
CNN可视化技术总结
共 10486字,需浏览 21分钟
·
2021-02-25 22:02

极市导读
本文基本介绍完了目前CNN可视化的一些方法,即特征图可视化,卷积核可视化和类可视化,并总结了一些可视化工具与项目。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录:
1.特征图可视化方法
2.卷积核可视化
3.类可视化
4.可视化工具与项目
一、特征图可视化方法
在CV很多方向所谓改进模型,改进网络,都是在按照人的主观思想在改进,常常在说CNN的本质是提取特征,但并不知道它提取了什么特征,哪些区域对于识别真正起作用,也不知道网络是根据什么得出了分类结果。如在上次解读的一篇论文《Feature Pyramid Transformer》(简称FPT)中,作者提出背景信息对于识别目标有重要作用,因为电脑肯定是在桌上,而不是水里,大街上,背景中的键盘鼠标的存在也能辅助区分电脑与电视机,因此作者提出要使用特征金字塔融合背景信息。从人的主观判断来看,这点非常合理。但对于神经网络来说,FPT真的有融合背景信息,而普通CNN网络没有融合背景信息?又或者说,一般而言,除了提出的新模型,还会加上主观设计的各种tricks,确定最后是因为融合了背景信息而精度提高了,还是说背景确实融合了,但实际上对精度没有影响,而是各种tricks起了作用?这一切并不确定,因为并不确定CNN到底学到了什么。
解决这个问题的办法有很多,一个是想办法看看CNN内部学到了什么,一个是控制变量法。提到这个控制变量法,在某一篇论文中(我对不起我的读者,论文累积量太大,忘记是哪一篇,只记得该论文的一些新颖之处),在设计了一个新的模型后,通过改变卷积层的某些通道,来看最后模型的精度的变化,从而确定哪些通道对这个模型是真正起作用的,而哪些是冗余的。按照这个思路,我们或许可以在数据预处理时,故意裁剪掉人主观认为有用的背景信息,例如裁剪辅助识别电脑的桌子,键盘鼠标,重新训练FPT,从而看最终精度有没有影响。很明显,这种方法理论上是可行的,但实际上工作量巨大,不现实。而CNN可视化是值得考虑的方法。
除了上面提到的一点,CNN可视化的作用还有哪些?
在少数提出新模型或新methods的论文中,往往会给出这个模型的一些可视化图来证明这个模型或这个新methods对于任务的作用,这一点不仅能增加新模型或新methods可信度,也能起到增加工作量,增加论文字数的作用,如研究者想到一个method,一两页就介绍加推理加证明完了,效果明显,但作为一篇论文却字数太少,工作量不够多,就可以考虑可视化使用了这个methods的网络与没有使用这个methods的网络,进行对比,分析分析,就可以变成一篇完整的论文了。此外,CNN可视化还有一个作用,根据可视化某个网络的结果分析其不足之处,从而提出新的改进方法。例如:ZFNet正是对AlexNet进行可视化后改进而来,获得了ILSVRC2014的冠军。
CNN可视化方法
