
重磅!一文深入深度学习模型压缩和加速
AI编辑:我是小将
本文作者:谢杨易
https://zhuanlan.zhihu.com/p/179945324
本文已由原作者授权,不得擅自二次转载
1 背景
近年来深度学习模型在计算机视觉、自然语言处理、搜索推荐广告等各种领域,不断刷新传统模型性能,并得到了广泛应用。随着移动端设备计算能力的不断提升,移动端AI落地也成为了可能。相比于服务端,移动端模型的优势有:
减轻服务端计算压力,并利用云端一体化实现负载均衡。特别是在双11等大促场景,服务端需要部署很多高性能机器,才能应对用户流量洪峰。平时用户访问又没那么集中,存在巨大的流量不均衡问题。直接将模型部署到移动端,并在置信度较高情况下直接返回结果,而不需要请求服务端,可以大大节省服务端计算资源。同时在大促期间降低置信度阈值,平时又调高,可以充分实现云端一体负载均衡。
实时性好,响应速度快。在feed流推荐和物体实时检测等场景,需要根据用户数据的变化,进行实时计算推理。如果是采用服务端方案,则响应速度得不到保障,且易造成请求过于密集的问题。利用端计算能力,则可以实现实时计算。
稳定性高,可靠性好。在断网或者弱网情况下,请求服务端会出现失败。而采用端计算,则不会出现这种情况。在无人车和自动驾驶等可靠性要求很高的场景下,这一点尤为关键,可以保证在隧道、山区等场景下仍能稳定运行。
安全性高,用户隐私保护好。由于直接在端上做推理,不需要将用户数据传输到服务端,免去了网络通信中用户隐私泄露风险,也规避了服务端隐私泄露问题
移动端部署深度学习模型也有很大的挑战。主要表现在,移动端等嵌入式设备,在计算能力、存储资源、电池电量等方面均是受限的。故移动端模型必须满足模型尺寸小、计算复杂度低、电池耗电量低、下发更新部署灵活等条件。因此模型压缩和加速就成为了目前移动端AI的一个热门话题。模型压缩和加速不仅仅可以提升移动端模型性能,在服务端也可以大大加快推理响应速度,并减少服务器资源消耗,大大降低成本。结合移动端AI模型和服务端模型,实现云端一体化,是目前越来越广泛采用的方案。模型压缩和加速是两个不同的话题,有时候压缩并不一定能带来加速的效果,有时候又是相辅相成的。压缩重点在于减少网络参数量,加速则侧重在降低计算复杂度、提升并行能力等。模型压缩和加速是一个很大的命题,可以从多个角度优化。总体来看,个人认为主要分为三个层次:
