
DDD 领域驱动设计:解析业务领域的奥秘
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:juejin.cn/post/7252860409613942842
推荐:https://t.zsxq.com/11yPfGLPK
自律才能自由
引言
软件开发中的挑战和问题
-
复杂性管理:当处理复杂业务需求时,软件系统往往变得复杂,难以理解和维护。不清晰的业务逻辑和模型使开发人员难以捕捉并准确地实现业务需求。
-
领域专家与开发人员之间的沟通障碍:业务专家负责提供业务需求和知识,而开发人员负责将这些需求转化为可执行的软件系统。然而,由于不同的专业背景和术语之间的差异,很难进行有效的沟通,造成开发过程中的误解和偏差。
-
数据库驱动设计的局限性:在传统的软件开发中,往往将数据库设计作为业务逻辑的中心。这导致了紧密耦合的数据模型和业务逻辑,使系统变得脆弱且难以修改和扩展。
-
难以应对变化:在现实世界中,业务需求会不断变化和演化。然而,传统的软件开发方法往往缺乏灵活性,难以适应这种变化。系统修改和扩展常常会引入错误和破坏现有的结构。
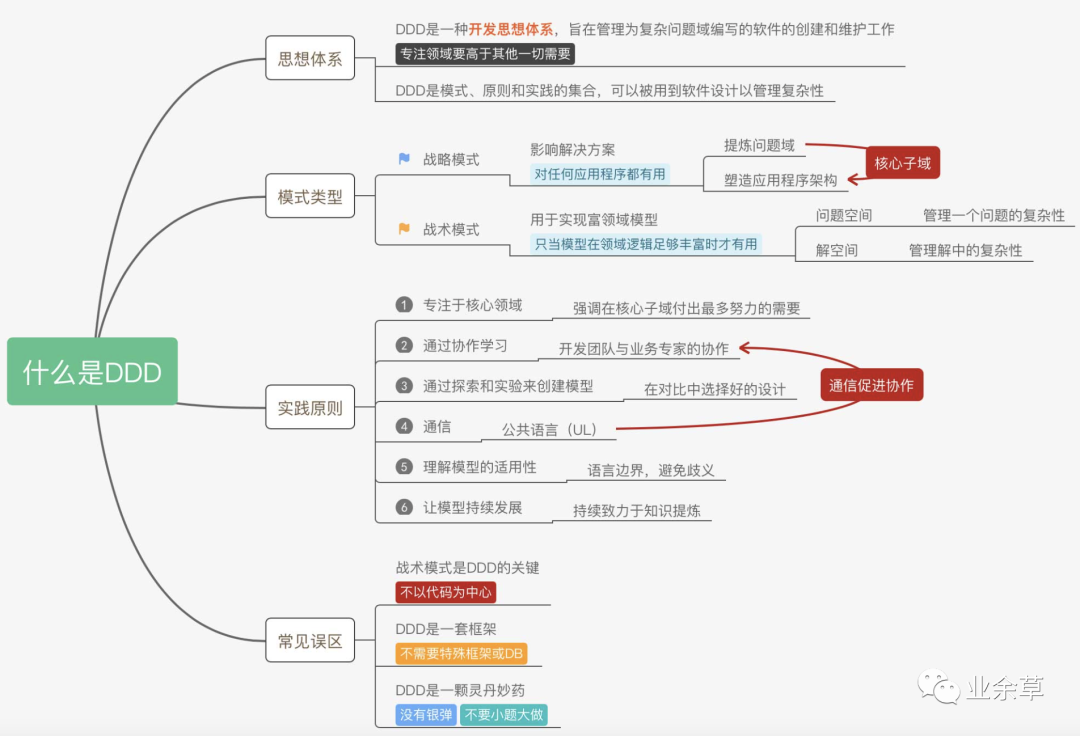
DDD 架构的定义和目标
当谈到领域驱动设计(Domain-Driven Design,DDD)架构时,它是一种软件设计方法,旨在帮助开发人员更好地理解和解决复杂业务领域的挑战。DDD 架构的目标是将软件设计与实际业务需求紧密结合,通过明确的领域模型和业务概念来支持系统的开发和演化。
-
定义: 领域驱动设计是一种基于领域模型的软件设计和开发方法,强调将软件设计与业务领域的实际需求相结合。它提供了一组原则、模式和工具,帮助团队更好地理解业务领域、捕捉业务知识,并以清晰的方式将其映射到软件系统中。
-
目标:
-
解决复杂性:DDD 通过将业务领域划分为明确的模块和概念,帮助开发人员处理复杂性。它鼓励建立一个明确的、可靠的领域模型,帮助开发人员更好地理解和应对业务领域的挑战,从而简化开发过程。
-
清晰的业务模型:DDD 强调提取和表达业务知识,并将其映射到软件系统中的领域模型。通过建立一个明确的、统一的领域模型,团队成员可以共享对业务概念和规则的理解,促进更好的沟通和对业务需求的一致性理解。
-
高度可维护性:DDD 倡导使用清晰的领域模型来构建软件系统,这有助于提高系统的可维护性。通过将业务逻辑和状态封装在领域对象中,并使用聚合根等DDD模式,可以简化代码结构,降低耦合性,从而使系统更易于修改和扩展。
-
迭代开发和增量交付:DDD 鼓励采用增量开发和敏捷方法,通过迭代方式逐步完善和验证领域模型。它强调与领域专家密切合作,通过快速迭代的方式逐步演化系统,以满足不断变化的业务需求。
-
技术和业务的融合:DDD 鼓励技术人员和业务专家之间的紧密合作,通过共同理解和共享语言来构建一个有效的领域模型。它试图消除技术术语和业务术语之间的隔阂,促进团队之间的有效沟通和协作。
通过遵循 DDD 架构的原则和模式,开发人员可以更好地理解和解决复杂业务需求,构建可维护、高度设计的软件系统,并与业务专家进行更紧密的合作。这种方法有助于确保软件系统与实际业务需求的一致性,提高开发效率并最大程度地满足用户需求。
DDD 架构的重要性和应用场景
DDD(领域驱动设计)架构的重要性在于它提供了一种将软件系统的复杂业务逻辑与技术实现相结合的方法。它强调以领域模型为核心,通过深入理解和准确映射业务领域,来解决传统开发中的一些常见问题,提高软件系统的可维护性、可扩展性和灵活性。
以下是 DDD 架构的重要性和应用场景的详细介绍:
-
业务复杂性管理:软件系统往往涉及复杂的业务需求和逻辑。DDD 提供了一种将复杂业务逻辑进行建模和组织的方法,通过领域模型的概念和规则,使开发人员能够更好地理解和处理复杂性,降低系统的认知负担。
-
高效的沟通和协作:DDD 强调业务专家与开发人员之间的紧密合作。通过共同创建和维护领域模型,业务专家能够更有效地表达需求和规则,开发人员可以更准确地理解和实现这些需求。这种良好的沟通和协作有助于减少开发过程中的误解和偏差,提高开发效率和质量。
-
高内聚、低耦合的模块化设计:DDD 通过将软件系统划分为多个领域模型和限界上下文,强调模块化和边界的概念。每个模块都有自己的职责和规则,模块之间通过清晰的接口进行交互,从而实现高内聚、低耦合的设计。这种模块化的设计使系统更易于理解、修改和扩展,提高了系统的可维护性和灵活性。
-
支持变化和演化:DDD 提倡对业务需求的变化持开放态度,并提供了适应变化的方法。通过领域模型的概念,DDD 强调将业务逻辑和规则封装在模型中,使其更易于修改和演化。当业务需求发生变化时,可以通过调整模型而不是整个系统来适应变化,减少对系统的影响。
-
提高软件质量:DDD 强调关注业务领域本身而非技术细节,帮助开发人员更好地理解业务需求。通过准确映射业务领域,可以更容易地验证系统的正确性和完整性。同时,DDD 还鼓励使用领域驱动测试来验证领域模型的行为,确保系统按照预期工作。
在实际应用中,DDD 适用于以下场景:
-
复杂业务系统:当开发的软件系统涉及复杂的业务需求和逻辑时,DDD 可以帮助将这些复杂性进行合理组织和管理。
-
长期维护和演化:当软件系统需要长期维护和演化时,DDD 的模块化设计和适应变化的特性能够降低修改和扩展的风险。
