
MQ消息中间件,面试能问写什么?
浪尖聊大数据
共 13249字,需浏览 27分钟
·
2021-05-18 21:30
来自:blog.csdn.net/qq_29676623/article/details/85108070
1. 为什么使用消息队列?
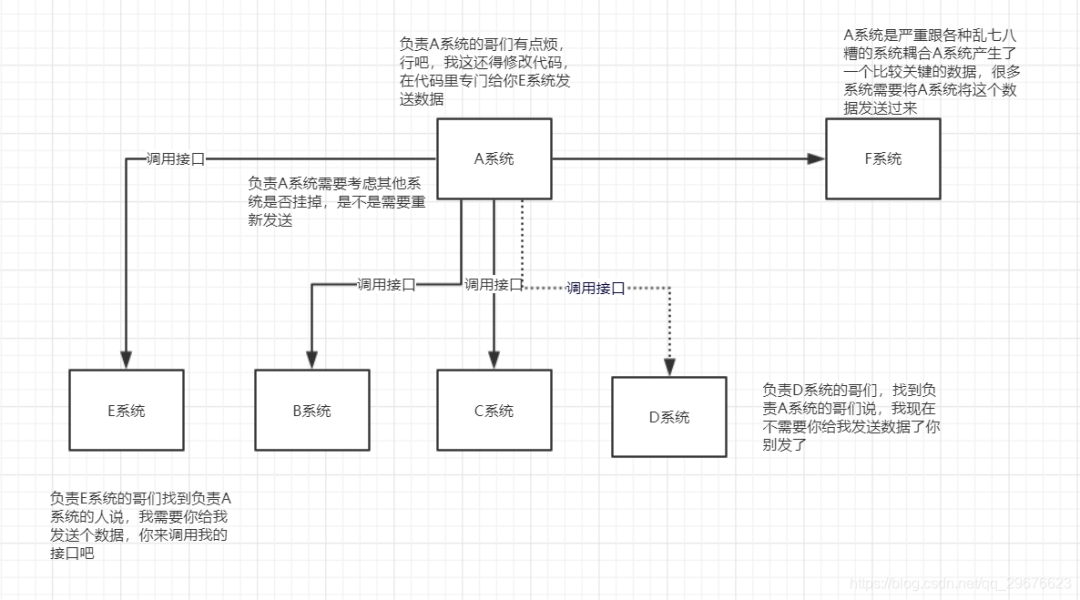
