
触类旁通Elasticsearch之吊打同行系列:分析篇
共 20553字,需浏览 42分钟
·
2020-12-07 14:20
点击上方蓝色字体,选择“设为星标”




目录
一、什么是分析
二、分析文
三、分析API
四、分析器、分词器、分词过滤器
内置分析器
分词器
分词过滤器
五、N元语法、侧边N元语法、滑动窗口
六、IK中文分词插件
一、什么是分析
分析(analysis)是在文档被发送并加入倒排索引之前,ES在其主体上进行的操作。在文档被加入索引之前,ES让每个被分析字段经过一系列的处理步骤。
字符过滤:使用字符过滤器转变字符。
文本切分为分词:将文本切分为单个或多个分词。
分词过滤:使用分词过滤器转变每个分词。
分词索引:将这些分词存储到索引中。
图1展示了将文本“share your experience with NoSql & big data technologies”进行分析的整个流程。
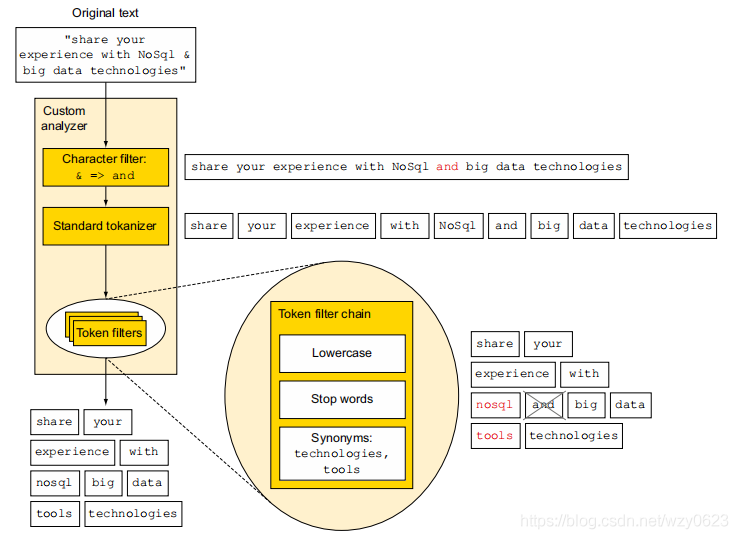
(1)字符过滤
字符过滤将特定的字符序列转变为其它的字符序列。图1中使用特定过滤器将&替换为“and”。
(2)切分为分词
Lucene处理的是被称为分词(token)的数据。分词是从文本片段生成的,可能会产生任意数量(甚至是0)的分词。例如,标准英文分词器根据空格、换行和破折号等字符,将文本分割为分词。图1中,这种行为表现为将字符串“share your experience with NoSql and big data technologies”分割为分词share、your、experience、with、NoSql、and、big、data和technologies。
(3)分词过滤
一旦文本被转换为分词,ES将会对每个分词运用分词过滤器(token filter)。这些分析过滤器可以将一个分词作为输入,然后根据需要进行修改、添加或删除。图1给出的例子中,有3种分词过滤器:第一个将分析转为小写,第二个删除停用词“and”,第三个将词条“tools”作为“technologies”的同义词进行添加。
(4)分词索引
当分词经过零个或多个分词过滤器,它们将被发送到Lucene进行文档的索引,这些分词组成了倒排索引。
零个或多个字符过滤器、一个分词器、零个或多个分词过滤器组成了一个分析器(analyzer)。搜索在索引中执行之前,根据所使用的查询类型,分析同样可以运用到搜索的文本。如match、match_phrase在搜索之前会对文本执行分析步骤,而term和terms则不会。
二、分析文档
有以下两种方式指定字段所使用的分析器:
创建索引时,为特定的索引进行设置。
在ES配置文件中,设置全局分析器。
(1)在索引创建时增加分析器
下面的代码在创建myindex索引时定制了分析器,为所有的分析步骤指定了定制的部分。
curl -XPUT '172.16.1.127:9200/myindex?pretty' -H 'Content-Type: application/json' -d '{"settings": {"number_of_shards": 2, # 主分片数"number_of_replicas": 1, # 副本数"index": {"analysis": { # 索引的分析设置"analyzer": { # 在分析器对象中设置定制分析器"myCustomAnalyzer": { # 定制名为myCustomAnalyzer的分析器"type": "custom", # 分析器类型为定制"tokenizer": "myCustomTokenizer", # 使用名为myCustomTokenizer的分析器对文本进行分词"filter": [ # 指定文本需要经过两个分词过滤器myCustomFilter1和myCustomFilter2"myCustomFilter1","myCustomFilter2"],"char_filter": [ # 设置定制的字符过滤器myCustomCharFilter,它会在其它分析步骤之前运行"myCustomCharFilter"]}},"tokenizer": {"myCustomTokenizer": {"type": "letter" # 设置定制分析器的类型为letter}},"filter": {"myCustomFilter1": {"type": "lowercase" # 定制两个分词过滤器,一个是转为小写,一个使用kstem进行词干处理},"myCustomFilter2": {"type": "kstem"}},"char_filter": {"myCustomCharFilter": { # 定制的字符过滤器,将字符翻译为其它映射"type": "mapping","mappings": ["ph=>f","u=>you"]}}}}},"mappings": {"_doc": {"properties": {"description": {"type": "text","analyzer": "myCustomAnalyzer" # 为description字段指定myCustomAnalyzer分析器},"name": {"type": "text","analyzer": "standard", # 为name字段指定standard分析器"fields": {"raw": {"index": false, # 保留不做分析的原始文本,通过name.raw引用"type": "text"}}}}}}}
(2)在ES配置文件中添加分析器
在ES配置文件中指定分析器,需要重启ES才能生效。下面的例子在elasticsearch.yml配置文件中设置分析器。这里的定制分析器和前面的一样,不过是在YAML里设置的。