一、特征图可视化。特征图可视化有两类方法,一类是直接将某一层的feature map映射到0-255的范围,变成图像。另一类是使用一个反卷积网络(反卷积、反池化)将feature map变成图像,从而达到可视化feature map的目的。
二、卷积核可视化。
三、类激活可视化。这个主要用于确定图像哪些区域对识别某个类起主要作用。如常见的热力图(Heat Map),在识别猫时,热力图可直观看出图像中每个区域对识别猫的作用大小。这个目前主要用的方法有CAM系列(CAM、Grad-CAM、Grad-CAM++)。
四、一些技术工具。通过一些研究人员开源出来的工具可视化CNN模型某一层。
CNN技术总结将按照这四个方法,分成四个部分总结CNN可视化技术。对于以后出现新的技术,或者补充,将更新在公众号CV技术指南的技术总结部分。在本文,主要介绍第一类方法,特征图可视化。
直接可视化
单通道特征图可视化,由于feature map并不是在0-255范围,因此需要将其进行归一化。以pytorch为例,使用torchvision.utils.make_grid()函数实现归一化
def make_grid(tensor, nrow=8, padding=2,normalize=True, range=None,=False,pad_value=0):
多通道特征图的显示,即对某一层所有通道上的特征图融合显示,在使用make_grid函数后,pytorch环境下可使用tensorboardX下的SummerWriterh中的add_image函数。
本部分内容参考链接:https://zhuanlan.zhihu.com/p/60753993
反卷积网络( deconvnet )
feature map可视化的另一种方式是通过反卷积网络从feature map变成图像。反卷积网络在论文《Visualizing and Understanding Convolutional Networks》中提出,论文中提出图像像素经过神经网络映射到特征空间,而反卷积网络可以将feature map映射回像素空间。
如下图所示,反卷积网络的用途是对一个训练好的神经网络中任意一层feature map经过反卷积网络后重构出像素空间,主要操作是反池化unpooling、修正rectify、滤波filter,换句话说就是反池化,反激活,反卷积。
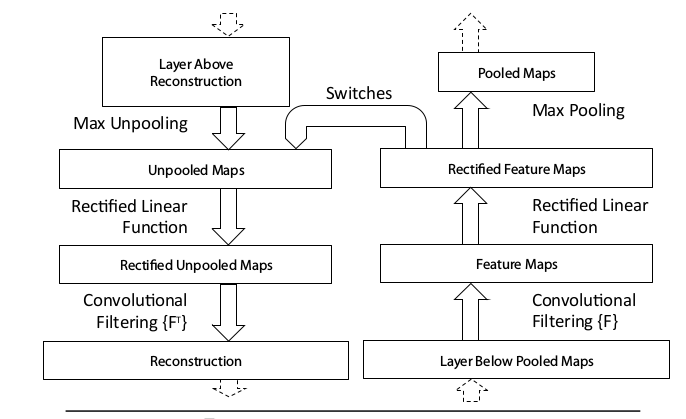
由于不可能获取标签数据,因此反卷积网络是一个无监督的,不具备学习能力的,就像一个训练好的网络的检测器,或者说是一个复杂的映射函数。
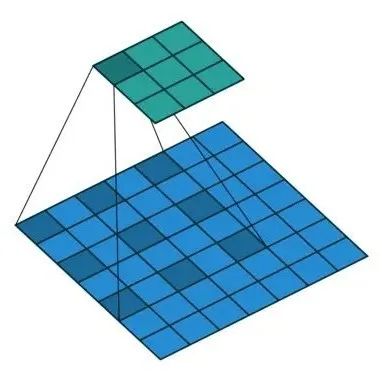
反池化Unpooling
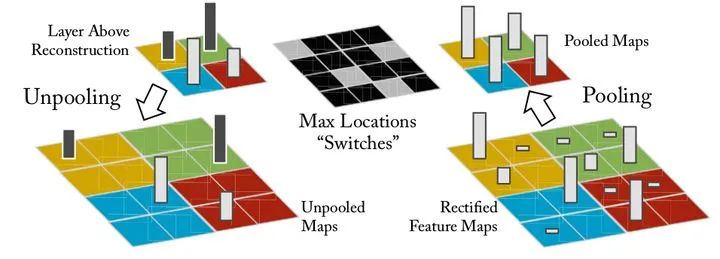
在上一篇文章《池化技术总结》中提到最大池化会记录最大值的坐标,在上图中就是switches,而反池化就只需要将最大值放到原位置,而其他位置的值并不知道,直接置零。如下图所示。
修正Rectification
CNN使用ReLU确保feature map上的值都是正的,因此在反卷积中也使用ReLU。这里所谓Rectification其实就是让unpooling后的值都是正的,换句话说就是使用ReLU。