-
多团队协作:当多个团队同时开发一个大型软件系统时,DDD 提供了明确的边界和接口定义,有助于不同团队之间的协作和集成。
-
高度可定制的业务需求:当业务需求需要高度定制化和个性化时,DDD 的领域模型可以准确表达特定的业务规则和行为。
DDD 架构的核心概念
领域模型和领域对象的概念
领域模型和领域对象是领域驱动设计(DDD)中的两个核心概念,它们在软件开发中起着重要的作用。
-
领域模型(Domain Model): 领域模型是对业务领域的抽象和建模,它描述了业务中的概念、规则和关系。领域模型是对现实世界的业务问题进行抽象的结果,它反映了业务专家对领域的理解,并将其表达为软件系统中的对象和逻辑。领域模型通常由实体(Entities)、值对象(Value Objects)、聚合(Aggregates)、服务(Services)等组成。
领域模型的设计旨在准确地反映业务领域的本质特征,并将其与技术实现相分离。通过领域模型,开发人员能够更好地理解业务需求、规则和流程,提供一种共享的语言,促进开发团队与业务专家之间的沟通与协作。
-
领域对象(Domain Object): 领域对象是领域模型中的具体实体,代表了业务领域中的一个概念或实体。它是领域模型中的核心元素,包含了数据和行为,并且具有业务规则和约束。领域对象通常具有唯一的标识,并通过标识来进行区分和操作。
领域对象不仅包含了数据的状态,还具有对这些数据进行操作和处理的方法。它封装了业务行为和逻辑,实现了业务规则的验证和执行。领域对象的设计应该注重领域的本质特征,准确表达业务需求,并通过方法的行为来保护和维护其内部数据的完整性和一致性。
领域对象在领域模型中相互交互和协作,通过消息传递和调用方法来实现业务流程和功能。它们可以形成聚合,建立关联关系,参与业务规则的执行和数据的变更。
聚合根和实体的定义和作用
在领域驱动设计(DDD)中,聚合根(Aggregate Root)和实体(Entity)是用于建模领域模型的重要概念,它们具有不同的定义和作用。
-
聚合根(Aggregate Root): 聚合根是领域模型中的一个重要概念,它是一组相关对象的根节点,代表了一个整体的概念或实体。聚合根负责维护聚合内部的一致性和完整性,并提供对聚合内部对象的访问和操作。
聚合根通过封装内部的实体、值对象和关联关系,形成一个边界,它定义了聚合的边界和访问规则。聚合根通常具有全局唯一的标识,可以通过该标识来标识和访问整个聚合。聚合根作为聚合的入口点,通过公开的方法来处理聚合内部的业务逻辑和行为。
聚合根在领域模型中扮演着重要的角色,它具有以下作用:
-
约束整个聚合的一致性和完整性 -
提供对聚合内部对象的访问和操作 -
封装聚合内部的复杂关联关系和业务规则 -
作为聚合的接口,与外部系统进行交互 -
实体(Entity): 实体是领域模型中具体的对象,代表了业务领域中的一个具体概念或实体。实体具有唯一的标识,并且在整个系统中可以通过该标识进行识别和访问。实体包含了数据和行为,并且具有业务规则和行为。
实体通常属于某个聚合,并且在聚合内部起到具体的角色。实体可以直接参与业务规则的验证和执行,它负责维护自身的状态和行为,并与其他实体进行交互。实体可以有自己的属性和方法,并且可以通过消息传递和调用方法来实现与其他实体的协作和交互。
实体在领域模型中扮演着以下作用:
-
表示业务领域中的具体概念和对象 -
维护自身的状态和行为 -
参与聚合内部的业务规则的执行和数据的变更 -
与其他实体进行交互和协作
总结起来,聚合根是领域模型中一组相关对象的根节点,它负责维护整个聚合的一致性和完整性;而实体是具体的业务概念和对象,代表了聚合内部的一个具体实例,它负责维护自身的状态和行为,并与其他实体进行交互。聚合根和实体在领域模型中具有不同的定义和作用,它们协同工作,构建出强大而灵活的领域模型,提供了一种可靠的方法来处理复杂的业务需求。
值对象和服务的概念
-
值对象(Value Object): 值对象是指在领域模型中用来表示某种特定值或属性的对象,它没有唯一的标识符,通过其属性值来区分不同的对象。值对象通常被用于聚合内部,作为实体的属性或者组成聚合根的一部分。
值对象具有以下特点:
值对象的作用:
-
封装重复的属性,提高代码可读性和可维护性。 -
提供了一种更加表达领域概念的方式,增强了代码的语义性。 -
作为实体的属性,帮助实体建立复杂的关联关系。 -
支持领域行为的建模和封装。 -
不可变性:值对象的属性值在创建后不可改变,任何修改都应该创建一个新的值对象。 -
相等性:值对象的相等性根据其属性值来决定,相同属性值的值对象被认为是相等的。 -
无副作用:值对象的行为不会产生副作用,对其的操作不会改变系统的状态。 -
服务(Service): 服务是领域模型中的一种行为抽象,它表示一组操作或行为的集合,通常与领域对象无关。服务可以是无状态的,也可以是有状态的,它们通过接口或者静态方法来提供服务。
服务具有以下特点:
服务的作用:
-
处理复杂的领域操作,协调多个实体或值对象之间的交互。 -
提供领域无关的功能,例如验证、计算等。 -
支持领域模型的完整性和一致性。 -
封装行为:服务封装了一组操作或者行为,在方法级别上对领域操作进行了组织和归纳。 -
强调整合:服务跨越多个领域对象,协调它们之间的交互,促进领域模型的整体性和一致性。 -
