
NIo开发利器ByteBuffer
有道无术,术尚可求也!有术无道,止于术!
想要使用NIO开发Socket分服务端和客户端,必须掌握的一个知识点就是ByteBuffer的使用,他是NIO再数据传输中的利器!相比于BIO传输过程中的字节流,ByteBuffer更能体现出服务端/客户端对于数据的操作效率,ByteBuffer内存维护一个指针,使得传输的数据真正的能够达到重复使用,重复读写的能力!
主要API和属性
他是对于Buffer的一个默认实现,具体主要的属性和方法我们需要看Buffer类:
主要属性
//指针标记
private int mark = -1;
//指针的当前位置
private int position = 0;
//翻转后界限
private int limit;
//最大容量
private int capacity;
//当为堆外内存的时候,内存的地址
long address;
主要方法
//返回当前缓冲区的最大容量
public final int capacity() {return capacity;}
//返回当前的指针位置
public final int position() {return position;}
//返回当前的读写界限
public final int limit() {return limit;}
//标记当前指针位置
public final Buffer mark() {
mark = position;
return this;
}
//恢复当前指针位置
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
//清空缓冲区,注意这里并不会清空数据,只是将各项指标初始化,后续再写入数据就直接覆盖
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
//切换读写模式
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
//重新从头进行读写,初始化指针和标记位置
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
//剩余可读可写的数量
public final int remaining() {return limit - position;}
//当前是否可读/可写
public final boolean hasRemaining() {return position < limit;}
//是不是只读的
public abstract boolean isReadOnly();
//是不是支持数组访问
public abstract boolean hasArray();
//获取当前缓存的字节数组(当hasArray返回为true的时候)
public abstract Object array();
//是不是堆外缓冲区也就是直接缓冲区
public abstract boolean isDirect();
//取消缓冲区
final void discardMark() {mark = -1;}
堆内缓冲
什么是堆内缓冲区?所谓的堆内缓冲区,顾名思义就是再JVM对上分配的缓冲区,一般由**byte[]**实现,它有一个好处,就是它的内存的分配与回收由JVM自动完成,用户不必自己再操心内存释放的问题,但是缺点也很明显,就是它再数据传输的时候,需要将数据从JVM复制到本地物理内存上,多了一次复制操作!
创建堆内缓冲区
java堆内缓冲区的默认实现是 HeapByteBuffer,但是这个对象是一个 default权限的类,你是无法直接创建的,只能通过JDK底层暴露的api来创建:
//1. 分配一个最大能够存储128个字节的堆内存
ByteBuffer heapRam = ByteBuffer.allocate(128);
//2. 或者直接初始化数据创建
ByteBuffer wrapBuffer = ByteBuffer.wrap("欢迎关注公众号:【源码学徒】 学习更多源码知识!".getBytes());
堆内缓冲区API源码解析
构造方法
以上两种方案创建的都是一个堆内缓冲区,他们创建的逻辑大致相同,我们以 ByteBuffer.allocate为例进行分析:
public static ByteBuffer allocate(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException();
}
//创建一个堆内缓冲区
return new HeapByteBuffer(capacity, capacity);
}
我们可以看到,通过 ByteBuffer.allocate创建的缓冲区是一个 HeapByteBuffer,他是堆内缓冲区!我们继续往下分析:
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}
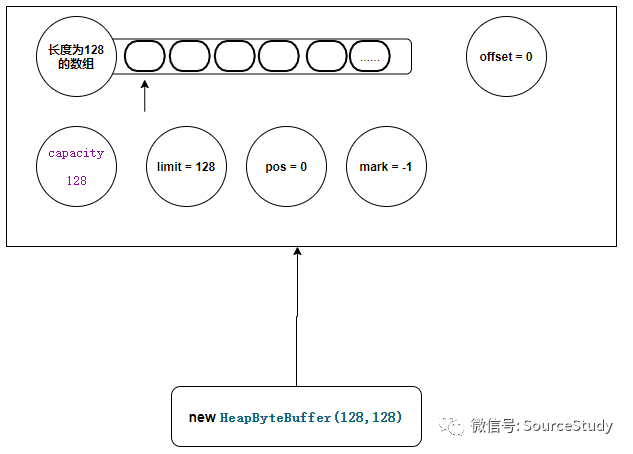
注意此时,cap和lim都是我们传递的大小,内部还创建了一个cap大小的字节数组传递下去!他就是堆内最终存储数据的数组!
