
MySQL与redis缓存的同步方案
点击上方 Java学习之道,选择 设为星标
来源: zhangshengrong.com/p/8AaYmZmda2/
作者:张生荣
本文介绍MySQL与Redis缓存的同步的两种方案
-
方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现 -
方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis
Part1方案1(UDF)
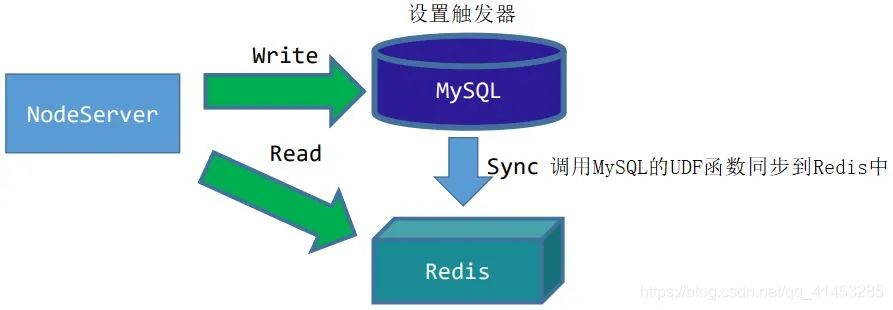
场景分析: 当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找
过程大致如下:
在MySQL中对要操作的数据设置触发器Trigger,监听操作
客户端(NodeServer)向MySQL中写入数据时,触发器会被触发,触发之后调用MySQL的UDF函数
UDF函数可以把数据写入到Redis中,从而达到同步的效果
方案分析:
-
这种方案适合于读多写少,并且不存并发写的场景 -
因为MySQL触发器本身就会造成效率的降低,如果一个表经常被操作,这种方案显示是不合适的
Part2演示案例
下面是MySQL的表

下面是UDF的解析代码

定义对应的触发器


Part3方案2(解析binlog)
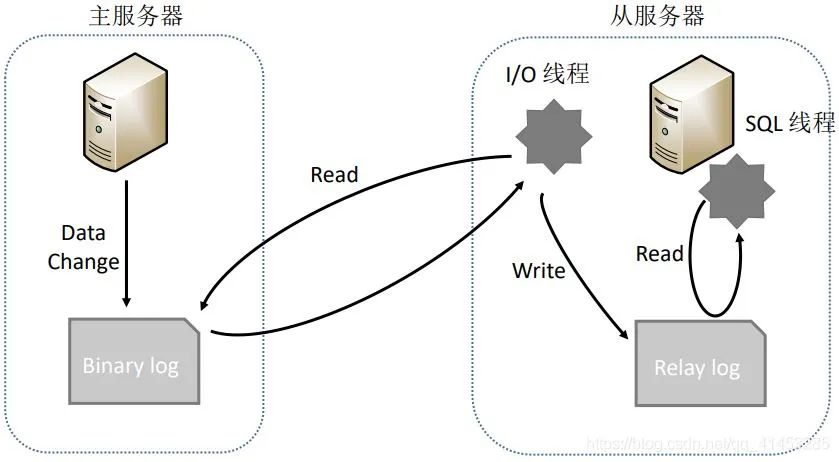
在介绍方案2之前我们先来介绍一下MySQL复制的原理,如下图所示:
-
主服务器操作数据,并将数据写入Bin log -
从服务器调用I/O线程读取主服务器的Bin log,并且写入到自己的Relay log中,再调用SQL线程从Relay log中解析数据,从而同步到自己的数据库中
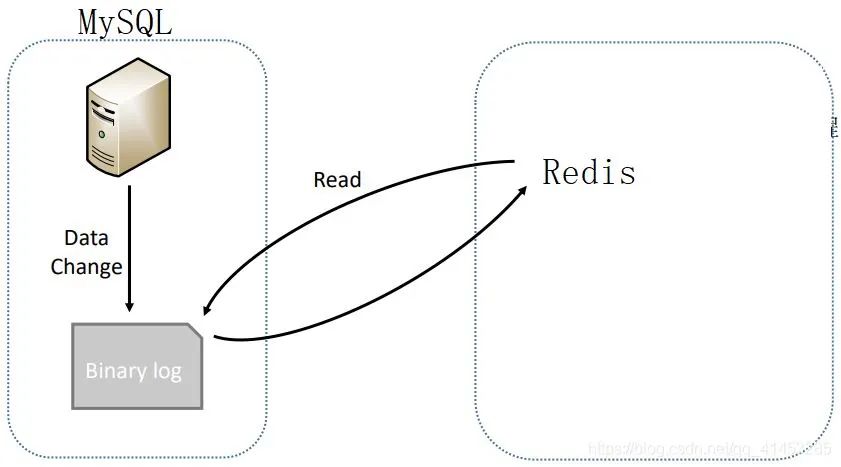
方案2就是:
-
上面MySQL的整个复制流程可以总结为一句话,那就是:从服务器读取主服务器Bin log中的数据,从而同步到自己的数据库中 -
我们方案2也是如此,就是在概念上把主服务器改为MySQL,把从服务器改为Redis而已(如下图所示),当MySQL中有数据写入时,我们就解析MySQL的Bin log,然后将解析出来的数据写入到Redis中,从而达到同步的效果
例如下面是一个云数据库实例分析:
云数据库与本地数据库是主从关系。云数据库作为主数据库主要提供写,本地数据库作为从数据库从主数据库中读取数据
本地数据库读取到数据之后,解析Bin log,然后将数据写入写入同步到Redis中,然后客户端从Redis读数据
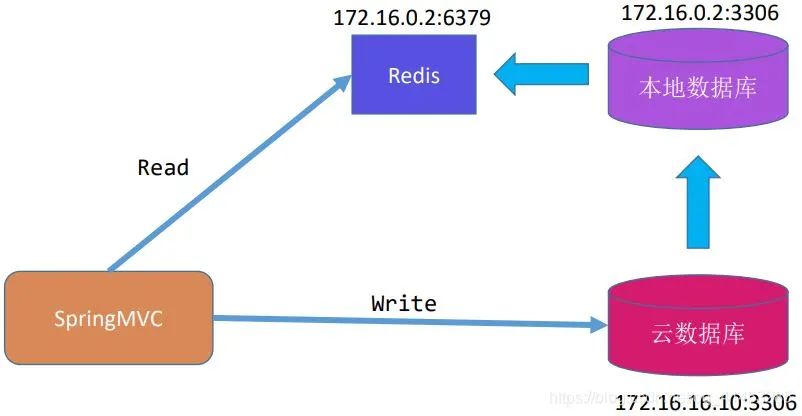
这个技术方案的难点就在于: 如何解析MySQL的Bin Log。但是这需要对binlog文件以及MySQL有非常深入的理解,同时由于binlog存在Statement/Row/Mixedlevel多种形式,分析binlog实现同步的工作量是非常大的
Canal开源技术
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)
开源参考地址有:https://github.com/liukelin/canal_mysql_nosql_sync
工作原理(模仿MySQL复制):
-
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议 -
mysql master收到dump请求,开始推送binary log给slave(也就是canal) -
canal解析binary log对象(原始为byte流)