面向操作:服务的主要目的是执行某个操作,并且不保留任何状态。
DDD 架构中的分层思想
分层架构的概述和好处
领域驱动设计(Domain-Driven Design,DDD)分层架构是一种常用于构建复杂软件系统的架构风格。它将系统划分为多个层次,每个层次都有特定的职责和关注点,以实现高内聚低耦合的目标。
-
概述: DDD分层架构基于单一职责原则(Single Responsibility Principle)和依赖倒置原则(Dependency Inversion Principle)构建,提供了一种将业务逻辑、领域模型和基础架构等不同关注点进行分离的方式。
通常,DDD分层架构由以下几个层次组成:
-
用户界面层(User Interface Layer):负责与用户交互,展现系统的用户界面,接收用户输入和显示输出。 -
应用层(Application Layer):协调用户界面和领域层之间的交互,处理用户请求,调用领域服务和领域对象来完成业务逻辑。 -
领域层(Domain Layer):包含领域模型、实体、值对象等,负责实现业务规则和行为,封装核心的业务逻辑。 -
基础架构层(Infrastructure Layer):提供与基础设施相关的支持,包括数据库访问、消息队列、日志等。 -
好处: DDD分层架构带来了以下好处:
-
高内聚低耦合:通过将不同关注点分离到不同层中,实现了高内聚和低耦合。每个层次都有明确的职责,可以更容易理解和维护。 -
可测试性:每个层次可以独立测试,因为它们的职责清晰,依赖关系明确。这样可以更容易编写单元测试和集成测试,提高代码质量。 -
可扩展性:由于各层之间的松散耦合,当需要添加新功能或修改现有功能时,只需修改特定的层次,而无需影响其他层次。 -
可维护性:DDD分层架构使得系统的各个部分有明确的职责和边界,降低了代码的复杂性,提高了代码的可读性和可维护性。 -
模块化开发:不同层次之间的分离使得开发团队可以更好地并行工作,各自专注于自己的任务,提高开发效率。
要注意的是,DDD分层架构并不是一成不变的,具体的架构设计可能因系统规模、团队结构和业务需求等因素而有所调整。重要的是理解各层次的职责和关注点,并保持良好的代码组织和架构设计原则,以实现可维护、可扩展的软件系统。
领域层、应用层和基础设施层的职责和关系
-
领域层:
-
实现业务领域的概念和规则。 -
封装核心的业务逻辑。 -
管理领域对象之间的关系和交互。 -
保证数据的一致性和有效性。 -
职责:领域层是整个系统的核心,负责实现业务规则和逻辑。它包含了领域模型、实体、值对象、聚合根等概念。领域层主要完成以下职责: -
关系:领域层通常不依赖于其他层,并且其他层也不应该直接依赖于领域层。它通过定义接口或领域服务的方式暴露给应用层,应用层可以调用领域层的接口或服务来处理业务逻辑。 -
应用层:
-
接收和验证用户输入。 -
转化用户请求为领域对象的操作。 -
协调多个领域对象之间的交互和协作。 -
调用领域服务来完成复杂的业务操作。 -
职责:应用层作为领域层和用户界面层之间的协调者,负责处理用户请求、协调领域对象和领域服务来完成业务逻辑。应用层主要完成以下职责: -
关系:应用层依赖于领域层,通过调用领域层中的接口或领域服务来实现业务逻辑。它还可以调用基础设施层提供的服务来处理与外部系统的交互。 -
基础设施层:
-
与外部系统进行通信和交互。 -
提供数据持久化的支持,例如数据库访问、ORM等。 -
实现与基础设施相关的技术细节,例如日志记录、缓存管理等。 -
职责:基础设施层提供与基础设施相关的支持,包括数据库访问、消息队列、外部API调用、缓存、日志等功能。基础设施层主要完成以下职责: -
关系:基础设施层依赖于应用层和领域层,它为这些层提供必要的支持和服务。例如,领域层和应用层可以通过基础设施层访问数据库、记录日志或发送消息。
总体而言,领域层关注业务逻辑和规则,应用层协调业务逻辑的执行,基础设施层提供系统级的技术支持。它们之间的关系是领域层不依赖其他层,应用层依赖领域层,基础设施层提供支持给应用层和领域层。
领域事件和领域服务的使用
-
领域事件:
-
触发其他领域对象的行为或状态变化。 -
提供领域对象之间的解耦,使得系统更加灵活和可扩展。 -
记录和跟踪系统的状态变化,以满足审计需求。 -
与外部系统进行异步通信,例如发布消息给消息队列。 -
定义:领域事件是指在领域模型中发生的具有业务意义的、可追溯的事情或状态变化。它通常表示系统中重要的业务行为或关键的业务状态转换。 -
使用场景:使用领域事件可以捕捉和记录领域模型中的重要业务行为,以便在该事件发生后执行相应的业务逻辑。一些常见的使用场景包括: -
实现方式:领域事件通常由领域对象产生并发布,可以使用观察者模式或发布-订阅模式进行订阅和处理。在事件发布时,应用层或基础设施层可以监听并执行相应的业务逻辑。 -
领域服务:
-
处理涉及多个领域对象的复杂业务逻辑。 -
跨聚合根或子域执行事务性操作。 -
与外部系统进行交互或集成。 -
定义:领域服务是指在领域模型中提供的一种操作或功能,它不属于任何特定的领域对象,而是用于协调多个领域对象之间的交互和实现复杂的业务逻辑。 -
使用场景:使用领域服务可以处理那些涉及多个领域对象或需要跨领域边界的业务操作。一些常见的使用场景包括: -
