
NeurIPS 2021 | 医学图像GAN生成,在Noisy Data上训练出超越监督学习的模型
共 4366字,需浏览 9分钟
·
2021-10-25 13:23
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
作者:藏云阁主 | 转自知乎 侵删
https://zhuanlan.zhihu.com/p/415238682
介绍一篇Manteia算法组的NeurIPS 2021 Spotlight文章。文章讨论的核心问题是,在医学图像生成领域,限制模型表现进一步提升的原因是什么?用什么方法可以打破该限制?我们希望通过这篇文章,给大家带来医学图像生成的新范式。

Introduction
Pix2Pix[1]和Cycle-consistency[2]是医学图像生成领域的两大主流模式。
对于Pix2Pix而言,它对训练数据的要求是比较严格的,必须是成对且像素级对齐的,当数据对齐质量下降时,模型的效果就会严重衰退甚至导致整个模式的崩溃,还有一个重要的事实是,像素级对齐的医学影像数据集很难获取,这是因为通常两种模态的影像不是同时采集的,在此期间患者的呼吸运动、身体解剖结构的变化等都会导致两组图像的misalignment。这一点我们将在后文的实验结果中展示。
另一种模式,Cycle-consistency对于数据质量的要求不如Pix2Pix那样严格,它可以接受source和target有misalignment的误差,但它也没有对这种misalignment进行处理,导致生成效果也没有达到最优,并且训练也非常不稳定。
立足于以上几个事实,我们提出了一种新的医学图像生成模式RegGAN。基于"loss-correction"[3]理论,未严格对齐的数据可以当作是有噪声的标签,而在生成器上使用一个额外的配准网络可以自适应地拟合这种噪声分布。