// mark = -1 pos = 0 lim = 128 cap = 128 hb = 字节数组对象 offset = 0
ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset) {
super(mark, pos, lim, cap);
//前面创建的字节数组对象
this.hb = hb;
//保存一个偏移量 默认为0
this.offset = offset;
}
然后再调用父类的构造参数:
Buffer(int mark, int pos, int lim, int cap) {
if (cap < 0){
throw new IllegalArgumentException("Negative capacity: " + cap);
}
//保存最大容量
this.capacity = cap;
//保存limit
limit(lim);
//保存pos指针位置
position(pos);
//........ 忽略无必要代码.........
}
此时我们的一个堆内缓冲区就创建完成了,它的内部结构如下:
put方法
现在我们的容器创建好了,我们就需要往里面怼数据了呀,我们需要往里面写入一段字节数组:
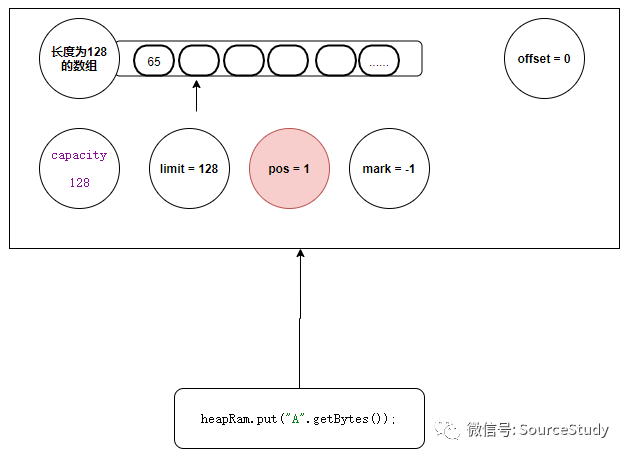
heapRam.put("A".getBytes());
我们调用put方法往ByteBuffer里面写入一段数据会发生什么呢?
public ByteBuffer put(byte[] src, int offset, int length) {
//先判断当前数据的长度是否超过可写长度了
// remaining() = limit - position = 128 - 0
if (length > remaining()) {
throw new BufferOverflowException();
}
//hb还记得吗,就是我们再创建堆内缓冲区所创建的字节数组
//这里就是将我们的数据拷贝到从当前的指针位置开始的堆内缓存(hb字节数组)
System.arraycopy(src, offset, hb, ix(position()), length);
//将当前的指针位置 + 数据长度,我们本次写入的数据长度是1 那么当前的指针索引就是 1
position(position() + length);
return this;
}
当调用put方法后,内部数据结构如下:
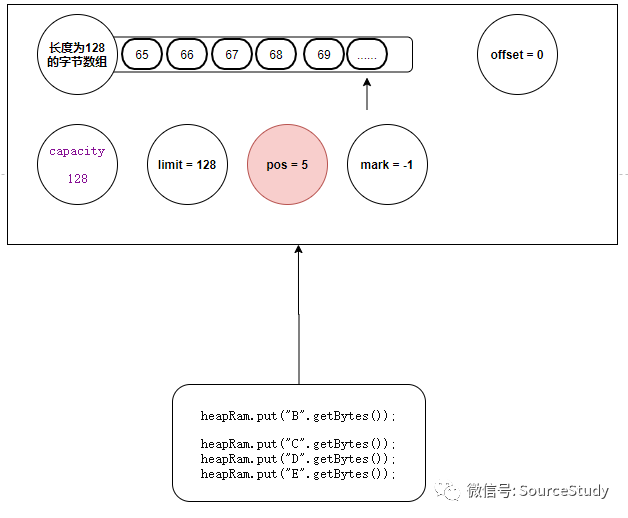
为了方便后续的讲解我们再次写入几个数据的时候,逻辑和上方一样:
heapRam.put("B".getBytes());
heapRam.put("C".getBytes());
heapRam.put("D".getBytes());
