
3毫秒极速识别,一个4.1k Satr的开源项目
不点蓝字关注,我们哪来故事?
人脸、车辆、人体属性、卡证、交通标识等经典图像识别能力,在我们当前数字化工作及生活中发挥着极其重要的作用。业内也不乏顶尖公司提供的可直接调用的API、SDK,但这些往往面临着定制化场景泛化效果不好、价格昂贵、黑盒可控性低、技术壁垒难以形成多诸多痛点。

话不多说,赶紧送上传送门,识货的小伙伴赶紧尝试一下吧!

图2 9大场景模型效果示意图
1
亮点一
完美平衡精度与速度
从大名鼎鼎的Resnet50到如今火热的Swin-Transformer,模型精度不断被刷新,但是预测效率并不高。即使是Swin-Transformer最小的模型,在CPU上的预测速度也超过100ms,远远无法满足产业实时预测的需求。
而使用MobileNet系列等轻量化模型可以保证较高的预测效率,在CPU上预测一张图像大约3ms,但是模型精度往往和大模型有很大差距。
PaddleClas推出的超轻量图像分类方案(Practical Ultra Light Classification,简称PULC),就完美解决上述产业落地中算法精度和速度难以平衡的痛点。
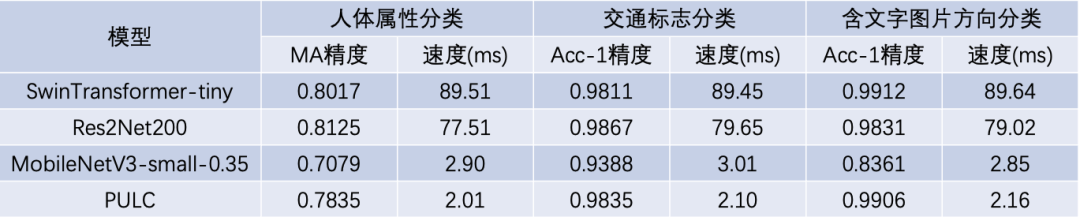
表1 不同模型精度速度结果对比
如图所示,它的精度与Swin-Transformer等大模型比肩,预测速度却可以快30倍以上,在CPU上的推理时长仅需2ms!
2
亮点二
易用性极强
PULC方案不仅完美地平衡了精度与速度,还充分考虑了产业实践过程中需要定制化的对算法快速迭代的需求,只需一行命令,就可完成模型训练。
与此同时,PaddleClas 团队还发布了包括人、车、OCR在内的9大场景模型,仅需2步就能实现业务 POC 效果验证,训练、推理、部署一条龙,真正实现“开箱即用”。

