1, pad=1, norm="bn",
activate="leaky"),
Convolutional(filters_in=256, filters_out=128, kernel_size=1, stride=1, pad=0, norm="bn",
activate="leaky"),
)
self.__conv2_0 = Convolutional(filters_in=128, filters_out=256, kernel_size=3, stride=1,
pad=1, norm="bn", activate="leaky")
self.__conv2_1 = Convolutional(filters_in=256, filters_out=fo_2, kernel_size=1,
stride=1, pad=0)
# 输出 52*52*3*(20+5)
def forward(self, x0, x1, x2): # large, medium, small
# large
r0 = self.__conv_set_0(x0) # DBL*5
out0 = self.__conv0_0(r0) # DBL
out0 = self.__conv0_1(out0) # conv -> 13*13*3*(20+5)
# medium
r1 = self.__conv0(r0) # DBL
r1 = self.__upsample0(r1) # Upsample
x1 = self.__route0(x1, r1) # concat
r1 = self.__conv_set_1(x1) # DBL*5
out1 = self.__conv1_0(r1) # DBL
out1 = self.__conv1_1(out1) # conv -> 26*26*3*(20+5)
# small
r2 = self.__conv1(r1) # DBL
r2 = self.__upsample1(r2) # Upsample
x2 = self.__route1(x2, r2) # concat
r2 = self.__conv_set_2(x2) # DBL*5
out2 = self.__conv2_0(r2) # DBL
out2 = self.__conv2_1(out2) # conv -> 52*52*3*(20+5)
return out2, out1, out0 # small, medium, large
yolo_head
import torch.nn as nn
import torch
class Yolo_head(nn.Module):
def __init__(self, nC, anchors, stride):
super(Yolo_head, self).__init__()
self.__anchors = anchors # [(1.25, 1.625), (2.0, 3.75), (4.125, 2.875)]
self.__nA = len(anchors)
self.__nC = nC
self.__stride = stride # 8
def forward(self, p): # p: [4, 75, 52, 52]
# 获取batch_size 和 feature map的宽
bs, nG = p.shape[0], p.shape[-1]
# [batch_size, 3, (4,1,20), scale, scale] -> [batch_size, scale, scale, 3, (4,1,20)]
p = p.view(bs, self.__nA, 5 + self.__nC, nG, nG).permute(0, 3, 4, 1, 2) # 4*52*52*3*25
p_de = self.__decode(p.clone())
return (p, p_de)
def __decode(self, p):
""" 解码过程
1. 生成抛锚框
2. 根据预测调整锚框
"""
batch_size, output_size = p.shape[:2]
device = p.device
stride = self.__stride # -8-/16/32
anchors = (1.0 * self.__anchors).to(device) # [(1.25, 1.625), (2.0, 3.75), (4.125, 2.875)]
conv_raw_dxdy = p[:, :, :, :, 0:2] # [batch_size, scale, scale, 3, 2],获取最后一个维度中的前两维作为调整参数x,y
conv_raw_dwdh = p[:, :, :, :, 2:4] # [batch_size, scale, scale, 3, 2],获取最后一个维度中的3和4维作为调整参数h,w
conv_raw_conf = p[:, :, :, :, 4:5] # [batch_size, scale, scale, 3, 1],获取最后一个维度中的5维作为框内有无目标置信度
conv_raw_prob = p[:, :, :, :, 5:] # [batch_size, scale, scale, 3, 20],获取最后一个维度中的后20维作为VOC数据类别的结果
# !----------- 生成特征图的坐标点 ------------- #
# [[0, ..., 0],[1, ..., 1],..., [51, ..., 51]]
y = torch.arange(0, output_size).unsqueeze(1).repeat(1, output_size) # [52, 52]
# [[0, ..., 51],[0, ..., 51],..., [0, ..., 51]]
x = torch.arange(0, output_size).unsqueeze(0).repeat(output_size, 1) # [52, 52]
grid_xy = torch.stack([x, y], dim=-1) # 相当于标记处特征图的每个格子左上角的坐标
# 因为要生成3个先验框,所以也可以生成三个特征图,每个特征图对应不同的先验框
grid_xy = grid_xy.unsqueeze(0).unsqueeze(3).repeat(batch_size, 1, 1, 3, 1).float().to(device)
