
【论文解读】Six Attributes of Unhealthy Conversations 不健康对话的六个特征
这是 Google Pair 团队比较新的研究~
这篇主要是讲的数据集以及标注相关的研究。
0. 摘要
本文展示了一个包含 44000 条在线评论的数据集,这些评论已被标记为“健康”或“不健康”,基于六个子属性:
hostile(敌对) antagonistic, insulting, provocative or trolling(对抗性、侮辱性、挑衅性或挑衅性的) dismissive(不屑一顾) condescending or patronising(居高临下的) sarcastic (讽刺的) an unfair generalisation(不公平的)
每个标签还有一个置信度分数。作者认为,需要允许对“不健康的在线对话”这一广泛概念进行研究的数据集。他们提供了数据集的汇总统计数据和初始模型,并讨论了未来研究的局限性和方向。
1. 介绍
由于互联网的普及和在线论坛的发展,在线用户讨论已成为一个重要的研究领域。然而,互联网使用率的增加也导致网上负面行为的增加,包括虐待和骚扰。这种负面行为会对个人的幸福感产生严重影响,导致他们离开在线社区或减少参与,并可能导致线下仇恨犯罪。旨在自动化审核、为人工审核团队提供分类或设计系统以鼓励更健康的对话的研究有可能提高在线讨论的质量和可用性。
研究人员和网站管理员面临着为在线讨论建立不良评论类型、一致可靠地应用它以及解释对抗性用户行为以响应节制的挑战。先前关于在线有毒评论的研究在使用基于众包数据训练的分类器检测明显形式的毒性方面取得了一些成功,但在检测可能隐含的、需要特定知识或背景或具有特定文化背景的更微妙形式的毒性方面存在困难。为了应对这一挑战,需要可用于训练机器学习模型的关于更微妙的毒性属性的高质量、大型、带注释的数据集。然而,目前关于这些属性的可用数据集很少,特别是在英语以外的语言中,这阻碍了进一步的研究。