算法应用层压缩加速。这个维度主要在算法应用层,也是大多数算法工程师的工作范畴。主要包括结构优化(如矩阵分解、分组卷积、小卷积核等)、量化与定点化、模型剪枝、模型蒸馏等。
框架层加速。这个维度主要在算法框架层,比如tf-lite、NCNN、MNN等。主要包括编译优化、缓存优化、稀疏存储和计算、NEON指令应用、算子优化等
硬件层加速。这个维度主要在AI硬件芯片层,目前有GPU、FPGA、ASIC等多种方案,各种TPU、NPU就是ASIC这种方案,通过专门为深度学习进行芯片定制,大大加速模型运行速度。
2 算法层压缩加速
1.1 结构优化
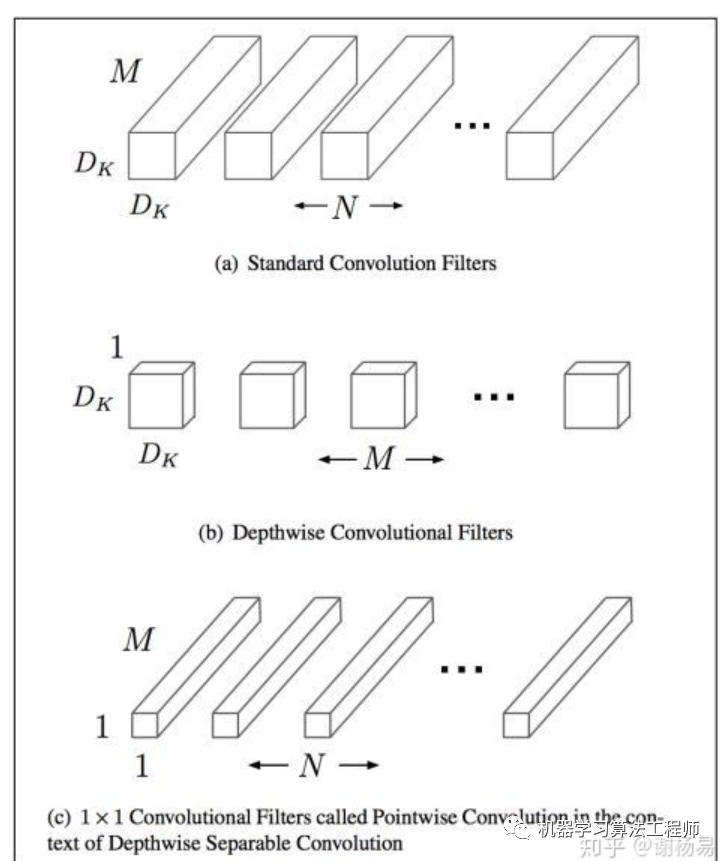
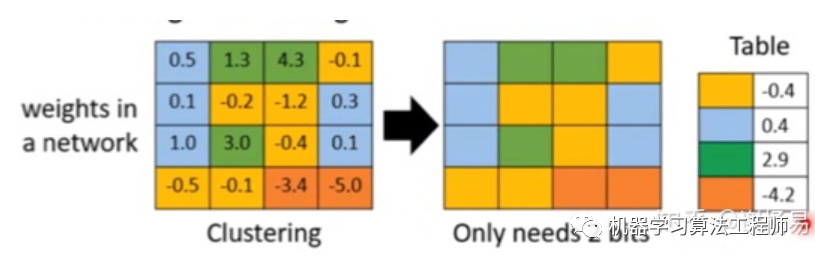
1.1.1 矩阵分解
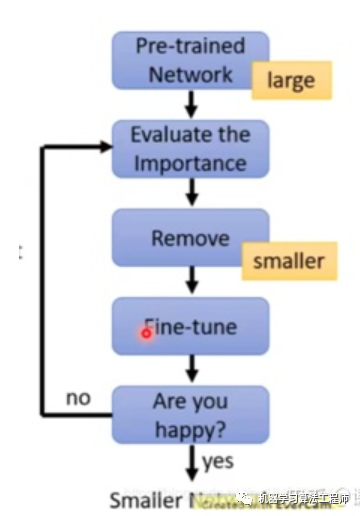
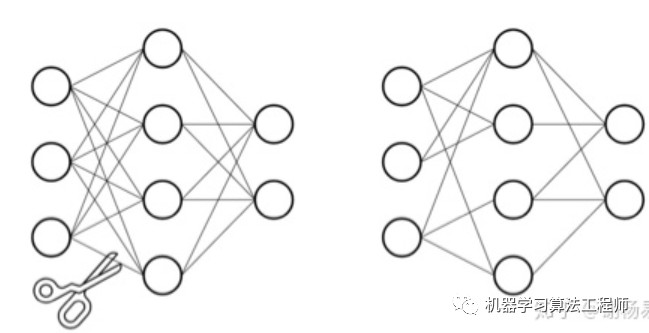
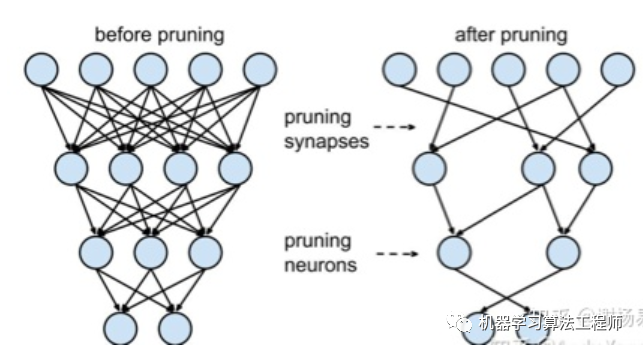
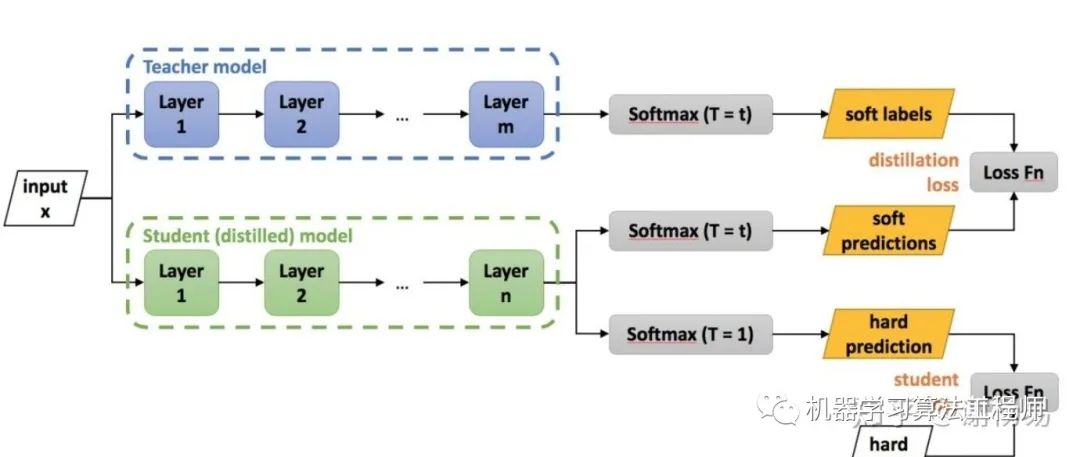
将M x N的矩阵分解为M x K + K x N,只要让K< 其中M为词表长度,也就是vocab_size,典型值为21128。N为隐层大小,典型值为1024,也就是hidden_size。K为我们设置的低维词嵌入空间,可以设置为128。 分解前:矩阵参数量为 (M * N) 分解后:参数量为 (MK + KN) 压缩量:(M * N) / (MK + KN), 由于M远大于N,故可近似为 N / k, 当N=2014,k=128时,可以压缩8倍 相对于DNN全连接参数量过大的问题,CNN提出了局部感受野和权值共享的概念。在NLP中同样也有类似应用的场景。比如ALBert中,12层共用同一套参数,包括multi-head self attention和feed-forward,从而使得参数量降低到原来的1/12。这个方案对于模型压缩作用很大,但对于推理加速则收效甚微。因为共享权值并没有带来计算量的减少。 在视觉模型中应用较为广泛,比如shuffleNet,mobileNet等。我们以mobileNet为例。