架构:
server代表一个canal运行实例,对应于一个jvm
instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
-
eventParser (数据源接入,模拟slave协议和master进行交互,协议解析) -
eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作) -
eventStore (数据存储) -
metaManager (增量订阅&消费信息管理器)

大致的解析过程如下:
-
parse解析MySQL的Bin log,然后将数据放入到sink中 -
sink对数据进行过滤,加工,分发 -
store从sink中读取解析好的数据存储起来 -
然后自己用设计代码将store中的数据同步写入Redis中就可以了 -
其中parse/sink是框架封装好的,我们做的是store的数据读取那一步

更多关于Cancl可以百度搜索
下面是运行拓扑图

MySQL表的同步,采用责任链模式,每张表对应一个Filter。例如zvsync中要用到的类设计如下:
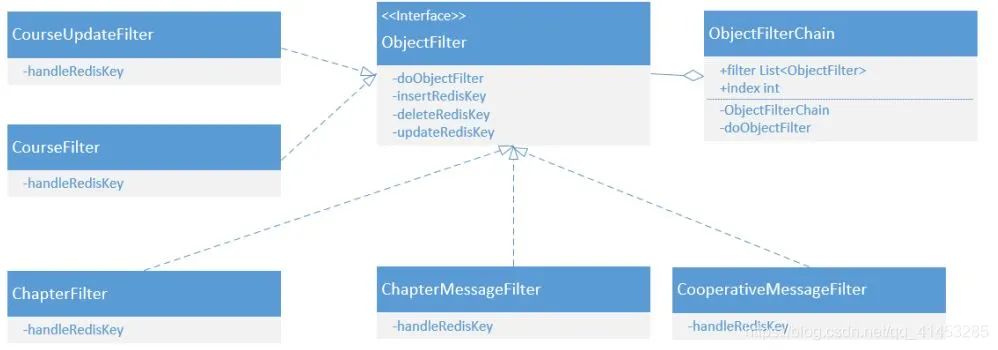
下面是具体化的zvsync中要用到的类,每当新增或者删除表时,直接进行增删就可以了

Part4附加
本文上面所介绍的都是从MySQL中同步到缓存中。但是在实际开发中可能有人会用下面的方案:
-
客户端有数据来了之后,先将其保存到Redis中,然后再同步到MySQL中 -
这种方案本身也是不安全/不可靠的,因此如果Redis存在短暂的宕机或失效,那么会丢失数据

到此这篇关于浅谈MySQL与redis缓存的同步方案的文章就介绍到这了
-  | 更多精彩文章 -
| 更多精彩文章 -

▽加我微信,交个朋友 长按/扫码添加↑↑↑