heapRam.put("E".getBytes());
get方法
我们现在再缓冲区里面写入了 ABCDE五个数据,此时我们如果想从缓冲区取数据,就应该调用另外一个api:get()方法
byte b = heapRam.get();
System.out.println(new String(new byte[]{b}));
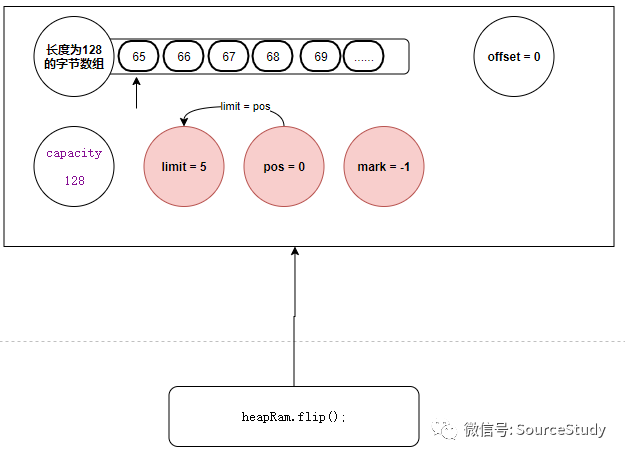
但是,很奇怪的是,我们打印了一个空,并没有想象中的打印一个A,这是为什么呢?我们由上面的分析可以知道,每次缓冲区对于数据的操作都是基于指针来做的,我们每一次操作数据,指针都会后移一位,当我们发生一个get()请求后,指针依旧会后移,将下标为5的数据返回同时自身自增变为6.但是下标为5的并没有数据,只能返回一个空数据,所以我们如果想从头读数据,就必须想办法将指针复位,重新变为0,我们此时往里面写数据,我们称之为写模式,想要切换到读模式就必须调用 **heapRam.flip();**方法来切换读写模式,复位读写指针!
heapRam.flip();
那这个api具体做了什么呢?仅仅是将读写指针复位吗? 那我提出一个问题,不妨读者读到这里思考一下,如果仅仅是指针复位的话,我们如何控制不让用户读超呢? **我们只写入了5个数,如何避免用户读第六个数据呢?**我们带着疑问,看下 flip方法究竟做了什么:
public final Buffer flip() {
//将当前的指针位置赋值给limit
limit = position;
//读写指针复位
position = 0;
mark = -1;
return this;
}
filp方法
我们可以看到,filp方法再复位读写指针之前,记录了一个位置 limit,具体他是干嘛的,我么稍后再说 到现在为止,我们的数据结构如下:
byte b = heapRam.get();
System.out.println(new String(new byte[]{b}));
此时我们再次调用get方法,指针后移,同时返回当前指针位置代表的数据:注意 ix方法不用管,他是计算偏移量的,这里始终是0
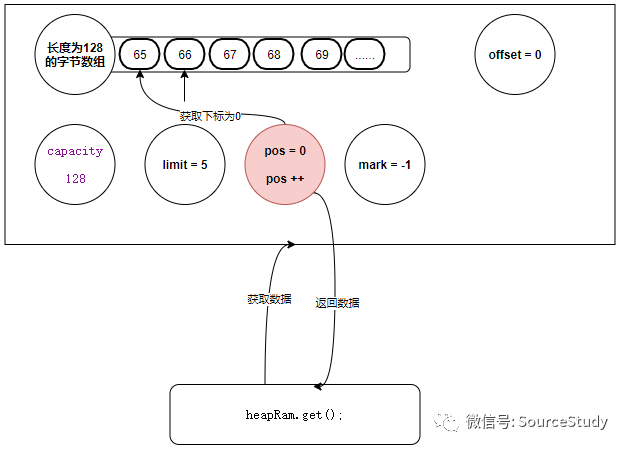
public byte get() {
return hb[ix(nextGetIndex())];
}
nextGetIndex:主要是判断当前指针是否超过了 limit的限制,同时自增指针位置
final int nextGetIndex() {
//limit的作用在这里被体现,判断你的读指针是不是读超了数据范围
if (position >= limit){
throw new BufferUnderflowException();
}
//返回读指针的位置,并自增1
return position++;
}
get方法主要是直接返回字节数组某个下标的位置的字节数据!