对于常规的M输入通道,N输出通道,dk x dk的kernel size的卷积,需要参数量为 M x N x dk x dk。这是因为每个输入通道,都会抽取N种特征(对应输出通道数),不同的输入通道需要不同的kernel来做抽取,然后叠加起来。故M个输入通道,N个输出通道,就需要M x N个kernel了。mobileNet对常规卷积做了优化,每个输入通道,仅需要一个kernel做特征提取,这叫做depth wise。如此M个通道可得到M个feature map。但我们想要的是N通道输出,怎么办呢?mobileNet采用一个常规1 x 1卷积来处理这个连接,从而转化到N个输出通道上。总结下来,mobileNet利用一个dk x dk的depth wise卷积和一个1 x 1的point wise卷积来实现一个常规卷积。 分组前:参数量 (M x N x dk x dk) 分组后:参数量 (M x dk x dk + M x N x 1 x 1) 压缩量:(M x dk x dk + M x N x 1 x 1) / (M x N x dk x dk), 近似为 1/(dk x dk)。dk的常见值为3,也就是3*3卷积,故可缩小约9倍 如下图所示 使用两个串联小卷积核来代替一个大卷积核。inceptionV2中创造性的提出了两个3x3的卷积核代替一个5x5的卷积核。在效果相同的情况下,参数量仅为原先的3x3x2 / 5x5 = 18/25 使用两个并联的非对称卷积核来代替一个正常卷积核。inceptionV3中将一个7x7的卷积拆分成了一个1x7和一个7x1, 卷积效果相同的情况下,大大减少了参数量,同时还提高了卷积的多样性。 全局平均池化代替全连接层。这个才是大杀器!AlexNet和VGGNet中,全连接层几乎占据了90%的参数量。inceptionV1创造性的使用全局平均池化来代替最后的全连接层,使得其在网络结构更深的情况下(22层,AlexNet仅8层),参数量只有500万,仅为AlexNet的1/12 1x1卷积核的使用。1x1的卷积核可以说是性价比最高的卷积了,没有之一。它在参数量为1的情况下,同样能够提供线性变换,relu激活,输入输出channel变换等功能。VGGNet创造性的提出了1x1的卷积核 使用小卷积核来代替大卷积核。VGGNet全部使用3x3的小卷积核,来代替AlexNet中11x11和5x5等大卷积核。