不健康评论语料库 (UCC) 是一个包含大约 44,000 条在线评论和相应标签的数据集,旨在识别评论是否适合“健康”在线对话。UCC 包括评论是否具有敌意、敌对、不屑一顾、居高临下、讽刺或不公平概括的标签,还包括每个标签的置信度分数。UCC 旨在提供有关讽刺、敌意和居高临下等属性的高质量数据,并提供其规模的第一个数据集,其中包含轻蔑、不公平概括和“健康”对话的总体评估标签。UCC 是开源的,包括针对数据集评估的基线分类模型。该论文还讨论了数据集中潜在的偏差来源。
2. 从“toxic”评论到“不健康”对话
这里讨论了“健康的”在线公共对话的概念,其特点是发帖和评论是真诚的,没有过度敌对或破坏性,并且通常会邀请参与。虽然此类对话可能包含激烈的辩论,但它们不一定友好、语法正确、结构合理、知识渊博或不含粗俗。对在线对话的一些有害贡献显然是贬损、威胁、暴力或侮辱,但其他人可能更 subtle,例如讽刺、傲慢或轻蔑。识别这些有问题的在线评论的微妙指标很困难,因为它们不那么极端,也不太可能使用明确可识别的露骨或煽动性语言,可能会根据上下文和期望而有不同的看法,并且被错误地识别。
在线识别有害评论的 challenge 是在能正确地识别健康评论的情况下这样做。有害评论可分为两类:明确意图侮辱、威胁或辱骂的评论,以及与他人互动但以可能激怒、伤害或阻止他人的方式撰写的评论。
不健康属性的类型旨在包括第二类评论,并确定它们是否属于健康的在线对话。抽象的“健康”评级与其他属性的组合提供了一个有用的数据集,用于研究差别很细微的评论,并可用于开发为特定生产环境定制的模型。然而,这些属性的存在是否表明对话健康或不健康也将取决于论坛和用户的性质。