# 中心点调整参数进行Sigmoid操作归一化到[0,1],然后对锚框的中心点进行调整
pred_xy = (torch.sigmoid(conv_raw_dxdy) + grid_xy) * stride # grid_xy: 锚框的中心点,
# 宽高调整参数进行指数运算,然后对锚框的宽高进行调整
pred_wh = (torch.exp(conv_raw_dwdh) * anchors) * stride # anchors: 锚框的初始换宽高
pred_xywh = torch.cat([pred_xy, pred_wh], dim=-1)
pred_conf = torch.sigmoid(conv_raw_conf)
pred_prob = torch.sigmoid(conv_raw_prob)
pred_bbox = torch.cat([pred_xywh, pred_conf, pred_prob], dim=-1)
return pred_bbox.view(-1, 5 + self.__nC) if not self.training else pred_bbox
loss
import sys
sys.path.append("../utils")
import torch
import torch.nn as nn
from utils import tools
import config.yolov3_config_voc as cfg
class FocalLoss(nn.Module):
def __init__(self, gamma=2.0, alpha=1.0, reduction="mean"):
super(FocalLoss, self).__init__()
self.__gamma = gamma
self.__alpha = alpha
self.__loss = nn.BCEWithLogitsLoss(reduction=reduction)
def forward(self, input, target):
loss = self.__loss(input=input, target=target)
loss *= self.__alpha * torch.pow(torch.abs(target - torch.sigmoid(input)), self.__gamma)
return loss
class YoloV3Loss(nn.Module):
def __init__(self, anchors, strides, iou_threshold_loss=0.5):
super(YoloV3Loss, self).__init__()
self.__iou_threshold_loss = iou_threshold_loss
self.__strides = strides
def forward(self, p, p_d, label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes):
"""
:param p: Predicted offset values for three detection layers.
The shape is [p0, p1, p2], ex. p0=[bs, grid, grid, anchors, tx+ty+tw+th+conf+cls_20]
:param p_d: Decodeed predicted value. The size of value is for image size.
ex. p_d0=[bs, grid, grid, anchors, x+y+w+h+conf+cls_20]
:param label_sbbox: Small detection layer's label. The size of value is for original image size.
shape is [bs, grid, grid, anchors, x+y+w+h+conf+mix+cls_20]
:param label_mbbox: Same as label_sbbox.
:param label_lbbox: Same as label_sbbox.
:param sbboxes: Small detection layer bboxes.The size of value is for original image size.
shape is [bs, 150, x+y+w+h]
:param mbboxes: Same as sbboxes.
:param lbboxes: Same as sbboxes
"""
strides = self.__strides
loss_s, loss_s_giou, loss_s_conf, loss_s_cls = self.__cal_loss_per_layer(p[0], p_d[0], label_sbbox,
sbboxes, strides[0])
loss_m, loss_m_giou, loss_m_conf, loss_m_cls = self.__cal_loss_per_layer(p[1], p_d[1], label_mbbox,
mbboxes, strides[1])
loss_l, loss_l_giou, loss_l_conf, loss_l_cls = self.__cal_loss_per_layer(p[2], p_d[2], label_lbbox,
lbboxes, strides[2])
loss = loss_l + loss_m + loss_s
loss_giou = loss_s_giou + loss_m_giou + loss_l_giou
loss_conf = loss_s_conf + loss_m_conf + loss_l_conf
loss_cls = loss_s_cls + loss_m_cls + loss_l_cls
return loss, loss_giou, loss_conf, loss_cls
def __cal_loss_per_layer(self, p, p_d, label, bboxes, stride):
"""
(1)The loss of regression of boxes.