Filtering
Filtering指的是反卷积,具体操作就是使用原网络的卷积核的转置作为卷积核,对Rectification后的输出进行卷积。
注:在以上重构过程中没有使用对比归一化操作。
反卷积网络特征可视化结果

导向反向传播
在论文《Striving for Simplicity:The All Convolutional Net》中提出使用导向反向传播(Guided-backpropagation),导向反向传播与反卷积网络的区别在于对ReLU的处理方式。在反卷积网络中使用ReLU处理梯度,只回传梯度大于0的位置,而在普通反向传播中只回传feature map中大于0的位置,在导向反向传播中结合这两者,只回传输入和梯度都大于0的位置,这相当于在普通反向传播的基础上增加了来自更高层的额外的指导信号,这阻止了负梯度的反传流动,梯度小于0的神经元降低了正对应更高层单元中我们想要可视化的区域的激活值。

使用导向反向传播与反卷积网络的效果对比

明显使用导向反向传播比反卷积网络效果更好。
总结:分析反卷积网络的对各层feature map可视化的结果可知,CNN中会学到图像中的一些主要特征,如狗头,鼻子眼睛,纹理,轮廓等内容。但对特征图可视化有个明显的不足,即无法可视化图像中哪些区域对识别具体某个类别的作用,这个主要是使用CAM系列的方法,下文将进行讲解。
二、卷积核可视化
上面我们介绍了特征图可视化方法,对于特征图可视化的方法(或者说原理)比较容易理解,即把feature map从特征空间通过反卷积网络映射回像素空间。
那卷积核怎样可视化呢,基于什么原理来可视化?卷积核的尺寸一般只有3x3, 5x5大小,如何可视化?下面将介绍这个两个内容。
卷积核可视化的原理
卷积核,在网络中起到将图像从像素空间映射到特征空间的作用,可认为是一个映射函数,像素空间中的值经过卷积核后得到响应值,在特征提取网络中,基本都是使用最大池化来选择最大响应值进入下一层继续卷积,其余响应值低的都进入待定。也就是说,我们认定只有响应值大的才会对最终的识别任务起作用。
根据这个思路,给定一个已经训练好的网络,现在想要可视化某一层的某一个卷积核,我们随机初始化生成一张图(指的是对像素值随机取值,不是数据集中随机选一张图),然后经过前向传播到该层,我们希望这个随机生成的图在经过这一层卷积核时,它的响应值能尽可能的大,换句话说,响应值比较大的图像是这个卷积核比较认可的,是与识别任务更相关的。然后不断调整图像像素值,直到响应值足够大,我们就可以认为此时的图像就是这个卷积核所认可的,从而达到可视化该卷积核的目的。
理解了它的原理后,它的实现方法就比较简单了,设计一个损失函数,即以经过该层卷积核后的响应值为目标函数,使用梯度上升,更新像素值,使响应值最大。
实现代码
Setup