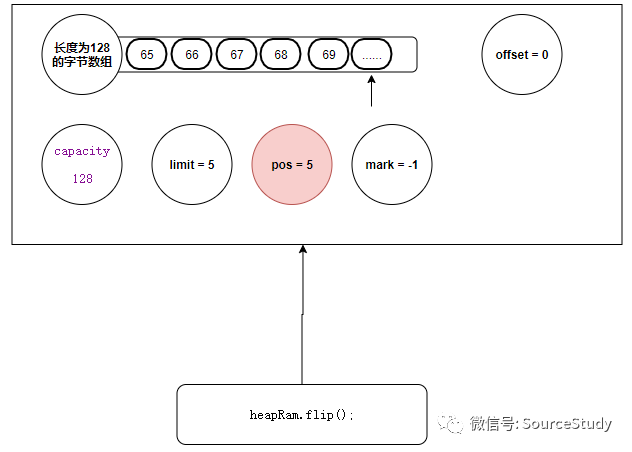
我们多读一些数据:
byte[] bytes = new byte[4];
heapRam.get(bytes);
System.out.println(new String(bytes));
当我们传递了一个字节数组去读取的时候,它的内部是如何做的呢?
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
//将数据拷贝至我们传递的字节数组中
System.arraycopy(hb, ix(position()), dst, offset, length);
//读指针位置+我们要读取的长度
position(position() + length);
return this;
}
此时缓冲区的内部数据结构如下:
我们把数据读完了,下面,我又想往里面写数据了,假设直接写是否能写呢? put方法向下表为5的地方写一个数据,同时指针后移,似乎可行,我们分析一下put方法,具体我们前面已经分析过了,再put方法的源码中,有这么一段逻辑:
if (length > remaining())
throw new BufferOverflowException();
假设写入数据的长度,大于剩余可写长度,就会报错,我们具体看下这个方法的逻辑:
public final int remaining() {
return limit - position;
}
我们看上图的数据结构数据可知,该结果为0,就必定会报错,所以说,当我们向再次切换成写模式的话,就一定要初始化 pos,还是调用filp方法吗?重新调用filp方法固然可行,但是,调用filp方法并不会初始化limit的大小,造成明明我们分配了128个字节的大小,但是可用的永远都只有5个,所以,我们如果想让数据重新能够初始化,就必须让limit = capacity,JDK也为我们提供了接口:clear
clear方法
heapRam.clear();
public final Buffer clear() {
//读写指针归零
position = 0;
//limit初始化为初始状态
limit = capacity;
//标记初始化为初始状态
mark = -1;
return this;