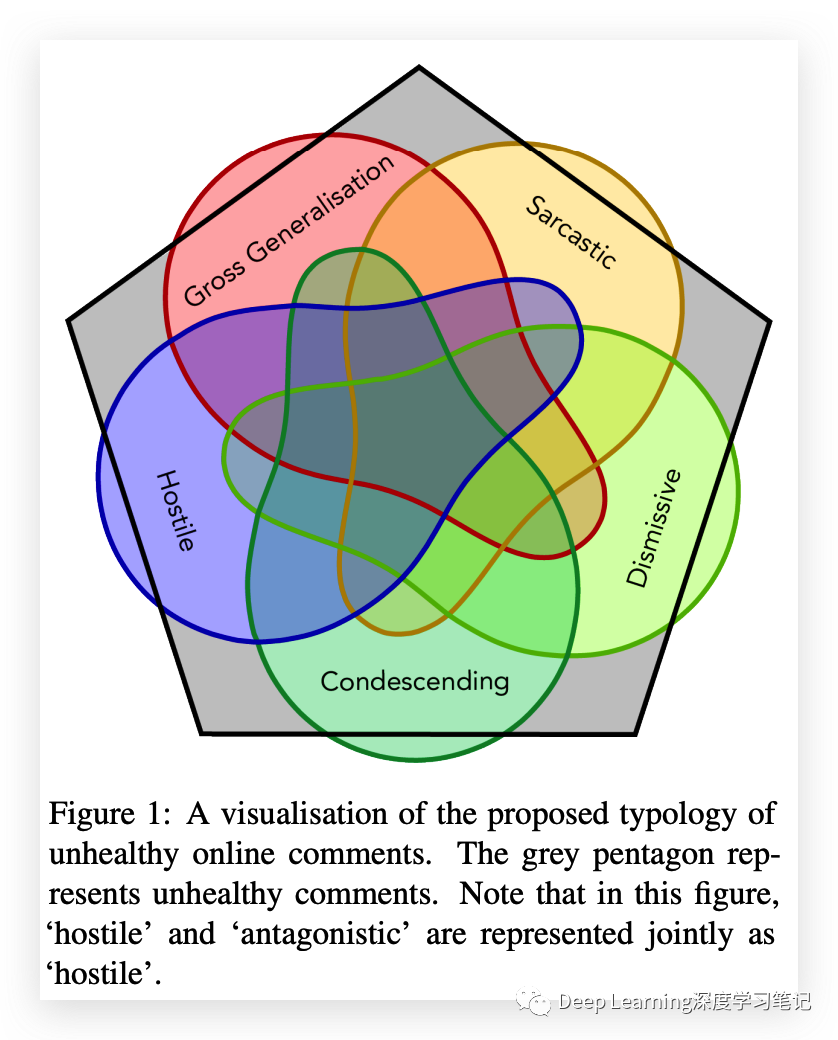
3. 源数据和 annotation
该数据集包含来自 Globe and Mail 新闻网站的不超过 250 个字符的评论。这些评论由一组 588 名众包工作者使用标准问卷对某些属性的存在进行注释。如果注释者之间对特定评论没有达成足够的共识,则要求添加注释,直到达成足够的共识。所有评论都至少被注释了 3 次,每个评论最多有 5 个注释者。由于被评估属性的主观性和模糊性,注释过程具有挑战性。
注释任务的目标是最大化注释者对任务的共同理解,而不仅仅是最大化一致性。为实现这一目标,问题的措辞经过精心设计,以尽可能对每个问题的询问达成共识。通过计算感知错误注释的比例及其严重性来评估结果数据的质量。最好的结果主要依靠注释者对属性的隐含理解和直觉,并辅以简短的内联解释。这些解释是针对更模糊的属性添加的,并且是基于较小测试的结果。
注释过程包括一个质量控制机制,以确保分歧反映合理的意见分歧,而不是误解或对任务的疏忽。为此目的使用了一组“测试评论”,为此手动建立了正确的答案。注释者对这些测试评论的准确性被用作“可信度分数”,得分低于 78% 的注释者将从池中移除,并且他们之前的注释将被丢弃。测试注释被设计成被注释的属性的清晰示例,并且包含了特定的测试注释以解决通过初步测试发现的常见误解或错误。
对于评论是否属于健康对话的问题,包含的测试评论很少。这些测试评论是极端的例子,例如高度辱骂的评论,以确保注释者不是随机回答问题。这个问题的测试评论的使用被最小化有两个原因:首先,很难建立排除注释者的测试,因为这个问题是最开放的;其次,允许注释者在这个问题上有更大的自由裁量权,可以深入了解这六个属性与被标记为不健康之间是否存在相关性。
4. UCC 数据集