import numpy as npimport tensorflow as tffrom tensorflow import keras# The dimensions of our input imageimg_width = 180img_height = 180# Our target layer: we will visualize the filters from this layer.# See `model.summary()` for list of layer names, if you want to change this.layer_name = "conv3_block4_out"Build a feature extraction model
# Build a ResNet50V2 model loaded with pre-trained ImageNet weightsmodel = keras.applications.ResNet50V2(weights="imagenet", include_top=False)# Set up a model that returns the activation values for our target layerlayer = model.get_layer(name=layer_name)feature_extractor = keras.Model(inputs=model.inputs, outputs=layer.output)Set up the gradient ascent process
loss函数取最大化指定卷积核的响应值的平均值,为了避免边界的影响,边界的响应值不计。
def compute_loss(input_image, filter_index):activation = feature_extractor(input_image)# We avoid border artifacts by only involving non-border pixels in the loss.filter_activation = activation[:, 2:-2, 2:-2, filter_index]return tf.reduce_mean(filter_activation)@tf.functiondef gradient_ascent_step(img, filter_index, learning_rate):with tf.GradientTape() as tape:tape.watch(img)loss = compute_loss(img, filter_index)# Compute gradients.grads = tape.gradient(loss, img)# Normalize gradients.grads = tf.math.l2_normalize(grads)img += learning_rate * gradsreturn loss, imgSet up the end-to-end filter visualization loop