实现方式:领域服务通常被定义为领域模型中的一个接口或抽象类,并由具体的实现类来提供具体的操作。在应用层中,可以通过调用领域服务的方法来执行相应的业务逻辑。
DDD 架构中的设计原则和模式
通用领域设计原则的介绍
-
领域模型贫血 VS 充血模型:
-
领域模型贫血(Anemic Domain Model)是指将业务逻辑主要放在服务对象中,而领域对象(实体、值对象等)则只具备数据和基本操作,缺乏自身的行为。这种模型会导致业务逻辑分散和难以维护。 -
充血模型(Rich Domain Model)是指将业务逻辑尽可能地放在领域对象中,使其具备自身的行为和状态。这种模型可以更好地保护业务规则,提高内聚性和可维护性。 -
聚合根:
-
聚合根(Aggregate Root)是领域模型的核心,它是一组具有内聚性的相关对象的根实体。聚合根负责维护整个聚合内的一致性和业务规则。 -
通过定义聚合根,可以避免直接操作聚合内的对象,而是通过聚合根进行操作,确保聚合的完整性、一致性和封装性。 -
领域事件驱动:
-
领域事件(Domain Event)是领域模型中重要的业务行为或状态变化的表示。通过使用领域事件,可以实现领域对象之间的解耦和松散耦合。 -
领域事件的发生可以触发其他领域对象的行为或状态变化,实现业务流程的演进和响应。 -
值对象:
-
值对象(Value Object)是指没有唯一标识、不可变且没有生命周期的对象。它们通常用来表示领域中的某个值或属性,并且可以作为实体的属性或参数。 -
值对象应该通过封装自身的状态来保证数据的一致性和完整性,提供相等性判断和对外不可变等特性。 -
领域服务:
-
领域服务(Domain Service)是指不属于任何特定的领域对象,而是用于解决跨多个领域对象的复杂业务逻辑的操作或功能。 -
领域服务可以协调多个领域对象之间的交互,处理复杂的业务规则和操作,并实现领域模型中无法被单个领域对象所包含的业务。
实体-值对象模式的使用
DDD(领域驱动设计)中的实体-值对象模式是一种常用的领域建模技术,用于表示和处理领域中的实体和值对象。
-
实体(Entity):
-
实体是具有唯一标识的具体领域对象,它具有生命周期、可以拥有状态和行为,并且可以与其他实体进行交互。 -
实体通过标识属性来区分不同的对象,并且可以根据业务规则进行状态变化和行为操作。 -
实体通常具有持久性,需要被保存到数据库或其他存储介质中。 -
值对象(Value Object):
-
值对象是用于描述某个特定概念的不可变对象,没有唯一标识和生命周期,仅仅通过其属性值来区分不同的对象。 -
值对象重点关注其属性的语义,而不是标识,因此通常具有更精简的行为,只包含基本的访问方法。 -
值对象一般不具有持久性,也不需要被单独保存到数据库中,它通常作为实体的组成部分存在。
在使用实体-值对象模式时,以下是一些常见的注意事项和使用方式:
-
实体的特点和使用:
-
实体应该具有唯一标识,通过标识来区分不同的对象。 -
实体的行为和状态应该与其标识关联,尽可能在实体内部处理业务规则和状态变化。 -
实体之间可以通过引用和关联进行交互。 -
值对象的特点和使用:
-
值对象没有唯一标识,仅通过其属性值来区分不同的对象。 -
值对象应该是不可变的,即创建后不可修改其属性值。 -
值对象可以作为实体的属性或参数来使用,用于描述实体的某个特定概念。 -
实体和值对象的区别和选择:
-
实体是具有生命周期和标识的,适合表示具有独立生命周期和状态变化的对象。 -
值对象是没有生命周期和标识的,适合表示不可变的、相对简单的概念。 -
在建模过程中,根据具体的业务需求和概念的本质,选择合适的实体或值对象来表示。 -
实体和值对象的关系:
-
实体可以包含值对象作为其属性,用于描述实体的某些属性或特征。 -
实体和值对象之间可以存在聚合关系,即实体可以作为聚合根,拥有一组相关的实体和值对象。
DDD实体和值对象示例
以下是一个简单的Java代码示例,展示了实体和值对象的使用:
// 实体 - User
public class User {
private UUID id;
private String username;
private String password;
public User(UUID id, String username, String password) {
this.id = id;
this.username = username;
this.password = password;
}
// Getters and setters
// ...
public boolean isValidPassword(String inputPassword) {
return this.password.equals(inputPassword);
}
}
// 值对象 - Address
public class Address {
private String street;
private String city;
private String country;
public Address(String street, String city, String country) {
this.street = street;
this.city = city;
this.country = country;
}
// Getters and setters
// ...