该数据集包含 44355 条评论,每个属性都被标记为“是”或“否”,以及每个标签的置信度分数。这些标签和置信度分数基于不同注释者给出的答案,由他们各自的可信度分数加权。包含每个属性的评论比例如下表所示。
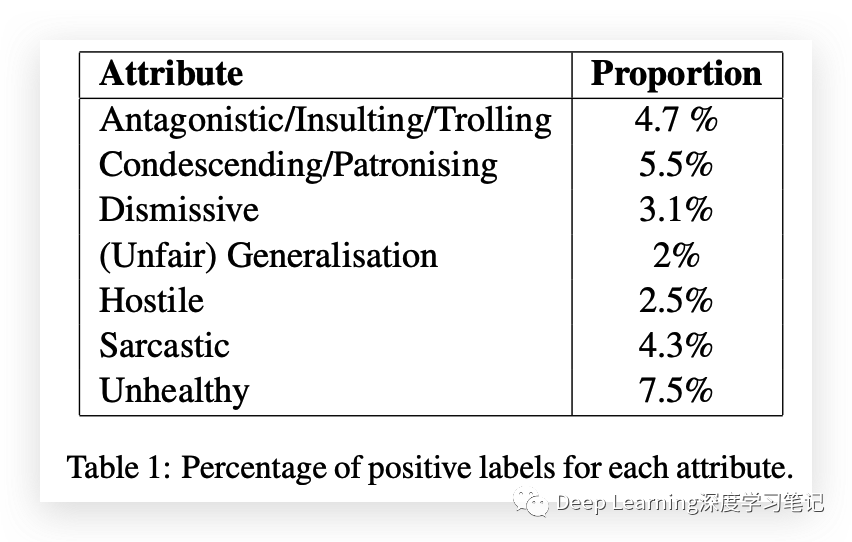
置信度分布如图所示。
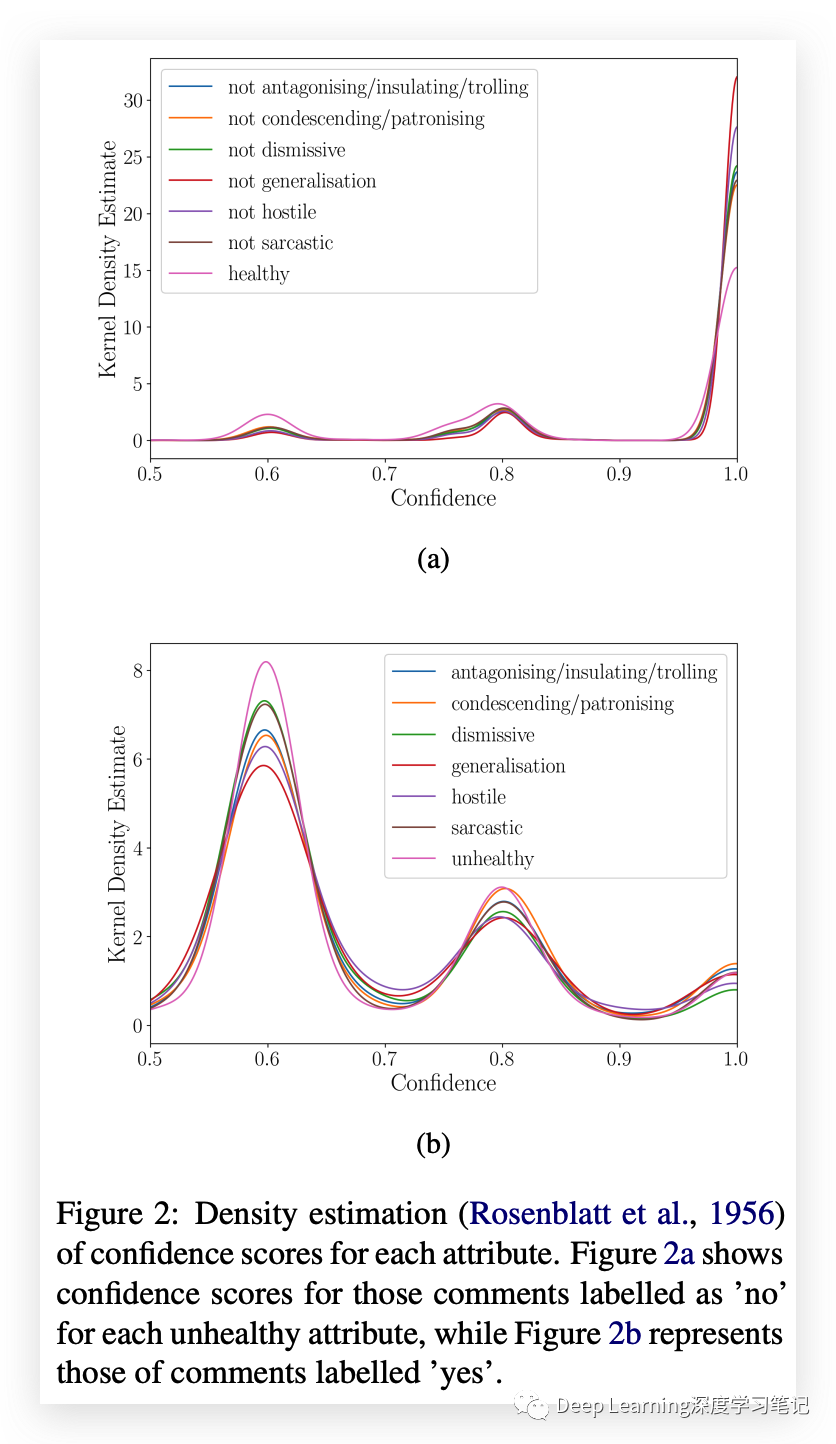
SFU 意见和评论语料库数据集包含各种属性的流行程度较低,例如讽刺,但仍然对识别这些微妙属性做出了重大贡献。该数据集是通过众包和人工分析创建的,被认为代表了这些属性在类似环境中的普遍性,例如在线报纸评论部分。对于讽刺等属性,可以从 Twitter 或 Reddit 等来源收集自标记数据,但对于其他属性,众包是获得高质量数据的唯一可行途径。
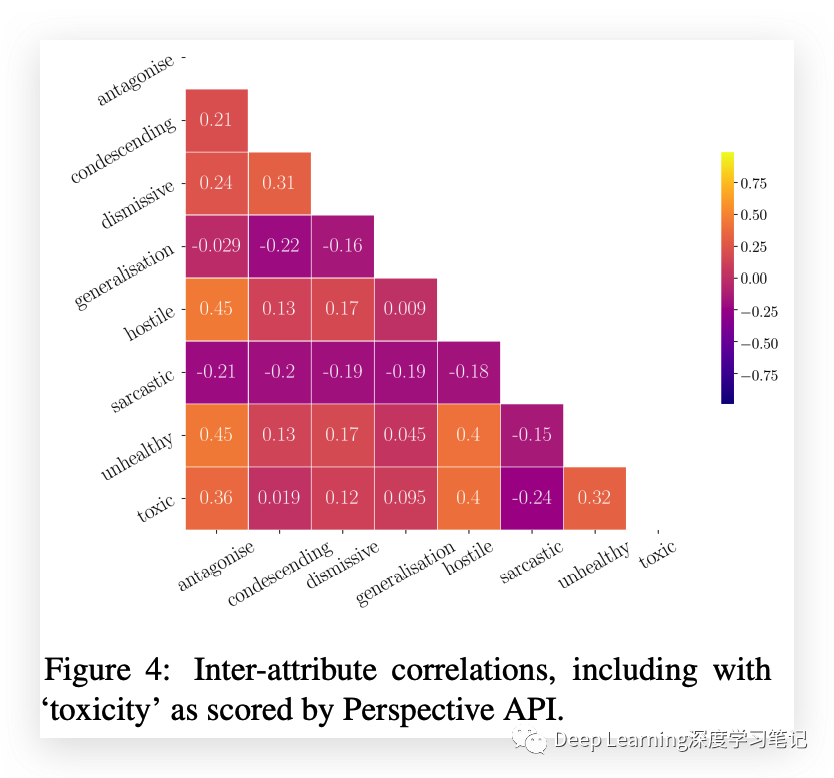
UCC 数据集在大多数属性之间具有低相关性,表明它能够区分不同类型的细微不健康属性。敌对和敌对的评论之间存在显着相关性,而更微妙的属性(例如轻蔑/屈尊和对抗)之间存在一些相关性。该数据集还与 Perspective API 产生的“toxic”分数显着相关,表明它捕获了不同于明显 toxic 的东西。注释者通常不会将讽刺与其他不健康的属性联系起来,并且对健康对话有一个广泛的一般概念,其中主要包括轻蔑、居高临下、讽刺和笼统的评论。由于任务的性质和注释方法,数据集中存在一定程度的噪声,难以量化。
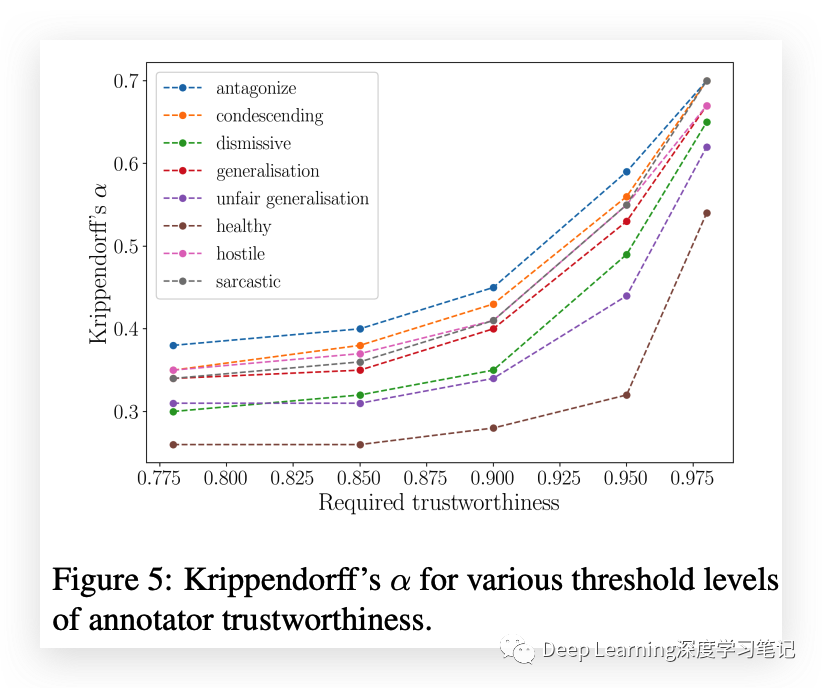