小卷积核虽然参数量较少,但也会带来特征面积捕获过小的问题。inception net认为越往后的卷积层,应该捕获更多更高阶的抽象特征。因此它在靠后的卷积层中使用的5x5等大面积的卷积核的比率较高,而在前面几层卷积中,更多使用的是1x1和3x3的卷积核。 深度学习模型参数通常是32bit浮点型,我们能否使用16bit,8bit,甚至1bit来存储呢?答案是肯定的。常见的做法是保存模型每一层时,利用低精度来保存每一个网络参数,同时保存拉伸比例scale和零值对应的浮点数zero_point。推理阶段,利用如下公式来网络参数还原为32bit浮点: 一种实现伪量化的方案是,利用k-means等聚类算法,步骤如下: 将大小相近的参数聚在一起,分为一类。 每一类计算参数的平均值,作为它们量化后对应的值。 每一类参数存储时,只存储它们的聚类索引。索引和真实值(也就是类内平均值)保存在另外一张表中 推理时,利用索引和映射表,恢复为真实值。 过程如下图 从上可见,当只需要4个类时,我们仅需要2bit就可以实现每个参数的存储了,压缩量达到16倍。推理时通过查找表恢复为浮点值,精度损失可控。结合霍夫曼编码,可进一步优化存储空间。一般来说,当聚类数为N时,我们压缩量为 log(N))] / 32 与伪量化不同的是,定点化在推理时,不需要还原为浮点数。这需要框架实现算子的定点化运算支持。目前MNN、XNN等移动端AI框架中,均加入了定点化支持。 剪枝归纳起来就是取其精华去其糟粕。按照剪枝粒度可分为突触剪枝、神经元剪枝、权重矩阵剪枝等。总体思想是,将权重矩阵中不重要的参数设置为0,结合稀疏矩阵来进行存储和计算。通常为了保证performance,需要一小步一小步地进行迭代剪枝。步子大了,容易那个啥的,大家都懂的哈。常见迭代剪枝流程如下图所示 训练一个performance较好的大模型 评估模型中参数的重要性。常用的评估方法是,越接近0的参数越不重要。当然还有其他一些评估方法,这一块也是目前剪枝研究的热点 将不重要的参数去掉,或者说是设置为0。之后可以通过稀疏矩阵进行存储。比如只存储非零元素的index和value 训练集上微调,从而使得由于去掉了部分参数导致的performance下降能够尽量调整回来 验证模型大小和performance是否达到了预期,如果没有,则继续迭代进行。 突触剪枝剪掉神经元之间的不重要的连接。对应到权重矩阵中,相当于将某个参数设置为0。