}
// 使用实体和值对象
public class Main {
public static void main(String[] args) {
UUID userId = UUID.randomUUID();
User user = new User(userId, "johnDoe", "password123");
Address address = new Address("123 Main St", "Cityville", "Countryland");
user.setAddress(address);
// 访问实体和值对象的属性
System.out.println("User ID: " + user.getId());
System.out.println("Username: " + user.getUsername());
Address userAddress = user.getAddress();
System.out.println("Street: " + userAddress.getStreet());
System.out.println("City: " + userAddress.getCity());
System.out.println("Country: " + userAddress.getCountry());
// 调用实体的方法
String inputPassword = "password123";
boolean isValid = user.isValidPassword(inputPassword);
System.out.println("Is valid password? " + isValid);
}
}
以上示例中,定义了一个User实体类和一个Address值对象类。User具有唯一标识(UUID)、用户名和密码属性,并且有一个isValidPassword方法用于验证密码的有效性。Address作为User的一个属性,描述了用户的地址。
在Main类中,创建了一个User对象和一个Address对象,并通过调用相应的setter方法将Address对象赋值给User对象。然后通过访问实体和值对象的属性来打印相关信息,并调用实体的方法进行验证。
聚合根和聚合模式的应用
DDD(领域驱动设计)中的聚合根和聚合模式是一种重要的设计概念,用于管理和维护领域对象之间的整体性和一致性。
-
聚合根(Aggregate Root):
-
聚合根是领域模型中的一个重要概念,它是一组相关对象的根实体,代表了一个聚合的边界。 -
聚合根必须负责保证聚合内对象的一致性和完整性,并提供对聚合内对象的访问、操作和维护。 -
聚合根通过标识属性来唯一标识一个聚合实例,并将聚合内部的对象封装在其内部。 -
聚合根应该尽可能减少外部对聚合内部对象的直接访问,而通过聚合根提供的方法来间接操作聚合内部对象。 -
聚合模式(Aggregate Pattern):
-
聚合模式是一种将一组相关的领域对象组织成聚合的方式,以实现整体性和一致性的管理。 -
聚合由聚合根和聚合内的对象组成,聚合根负责管理和控制聚合内的对象,维护其状态一致性。 -
聚合模式通过将领域对象划分为聚合根、实体和值对象等层次结构,以及定义聚合根的边界和关联关系,来约束对象之间的访问和操作。 -
聚合模式强调封装和隐藏聚合内部对象,通过聚合根提供的方法来管理聚合的行为和状态。
在应用聚合根和聚合模式时,以下是一些常见的使用场景和注意事项:
-
聚合根的定义和使用:
-
聚合根应该是具有唯一标识的实体对象,代表了整个聚合的边界。 -
聚合根负责管理和维护聚合内的对象之间的关系和一致性。 -
外部对象应该通过聚合根来访问和操作聚合内的对象,以保证聚合的整体性。 -
聚合内部对象的定义和访问:
-
聚合内部的对象可以包括实体、值对象和其他聚合根,根据具体业务需求来设计和划分。 -
聚合内部对象应该被封装起来,不直接暴露给外部对象。 -
外部对象通过聚合根提供的方法来间接访问和操作聚合内部的对象。 -
聚合之间的关系和边界:
-
聚合之间可以存在嵌套和引用关系,形成复杂的领域模型网。 -
每个聚合根应该有清晰的边界,以限制不同聚合之间的直接访问和操作。 -
聚合之间的关系应该通过聚合根的标识属性和引用属性来建立。 -
事务边界和持久化:
-
DDD中的聚合通常对应着数据库事务的边界,一个聚合就是一个单元的数据修改和持久化操作。 -
聚合根负责控制和维护聚合内对象的一致性,确保整个聚合的状态在事务内是一致的。 -
聚合根的持久化应该与聚合内部的对象一起进行,保证数据的完整性和一致性。
聚合根和聚合模式的应用可以提高领域建模的粒度和灵活性,将领域对象组织为聚合能够更好地管理对象间的关系和状态变化。使用聚合根和聚合模式能够提高系统的可维护性、可扩展性和并发性,并减少领域模型的复杂度。
DDD聚合根
以下是一个简单的Java代码示例,用于说明聚合根和聚合模式的应用方式:
// 聚合根类
public class OrderAggregate {
private String orderId;
private List<OrderItem> orderItems;
public OrderAggregate(String orderId) {
this.orderId = orderId;
this.orderItems = new ArrayList<>();
}
// 添加订单项
public void addOrderItem(String productId, int quantity) {
OrderItem item = new OrderItem(productId, quantity);
orderItems.add(item);
}
// 移除订单项
public void removeOrderItem(String productId) {
OrderItem itemToRemove = null;
for (OrderItem item : orderItems) {
if (item.getProductId().equals(productId)) {
itemToRemove = item;
break;
}
}
if (itemToRemove != null) {
orderItems.remove(itemToRemove);
}
}
// 获取所有订单项
public List<OrderItem> getOrderItems() {
return orderItems;
}
// 计算订单总价
public double calculateTotalPrice() {
double totalPrice = 0.0;
for (OrderItem item : orderItems) {
double itemPrice = item.calculateItemPrice();