}
可以看到,clear方法将我们缓冲区中的所有指标全部的进行初始化了,指针重新归0,但是JDK考虑到性能影响byte数组中的数据并没有被清除,只会被新数据覆盖调!
由同学会问,你不是说ByteBuffer可以进行重复的读取吗? 这明明只能读一遍,读完就得初始化指针位置,你骗人!
别着急,想要进行重复的读写操作,我们必须还要掌握另外一组API:mark() 、reset();
我们假设我们此时处于读模式,数据结构如下:
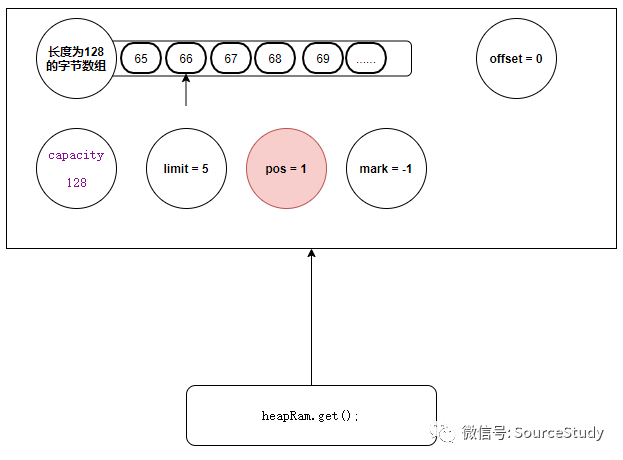
mark方法
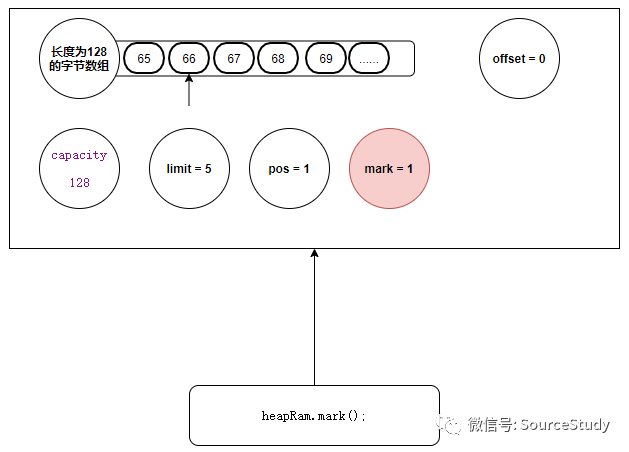
我们此时想,一会读完数据了,还想再次回到当前的位置进行数据的二次读取,我们此时就应该调用mark()方法,打个标记,它的底层会记录当前指针的位置:
heapRam.mark();
public final Buffer mark() {
//记录当前读指针的位置
mark = position;
return this;
}
调用mark方法之后,我们的数据结构如下:
然后我们将数据读完:
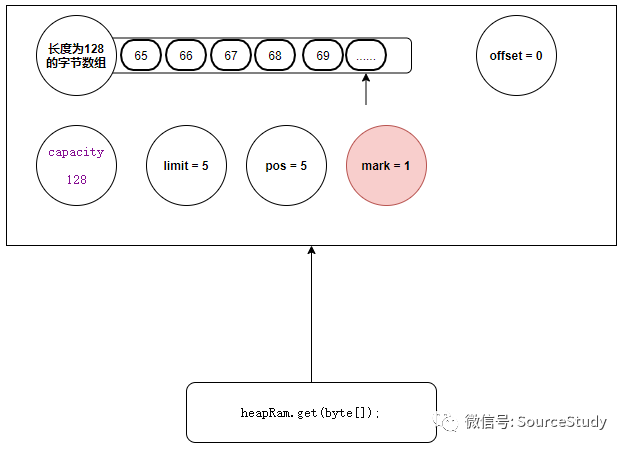
reset方法
我们将数据读完之后,想再从标记位置开始读取的时候:
heapRam.reset();
public final Buffer reset() {
//获取当前标记的位置
int m = mark;
if (m < 0)
//如果标记位为负数,就证明没有进行标记过直接报错
throw new InvalidMarkException();
//然后将标记位置赋值给当前的指针位置
position = m;
return this;
}
当前的数据结构如下:
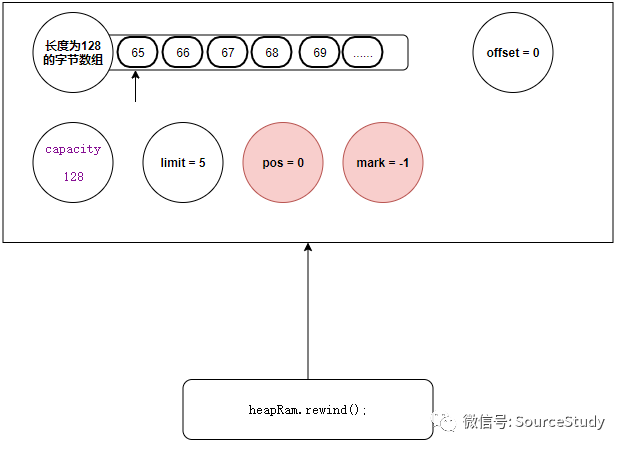
rewind方法
如此,我们就可以进行复读了,相类似的方法还有:rewind
heapRam.rewind();
public final Buffer rewind() {
//回复读写指针为0
position = 0;
//废弃标记位置
mark = -1;
return this;
}
rewind方法是直接返回的 缓冲区的头部,同时废弃标记的位置 !