index:analysis:analyzer:myCustomAnalyzer:type: customtokenizer: myCustomTokenizerfilter: [myCustomFilter1, myCustomFilter2]char_filter: myCustomCharFiltertokenizer:myCustomTokenizer:type: letterfilter:myCustomFilter1:type: lowercasemyCustomFilter2:type: kstemchar_filter:myCustomCharFilter:type: mappingmappings: ["ph=>f", "u =>you"]
三、分析API
当跟踪信息是如何在ES索引中存储的时候,使用分析API来测试分析的过程是十分有用的。分析API允许向ES发送任何文本,指定所使用的分析器、分词器或者分词过滤器,然后获取分析后的分词。下面的代码使用标准分析器分析了文本“share your experience with NoSql & big data technologies”。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "standard","text" : "share your experience with NoSql & big data technologies"}'
结果返回:
{"tokens" : [{"token" : "share","start_offset" : 0,"end_offset" : 5,"type" : "" ,"position" : 0},{"token" : "your","start_offset" : 6,"end_offset" : 10,"type" : "" ,"position" : 1},{"token" : "experience","start_offset" : 11,"end_offset" : 21,"type" : "" ,"position" : 2},{"token" : "with","start_offset" : 22,"end_offset" : 26,"type" : "" ,"position" : 3},{"token" : "nosql","start_offset" : 27,"end_offset" : 32,"type" : "" ,"position" : 4},{"token" : "big","start_offset" : 35,"end_offset" : 38,"type" : "" ,"position" : 5},{"token" : "data","start_offset" : 39,"end_offset" : 43,"type" : "" ,"position" : 6},{"token" : "technologies","start_offset" : 44,"end_offset" : 56,"type" : "" ,"position" : 7}]}
分析API中最为重要的输出是token键。输出是一组这样的映射列表,代表了处理后的分词。实际上,就是这些分词将会被写入到索引中。上例中的文本分析后获得8个分词。该例使用了标准的分析器,每个分词被转为小写,每个句子结尾的标点也被去除。
(1)选择分析器
可以通过analyzer参数引用分析器的名字:
curl -X GET "172.16.1.127:9200/get-together/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "myCustomAnalyzer","text" : "share your experience with NoSql & big data technologies"}'
(2)通过组合即兴创建分析器
可以尝试分词器和分词过滤器的组合。例如,使用空白分词器(按照空白来切分文本),然后使用小写和反转分词过滤器,可以这样做:
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "whitespace","filter" : ["lowercase", "reverse"],"text" : "share your experience with NoSql & big data technologies"}
将得到如下分词:erahs, ruoy, ecneirepxe, htiw, lqson, &, gib, atad, seigolonhcet
(3)基于某个字段映射的分析
ES允许基于所创建的映射字段来进行分析:
curl -X GET "172.16.1.127:9200/get-together/_analyze?pretty" -H 'Content-Type: application/json' -d'{"field" : "description","text" : "share your experience with NoSql & big data technologies"}
ES自动使用与description字段关联的分析器进行文本分析。该特性需要指定一个索引,因为ES需要从索引中获取特定字段的映射。
(4)使用词条向量API来学习索引词条
可以使用 _termvector 端点获取词条的更多信息。使用改端点可以了解词条,了解它们在文档中、索引中出现的频率,以及出现在文档中的位置。
curl '172.16.1.127:9200/get-together/_doc/2/_termvector?pretty=true'结果返回:
{"_index" : "get-together","_type" : "_doc","_id" : "2","_version" : 6,"found" : true,"took" : 35,"term_vectors" : {"description" : { # 返回词条信息"field_statistics" : { # 该字段中词条统计数据"sum_doc_freq" : 249, # 该字段中所有词条的文档频率之和"doc_count" : 16, # 包含这个字段的文档数量"sum_ttf" : 267 # 字段中所有词条频率之和},"terms" : { # 包含字段description中所有词条的对象"about" : { # 属于结果数据的词条"term_freq" : 1, # 词条在字段中出现的次数"tokens" : [ # 词条在字段中的位置{"position" : 5,"start_offset" : 27,"end_offset" : 32}]},"and" : {"term_freq" : 1,"tokens" : [{"position" : 10,"start_offset" : 71,"end_offset" : 74}]},...}}}}