def initialize_image():# We start from a gray image with some random noiseimg = tf.random.uniform((1, img_width, img_height, 3))# ResNet50V2 expects inputs in the range [-1, +1].# Here we scale our random inputs to [-0.125, +0.125]return (img - 0.5) * 0.25def visualize_filter(filter_index):# We run gradient ascent for 20 stepsiterations = 30learning_rate = 10.0img = initialize_image()for iteration in range(iterations):img = gradient_ascent_step(img, filter_index, learning_rate)# Decode the resulting input imageimg = deprocess_image(img[0].numpy())return loss, imgdef deprocess_image(img):# Normalize array: center on 0., ensure variance is 0.15img -= img.mean()img /= img.std() + 1e-5img *= 0.15# Center cropimg = img[25:-25, 25:-25, :]# Clip to [0, 1]img += 0.5img = np.clip(img, 0, 1)# Convert to RGB arrayimg *= 255img = np.clip(img, 0, 255).astype("uint8")return img
可视化效果图
可视化vgg16卷积核





总结:本部分内容介绍了一种可视化卷积核的方法,即通过生成指定卷积核响应值尽可能大的图像来达到可视化卷积核的目的,使用的方法是梯度上升。
在不少论文的末尾都有可视化卷积核来分析提出的模型,该方法值得了解。
三、类可视化
前面我们介绍了两种可视化方法,特征图可视化和卷积核可视化,这两种方法在论文中都比较常见,这两种更多的是用于分析模型在某一层学习到的东西。在理解这两种可视化方法,很容易理解图像是如何经过神经网络后得到识别分类。
然而,上次我在知乎看到一个通过yolov3做跌倒检测,希望加上人脸识别进行多任务学习从而提高准确率的提问。这明显提问者并不理解神经网络是如何对这种带有时间维度的视频进行分析从而实现行为识别,从本质上来讲,这其实是不理解神经网络具体是如何识别一个类的。因此,当在这一点上理解错误后,所进行的模型选择、方案设计和改进,就都是不合理的。
(我在知乎上回答了这个问题正确的跌倒检测思路应该是什么,感兴趣的可以去看看)
因此,在下面的文字中,我们将介绍一种对于不同的类,如何知道模型根据哪些信息来识别的方法,即对类进行可视化,通俗一点来说就是热力图。这个方法主要是CAM系列,目前有CAM, Grad-CAM, Grad-CAM++。