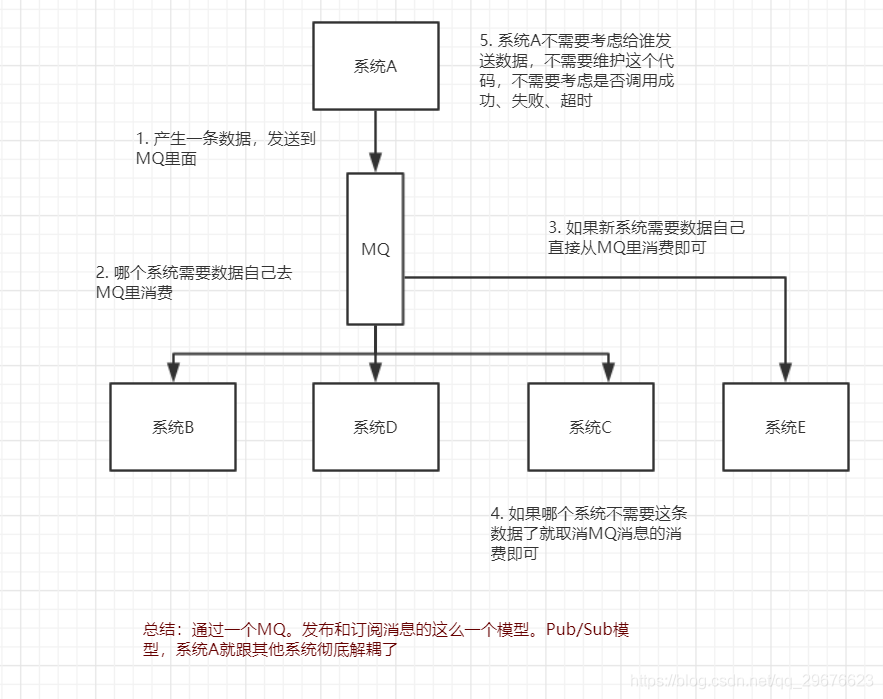
解耦
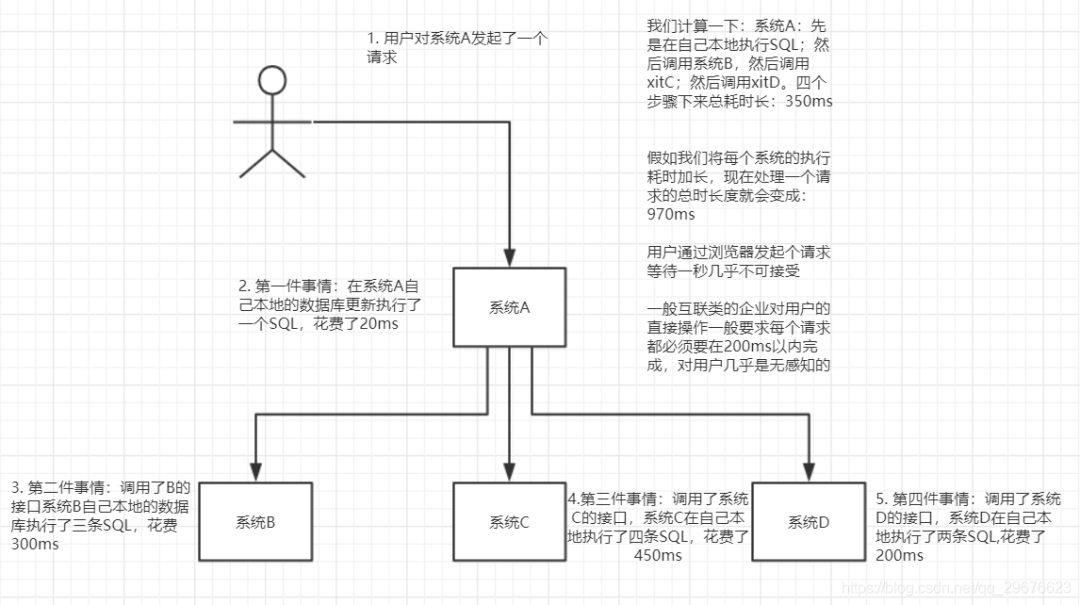
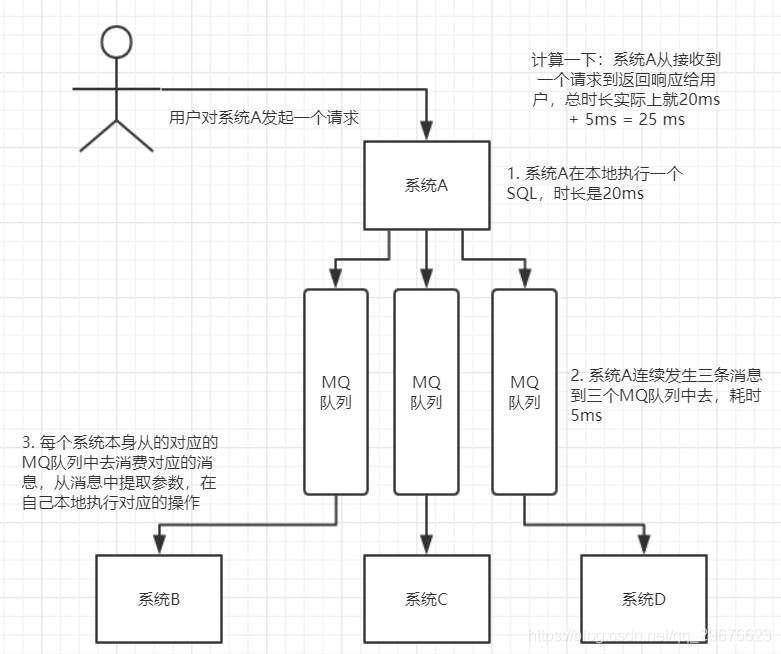
异步
削峰

2. 消息队列的有点和缺点?