可以指定需要统计数据的字段:
curl '172.16.1.127:9200/get-together/_doc/2/_termvector?pretty=true' -H 'Content-Type: application/json' -d '{"fields": ["description","tags"],"term_statistics": true}
下面是响应的一部分,只显示了一个词条,结构和之前的代码样例相同。
"about" : { # 展示信息的词条"doc_freq" : 6, # 出现这个词条的文档数"ttf" : 6, # 索引中该词条的总词频"term_freq" : 1,"tokens" : [{"position" : 5,"start_offset" : 27,"end_offset" : 32}]}
四、分析器、分词器、分词过滤器
内置分析器
(1)标准分析器
标准分析器(standard analyzer)是ES默认的文本分析器,包括标准分词器、标准分词过滤器、小写转换分词过滤器和停用词分词过滤器。
(2)简单分析器
简单分析器(simple analyzer)只使用小写转换分词器。这意味着在非字母处进行分词,并将分词自动转为小写。
(3)空白分析器
空白分析器(whitespace analyzer)只根据空白将文本切分为若干分词。
(4)停用词分析器
停用词分析器(stop analyzer)和简单分析器的行为很像,只是在分词流中额外地过滤了停用词。
(5)关键词分析器
关键词分析器(keyword analyzer)将整个字段当做一个单独的分词。最好是将index设置为false,而不是在映射中使用关键词分析器。
(6)模式分析器
模式分析器(pattern analyzer)允许指定一个分词切分的模式。但由于需要指定模式,更有意义的做法是使用定制分析器,组合现有的模式分词器和所需的分词过滤器。
(7)语言和多语言分析器
ES支持许多能直接使用的特定语言分析器。
(8)雪球分析器
雪球分析器(snowball analyzer)除了使用标准的分词器和分词过滤器,也使用了小写分词过滤器和停用词过滤器。它还使用了雪球词干器对文本进行词干提取。
分词器
(1)标准分词器
标准分词器(standard tokenizer)是一个基于语法的分词器,它处理Unicode文本的切分,分词默认的最大长度是255。它也移除了逗号和句号这样的标点符号。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "standard","text" : "I have, potatoes."}
切分后的分词是I、have和potatoes。
(2)关键词分词器
关键词分词器(keyword tokenizer)将整个文本作为单个分词,提供给分词过滤器。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "keyword","text" : "Hi, there."}
唯一的分词是Hi, there.。
(3)字母分词器
字母分词器(letter tokenizer)根据非字母的符号,将文本切分省分词。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "letter","text" : "Hi, there."}
分词是Hi和there。
(4)小写分词器
小写分词器(lowercase tokenizer)结合了常规的字母分词器和小写分词过滤器的行为。通过一个单独的分词器来实现的主要原因是,一次进行两项操作会获得更好的性能
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "lowercase","text" : "Hi, there."}
分词是hi和there。
(5)空白分词器
空白分词器(whitespace tokenizer)通过空白来分隔不同的分词,空白包括空格、制表符、换行等。该分词器不会删除任何标点符号。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "whitespace","text" : "Hi, there."}
分词是Hi,和there.。
(6)模式分词器
模式分词器(pattern tokenizer)允许指定一个任意的模式,将文本切分为分词。被指定的模式应该匹配间隔符号。下面代码创建一个定制分析器,它在出现文本.-.的地方将分词断开。
curl -XPUT '172.16.1.127:9200/pattern?pretty' -H 'Content-Type: application/json' -d '{"settings": {"index": {"analysis": {"tokenizer": {"pattern1": {"type": "pattern","pattern": "\\.-\\."}}}}}}'curl -X GET "172.16.1.127:9200/pattern/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "pattern1","text" : "breaking.-.some.-.text"}'
分词是breaking、some和text。
(7)UAX URL 电子邮件分词器
