
使用 kube-vip 搭建高可用 Kubernetes 集群
kube-vip 可以在你的控制平面节点上提供一个 Kubernetes 原生的 HA 负载均衡,我们不需要再在外部设置 HAProxy 和 Keepalived 来实现集群的高可用了。
kube-vip 是一个为 Kubernetes 集群内部和外部提供高可用和负载均衡的开源项目,在 Vmware 的 Tanzu 项目中已经使用 kube-vip 替换了用于 vSphere 部署的 HAProxy 负载均衡器,本文我们将先来了解 kube-vip 如何用于 Kubernetes 控制平面的高可用和负载均衡功能。
特点
Kube-Vip 最初是为 Kubernetes 控制平面提供 HA 解决方案而创建的,随着时间的推移,它已经发展为将相同的功能合并到 Kubernetes 的 LoadBalancer 类型的 Service 中了。
VIP 地址可以是 IPv4 或 IPv6 带有 ARP(第2层)或 BGP(第3层)的控制平面 使用领导选举或 raft 控制平面 带有 kubeadm(静态 Pod)的控制平面 HA 带有 K3s/和其他(DaemonSets)的控制平面 HA 使用 ARP 领导者选举的 Service LoadBalancer(第 2 层) 通过 BGP 使用多个节点的 Service LoadBalancer 每个命名空间或全局的 Service LoadBalancer 地址池 Service LoadBalancer 地址通过 UPNP 暴露给网关
HAProxy 和 kube-vip 的 HA 集群
在以前我们在私有环境下创建 Kubernetes 集群时,我们需要准备一个硬件/软件的负载均衡器来创建多控制面集群,更多的情况下我们会选择使用 HAProxy + Keepalived 来实现这个功能。一般情况下我们创建2个负载均衡器的虚拟机,然后分配一个 VIP,然后使用 VIP 为负载均衡器提供服务,通过 VIP 将流量重定向到后端的某个 Kubernetes 控制器平面节点上。
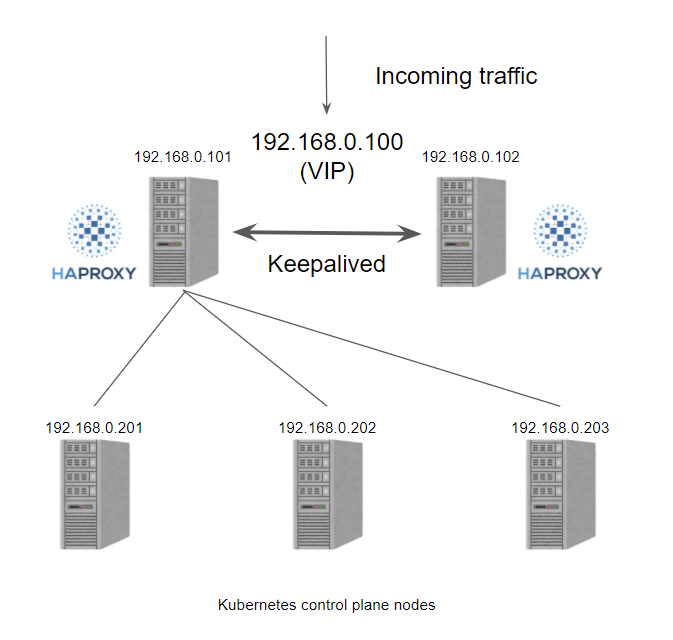
接下来我们再来看看如果我们使用 kube-vip 的话会怎样呢?