3. kafka、activemq、rabbitmq、rocketmq都有什么优缺点?
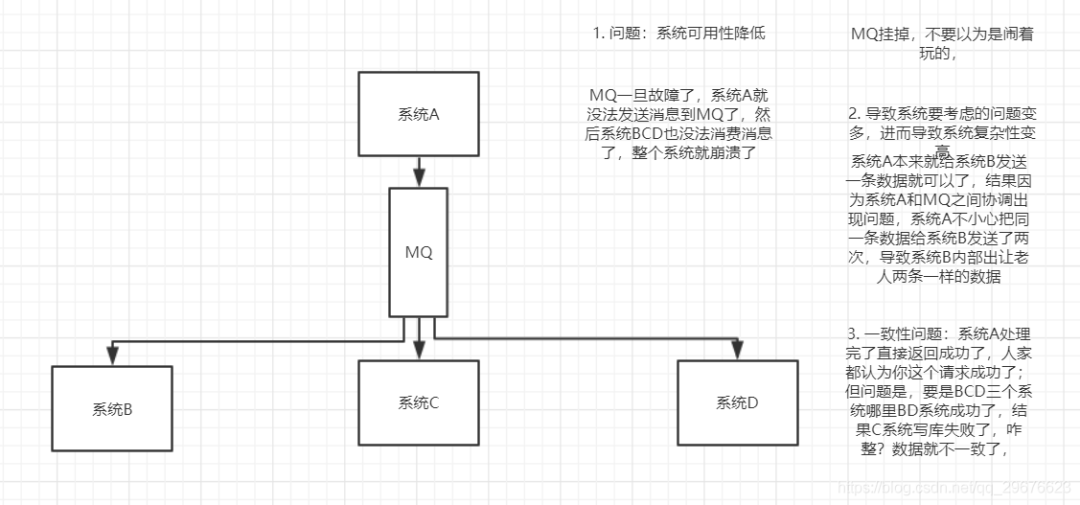
1. 引入消息队列之后如何保证其高可用性?
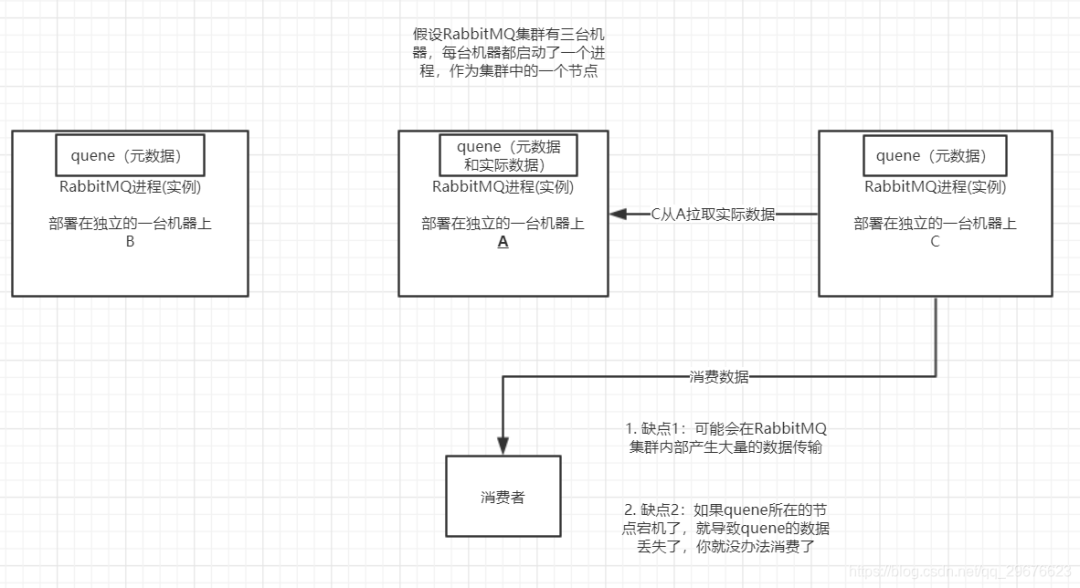