totalPrice += itemPrice;
}
return totalPrice;
}
}
// 订单项类
public class OrderItem {
private String productId;
private int quantity;
public OrderItem(String productId, int quantity) {
this.productId = productId;
this.quantity = quantity;
}
// 获取产品ID
public String getProductId() {
return productId;
}
// 获取订单项数量
public int getQuantity() {
return quantity;
}
// 计算订单项总价
public double calculateItemPrice() {
// 根据产品ID和数量计算订单项的总价,这里只是个示例,具体实现可以根据业务需求编写
return 0.0;
}
}
// 测试代码
public class Main {
public static void main(String[] args) {
// 创建聚合根对象
OrderAggregate order = new OrderAggregate("123456");
// 添加订单项
order.addOrderItem("001", 2);
order.addOrderItem("002", 1);
// 计算订单总价
double totalPrice = order.calculateTotalPrice();
// 打印订单总价
System.out.println("Total Price: " + totalPrice);
}
}
以上示例代码展示了一个简单的订单聚合,其中OrderAggregate表示聚合根,OrderItem表示聚合内的对象。在OrderAggregate中,我们可以通过添加和移除订单项来管理聚合内部的对象,并通过计算订单总价方法来操作聚合内的对象。通过使用聚合根和聚合模式,我们能够更好地组织和管理领域对象,提高代码的可维护性和扩展性。
领域事件和事件驱动模式的实践
-
领域事件:
-
领域事件是在领域模型中发生的具有业务含义的事情,它记录了一些状态改变或者领域对象之间的交互。 -
领域事件通过描述事情的发生来反映业务的变化,通常使用过去式的动词来命名,如OrderCreated、ProductStockUpdated等。 -
领域事件可以被发布和订阅,以便通知其他感兴趣的领域模型或组件进行相应的处理。 -
事件驱动模式:
-
事件驱动模式是一种软件架构模式,其中系统的行为和状态变化是由触发的事件驱动的。 -
在DDD中,事件驱动模式用于实现领域模型之间的解耦,通过发布和订阅事件来实现模块之间的通信和协作。 -
事件驱动模式采用消息传递的方式,领域模型之间通过发布事件和订阅事件来进行通信。 -
发布者负责发布事件,订阅者通过注册自己的事件处理方法来订阅感兴趣的事件,并在事件发生时执行相应的响应逻辑。
在实践领域事件和事件驱动模式时,以下是一些常见的步骤和注意事项:
-
定义领域事件:
-
根据业务需求和领域模型的变化,识别和定义需要引入的领域事件。 -
给每个领域事件命名,使用过去式的动词来描述事件发生的动作。 -
实现领域事件:
-
在领域模型中定义并触发相应的领域事件,通常是在领域对象的行为方法中进行触发。 -
领域事件可以携带一些必要的数据信息,以提供事件处理的上下文和业务参数。 -
事件发布和订阅机制:
-
实现一个事件发布和订阅的机制,用于将事件传递给感兴趣的订阅者。可以使用消息队列、事件总线等技术来实现。 -
订阅者通过注册事件处理方法来订阅感兴趣的事件,发布者在事件发生时将事件发送给所有订阅者。 -
事件处理:
-
订阅者实现相应的事件处理方法,用于接收和处理事件。处理方法根据事件的类型和数据执行相应的业务逻辑。 -
事件处理方法可以修改自身状态,调用其他领域模型的方法,发送新的命令等。 -
事件溯源和持久化:
-
可以使用事件溯源机制来记录和存储所有发生的领域事件,以便进行回溯、重放和历史数据分析。 -
领域事件的持久化可以通过将事件存储到事件日志或数据库中来实现,以保证事件的持久性和可靠性。
通过实践领域事件和事件驱动模式,可以实现领域模型之间的解耦、灵活性和可扩展性。事件驱动的方式可以帮助我们构建具有高内聚低耦合的领域模型,并支持系统的可伸缩性和可维护性。在设计和实现过程中,要根据具体业务需求和系统架构选择合适的事件驱动技术和工具。
DDD领域事件
以下是一个简单的Java代码示例,演示了如何在领域模型中定义和使用领域事件:
首先,我们定义一个领域事件类OrderCreatedEvent,用于表示订单创建的事件:
public class OrderCreatedEvent {
private final String orderId;
private final String customerName;
public OrderCreatedEvent(String orderId, String customerName) {
this.orderId = orderId;
this.customerName = customerName;
}
public String getOrderId() {
return orderId;
}
public String getCustomerName() {
return customerName;
}
}
接下来,我们定义一个订单领域模型Order,其中包含了触发和发布领域事件的逻辑:
import java.util.ArrayList;
import java.util.List;
public class Order {
private final String orderId;
private final String customerName;
private final List<OrderCreatedEventListener> eventListeners;
public Order(String orderId, String customerName) {
this.orderId = orderId;
this.customerName = customerName;
this.eventListeners = new ArrayList<>();
}
public void addEventListener(OrderCreatedEventListener listener) {
eventListeners.add(listener);
}
public void create() {
// 创建订单的逻辑...