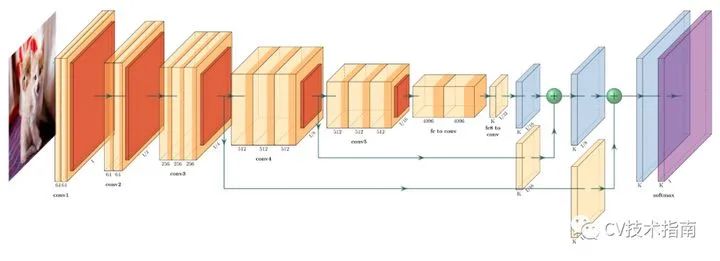
CAM(Class Activation Map)

如上图所示,CAM的结构由CNN特征提取网络,全局平均池化GAP,全连接层和Softmax组成。
实现原理:一张图片在经过CNN特征提取网络后得到feature maps, 再对每一个feature map进行全局平均池化,变成一维向量,再经过全连接层与softmax得到类的概率。
假定在GAP前是n个通道,则经过GAP后得到的是一个长度为1x n的向量,假定类别数为m,则全连接层的权值为一个n x m的张量。(注:这里先忽视batch-size)
对于某一个类别C, 现在想要可视化这个模型对于识别类别C,原图像的哪些区域起主要作用,换句话说模型是根据哪些信息得到该图像就是类别C。
做法是取出全连接层中得到类别C的概率的那一维权值,用W表示,即上图的下半部分。然后对GAP前的feature map进行加权求和,由于此时feature map不是原图像大小,在加权求和后还需要进行上采样,即可得到Class Activation Map。
用公式表示如下:(k表示通道,c表示类别,fk(x,y)表示feature map)
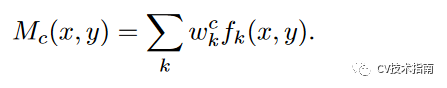
效果图:

CAM的分析
CAM有个很致命的缺陷,它的结构是由CNN + GAP + FC + Softmax组成,也就是说如果想要可视化某个现有的模型,但大部分现有的模型没有GAP这个操作,此时想要可视化便需要修改原模型结构,并重新训练,相当麻烦,且如果模型很大,在修改后重新训练不一定能达到原效果,可视化也就没有意义了。
因此,针对这个缺陷,其后续有了改进版Grad-CAM。
Grad-CAM
Grad-CAM的最大特点就是不再需要修改现有的模型结构了,也不需要重新训练了,直接在原模型上即可可视化。
原理:同样是处理CNN特征提取网络的最后一层feature maps。Grad-CAM对于想要可视化的类别C,使最后输出的类别C的概率值通过反向传播到最后一层feature maps,得到类别C对该feature maps的每个像素的梯度值,对每个像素的梯度值取全局平均池化,即可得到对feature maps的加权系数alpha,论文中提到这样获取的加权系数跟CAM中的系数几乎是等价的。接下来对特征图加权求和,使用ReLU进行修正,再进行上采样。
使用ReLU的原因是对于那些负值,可认为与识别类别C无关,这些负值可能是与其他类别有关,而正值才是对识别C有正面影响的。
用公式表示如下:
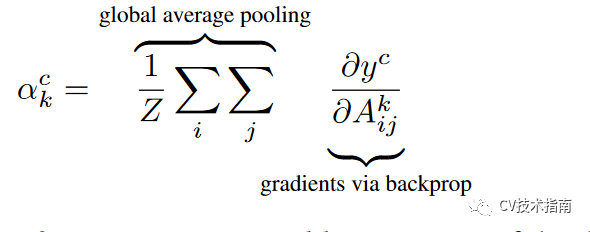

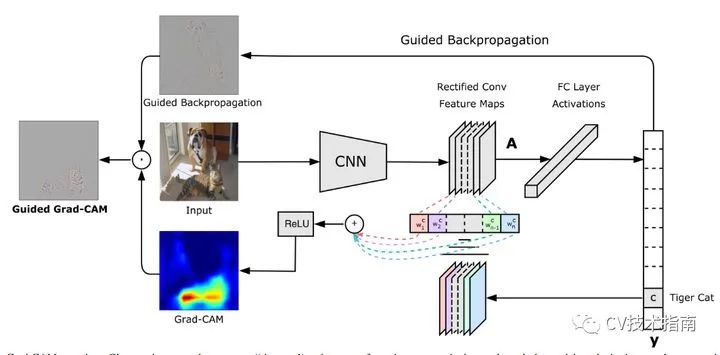
Grad-CAM的结构图如上图所示,对于Guided Backpropagation不了解的读者,可看CNN可视化技术总结的第一篇文章。
效果图如下:
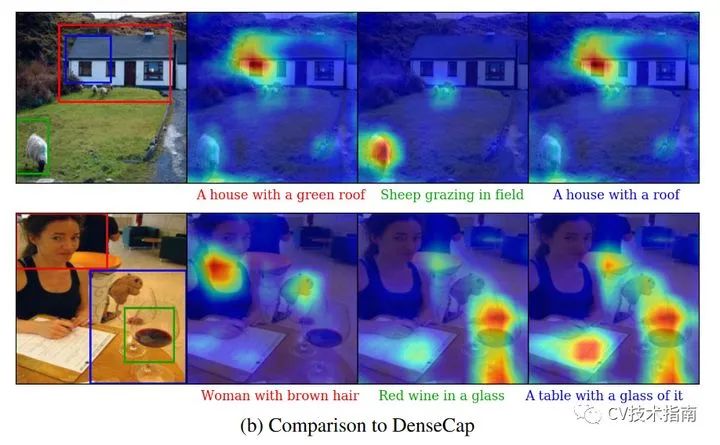