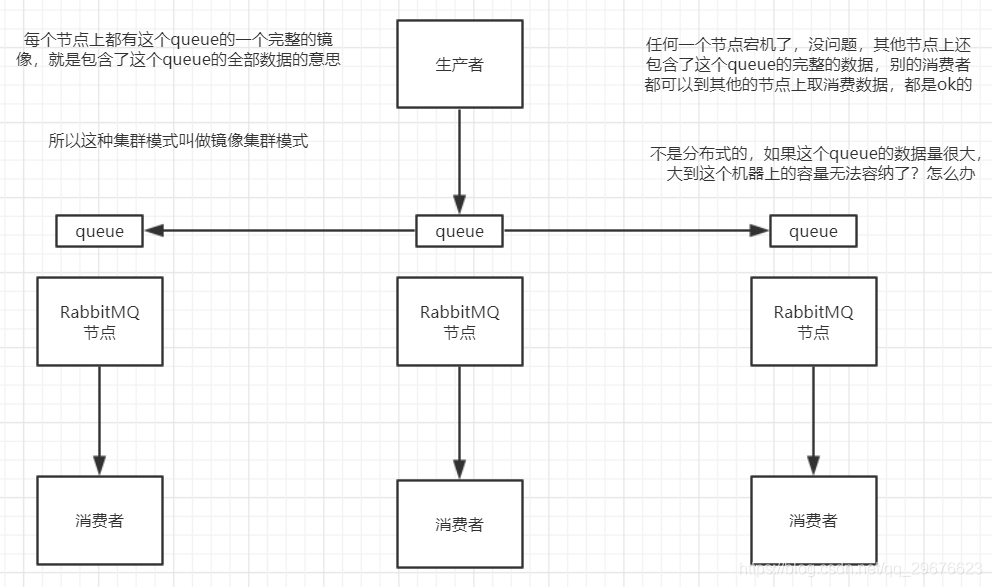
(1)RabbitMQ的高可用性
(2)kafka的高可用性

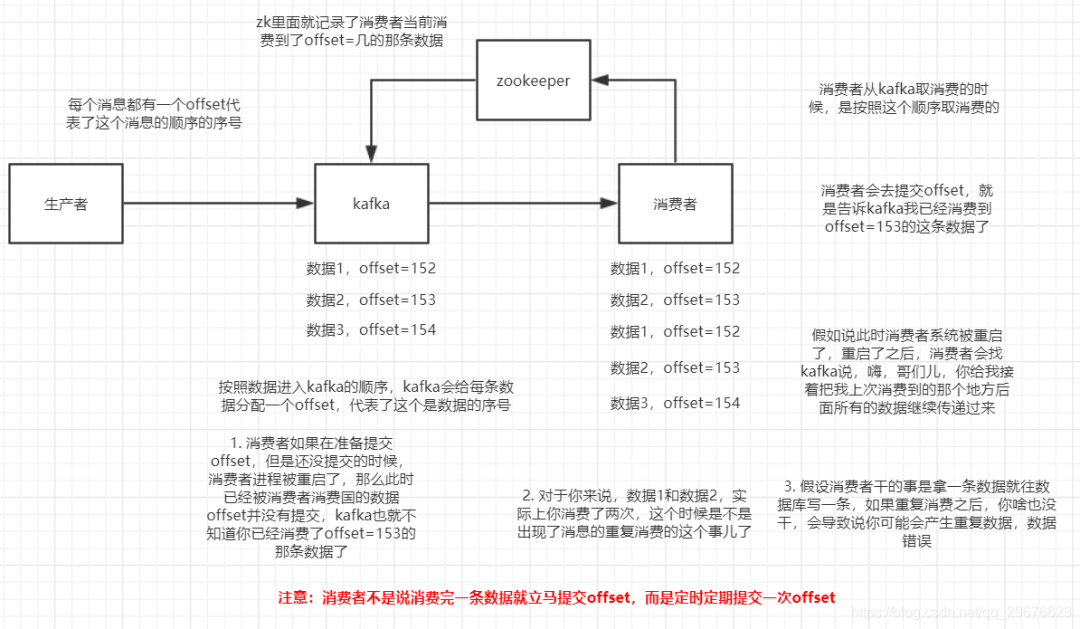