堆外缓冲区
创建堆外缓冲区
//1. 分配一个最大能够存储128个字节的堆外内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(128);
jvm如何操作堆外内存
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
//获取JDK底层的操作物理内存的工具类
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe o = (Unsafe) theUnsafe.get(null);
//从物理内存分配一块128的内存
long address = o.allocateMemory(128);
//获取字节数组的一个基本偏移 数组基本偏移
long arrayBaseOffset = (long)o.arrayBaseOffset(byte[].class);
byte[] bytes = "欢迎关注公众号:【源码学徒】 学习更多源码知识!".getBytes();
//向物理内存复制一段数据
// 数据源 数据的基本偏移 目标数据源 要复制到的内存地址 复制数据的长度
o.copyMemory(bytes, arrayBaseOffset, null, address, bytes.length);
//从物理机将数据拷贝回JVM内存中
byte[] copy = new byte[bytes.length];
// 数据源 物理地址 目标数据源 数组基本偏移量 复制数据的长度
o.copyMemory(null, address, copy, arrayBaseOffset, bytes.length);
//释放内存
o.freeMemory(address);
System.out.println(new String(copy));
}
上述的操作是分配一个物理内存、将一段数据写进物理内存、然后将数据从物理内存读进JVM数组、释放物理内存
有了基本的知识,我们一起分下下堆外内存的源码把!
堆外缓冲区Api源码解析
构造方法
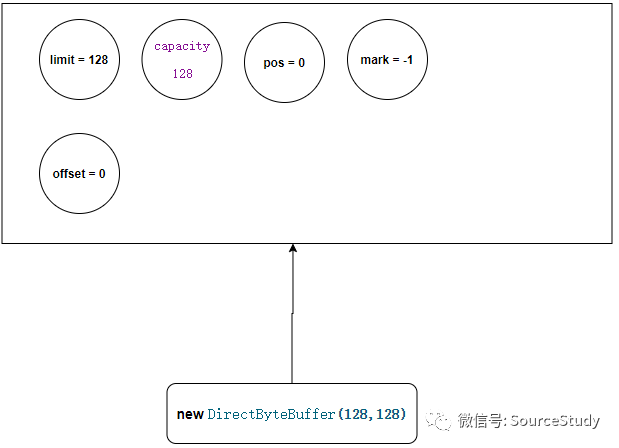
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
我们可以看到,堆外缓冲区是由DirectByteBuffer来代表的!
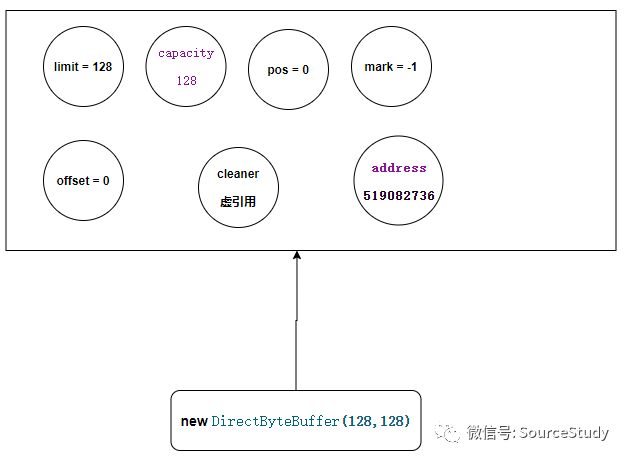
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
//......忽略其他代码..........
long base = 0;
try {
//从物理内存分配一块指定大小的内存 并返回当前分配内存的地址
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
//初始化内存
unsafe.setMemory(base, size, (byte) 0);
//判断是否对其的页面
if (pa && (base % ps != 0)) {
// 向上对其页面 并保存地址
address = base + ps - (base & (ps - 1));
} else {
//保存地址
address = base;
}
//这个极其重要,是JVM管理堆外内存的重要方法
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
我们来逐行进行分析,首先是 super(-1, 0, cap, cap);
// -1 0 128 128
MappedByteBuffer(int mark, int pos, int lim, int cap) {
//继续调用父类
super(mark, pos, lim, cap);
this.fd = null;
}
// -1 0 128 128
ByteBuffer(int mark, int pos, int lim, int cap) {
//在往上
this(mark, pos, lim, cap, null, 0);
}
// -1 0 128 128 null 0
ByteBuffer(int mark, int pos, int lim, int cap, byte[] hb, int offset) {
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
到这里就不往上分析了,它和创建堆内缓冲是一样的,保存一些基本的变量,但是注意 这里传递的hb是一个null,因为它是堆外缓冲区,不依赖与JVM内部的内存分配!