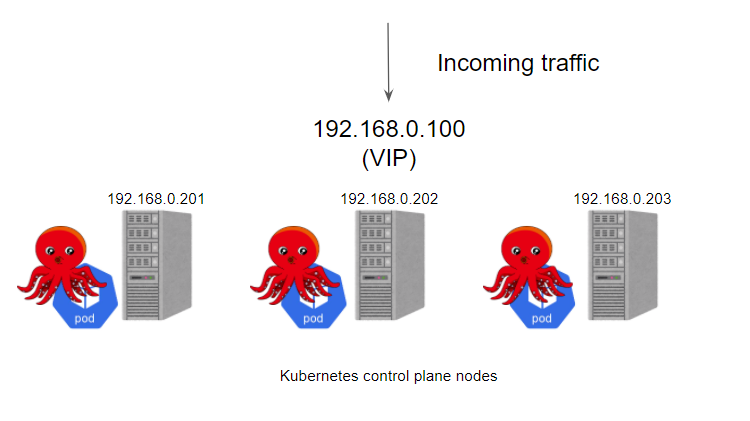
kube-vip 可以通过静态 pod 运行在控制平面节点上,这些 pod 通过ARP 对话来识别每个节点上的其他主机,所以需要在 hosts 文件中设置每个节点的 IP 地址,我们可以选择 BGP 或 ARP 来设置负载平衡器,这与 Metal LB 比较类似。这里我们没有 BGP 服务,只是想快速测试一下,所以这里我们使用 ARP 与静态 pod 的方式。
kube-vip 架构
kube-vip 有许多功能设计选择提供高可用性或网络功能,作为VIP/负载平衡解决方案的一部分。
Cluster
kube-vip 建立了一个多节点或多模块的集群来提供高可用性。在 ARP 模式下,会选出一个领导者,这个节点将继承虚拟 IP 并成为集群内负载均衡的领导者,而在 BGP 模式下,所有节点都会通知 VIP 地址。
当使用 ARP 或 layer2 时,它将使用领导者选举,当然也可以使用 raft 集群技术,但这种方法在很大程度上已经被领导者选举所取代,特别是在集群中运行时。
虚拟IP
集群中的领导者将分配 vip,并将其绑定到配置中声明的选定接口上。当领导者改变时,它将首先撤销 vip,或者在失败的情况下,vip 将直接由下一个当选的领导者分配。
当 vip 从一个主机移动到另一个主机时,任何使用 vip 的主机将保留以前的 vip <-> MAC 地址映射,直到 ARP 过期(通常是30秒)并检索到一个新的 vip <-> MAC 映射,这可以通过使用无偿的 ARP 广播来优化。
ARP
kube-vip可以被配置为广播一个无偿的 arp(可选),通常会立即通知所有本地主机 vip <-> MAC 地址映射已经改变。
下面我们可以看到,当 ARP 广播被接收时,故障转移通常在几秒钟内完成。
64 bytes from 192.168.0.75: icmp_seq=146 ttl=64 time=0.258 ms
64 bytes from 192.168.0.75: icmp_seq=147 ttl=64 time=0.240 ms
92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75)
Vr HL TOS Len ID Flg off TTL Pro cks Src Dst
4 5 00 0054 bc98 0 0000 3f 01 3d16 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 148
92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75)
Vr HL TOS Len ID Flg off TTL Pro cks Src Dst
4 5 00 0054 75ff 0 0000 3f 01 83af 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 149
92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75)
Vr HL TOS Len ID Flg off TTL Pro cks Src Dst
4 5 00 0054 2890 0 0000 3f 01 d11e 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 150
64 bytes from 192.168.0.75: icmp_seq=151 ttl=64 time=0.245 ms
使用 kube-vip
接下来我们来使用 kube-vip 搭建一个高可用的 Kubernetes 集群。先准备6个节点:
3个控制平面节点 3个 worker 节点
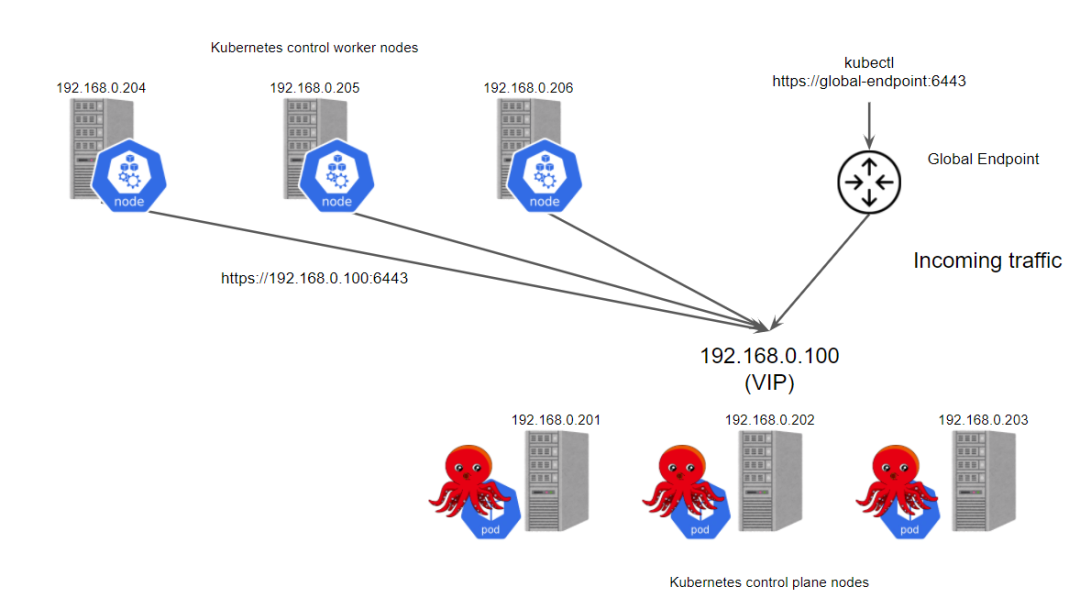
首先在宿主机上面安装相关依赖,包括 kubeadm、kubelet、kubectl 以及一个容器运行时,这里我们使用的是 containerd。
获取 kube-vip 的 docker 镜像,并在 /etc/kuberentes/manifests 中设置静态 pod 的 yaml 资源清单文件,这样 Kubernetes 就会自动在每个控制平面节点上部署 kube-vip 的 pod 了。
# 设置VIP地址
export VIP=192.168.0.100
export INTERFACE=eth0
ctr image pull docker.io/plndr/kube-vip:0.3.1
ctr run --rm --net-host docker.io/plndr/kube-vip:0.3.1 vip \
/kube-vip manifest pod \
--interface $INTERFACE \