// 发布领域事件
OrderCreatedEvent event = new OrderCreatedEvent(orderId, customerName);
notifyEventListeners(event);
}
private void notifyEventListeners(OrderCreatedEvent event) {
for (OrderCreatedEventListener listener : eventListeners) {
listener.onOrderCreated(event);
}
}
}
在Order类中,我们定义了一个addEventListener方法,用于订阅订单创建事件的监听器。在create方法中,当订单创建完成后,我们会触发相应的领域事件,并通知所有的订阅者。
下面是一个订单创建事件的监听器接口OrderCreatedEventListener的定义:
public interface OrderCreatedEventListener {
void onOrderCreated(OrderCreatedEvent event);
}
订阅者可以实现OrderCreatedEventListener接口,并实现onOrderCreated方法来处理订单创建事件。
以下是一个订阅者的示例实现:
public class EmailNotificationService implements OrderCreatedEventListener {
@Override
public void onOrderCreated(OrderCreatedEvent event) {
// 发送邮件通知给顾客
String orderId = event.getOrderId();
String customerName = event.getCustomerName();
System.out.println("发送邮件通知:订单 " + orderId + " 已创建,顾客名:" + customerName);
}
}
在这个示例中,EmailNotificationService实现了OrderCreatedEventListener接口,并在onOrderCreated方法中发送邮件通知给顾客。
最后,我们可以进行测试,使用以下代码创建一个订单并触发订单创建事件:
public class Main {
public static void main(String[] args) {
// 创建订单
Order order = new Order("123456", "John Doe");
// 添加订阅者
EmailNotificationService notificationService = new EmailNotificationService();
order.addEventListener(notificationService);
// 触发订单创建事件
order.create();
}
}
当执行order.create()方法时,订单创建事件将被触发,并通知EmailNotificationService发送邮件通知给顾客。
DDD 架构的应用实践
领域驱动设计的项目实施步骤
-
理解业务需求: 在开始实施DDD之前,首先需要充分理解业务需求和上下文。与业务专家合作,深入了解业务领域、业务规则、业务流程等方面的信息。这有助于建立一个准确的领域模型以及对业务的全面理解。
-
划定限界上下文: 通过定义限界上下文,将业务分成不同的子领域。限界上下文是一种逻辑边界,用于定义和隔离每个子领域的范围。每个限界上下文都与特定的业务功能或业务概念相关联,并有自己的领域模型。
-
构建领域模型: 针对每个限界上下文,开始构建对应的领域模型。领域模型是对业务领域中的实体、值对象、聚合根、领域服务等各个领域概念的建模。使用领域语言,将业务规则和概念转化为代码实体和对象。
-
强调领域模型的设计: 领域模型是DDD最核心的部分,需要注重其设计。通过使用领域驱动设计的原则和模式,如聚合、领域事件、领域服务等,来构建可维护、可扩展的领域模型。在设计过程中,可以使用UML类图、领域事件风暴等工具来辅助设计。
-
实施战术模式: DDD提供了一系列战术模式用于解决常见的领域建模问题,如实体、值对象、聚合、仓储、领域事件等。根据实际情况选择合适的战术模式来实现领域模型。
-
持续迭代开发: 在DDD项目中,持续迭代开发是很重要的。将项目划分成多个小的迭代周期,每个周期都能完成一个或多个功能点的开发。通过迭代开发,逐渐完善领域模型并不断与业务需求进行验证和调整。
-
领域驱动的架构设计: DDD强调以领域模型为核心的架构设计。设计合适的架构模式,如六边形架构、CQRS(Command and Query Responsibility Segregation)等,以支持领域模型的实现和演进。
-
领域事件驱动: 使用领域事件来解耦领域模型和外部系统之间的通信。通过使用事件驱动架构,可以实现松耦合、可伸缩的系统,并支持分布式系统的开发。
-
测试与验证: 在DDD项目中,测试至关重要。编写针对领域模型的单元测试、集成测试和端到端测试,确保领域模型的正确性和稳定性。此外,需要与业务专家进行沟通和验证,确保领域模型符合业务需求。
-
持续优化: 随着项目的进行,不断根据反馈和实际运行情况对领域模型进行优化和演进。根据项目的实际需求,可能需要对领域模型、限界上下文的划分、架构设计等进行调整和优化。
DDD 架构的架构设计和模块划分
-
领域层 (Domain Layer): 领域层是 DDD 的核心,包含了对业务领域的建模和实现。在该层中,将关注点放在业务核心概念、规则和逻辑上。主要包括以下模块:
-
实体 (Entity):代表领域中的具体对象,具有唯一的标识符和状态。实体封装了业务行为和状态变化的逻辑。 -
值对象 (Value Object):在领域层中用于描述某个特定概念的不可变对象。值对象没有唯一标识符,通常用于表示属性集合。 -
聚合根 (Aggregate Root):聚合是一组关联对象的集合,聚合根是聚合中的一个主要对象。聚合根负责保证聚合内部的一致性和约束。 -
领域服务 (Domain Service):处理领域对象之间的复杂业务逻辑,不属于任何一个具体的实体或值对象。 -
领域事件 (Domain Event):表示在领域中发生的重要事实,用于捕获和传递领域内发生的变化。 -
应用层 (Application Layer): 应用层处理用户接口与领域层之间的交互,并协调不同的领域对象完成具体的应用需求。它负责接收用户输入,解析请求,调用领域对象的方法,并将结果返回给用户。主要包括以下模块:
-
应用服务 (Application Service):提供用户能直接调用的接口,负责接收用户请求、处理输入验证和异常处理,协调领域对象的协作。 -