UAX URL 电子邮件分词器(UAX URL email tokenizer)将电子邮件和URL都作为单独的分词进行保留。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "uax_url_email","text" : "john.smith@example.com http://example.com?q=bar"}
结果返回:
{"tokens" : [{"token" : "john.smith@example.com","start_offset" : 0,"end_offset" : 22,"type" : "" ,"position" : 0},{"token" : "http://example.com?q=bar","start_offset" : 23,"end_offset" : 47,"type" : "" ,"position" : 1}]}
(8)路径层次分词器
路径层次分词器(path hierarchy tokenizer)允许以特定方式索引文件系统的路径。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "path_hierarchy","text" : "/usr/local/var/log/elasticsearch.log"}
分词是/usr、/usr/local、/usr/local/var、/usr/local/var/log和/usr/local/var/log/elasticsearch.log。
分词过滤器
(1)标准分词过滤器
标准分词过滤器(standard token filter)实际上什么事情都不做。
(2)小写分词过滤器
小写分词过滤器(lowercase token filter)将任何经过的分词转为小写。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "keyword","filter" : ["lowercase"],"text" : "HI THERE!"}
分词是hi there!
(3)长度分词过滤器
长度分词过滤器(length token filter)将长度超出最短和最长限制范围的单词过滤掉。例如,如果将min设置为2,max设置为8,任何小于2个字符和任何大于8个字符的分词将被移除。
curl -XPUT '172.16.1.127:9200/length?pretty' -H 'Content-Type: application/json' -d '{"settings": {"index": {"analysis": {"filter": {"my-length-filter": {"type": "length","max": 8,"min": 2}}}}}}'curl -X GET "172.16.1.127:9200/length/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "standard","filter" : ["my-length-filter"],"text" : "a small word and a longerword"}
分词结果是small、word和and。
(4)停用词分词过滤器
停用词分词过滤器(stop token filter)将停用词从分词流中移除。可以指定停用词列表:
curl -XPUT '172.16.1.127:9200/stopwords?pretty' -H 'Content-Type: application/json' -d'{"settings": {"index": {"analysis": {"analyzer": {"stop1": {"type": "custom","tokenizer": "standard","filter": ["my-stop-filter"]}},"filter": {"my-stop-filter": {"type": "stop","stopwords": ["the","a","an"]}}}}}}
为了从某个文件读取停用词列表,可以使用相对于配置文件的相对路径或是绝对路径。每个单词应该在新的一行上,文件必须是UTF-8编码。
curl -XPUT '172.16.1.127:9200/stopwords?pretty' -H 'Content-Type: application/json' -d'{"settings": {"index": {"analysis": {"analyzer": {"stop1": {"type": "custom","tokenizer": "standard","filter": ["my-stop-filter"]}},"filter": {"my-stop-filter": {"type": "stop","stopwords_path": "stopwords.txt"}}}}}}
(5)截断分词过滤器、修剪分词过滤器、限制分词数量过滤器
截断分词过滤器(truncate token filter)允许通过定制配置中的length参数,截断超过一定长度的分词。默认截断多于10个字符的部分。
修剪分词过滤器(trim token filter)删除一个分词中的所有空白部分。
限制分词数量过滤器(limit token count token filter)限制了某个字段可包含分词的最大数量。例如,如果创建了一个定制的分词数量过滤器,限制是8,那么分词流中只有前8个分词- 会被索引。这个设置使用max_token_count参数,默认是1。
(6)颠倒分词过滤器
颠倒分词过滤器(reverse token filter)允许处理一个分词流,并颠倒每个分词。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "standard","filter" : ["reverse"],"text" : "Reverse token filter"}
分词结果是esreveR、nekot和retlif。
(7)唯一分词过滤器