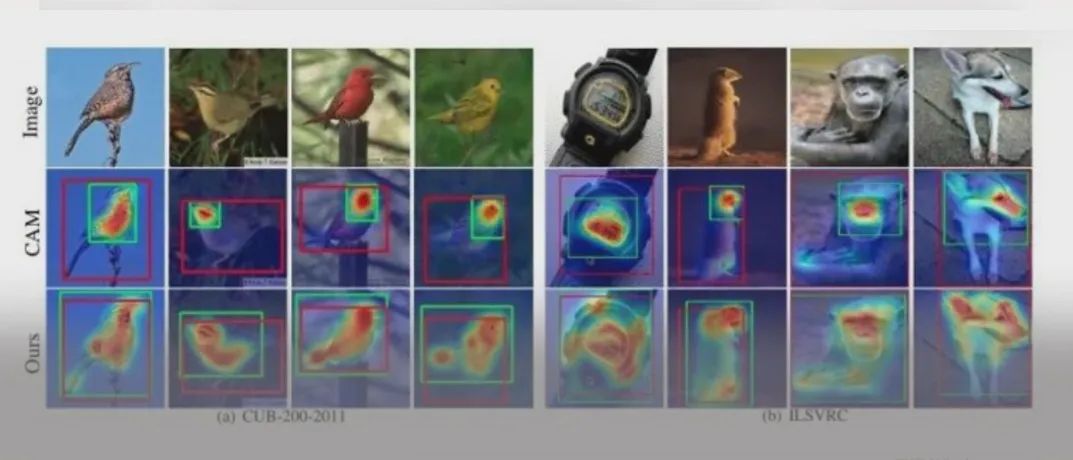
Grad-CAM后续还有改进版Grad-CAM++,其主要的改进效果是定位更准确,更适合同类多目标的情况,所谓同类多目标是指一张图像中对于某个类出现多个目标,例如七八个人。
改进方法是对加权系数的获取提出新的方法,该方法复杂到不忍直视。因此这里就不介绍了,感兴趣的读者可以阅读该论文:
CAM: arxiv.org/pdf/1512.0415
Grad-CAM: arxiv.org/pdf/1610.0239
Grad-CAM++: arxiv.org/pdf/1710.1106
四、可视化工具与项目
前面介绍了可视化的三种方法--特征图可视化,卷积核可视化,类可视化,这三种方法在很多提出新模型或新方法的论文中很常见,其主要作用是提高模型或者新方法的可信度,或者用来增加工作量,或者用来凑字数,还有一些作用是帮助理解模型针对某个具体任务是如何学习,学到了哪些信息,哪些区域对于识别有影响等。
本文将介绍一些可视化的项目,主要有CNN解释器,特征图、卷积核、类可视化的一些代码和项目,结构可视化工具,网络结构手动画图工具。
1. CNN-Explainer
这是一个中国博士发布的名叫CNN解释器的在线交互可视化工具。主要对于那些初学深度学习的小白们 理解关于神经网络是如何工作很有帮助,如卷积过程,ReLU过程,平均池化过程,中间每一层的特征图的样子,都可以看到,相当于给了一个显微镜,可以随意对任意一层,任何一项操作的前后变化,观察得清清楚楚。
显示卷积的过程中前后特征图的变化,中间的操作。
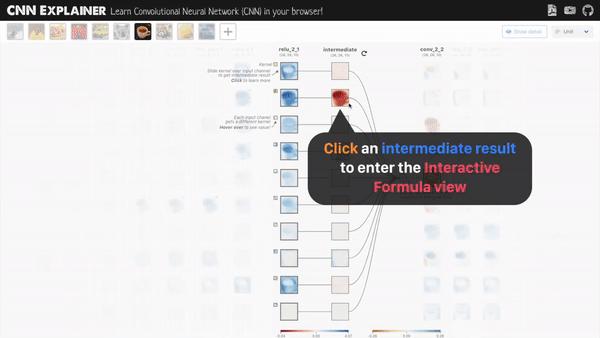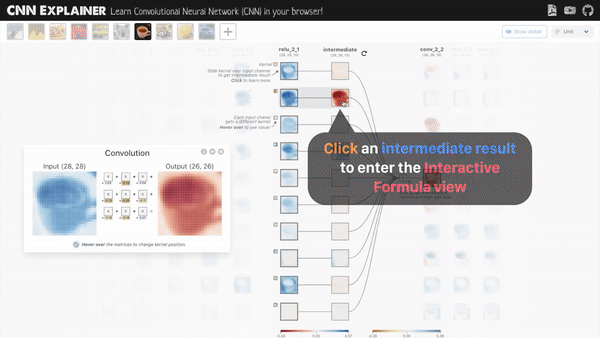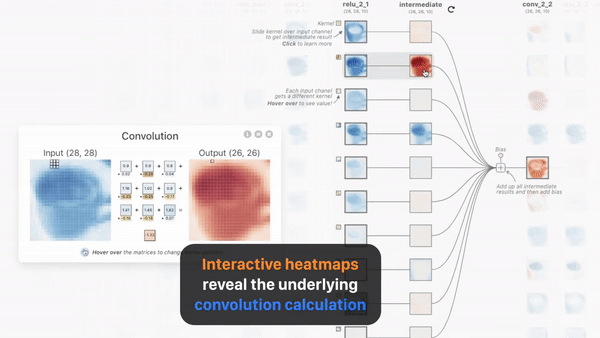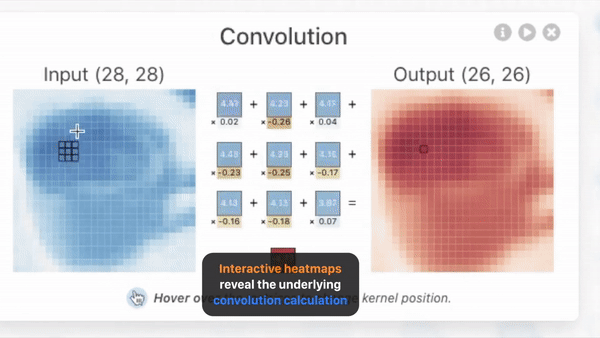
CNN是如何输出预测的
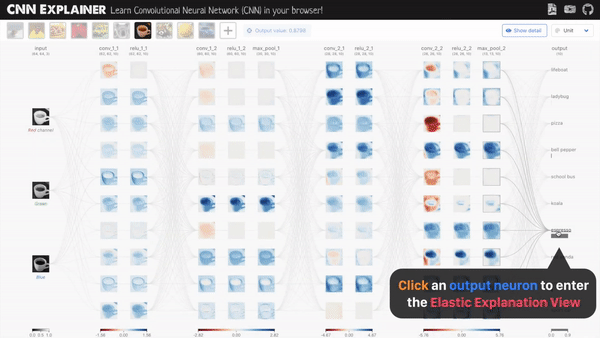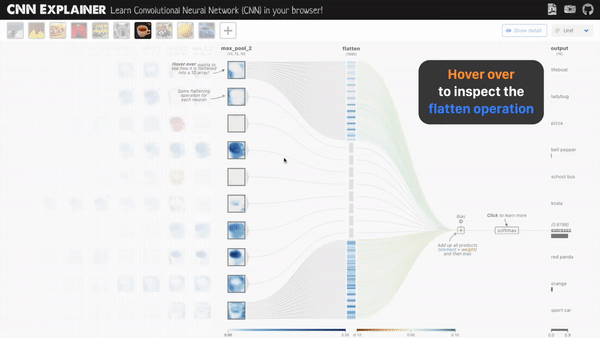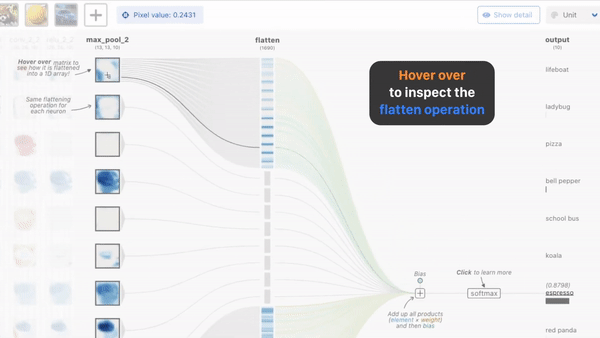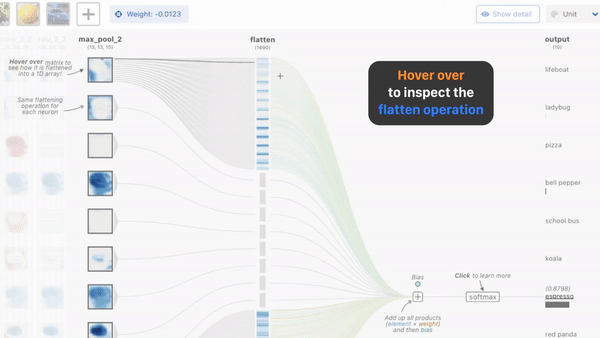
还可以在线上传图片,看到一张图片在经过每一层的卷积,池化,激活后的变化,最后输出预测结果。
项目链接:
https://github.com/poloclub/cnn-explainer
2. 一些可视化特征图、卷积核、热力图的代码。
可视化特征图
https://github.com/waallf/Viusal-feature-map
可视化卷积核
https://keras.io/examples/vision/visualizing_what_convnets_learn/
https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
Grad-CAM