如此简单的模式,只要任意地将其嵌入到目前SOTA的几种图像生成方法里,就能有效地提高它们的表现。使用了该模式后,即使是CycleGAN也能超越较新的NICEGAN,甚至网络参数量还更轻量。
RegGAN Explained
让我们来具体看一下Pix2Pix、Cycle-consistency和RegGAN各自的结构。其中,X为source domain,Y为target domain。
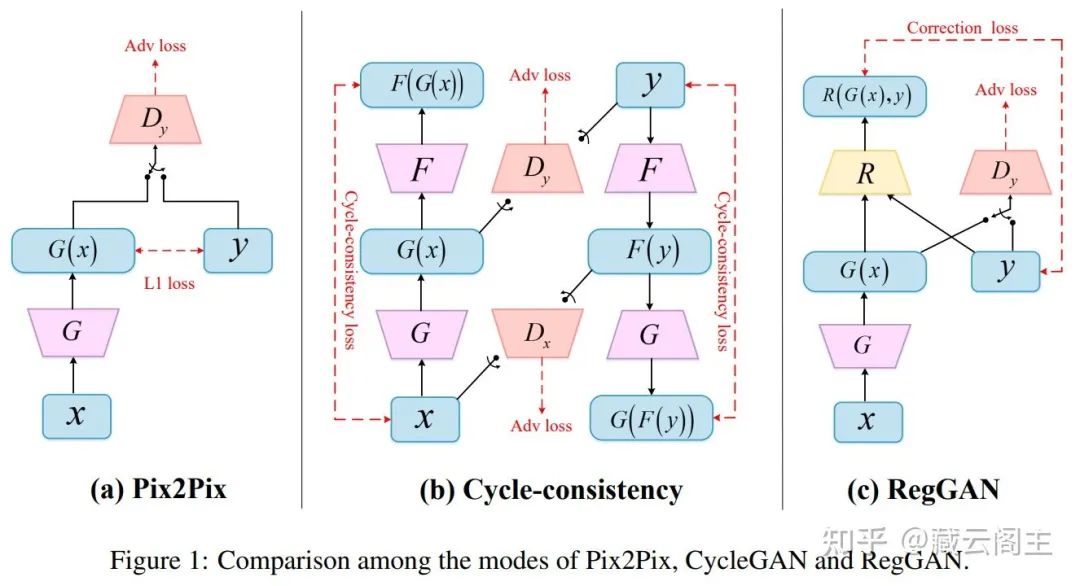
Pix2Pix是最像监督学习的一个模式,生成器G的loss来源主要有两个部分,一是生成图像G(x)与标签图像y的L1 loss,它的约束使得G(x)和y每一个像素点强度尽量一致,二是判别器D的Adv loss,它的约束要求G(x)能够骗过D,让D认为G(x)与y的图像强度分布是同一风格。
Cycle-consistency中有两个生成器G和F,以及两个D,G和F分别完成从X→Y和Y→X的生成,两个D则分别对这两个过程进行判别对抗,G和F的loss同样也有两个部分,一是由D传导过来的Adv loss,这部分的约束与Pix2Pix中相同,二是图像x本身与其依次经过G和F生成之后生成的图像F(G(x))之间的Cycle loss,该约束要求x与F(G(x))尽量相似。
要使Cycle loss最小,只需要x和F(G(x))之间相似就行,而对于G(x)则没有明确的约束。这就意味着Cycle-consistency的模式可能存在多解的情况[4]。例如,一个腹部的CT与MR配对的数据集,我们记CT为X,MR为Y,二者的空间位置并不是严格对齐的,这里我们可以假设的极端一些,假定CT中的body全都位于图像中心,而MR中的body相对于图像中心有上下左右四个方向各1cm的偏移。对于任意一张x,生成器G生成的G(x)就会有上下左右四个解,只要生成器F能够把任意空间位置的图像都转为中心对齐的图像F(y),就能够满足Cycle loss。当然,这里只描述了空间上的转换,风格上的转换我们假定两个生成器都能完成。