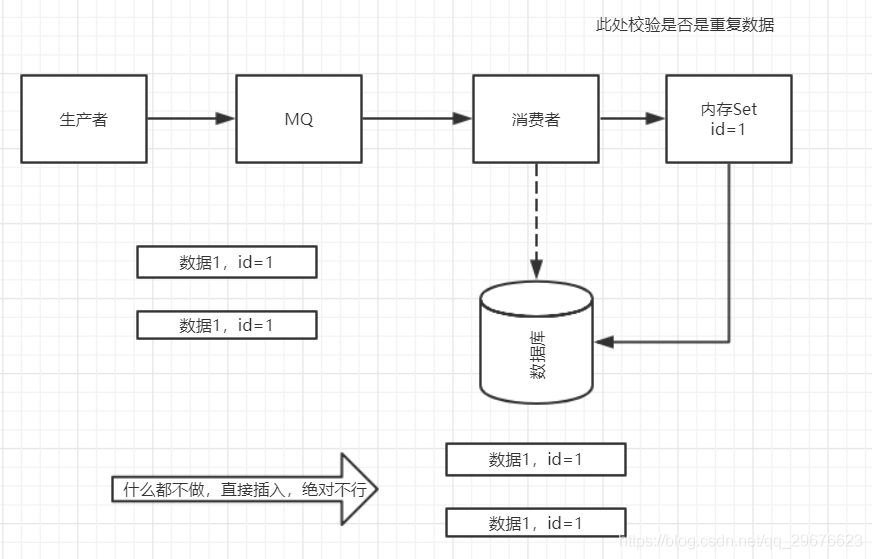
2. 如何保证消息不被重复消费(如何保证消息消费时的幂等性)?
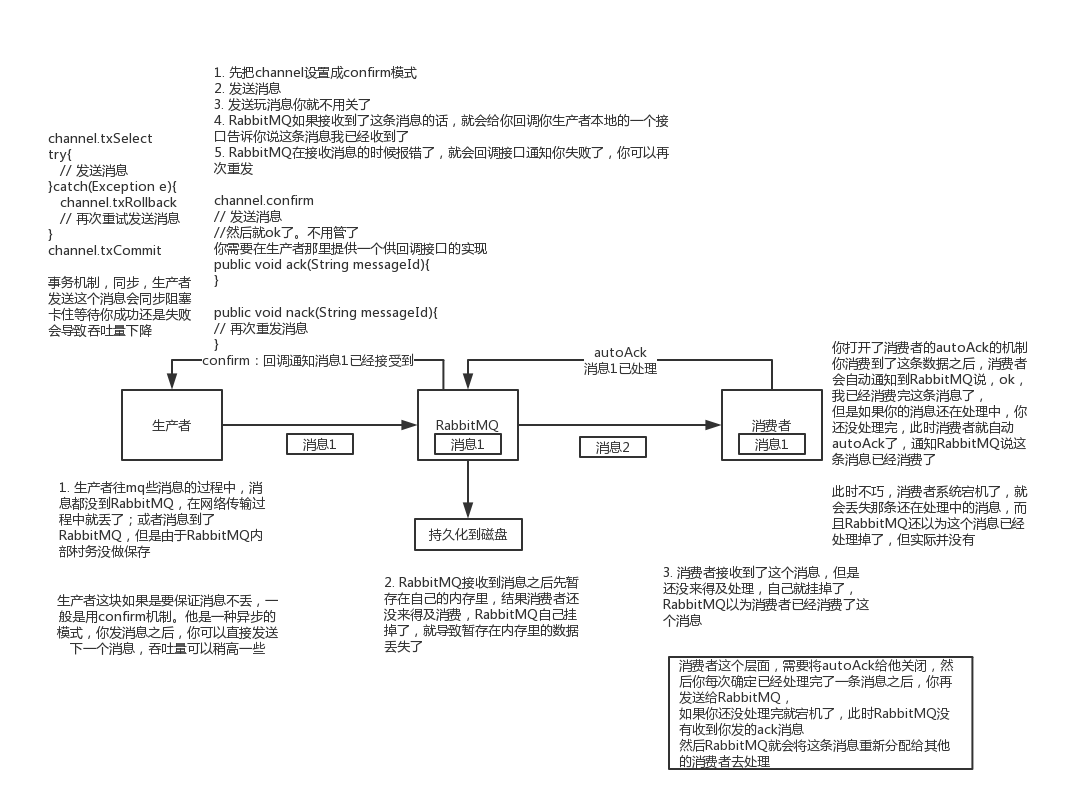
3. 如何保证消息的可靠传输(如何处理消息丢失的问题)?