Krippendorff's alpha (K-alpha) 的传统可靠性指标并不总是适合与主观任务的众包注释一起使用。K-alpha 是衡量注释者与随机猜测相比的同意程度的指标,并假设注释者之间的所有分歧都会降低可靠性。但是,主观属性可能并非如此。尽管如此,K-alpha 用于将 UCC 数据集与其他标记类似现象(例如讽刺和仇恨言论)的数据集进行比较。UCC 数据集的 K-alpha 范围从 0.31 到 0.39,与其他数据集相当。评论是否在健康对话中占有一席之地这一属性的 K-alpha 较低,为 0.26,这可能是由于问题的开放性。
另外,UCC 数据集包括注释者的可信度分数,用于决定每个评论的标签和置信度分数。这些可信度分数的使用得到以下事实的支持:随着所包含注释器的可信度阈值增加,由此产生的 K-alpha 稳步增加。这表明可信度分数确实反映了注释者的可靠性,并且他们的判断应该在评论标签的最终置信度中获得更大的权重。所有“可信”注释者对每个评论的单独注释也包含在 UCC 数据集中,允许用户应用他们自己的可信度阈值或使用首选聚合方法来派生标签。
5.Models and results
使用预训练的 BERT 模型和对 UCC 数据集进行微调产生的分类器与序列分类的现有技术相比性能适中。性能最高的属性是“敌对”和“对抗”,这与评论分类工作中通常注释的属性相似。“讽刺”标签的性能特别低。与人类工作者相比,BERT 模型在除“讽刺”之外的所有属性上都优于随机选择的人类注释器,这表明它已充分捕获这些属性的语义和句法结构。BERT 模型和人类注释者在“讽刺”属性方面的差距表明了模型性能改进的潜在领域。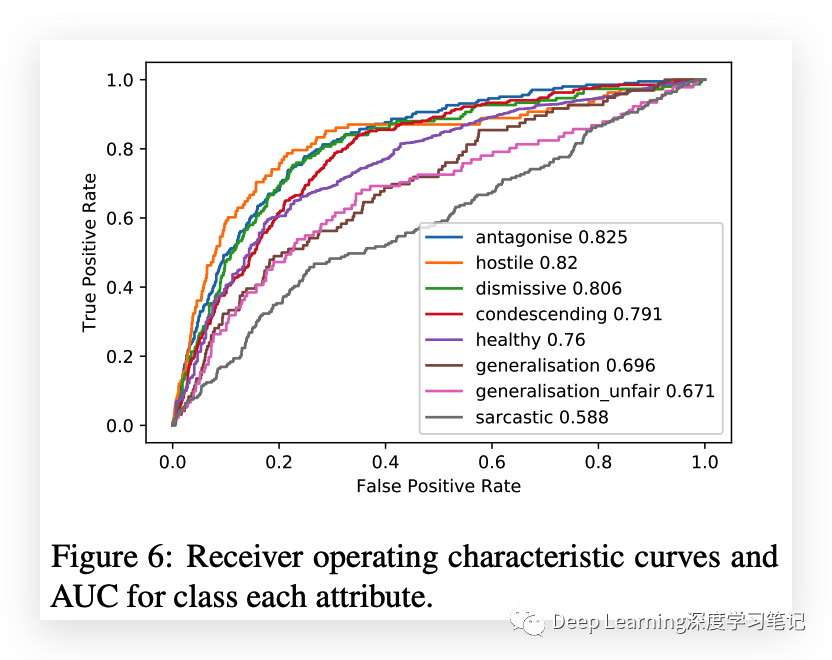
6.潜在的意外偏见
注释更 subtle 的不健康属性带来的另一个挑战是,有可能在基于这些数据训练的模型中编码无意识的社会偏见和价值判断。例如,讽刺通常是通过陈述一些作者认为明显不真实以至于会被解读为讽刺的东西来传达的。这些假设反映了作者的偏见——或者在评论注释的情况下,将评论标记为讽刺反映了注释者对明显不真实的看法。