唯一分词过滤器(unique token filter)只保留唯一的分词,它保留第一个匹配分词的元数据,而将其后出现的重复删除。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "standard","filter" : ["unique"],"text" : "foo bar foo bar baz"}
分词结果是foo、bar和baz。
(8)ASCII折叠分词过滤器
ASCII折叠分词过滤器(ASCII folding token filter)将不是普通ASCII字符的Unicode字符转化为ASCII中等同的字符,前提是这种等同存在。
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"tokenizer" : "standard","filter" : ["asciifolding"],"text" : "ünicode"}
分词结果是unicode。
(9)同义词分词过滤器
同义词分词过滤器(synonym token filter)在分词流中的同样位移处,使用关键词的同义词取代原始分词。例如“I own that automobile”和两个同义词“automobile”、“car”。如果不使用同义词分词过滤器:
curl -X GET "172.16.1.127:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "standard","text" : "I own that automobile"}
分词结果是i、own、that和automobile。
为了指定“automobile”的同义词,可以像下面这样定义定制分析器:
curl -XPUT '172.16.1.127:9200/syn-test?pretty' -H 'Content-Type: application/json' -d'{"settings": {"index": {"analysis": {"analyzer": {"synonyms": {"type": "custom","tokenizer": "standard","filter": ["my-synonym-filter"]}},"filter": {"my-synonym-filter": {"type": "synonym","expand": true,"synonyms": ["automobile=>car"]}}}}}}
当使用这个分析器时,可以看到在结果中automobile分词已被替换为car
curl -X GET "172.16.1.127:9200/syn-test/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "synonyms","text" : "I own that automobile"}
返回结果为:
{"tokens" : [{"token" : "I","start_offset" : 0,"end_offset" : 1,"type" : "" ,"position" : 0},{"token" : "own","start_offset" : 2,"end_offset" : 5,"type" : "" ,"position" : 1},{"token" : "that","start_offset" : 6,"end_offset" : 10,"type" : "" ,"position" : 2},{"token" : "car","start_offset" : 11, # 注意start_offset和end_offset使用的是automobile的数据"end_offset" : 21,"type" : "SYNONYM","position" : 3}]}
这个例子配置了同义词分词过滤器,让其使用同义词来取代分词,但是也可以使用这个过滤器将synonym分词额外添加到分词集合中。在这种情况下,应该使用automobile,car来替换automobile=>car。
五、N元语法、侧边N元语法、滑动窗口
N元语法是将一个单词切分为多个子单词。
(1)一元语法过滤器
“spaghetti”的一元语法(1-grams)是s、p、a、g、h、e、t、t、I。
(2)二元语法过滤器
如果将字符串切分为二元语法(bigrams,意味着两个字符的尺寸),会获得如下分词:sp、pa、ag、gh、he、et、tt、ti。
(3)三元语法过滤器
如果使用3个字符的尺寸(trigrams,被称为三元语法),将得到的分词是:spa, pag, agh, ghe, het, ett, tti。
(4)设置min_gram和max_gram
当使用这个分析器的时候,需要设置两个不同的尺寸:一个设置所想生成的最小的N元语法(设置min_gram),另一个设置所想生成的最大的N元语法(设置max_gram)。使用前面的例子,如果min_gram为2,max_gram为3,将获得两个先前例子的合并的分词集合:sp、spa、pa、pag、ag、agh、gh、ghe、he、het、et、ett、tt、tti、ti。
(5)侧边N元语法过滤器
侧边N元语法仅仅从前端的边缘开始构建N元语法。在“spaghetti”的例子中,如果min_gram为2,max_gram为6,那么将获得如下分词:sp、spa、spag、spagh、spaghe。
(6)N元语法的设置。
curl -XPUT '172.16.1.127:9200/ng?pretty' -H 'Content-Type: application/json' -d'{"settings": {"number_of_shards": 1,"number_of_replicas": 0,"index": {"analysis": {"analyzer": {"ng1": {"type": "custom","tokenizer": "standard","filter": [ # 配置一个分析器,颠倒、侧边N元语法和再次颠倒"reverse","ngf1","reverse"]}},"filter": {"ngf1": {"type": "edge_ngram", # 设置侧边N元语法分词过滤器的最小尺寸和最大尺寸"min_gram": 2,"max_gram": 6}}}}}}'curl -X GET "172.16.1.127:9200/ng/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "ng1","text" : "spaghetti"}