此时基本数据保存完毕,开始分配一块堆外内存:
base = unsafe.allocateMemory(size);
这里是调用的 native方法分配的缓冲区,是C来实现的,unsafe是JDK内部使用的一个操作物理内存的工具类,一般不对外开放,如果想要使用可以通过反射的方式获取,获取方式上面已经写出来了,同学们没事可以玩一下!
unsafe.setMemory(base, size, (byte) 0);
初始化内存区域,将所分配的内存里面的数据默认设置为字节0
address = base;
保存物理内存的地址,方面后面进行数据的读写
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
这个方法极其重要,主要负责改堆外内存的释放,他是一个虚引用,具体的讲解上一篇文章 深入分析NIO的零拷贝述的很详细,看一下JVM是如何释放一个不由JVM控制的堆外内存的!这里就不做具体的讲解了!
put方法
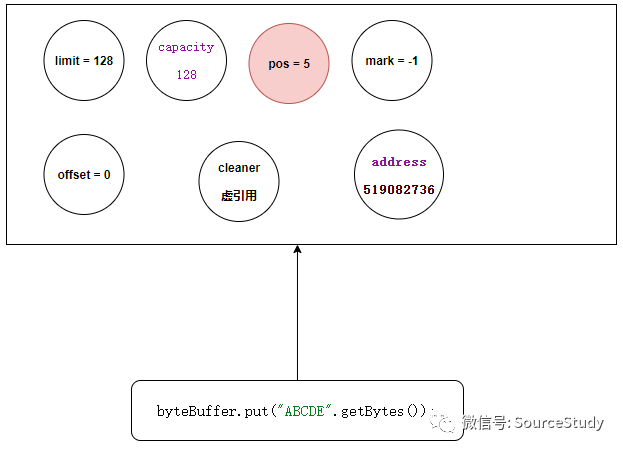
现在我们向堆外内存写入一段数据:
byteBuffer.put("ABCDE".getBytes());
我们看下源码是如何来操作堆外内存的
public final ByteBuffer put(byte[] src) {
return put(src, 0, src.length);
}
public ByteBuffer put(byte[] src, int offset, int length) {
if (((long)length << 0) > Bits.JNI_COPY_FROM_ARRAY_THRESHOLD) {
//检查越界
checkBounds(offset, length, src.length);
//获取当前的读写指针
int pos = position();
//获取当前的学些界限
int lim = limit();
//判断是否超过读写界限
assert (pos <= lim);
//计算剩余空间
int rem = (pos <= lim ? lim - pos : 0);
//判断写入数据是否大于剩余空间
if (length > rem) {
throw new BufferOverflowException();
}
//向物理内存拷贝数据
Bits.copyFromArray(src, arrayBaseOffset, (long)offset << 0, ix(pos), (long)length << 0);
//重新计算当前的读写指针
position(pos + length);
} else {
super.put(src, offset, length);
}
return this;
}
我们发现,里面最关键的一段代码是 Bits.copyFromArray(src, arrayBaseOffset, (long)offset << 0, ix(pos), (long)length << 0);
它传递的是:要写入的数据的字节数组、字节基准偏移、偏移量(0)、地址+读写指针的位置(addres + pos)、要写入的数据的长度
static void copyFromArray(Object src, long srcBaseOffset, long srcPos, long dstAddr, long length) {
//计算 偏移量 = 字节数组基准偏移量 + offset(0)
long offset = srcBaseOffset + srcPos;
//如果存在数据
while (length > 0) {
//判断数据是否大于1MB 如果大于1MB就默认只传递1MB,剩余数据交给下一次循环
long size = (length > UNSAFE_COPY_THRESHOLD) ? UNSAFE_COPY_THRESHOLD : length;
//拷贝数据
unsafe.copyMemory(src, offset, null, dstAddr, size);
//判断本次拷贝后剩余未拷贝的数据
length -= size;
//计算偏移量 本次应该偏移的数量
offset += size;
//计算地址 下次读取的起始位置
dstAddr += size;
}
}
我们会发现,里面的代码有一部分我们极其熟悉,正是上面我演示unsafe如何使用的代码,这里就是将数据拷贝至堆外内存的!现在它的内存结构如下:
filp方法
byteBuffer.flip();
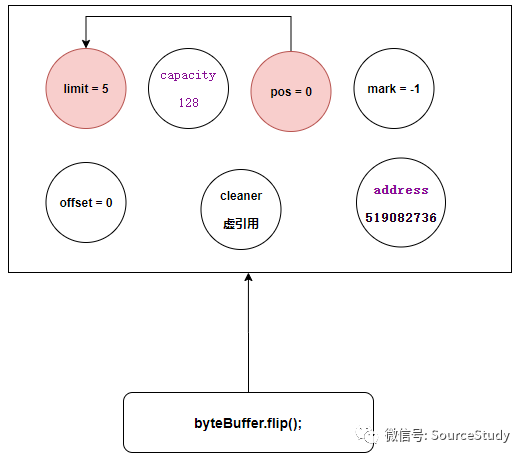
现在我们要获取数据了就也必须调用filp方法切换读写模式,直接缓冲区的切换方式和堆内内存的切换方式 一致,不做讲述,忘记的小伙伴请翻到上面看下!
