
快速re-ranking只需9.4毫秒:基于图网络的并行加速

极市导读
本文介绍作者项目组里的新工作,小组重新思考了re-ranking并提出了一个高并行的GNN的实现方式。将传统的re-ranking过程划分为两个阶段:检索出高质量的样本和更新特征。在Market-1501数据集上,小组把re-ranking过程从89.2s加速到了实时的9.4ms(约10000倍), 主要是利用了高并行的GNN架构在K40m GPU上做了加速。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
论文地址:https://arxiv.org/abs/2012.07620
作者:Xuanmeng Zhang, Minyue Jiang, Zhedong Zheng, Xiao Tan, Errui Ding, Yi Yang
代码地址(在百度审查后公布):Xuanmeng-Zhang/gnn-re-ranking
我目前正在百度视觉技术部车辆组实习,这是刚完成的一个工作,组里的氛围非常棒,能学到很多东西,欢迎大家来百度实习,有意向的同学可以把简历发到jiangminyue@baidu.com.
摘要
re-ranking是图像检索中一个广泛采用的后处理方法。但是,re-ranking一个主要的缺陷是高复杂度的计算量带来的巨大时间消耗,从而限制了在真实场景下的应用。在本文中,我们重新思考了re-ranking并提出了一个高并行的GNN的实现方式。具体来说,我们把传统的re-ranking过程划分为两个阶段:检索出高质量的样本和更新特征。我们认为第一阶段可以被构建k-近邻图替代,同时第二阶段可以通过在图上传播消息来完成。在Market-1501数据集上,我们把re-ranking过程从89.2s加速到了实时的9.4ms(约10000倍), 主要是利用了高并行的GNN架构在K40m GPU上做了加速。
引言
re-ranking通过利用高置信度的样本来对初始的检索结果重新排序。作为一种后处理方法,re-ranking被广泛运用在很多图象检索任务中,包括行人重识别,车辆重识别和定位任务。re-ranking主要可以分为两类:基于特征相似度和基于邻近样本相似度。特征相似度是通过特征之间的欧氏距离来计算,而邻近样本相似度是通过初始检索结果的top-k中共有的样本来计算的。举个例子,如果两个样本的检索列表top-k中共享的样本越多,那么他们的邻近样本相似度就越高。总的来说,基于邻近样本相似度的方法性能更好。这是因为一个难样本和query的特征相似度很高,但他们共有的top-k却往往不同(很难和其他所有的正样本都相似)。考虑到对负样本的鲁棒性,我们这里主要研究的是基于邻近样本相似度的re-ranking。但高计算复杂度让这类方法很难运用到实际场景中。例如k-reciprocal [1] 需要先用query检索到top-k的邻近样本,然后在通过这些样本再次重新检索并取交集比较,这引入了大量的额外计算。
为了解决这个问题,我们尝试通过并行的方式来实现这个过程。因为需要处理的数据是一个图状结构,我们引入了高并行的GNN来处理结构数据。我们把re-ranking划分为两个阶段,在第一阶段,我们通过构造knn图来建立数据之间的拓扑结构。在第二阶段,我们通过GNN来聚合并传播样本的特征。在Market-1501,VeRi-776,Oxford-5k, Paris-6k和University-1652等数据集上的实验显示了提出的方法能够大幅加速并达到有竞争力甚至更好的性能。
方法
问题定义:
给定一张query图片q和一个gallery的集和G, 图像检索需要找出从大量的候选图片中找出相关的图片。通常,我们把图像映射到一个语义特征空间并根据特征相似度排序得到初始检索列表。然后re-ranking方法能够进一步来修正初始检索结果。
建图
在一阶段我们需要建图,首先,我们计算出所有特征的相似度矩阵S:
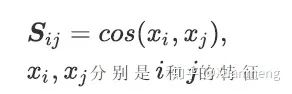
通过矩阵S我们能够构建出整个图G的邻接矩阵A:
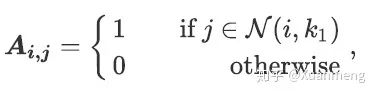
然而,一个理想的邻接矩阵应该是对称的,同时,如果两个样本互为邻近关系,他们应该被分配更大的权重,我们进一步计算得到新矩阵:
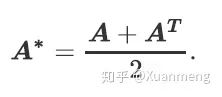
我们取A*的第i行作为节点i的顶点特征,通过这种方式,我们基于临近样本相似度建立了节点的特征。然后我们选取连接了高置信度的临近样本并定义边的权重为:
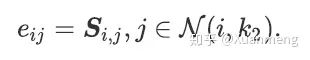
消息传递
在二阶段,我们通过聚合并传播特征来提升检索性能。受nmpn [2] 的启发,我们提出了一个简单的图网络来聚合高置信度的节点特征:
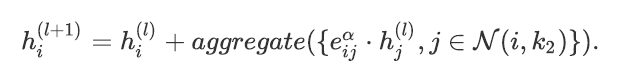
因为高并行的GNN能够很有效的在稀疏图上传播消息,我们能够同时更新所有的特征,进而达到实时更新的性能。
和现有方法的比较
我们的方法主要和两类方法有关:k-reciprocal re-ranking [1]和GNN。这里我们和k-reciprocal分析进行对比。
在阶段一,k-reciprocal需要计算Jaccard距离。然而,这需要首先选出k-reciprocal的临近样本来作为候选集和,然后进一步找出query和gallery的共享邻近样本来增加候选集合,这样双向验证的方式需要大量顺序和集合操作。相比之下,我们的方法通过建立knn图来进行关系建模,可以很容易的通过矩阵运算来实现,进而在GPU上实现加速。
在阶段二,传统方法直接采用了local query expansion的方式,然后这只能在一个局部区域以平均的权重进行消息传播。作为对比,我们的方法通过边的权重在整个建好的图上进行传播,同时结合了局部和全局的信息并很好的利用了图的拓扑结构。更进一步,我们可以通过增加GNN的层数来进一步优化特征。
实验
我们在五个数据集上进行了实验,首先我们比较了时间代价。

然后比较了检索性能:

可以看到,我们提出的方法在速度和性能上找到了一个平衡点。总的来说,我们的方法在大多数数据集上取得了最好或者第二好的性能表现,并在gpu上实现了实时的性能。
[1] Zhong, Zhun, Liang Zheng, Donglin Cao, and Shaozi Li. "Re-ranking person re-identification with k-reciprocal encoding." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1318-1327. 2017.
[2] Gilmer, Justin, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. "Neural message passing for Quantum chemistry." In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1263-1272. 2017.
感谢看完~~ 欢迎点赞转发评论~~
欢迎大家关注我们实验室ReLER(https://zhuanlan.zhihu.com/reler-lab)的后续工作!
推荐阅读