常见的做法是,按照数值大小对参数进行排序,将大小排名最后的k%置零即可,k%为压缩率。如下图 神经元剪枝则直接将某个节点直接去掉。对应到权重矩阵中,相当于某一行和某一列置零。常见做法是,计算神经元对应的一行和一列参数的平方和的根,对神经元进行重要性排序,将大小排名最后的k%置零。如下图 除了将权重矩阵中某些零散的参数,或者整行整列去掉外,我们能否将整个权重矩阵去掉呢?答案是肯定的,目前也有很多这方面的研究。NeurIPS 2019有篇文章 深入分析了BERT多头机制中每个头到底有多大用,结果发现很多头其实没啥卵用。他在要去掉的head上,加入mask,来做每个头的重要性分析。作者先分析了单独去掉每层每个头,WMT任务上bleu的改变。发现,大多数head去掉后,对整体影响不大。如下图所示 然后作者分析了,每层只保留一个最重要的head后,ACC的变化。可见很多层只保留一个head,performance影响不大。如下图所示 由此可见,直接进行权重矩阵剪枝,也是可行的方案。相比突触剪枝和神经元剪枝,压缩率要大很多。 蒸馏本质是student对teacher的拟合,从teacher中汲取养分,学到知识,不仅仅可以用到模型压缩和加速中。蒸馏常见流程如下图所示 老师和学生可以是不同的网络结构,比如BERT蒸馏到BiLSTM网络。但一般相似网络结构,蒸馏效果会更好。 总体loss为 soft_label_loss + hard_label_loss。soft_label_loss可以用KL散度或MSE拟合 soft label为teacher模型的要拟合的对象。可以是predic输出,也可以是embeddings, 或者hidden layer和attention分布。 针对软标签的定义,蒸馏的方案也是百花齐放,下面分享两篇个人认为非常经典的文章。 distillBERT由大名鼎鼎的HuggingFace出品。主要创新点为: Teacher 12层,student 6层,每两层去掉一层。比如student第二层对应teacher第三层 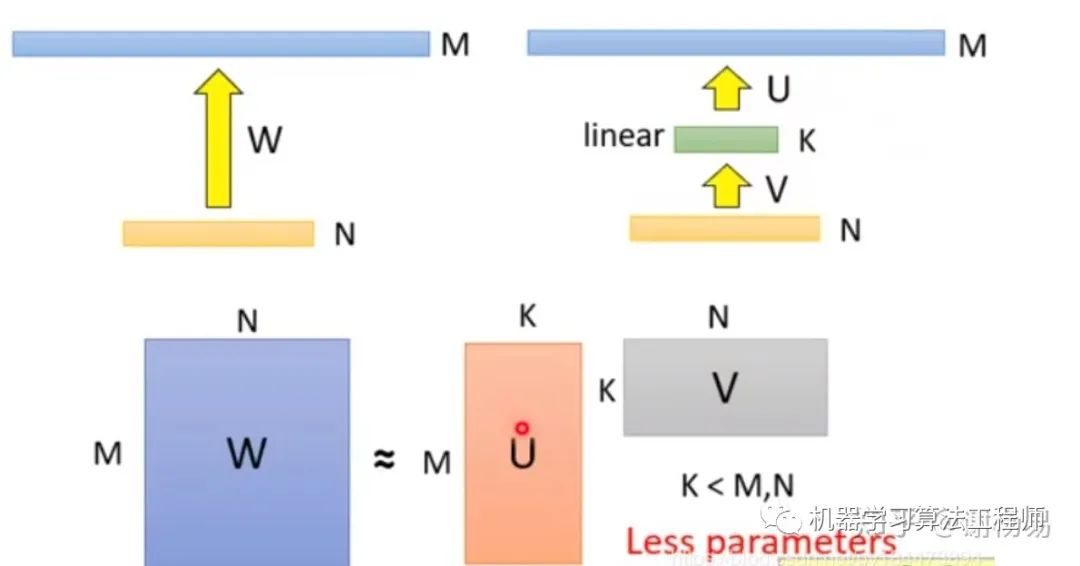
1.1.2 权值共享
1.1.3 分组卷积
1.1.4 分解卷积
1.1.5 其他
1.2 量化
1.2.1 伪量化
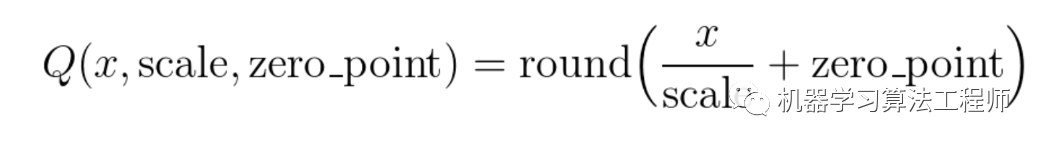