(1)rabbitmq
(2)kafka
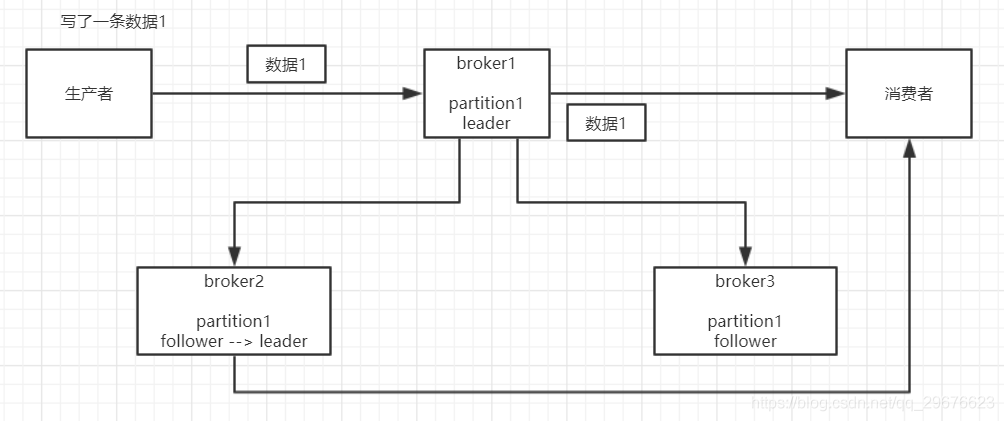
给这个topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了
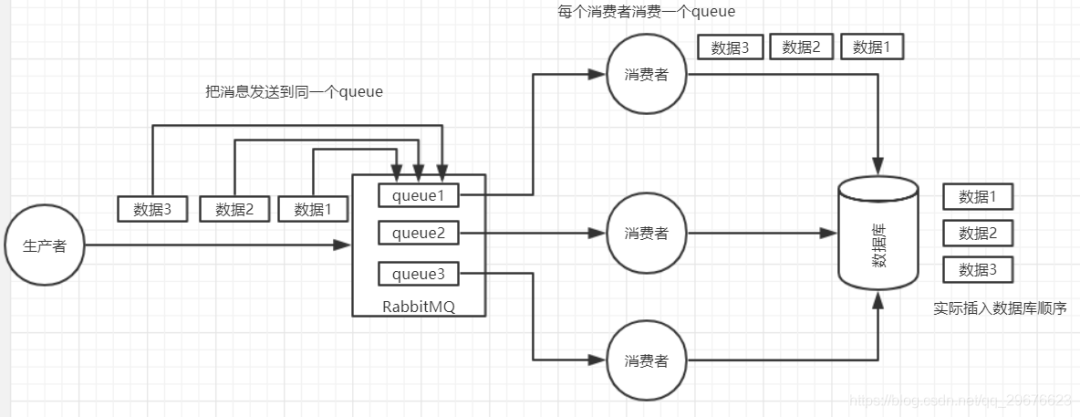
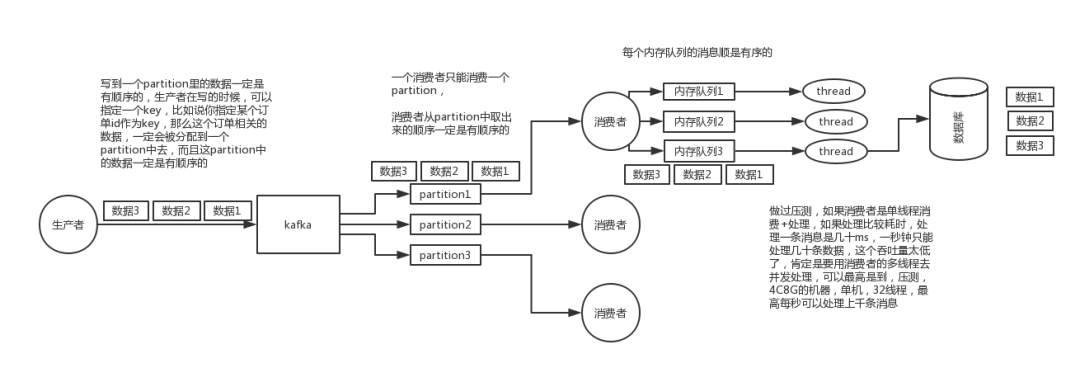
1. 如何保证消息的顺序性?