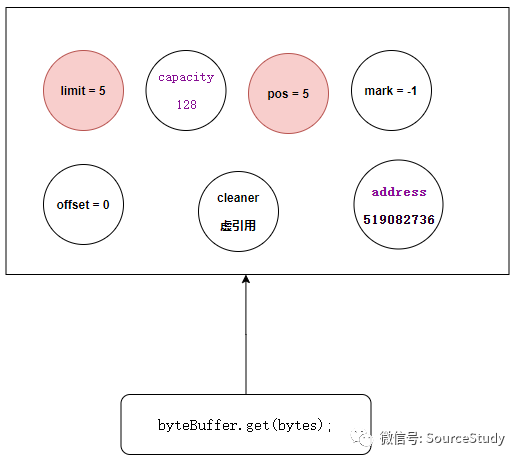
get方法
byte[] bytes = new byte[5];
byteBuffer.get(bytes);
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
// bytes 0 5
public ByteBuffer get(byte[] dst, int offset, int length) {
if (((long)length << 0) > Bits.JNI_COPY_TO_ARRAY_THRESHOLD) {
checkBounds(offset, length, dst.length);
//获取当前的读指针 0
int pos = position();
//获取当前的limit
int lim = limit();
//判断是否超过界限
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
if (length > rem) {
throw new BufferUnderflowException();
}
//关键方法 将物理内存中的数据复制到JVM内存中来
Bits.copyToArray(ix(pos), dst, arrayBaseOffset, (long)offset << 0, (long)length << 0);
//将读写指针切换至对应位置 5
position(pos + length);
} else {
super.get(dst, offset, length);
}
return this;
}
可以看出,当前的关键代码是 Bits.copyToArray(ix(pos), dst, arrayBaseOffset, (long)offset << 0, (long)length << 0); 我们分析一下
static void copyToArray(long srcAddr, Object dst, long dstBaseOffset, long dstPos, long length) {
//计算当前的偏移量
long offset = dstBaseOffset + dstPos;
while (length > 0) {
//最大拷贝长度是 1MB 高于1MB的下次循环再次拷贝
long size = (length > UNSAFE_COPY_THRESHOLD) ? UNSAFE_COPY_THRESHOLD : length;
// 将数据拷贝回指定的数组中
// 源数据 数据所在的内存地址 目标位置 偏移量 拷贝的长度
unsafe.copyMemory(null, srcAddr, dst, offset, size);
//计算剩余的数据长度
length -= size;
//计算下次拷贝的地址的偏移量
srcAddr += size;
//计算下次复制的偏移量
offset += size;
}
}
当前数据的数据结构为:
堆外缓冲区比较重要的几个点:
缓冲区的创建(构造函数) 数据的存储(put方法) 数据的获取(get方法) 堆外内存的释放
都已经介绍完毕,其他类似的API譬如 clear、mark、reset、rewind 再上面的外内内存的介绍中都已经介绍完毕了,逻辑都一样,感兴趣的小伙伴可以自己追一下源码!
对于NIO的学习,这个缓冲区是必不可少的一节课!务必要搞明白呀!
才疏学浅,如果文章中理解有误,欢迎大佬们私聊指正!欢迎关注作者的公众号,一起进步,一起学习!
❤️「转发」和「在看」,是对我最大的支持❤️