而Pix2Pix则没有这个问题,对于任意一张x,生成器生成的图像G(x)只能是唯一解才能让L1 loss最小,这种唯一性是包含了空间位置和风格的。也正是因为如此,数据的misalignment会很大程度上影响生成器的效果。
RegGAN的核心正是对空间位置和风格转换的解耦。生成器的loss来源有两部分,一是由判别器D传导的Adv loss,与之前的两个模式相同,二是将生成图像G(x)经过一个配准器R后得到的R(G(x), y)与标签图像y之间的Correction loss。之所以叫做Correction,是因为我们认为一对misaligned图像相当于是有噪声的标签,而这个噪声主要是由空间位置的不对齐带来的,而配准网络所做的事情就是消除空间位置带来的噪声。
L1 loss、Cycle loss、Correction loss这三者的形式均为L1 loss,但计算的对象是不同的。当然,也可以换成L2 loss或是其他形式的regression loss。
与我们的工作最接近的工作是Arar.M et al[5],他提出了一种用于自然图像多模态配准的方法,但是他们的工作聚焦于配准的效果而没有讨论这对于图像翻译的意义。而RegGAN的最大意义在于,证明了在医疗影像生成框架中使用配准网络能够带来显著的性能提升,这是一种全新的医疗影像生成模式。
Result
我们通过三个方面来评估RegGAN的效果:
证明RegGAN模式在多种图像生成方法中的可行性和优越性 (Exp. 1)
评价RegGAN对于噪声的敏感程度 (Exp. 2)
探索RegGAN在非配对数据上的可行性 (Exp. 3)