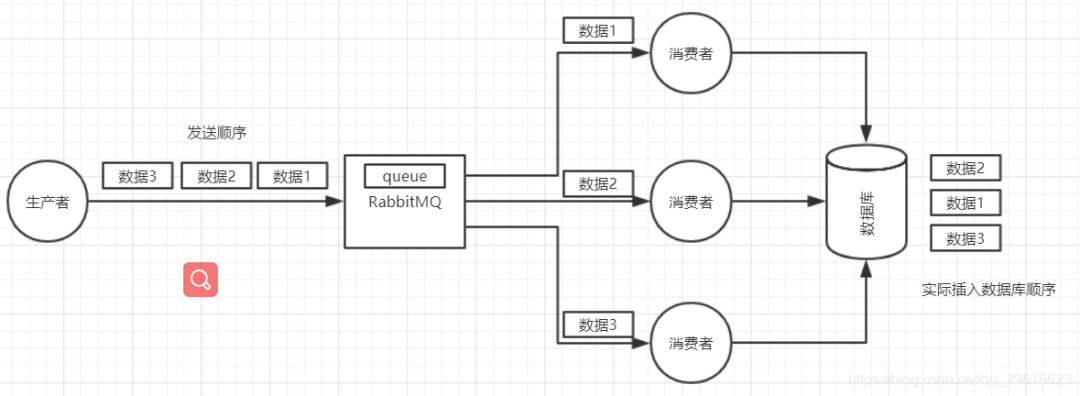
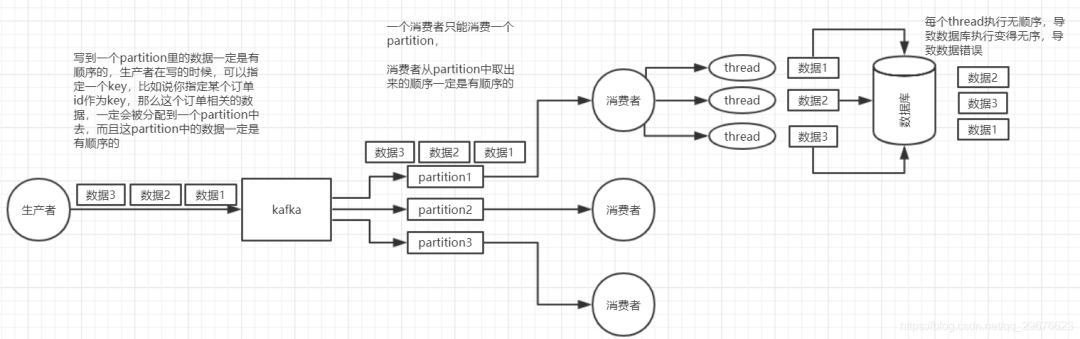
那如何保证消息的顺序性呢?简单简单
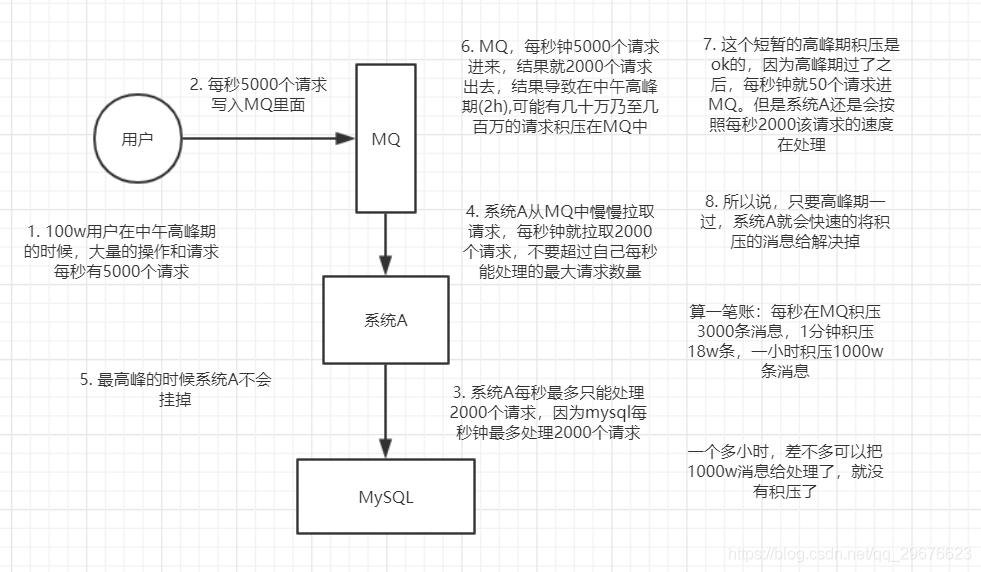