UCC 数据集包含来自加拿大在线报纸评论部分的评论,这些评论在没有新闻文章或其他评论的周围上下文的情况下单独呈现给注释者。还为注释者提供了一份标准问卷,其中包含对可能无法跨文化推广的属性的高级描述。这些因素可能会给数据集带来偏差。UCC 数据集不适用于在实时在线设置中无需人工干预的情况下立即用于自动审核。它可用于减少干预的 “nudges” 或提醒读者如何看待评论,以帮助在线讨论的参与者。了解并解决该领域的偏见非常重要,因为收集数据的方式会对生产环境中的用户产生重大影响。
7. Conclusions and Further work
作者引入了一个新的标记评论语料库和一个类型学来对不健康的在线对话的微妙方面进行分类。该类型包括六个子属性和标签的置信度分数。作者还描述了创建此类数据集的过程和挑战,并提供了有关数据规模的统计数据。他们发现,不健康评论的子属性在很大程度上独立于明显的 toxicity,并且大多与不健康的 contributions 相关。
另外,作者还使用基线模型进行了机器学习实验,发现其性能超过了众包工作者。他们建议收集更大的注释语料库可以提高测量该领域模型的能力。然而,作者认识到他们的不健康贡献类型可能并不详尽,未来的研究可以进一步完善类型、标准问卷,或将其应用于不同文化和地理背景下的论坛。作者计划进一步开展工作,探索模型和数据中的意外偏差。基于它的数据集和模型可用于研究不健康对话的早期迹象,并协助调节在线对话。
Reference:
论文原文: https://arxiv.org/abs/2010.07410
Google Pair: https://pair.withgoogle.com/tools/
知乎: https://zhuanlan.zhihu.com/p/596632747