1.2.2 聚类与伪量化
1.2.3 定点化
1.3 剪枝
1.3.1 剪枝流程
1.3.2 突触剪枝

1.3.3 神经元剪枝

1.3.4 权重矩阵剪枝


1.4 蒸馏
1.4.1 蒸馏流程
1.4.2 distillBERT
DistilBERT 比 BERT 快 60%,体积比 BERT 小 60%。在glue任务上,保留了 95% 以上的性能。在performance损失很小的情况下,带来了较大的模型压缩和加速效果。

1.4.3 tinyBERT
总体结构
重点来看下tinyBERT,它是由华为出品,非常值得深入研究。tinyBERT对embedding层,transformer层(包括hidden layer和attention),prediction层均进行了拟合。如下图
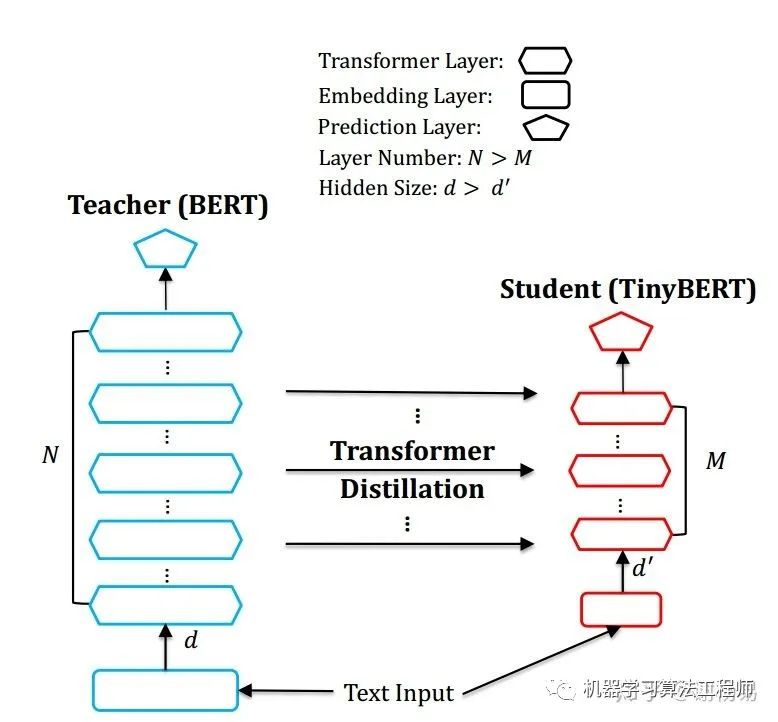
其中Embeddings采用MSE, Prediction采用KL散度, Transformer层的hidden layer和attention,均采用MSE。loss如下
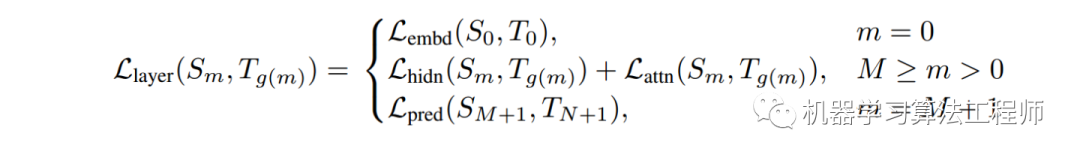
其中m为层数。
效果分析
表2: glue任务上的performance。在glue任务上,可达到bert-base的96%,几乎无损失。表3: tinyBERT模型大小和推理速度。缩小7.5倍,加速9.4倍。压缩和加速效果十分明显。
消融分析
表6:分析embedding、prediction、attention、hidden layer软标签作用,其中attention和hidden layer作用最大。这个也很好理解,transformer层本来就是整个BERT中最关键的部分。

表7:分析老师学生不同层对应方法的效果,uniform为隔层对应,top为全部对应老师顶部几层,bottom为全部对应老师底部几层。Uniform效果明显好很多。这个也很好理解,浅层可以捕捉低阶特征,深层可以捕捉高阶特征。全是低阶或者高阶显然不合适,我们要尽量荤素搭配。
3 框架层加速
3.1 手机端AI能力
目前移动端AI框架也比较多,包括谷歌的tf-lite,腾讯的NCNN,阿里的MNN,百度的PaddleLite, 小米的MACE等。他们都不同程度的进行了模型压缩和加速的支持。特别是端上推理的加速。 手机端AI性能排名