(1)大量消息在mq里积压了几个小时了还没解决
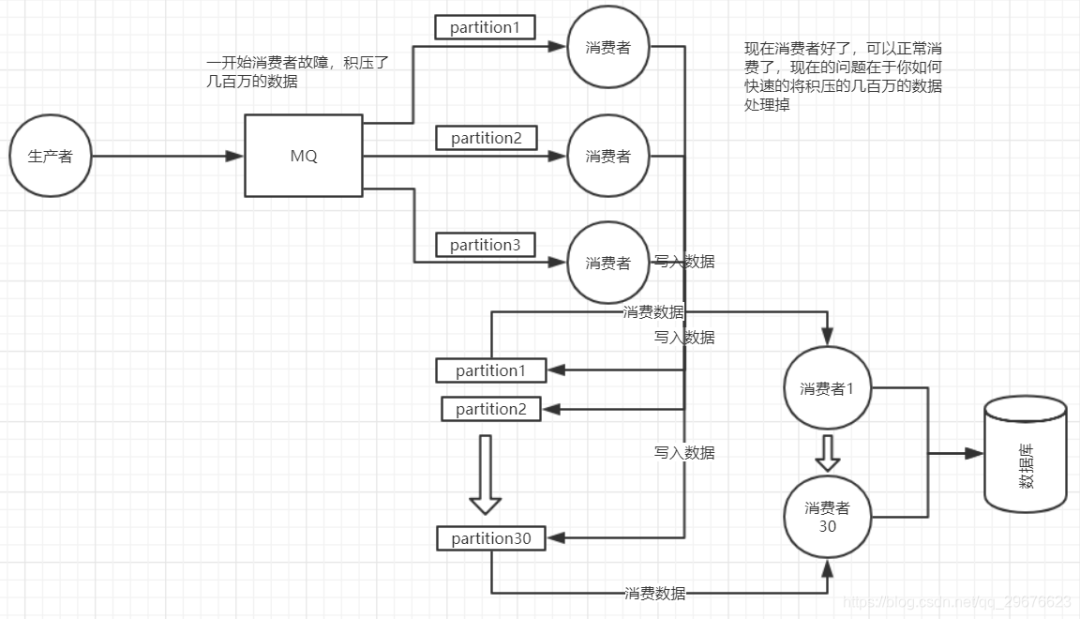
(2)这里我们假设再来第二个坑
(3)然后我们再来假设第三个坑
(4)能不能支持数据0丢失啊?可以的,参考我们之前说的那个kafka数据零丢失方案
评论