我们使用了BraTS 2018数据集来评估。BraTS 2018数据集是对齐程度较好的数据集,为了对比不同方法在misaligned数据上的表现,我们对训练数据增加了轻微的随机的空间变化,如旋转、缩放、平移等。下表为不同方法的具体表现。
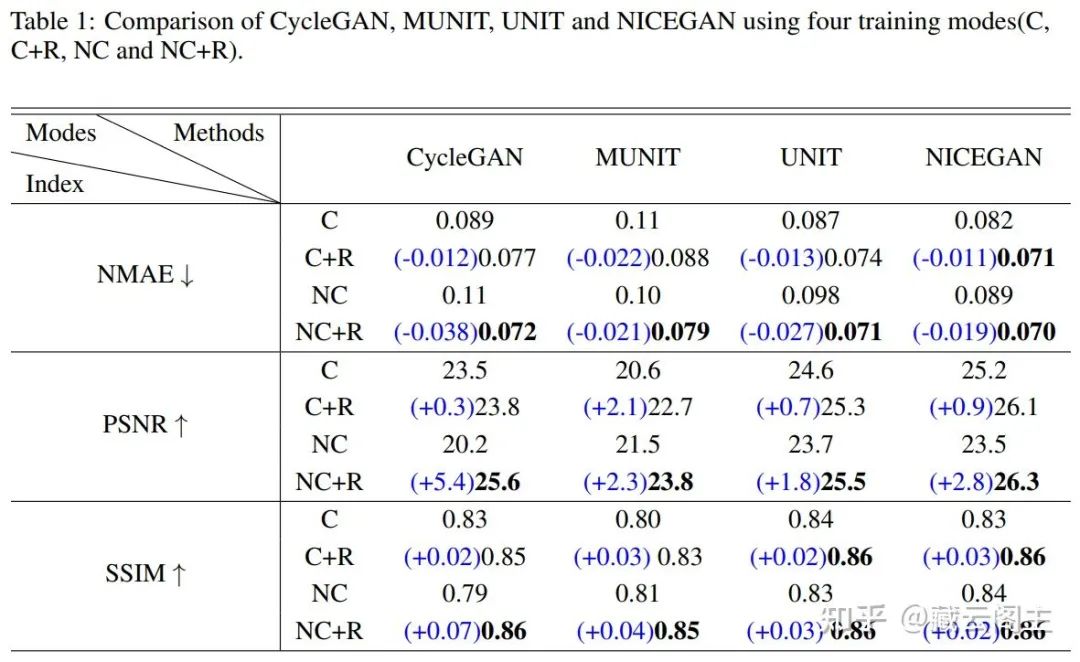
表中C表示Cycle-consistency模式,C+R表示Cycle-consistency加上Registration,NC表示Non Cycle-consistency,也就是把cycle loss移除,NC+R表示在NC的基础上加上了Registration,也就是最基本的RegGAN模式。
Exp. 1 在不同的方法中使用以上四种模式:
加入了Registration可以显著地改进各个方法的表现
C模式比NC模式普遍要好,而C+R与NC+R相比却没有明显优势,甚至有些还更差了,这意味着在使用了R之后,C就不再是提升性能的必要选择。另外,C模式必然包含2个生成器和2个判别器,相比于R来说,参数量更加臃肿。
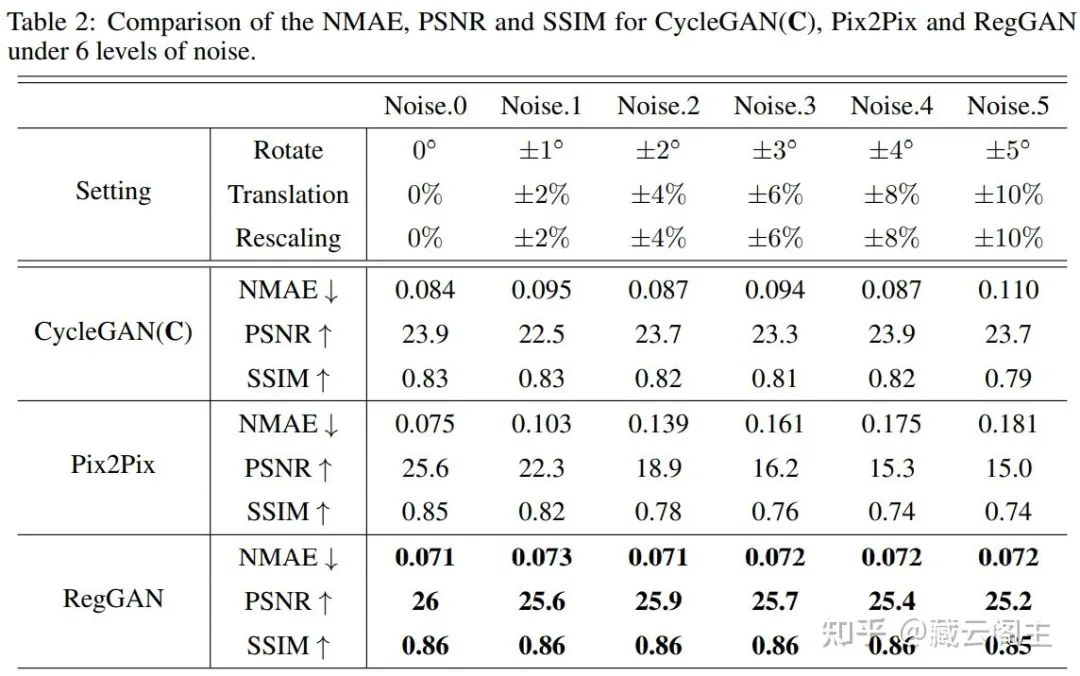
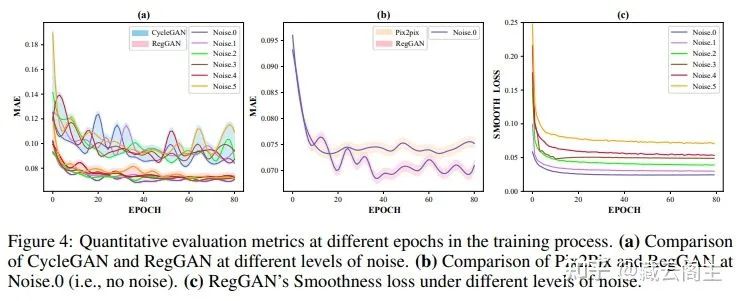
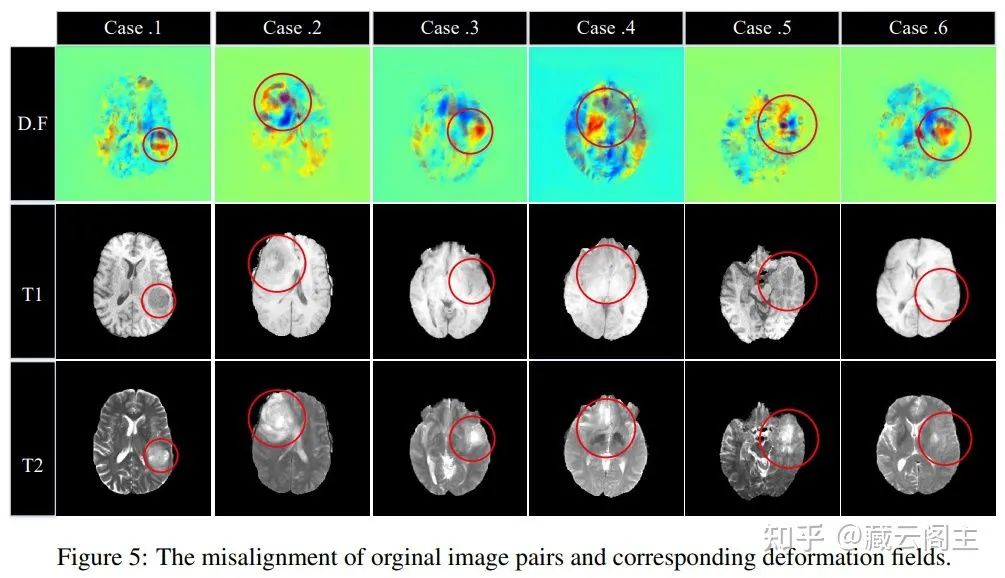
Exp. 2 评估噪声等级对模型性能的影响:
Pix2Pix模式的性能随着噪声增加而急剧下降
Cycle-consistency同样到噪声的影响,并且训练的loss非常不稳定,但在噪声较大的场景下比Pix2Pix要好
RegGAN受噪声影响程度低。另外,在Noise为0的情况下RegGAN依然优于Pix2Pix,理想情况下是不应该发生的,但实际情况是,完美的pixel-aligned医疗影像数据集几乎不存在,即使是BraTS 2018中依然存在轻微的misalignment,这一点可以从图5中明显地看出来,这也意味着RegGAN在广泛的数据集上都有应用价值。