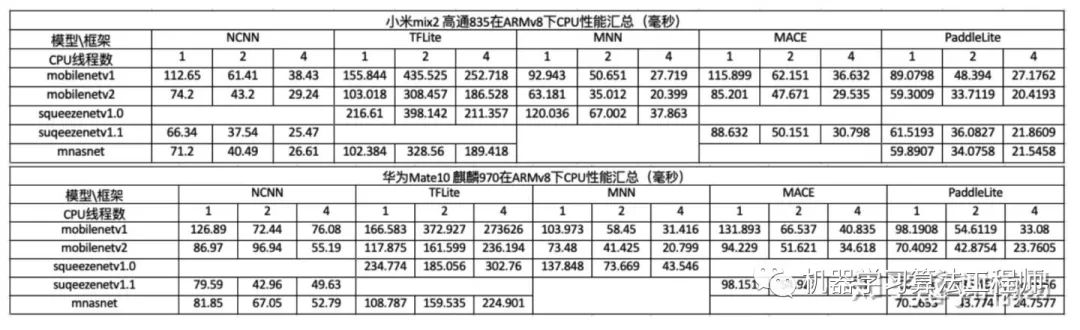
3.2 端侧AI框架加速优化方法
个人总结的主要方法如下,可能有遗漏哈,各位看官请轻拍
基于基本的C++编译器优化
打开编译器的优化选项,选择O2等加速选项
小函数内联,概率大分支优先,避免除法,查表空间换时间,函数参数不超过4个等
利用C,而不是C++,C++有不少冗余的东西
缓存优化
小块内存反复使用,提升cache命中率,尽量减少内存申请。比如上一层计算完后,接着用作下一层计算
连续访问,内存连续访问有利于一次同时取数,相近位置cache命中概率更高。比如纵向访问数组时,可以考虑转置后变为横向访问
对齐访问,比如224 x 224的尺寸,补齐为256 x 224,从而提高缓存命中率
缓存预取,CPU计算的时候,preload后面的数据到cache中
多线程
为循环分配线程
动态调度,某个子循环过慢的时候,调度一部分循环到其他线程中
稀疏化
稀疏索引和存储方案,采用eigen的sparseMatrix方案
内存复用和提前申请
扫描整个网络,计算每层网络内存复用的情况下,最低的内存消耗。推理刚开始的时候就提前申请好。避免推理过程中反复申请和释放内存,避免推理过程中因为内存不足而失败,复用提升内存访问效率和cache命中率
ARM NEON指令的使用,和ARM的深度融合。NEON可以单指令多取值(SIMD),感兴趣可针对学习,这一块水也很深。
手工汇编,毕竟机器编译出来的代码还是有不少冗余的。可以针对运行频次特别高的代码进行手工汇编优化。当然如果你汇编功底惊天地泣鬼神的强,也可以全方位手工汇编。
算子支持:比如支持GPU加速,支持定点化等。有时候需要重新开发端侧的算子。
4 硬件层加速
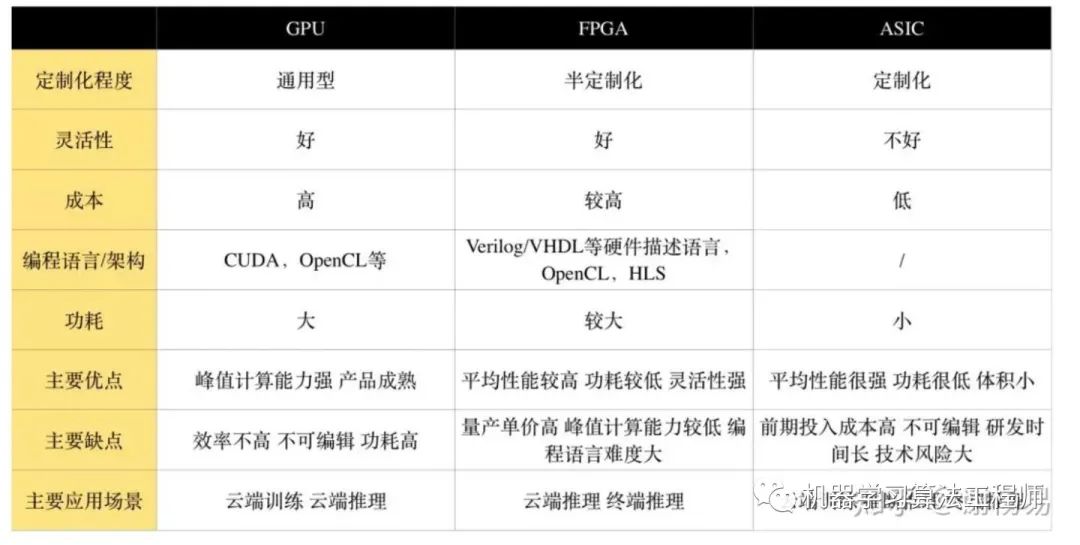
硬件层加速小编就连半瓢水都达不到了,为了保证整个方案的全面性,还是硬着头皮东施效颦下。目前AI芯片厂家也是百花齐放,谁都想插一脚,不少互联网公司也来赶集。如下图所示

AI 芯片目前三种方案。GPU目前被英伟达和AMD牢牢把控。ASIC目前最火,TPU、NPU等属于ASIC范畴。
推荐阅读
Python编程神器Jupyter Notebook使用的28个秘诀
机器学习算法工程师
一个用心的公众号