不仅如此,项目还匹配了详细的中文使用文档及产业实践范例教程。
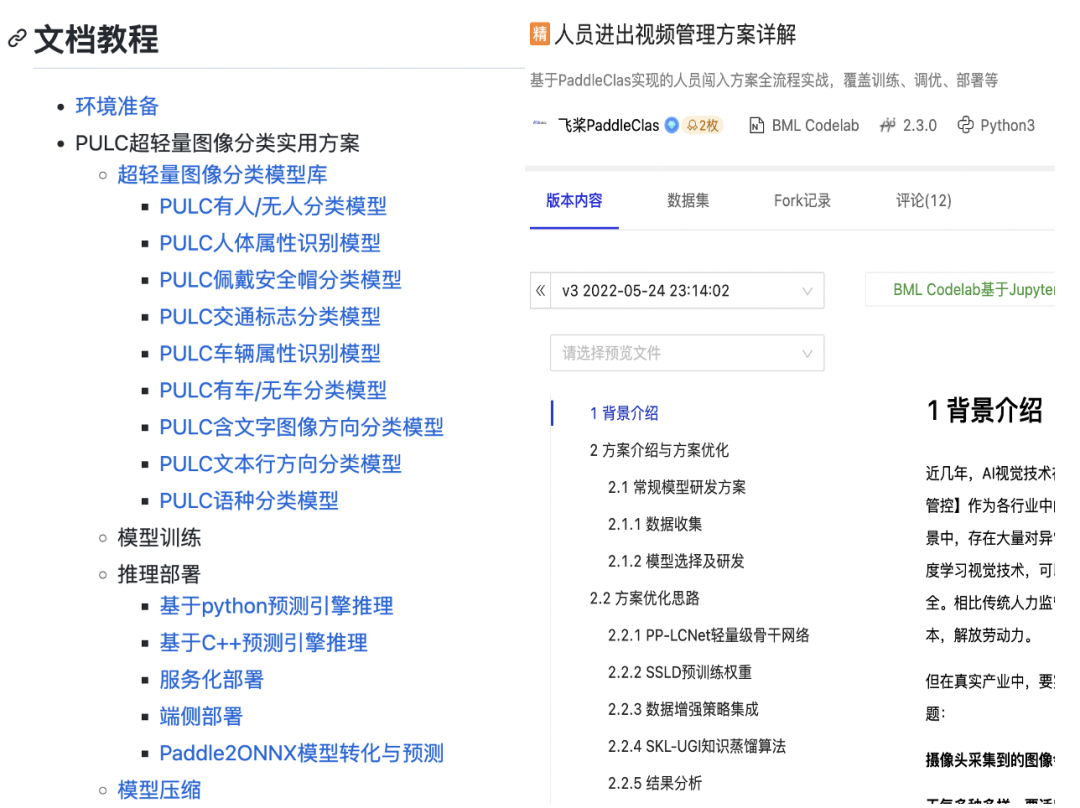
图3 使用文档及范例示意图
3
亮点三
集成超多硬核技术
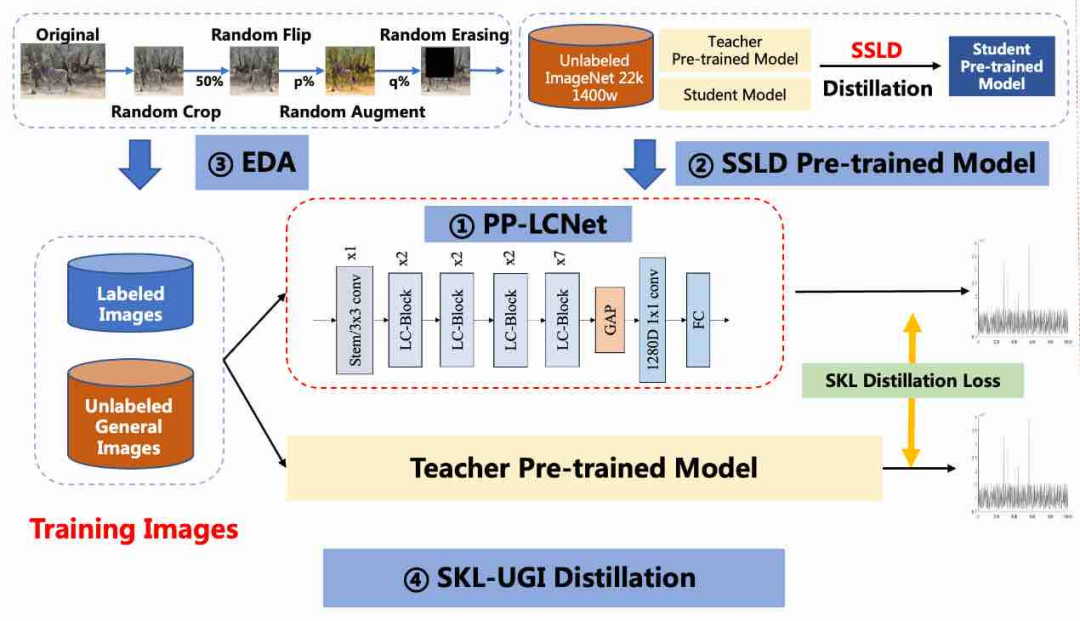
图4 超轻量图像分类方案(PULC)示意图
PP-LCNet轻量级骨干网络
PP-LCNet作为针对CPU量身打造的骨干网络模型,在速度、精度方面均远超如MobileNetV3等同体量算法,多个场景模型优化后,速度较SwinTransformer的模型快30倍以上,精度较MobileNetV3_small_0.35x高18个点。
SSLD预训练权重
SSLD半监督蒸馏算法可以使小模型学习到大模型的特征和ImageNet22k无标签大规模数据的知识。在训练小模型时,使用SSLD预训练权重作为模型的初始化参数,可以使不同场景的应用分类模型获得1-2.5个点的精度提升。
数据增强策略集成
该方案融合了图像变换、图像裁剪和图像混叠3种数据增强方法,并支持自定义调整触发概率,能使模型的泛化能力大大增强,提升模型在实际场景中的性能。模型可以在上一步的基础上,精度再提升1个点左右。
SKL-UGI知识蒸馏算法
4
服务真实场景需求
20种产业算法落地方案
不仅如此,PaddleClas团队考虑到真实产业应用面对的各种软硬件环境和不同的场景需求,在提供PULC方案的同时,还提供了包括3种训练方式、5种训练环境、3种模型压缩策略和9种推理部署方式在内的20种产业算法落地方案:

表2 PaddleClas训练推理部署功能支持列表
其中值得高度关注的有:
01 分布式训练
飞桨分布式训练架构具备4D混合并行、端到端自适应分布式训练等多项特色技术。在PP-LCNet训练中,4机8卡相较于单机8卡加速比达到3.48倍,加速效率87%,精度无损。
02 模型压缩
飞桨模型压缩工具PaddleSlim功能完备,覆盖模型裁剪、量化、蒸馏和NAS。图像分类模型经过量化裁剪后,移动端平均预测耗时减少24%。
03 移动端/边缘端部署
飞桨轻量化推理引擎Paddle Lite适配了20+ AI 加速芯片,可以快速实现图像分类模型在移动设备、嵌入式设备和IOT设备等高效设备的部署。
END
若觉得文章对你有帮助,随手转发分享,也是我们继续更新的动力。
长按二维码,扫扫关注哦
✬「C语言中文网」官方公众号,关注手机阅读教程 ✬