结果返回:
{"tokens" : [{"token" : "ti","start_offset" : 0,"end_offset" : 9,"type" : "" ,"position" : 0},{"token" : "tti","start_offset" : 0,"end_offset" : 9,"type" : "" ,"position" : 0},{"token" : "etti","start_offset" : 0,"end_offset" : 9,"type" : "" ,"position" : 0},{"token" : "hetti","start_offset" : 0,"end_offset" : 9,"type" : "" ,"position" : 0},{"token" : "ghetti","start_offset" : 0,"end_offset" : 9,"type" : "" ,"position" : 0}]}
(7)滑动窗口分词过滤器
ES有一个过滤器被称为滑动窗口分词过滤器(shingles),和N元语法以及侧边N元语法沿用了同样的方式。滑动窗口分词过滤器基本上是分词级别的N元语法,而不是字符级别的N元语法。
curl -XPUT '172.16.1.127:9200/shingle?pretty' -H 'Content-Type: application/json' -d '{"settings": {"index": {"analysis": {"analyzer": {"shingle1": {"type": "custom","tokenizer": "standard","filter": ["shingle-filter"]}},"filter": {"shingle-filter": {"type": "shingle","min_shingle_size": 2, # 设置最小和最大的滑动窗口尺寸"max_shingle_size": 3,"output_unigrams": false # 不保留原始的单个分词}}}}}}'curl -X GET "172.16.1.127:9200/shingle/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer" : "shingle1","text" : "foo bar baz"}
返回结果为
{"tokens" : [{"token" : "foo bar","start_offset" : 0,"end_offset" : 7,"type" : "shingle","position" : 0},{"token" : "foo bar baz","start_offset" : 0,"end_offset" : 11,"type" : "shingle","position" : 0,"positionLength" : 2},{"token" : "bar baz","start_offset" : 4,"end_offset" : 11,"type" : "shingle","position" : 1}]}
六、IK中文分词插件
(1)安装
/home/elasticsearch/elasticsearch-6.4.3/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.4.3/elasticsearch-analysis-ik-6.4.3.zip# 重启ES/home/elasticsearch/elasticsearch-6.4.3/bin/elasticsearch -d
(2)测试
curl -XPOST http://172.16.1.127:9200/index/fulltext/1?pretty -H 'Content-Type:application/json' -d'{"content":"美国留给伊拉克的是个烂摊子吗"}'curl -XPOST http://172.16.1.127:9200/index/fulltext/2?pretty -H 'Content-Type:application/json' -d'{"content":"公安部:各地校车将享最高路权"}'curl -XPOST http://172.16.1.127:9200/index/fulltext/3?pretty -H 'Content-Type:application/json' -d'{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}'curl -XPOST http://172.16.1.127:9200/index/fulltext/4?pretty -H 'Content-Type:application/json' -d'{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}'curl -XPOST http://172.16.1.127:9200/index/fulltext/_search?pretty -H 'Content-Type:application/json' -d'{"query" : { "match" : { "content" : "中国" }},"highlight" : {"pre_tags" : ["" , "" ],"post_tags" : ["", ""],"fields" : {"content" : {}}}}


版权声明:
文章不错?点个【在看】吧! ?