GIOU loss is defined in https://arxiv.org/abs/1902.09630.
Note: The loss factor is 2-w*h/(img_size**2), which is used to influence the
balance of the loss value at different scales.
(2)The loss of confidence.
Includes confidence loss values for foreground and background.
Note: The backgroud loss is calculated when the maximum iou of the box predicted
by the feature point and all GTs is less than the threshold.
(3)The loss of classes。
The category loss is BCE, which is the binary value of each class.
:param stride: The scale of the feature map relative to the original image
:return: The average loss(loss_giou, loss_conf, loss_cls) of all batches of this detection layer.
"""
BCE = nn.BCEWithLogitsLoss(reduction="none")
FOCAL = FocalLoss(gamma=2, alpha=1.0, reduction="none")
batch_size, grid = p.shape[:2]
img_size = stride * grid
p_conf = p[..., 4:5]
p_cls = p[..., 5:]
p_d_xywh = p_d[..., :4]
label_xywh = label[..., :4]
label_obj_mask = label[..., 4:5]
label_cls = label[..., 6:]
label_mix = label[..., 5:6]
# loss giou
giou = tools.GIOU_xywh_torch(p_d_xywh, label_xywh).unsqueeze(-1)
# The scaled weight of bbox is used to balance the impact of small objects and large objects on loss.
bbox_loss_scale = 2.0 - 1.0 * label_xywh[..., 2:3] * label_xywh[..., 3:4] / (img_size ** 2)
loss_giou = label_obj_mask * bbox_loss_scale * (1.0 - giou) * label_mix
# loss confidence
iou = tools.iou_xywh_torch(p_d_xywh.unsqueeze(4), bboxes.unsqueeze(1).unsqueeze(1).unsqueeze(1))
iou_max = iou.max(-1, keepdim=True)[0]
label_noobj_mask = (1.0 - label_obj_mask) * (iou_max < self.__iou_threshold_loss).float()
loss_conf = (label_obj_mask * FOCAL(input=p_conf, target=label_obj_mask) +
label_noobj_mask * FOCAL(input=p_conf, target=label_obj_mask)) * label_mix
# loss classes
loss_cls = label_obj_mask * BCE(input=p_cls, target=label_cls) * label_mix
loss_giou = (torch.sum(loss_giou)) / batch_size
loss_conf = (torch.sum(loss_conf)) / batch_size
loss_cls = (torch.sum(loss_cls)) / batch_size
loss = loss_giou + loss_conf + loss_cls
return loss, loss_giou, loss_conf, loss_cls
if __name__ == "__main__":
from model.yolov3 import Yolov3
net = Yolov3()
p, p_d = net(torch.rand(3, 3, 416, 416))
label_sbbox = torch.rand(3, 52, 52, 3, 26)
label_mbbox = torch.rand(3, 26, 26, 3, 26)
label_lbbox = torch.rand(3, 13, 13, 3, 26)
sbboxes = torch.rand(3, 150, 4)
mbboxes = torch.rand(3, 150, 4)
lbboxes = torch.rand(3, 150, 4)
loss, loss_xywh, loss_conf, loss_cls = YoloV3Loss(cfg.MODEL["ANCHORS"], cfg.MODEL["STRIDES"])(p, p_d, label_sbbox,
label_mbbox,
label_lbbox, sbboxes,
mbboxes, lbboxes)
print(loss)
参考连接
https://www.yuque.com/darrenzhang/cv/yolov3 https://blog.csdn.net/leviopku/article/details/82660381 https://blog.csdn.net/leviopku/article/details/82660381 https://blog.csdn.net/x454045816/article/details/107650430 https://cloud.tencent.com/developer/article/1588096 原文链接:https://blog.csdn.net/x454045816/article/details/107527326
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看