https://github.com/ramprs/grad-cam
热力图
https://github.com/heuritech/convnets-keras
下面这个项目是同时包含特征图可视化,卷积核可视化和热力图的一个链接:
https://github.com/raghakot/keras-vis
3. 结构可视化工具
Netscope
用于可视化模型结构的在线工具,仅支持caffe的prototxt文件可视化。需要自己写prototxt格式的文件。

此图来源于网络,侵删
项目地址:
https://github.com/ethereon/netscope
ConvNetDraw
这个工具用两个图可直接说明,第一个是输入,第二个是输出
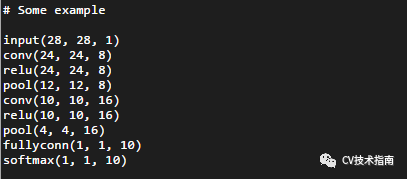
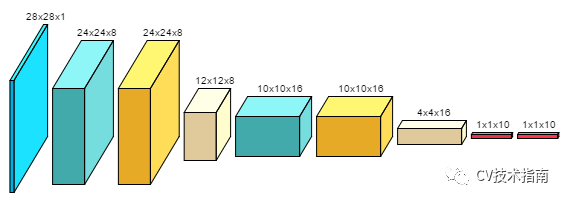
这两个图来源于网络,侵删
项目地址:
https://github.com/cbovar/ConvNetDraw
PlotNeuralNet
这个稍微麻烦一点点,效果图如下:
项目地址:
https://github.com/HarisIqbal88/PlotNeuralNet
4. 网络结构手动画图工具
很多新手会问的一个问题,论文中那些网络结构图是如何画的。
这里解答一下,我所了解的主要是用PPT, VISIO。当然也可以使用上面那几个。
再补充一个在线工具,NN-SVG
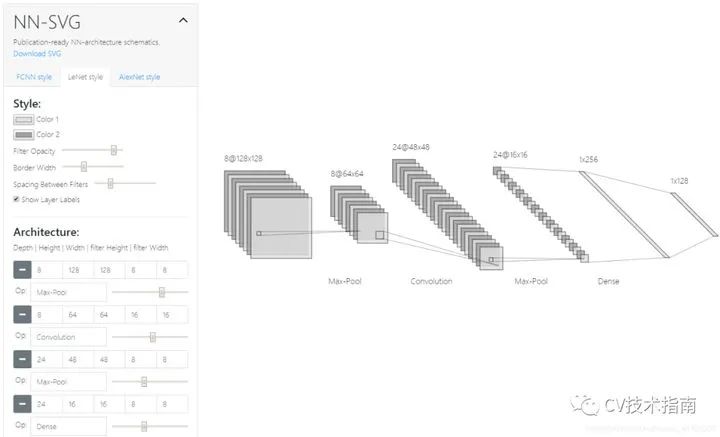
项目地址:http://alexlenail.me/NN-SVG/
总结
这四篇文章基本介绍完了目前CNN可视化的一些方法,即特征图可视化,卷积核可视化和类可视化,总结了一些可视化工具与项目,当然不免也有个别遗漏的,日后若有一些比较重大突破的一些可视化工具出来,将继续补充。
对于可视化,其实还包括训练过程的可视化,如Loss值,精度等实时更新,这个比较简单,就不在这个总结系列里说明了。
代码与可视化图的参考链接:
参考论文:
1.《Visualizing and Understanding Convolutional Networks》
2.《Striving for Simplicity:The All Convolutional Net》
3. Learning Deep Features for Discriminative Localization
4.Grad-CAM: Why did you say that?Visual Explanations from Deep Networks via Gradient-based Localization
5.Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks
推荐阅读
2021-02-23

2021-02-17
2021-02-16

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