--vip $VIP \
--controlplane \
--services \
--arp \
--leaderElection | tee /etc/kubernetes/manifests/kube-vip.yaml
接下来就可以配置 kubeadm 了,如下所示:
cat > ~/init_kubelet.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta2
kind: InitConfiguration
bootstrapTokens:
- token: "9a08jv.c0izixklcxtmnze7"
description: "kubeadm bootstrap token"
ttl: "24h"
nodeRegistration:
criSocket: "/var/run/containerd/containerd.sock"
---
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
controlPlaneEndpoint: "192.168.0.100:6443"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: "systemd"
protectKernelDefaults: true
EOF
kubeadm init --config init_kubelet.yaml --upload-certs
然后安装 CNI,比如我们选择使用 Cilium。
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
helm repo add cilium https://helm.cilium.io/
helm install cilium cilium/cilium --version 1.9.4 \
--namespace kube-system
在第一个控制平面节点准备好后,让其他节点加入你的集群。对于其他控制平面节点,运行如下命令:
kubeadm join 192.168.0.100:6443 --token hash.hash\
--discovery-token-ca-cert-hash sha256:hash \
--control-plane --certificate-key key
对于工作节点,运行类似命令:
kubeadm join 192.168.0.100:6443 --token hash.hash\
--discovery-token-ca-cert-hash sha256:hash
正常执行完成后集群就可以启动起来了:
# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master-0 Ready control-plane,master 121m v1.20.2 192.168.0.201 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
k8s-master-1 Ready control-plane,master 114m v1.20.2 192.168.0.202 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
k8s-master-2 Ready control-plane,master 113m v1.20.2 192.168.0.203 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
k8s-worker-0 Ready <none> 114m v1.20.2 192.168.0.204 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
k8s-worker-1 Ready <none> 114m v1.20.2 192.168.0.205 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
k8s-worker-2 Ready <none> 112m v1.20.2 192.168.0.206 <none> Ubuntu 20.04.2 LTS 5.4.0-45-generic containerd://1.4.3
现在可以看到我们的控制面的端点是 192.168.0.100,没有其他额外的节点,是不是非常方便。
参考文档:https://inductor.medium.com/say-good-bye-to-haproxy-and-keepalived-with-kube-vip-on-your-ha-k8s-control-plane-bb7237eca9fc