应用事件 (Application Event):用于在应用层中传播信息或通知,比如通知其他部分某个特定的事件已经发生。 -
基础设施层 (Infrastructure Layer): 基础设施层提供支持整个应用程序运行的基础设施服务,与具体的技术平台和框架相关。主要包括以下模块:
-
持久化层 (Persistence Layer):处理数据的持久化和访问,比如数据库访问、ORM 映射等。 -
外部服务层 (External Service Layer):与外部系统进行交互的服务,比如第三方 API、消息队列、文件存储等。 -
UI 层 (User Interface Layer):处理用户接口的实现,包括 Web 页面、移动应用或其他用户界面。 -
共享内核 (Shared Kernel): 共享内核是一种可选的模块,用于处理多个子域之间共享的通用领域知识和组件。如果多个子域之间存在类似的业务逻辑或概念,可以将其抽象为共享内核,在不同的子域中共享和重用。
这些层次和模块之间通过严格的边界划分和通信机制来保持松耦合。领域层是 DDD 的核心,并且在架构设计中占据主导地位,因为它直接与业务领域相关。应用层负责协调和转换用户请求和领域对象之间的交互。基础设施层提供了支持整个应用程序的基础设施服务。共享内核用于处理多个子域之间的通用业务部分。
DDD 架构与微服务架构的结合
DDD(领域驱动设计)架构和微服务架构可以结合起来,以实现更灵活、可扩展和高内聚的系统设计。
-
微服务边界与子域边界对应: DDD 强调将复杂业务领域分解为子域,而微服务架构则将系统分解为一组小型自治服务。这两者都强调通过明确的边界来隔离和解耦各个功能模块。在结合时,可以将每个微服务与一个或多个子域对应起来,使每个微服务专注于特定的业务能力。
-
微服务作为应用层: 在 DDD 中,应用层负责协调用户接口和领域层之间的交互。在微服务架构中,每个微服务都可以看作是一个独立的应用。因此,可以将微服务作为应用层来实现,负责处理用户请求、数据验证、事务处理等工作,并协调调用领域层的功能。
-
领域驱动设计在微服务中的体现: DDD 的核心概念如实体、值对象、聚合根和领域服务等,可以映射到微服务的实现中。每个微服务可以有自己的领域模型,负责实现特定子域的业务逻辑。微服务之间可以通过领域事件进行异步通信,以捕获和传递领域内发生的变化。
-
微服务的自治性和松耦合性: 微服务架构鼓励每个服务的自治性,即每个服务可以独立开发、部署和扩展。在结合 DDD 时,每个微服务可以拥有自己的领域对象和业务规则,并通过领域事件或异步消息队列实现与其他微服务的解耦。这种松耦合性使得单个微服务的修改不会波及整个系统,提高了系统的可维护性和可扩展性。
-
按业务能力组织微服务: 在 DDD 中,子域是按业务能力进行划分的,而微服务架构也强调遵循单一职责原则。因此,可以根据子域的边界和业务能力来组织微服务,每个微服务专注于一个或多个相关的业务能力。
-
分布式数据管理: 微服务架构中,每个微服务都有自己的数据库或数据存储。在结合 DDD 时,每个微服务可以有自己的数据模型和数据访问层,负责管理自己的数据。需要注意确保数据的一致性和完整性,可以使用事件溯源或分布式事务等机制来处理跨微服务的数据一致性问题。
DDD 架构的挑战和解决方案
复杂性和团队协作的问题
复杂性和团队协作是软件开发中普遍面临的挑战,尤其在大型项目中更为突出。
-
复杂性问题:
-
难以理解和管理:大规模软件系统通常涉及多个子系统和模块,其交互复杂度很高。代码的可读性和可维护性受到挑战。 -
高度耦合和依赖:不良的设计和实现可能导致组件之间紧密耦合,修改一个模块可能会影响其他模块,导致维护和扩展困难。 -
技术栈和工具的选择:需要评估和选择适合项目需求的技术栈和工具,使得系统开发过程更加高效和可维护。 -
团队协作问题:
-
沟通和协调:在大型项目中,多个团队成员之间的协作和沟通变得更加困难,需确保有效的信息共享和沟通渠道。 -
角色和责任:明确团队成员的角色和责任,确保每个人知道自己的任务和目标,避免任务冲突和重复工作。 -
分布式团队:如果团队分散在不同地区或时区,协作可能会更具挑战性。需要采用合适的工具和流程来促进远程团队成员之间的协作和沟通。
应对复杂性和团队协作问题的方法包括:
-
使用适当的架构和设计模式:通过使用合适的架构和设计模式,可以将系统分解为更小的、可管理的组件,并减少模块之间的耦合度。 -
引入自动化测试和持续集成:使用自动化测试和持续集成工具,确保代码质量和系统稳定性,并及早发现和解决问题。 -
实践敏捷开发方法:采用敏捷开发方法,如Scrum或Kanban,以增加透明度、灵活性和反馈,促进团队合作和快速响应变化。 -
建立清晰的沟通渠道:确保团队成员之间有良好的沟通和信息共享机制,例如定期的会议、沟通工具和文档分享。 -
高效的项目管理:使用适当的项目管理工具和技术,跟踪任务进度、资源分配和风险管理,以确保项目按时交付和团队协作高效。 -
持续学习和知识分享:鼓励团队成员进行持续学习,通过内部培训、技术分享会等方式提高技能水平和知识共享。
面向领域的测试和自动化测试策略
-
DDD 面向领域的测试策略:
-
业务规则测试:测试业务规则是否按预期工作,涉及验证各种业务规则的正确性。 -
聚合根测试:聚合根是 DDD 中的核心概念,测试应确保聚合根的行为和状态正确,并与其关联的实体、值对象及领域事件进行适当的交互和更新。 -
领域服务测试:领域服务负责处理领域中的复杂业务逻辑,测试要验证领域服务能够正确执行其职责。 -
领域事件测试:测试领域事件的产生、发布和处理,确保领域事件在系统中正确地传播和触发相关操作。 -
领域模型一致性测试:验证领域模型的一致性和完整性,确保模型在各种场景下的正确行为。 -
自动化测试策略:
-
单元测试:通过编写单元测试用例,测试领域对象、聚合根、值对象等的行为和状态,并确保它们按预期工作。 -
集成测试:测试多个领域对象或服务之间的集成,验证它们在协同工作时的正确性。 -
接口测试:测试与外部系统或服务的接口交互,确保数据传输和通信的准确性和稳定性。 -
持续集成测试:将自动化测试纳入持续集成流程,确保每次代码提交后都能进行自动化测试,从而及早发现问题并减少回归测试的工作量。
在进行 DDD 面向领域的测试和自动化测试时,需要关注以下注意事项:
-
确保测试覆盖率:尽可能涵盖业务领域的各个方面,以减少遗漏的测试场景。 -
使用适当的测试框架和工具:选择适合领域驱动设计的测试框架和工具,例如基于 BDD(行为驱动开发)的测试框架,如Cucumber或SpecFlow。 -
注重测试数据:测试数据在 DDD 测试中至关重要,应该考虑各种不同的情况,包括边界条件、异常情况等。 -
与领域专家紧密合作:与业务领域专家进行密切的合作和沟通,以确保测试场景和用例与业务需求一致。 -
持续改进:根据测试结果和反馈不断改进测试策略和自动化测试框架,提高测试质量和效率。