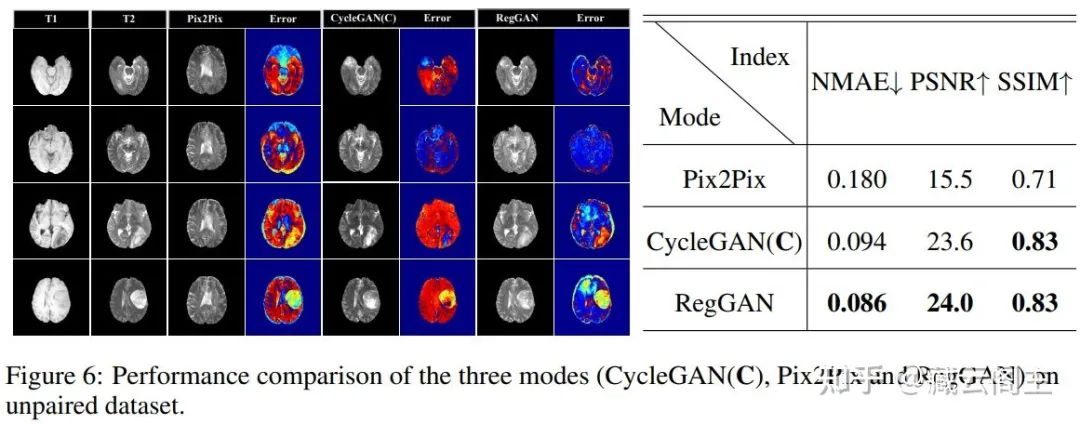
Exp. 3 Unpaired数据集上的表现:
Pix2Pix出现了模式坍缩,无论输入什么图像,生成器生成的图像几乎没有太大的变化
Cycle-consistency勉强能够work
RegGAN依然是这三种模式中最好的
Conclusion
从我们的实验结果中,我们得到三个结论:
对于paired well-aligned数据集,RegGAN ≥ Pix2Pix > CycleGAN(C)
对于paired misaligned数据集,RegGAN > CycleGAN(C) >Pix2Pix
对于unpaired数据集,RegGAN > CycleGAN(C) >Pix2Pix
在本文中,我们向大家介绍了一种新的Image-to-Image的医疗影像生成模式 RegGAN,并解释了它的原理,证明了它能够在多种网络结构中起到改进作用。
Recruitment

Manteia数据科技是一家自适应放疗解决方案提供商,以算法为核心,致力于提高放疗精度与临床效率。加入我们,与优秀的人,做非凡的事,我们喜欢具有远大理想和脚踏实地的伙伴,提供充满竞争力的福利待遇,并且提供全世界范围的学习机会。简历投递wumingxia@manteiatech.com
参考
^https://arxiv.org/abs/1611.07004
^https://arxiv.org/abs/1703.10593
^https://arxiv.org/abs/1609.03683
^https://openreview.net/forum?id=B1eWOJHKvB
^https://arxiv.org/abs/2003.08073
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》