
重大更新!一文了解京东通用目标重识别开源库FastReID V1.0

2020年6月,京东 AI 研究院发布了基于PyTorch的通用目标重识别(ReID)开源库FastReID。经过了最近半年的持续优化,2021年1月18日京东AI研究院发布了更新版本FastReID V1.0。在京东内部,FastReID已经获得广泛地应用于智能园区、智能楼宇、智能供应链、线下零售等实际项目中。
*GitHub链接:
https://github.com/JDAI-CV/fast-reid
“口罩识别”,这或许是国内抵抗疫情传播工作中,最基本也是最常见的信息核实手段。除此之外,高速路车流车牌监控、公共场所安防侦查......这些大部分人都不会刻意关注的应用,同样在给生活带来越来越多的便利。
但在“有意遮挡”以及隐私安全的把控上,这项技术的“便利”总伴随着一些风险与挑战。而通用目标重识别(ReID )正是其中最不可或缺的技术。
为满足通用实例重识别日益增长的应用需求,京东AI研究院于2020年6月发布基于PyTorch的通用目标重识别(ReID)开源库FastReID,并受到了许多用户的欢迎与反馈。经过半年多持续优化,2021年1月18日FastReID V1.0携重大更新“惊艳亮相”。
在了解FastReIDV1.0带来了哪些新功能与新思路之前,我们先来“破破冰”,了解一下究竟什么是通用目标重识别(ReID)。

通用目标重识别(ReID )又称跨境追踪,全称Re-identification,也就是重识别的意思。简单理解就是对于一个特定的目标(可能是行人、车辆或者其他特定物体),在候选图像集中检索到它,或称图像中目标的实例级检索。
再通俗一些,ReID算法能够通过视频监控系统,在跨摄像头的条件下,对无法获取清晰拍摄的特定目标进行跨摄像头连续跟踪,大大拓展摄像资源的利用深度,增强数据的时空连续性,并降低人力成本。
ReID可以作为识别技术的重要补充,提升对特定目标的识别追踪能力,适用于更多新的应用场景,将人工智能的认知水平提高到一个新阶段。
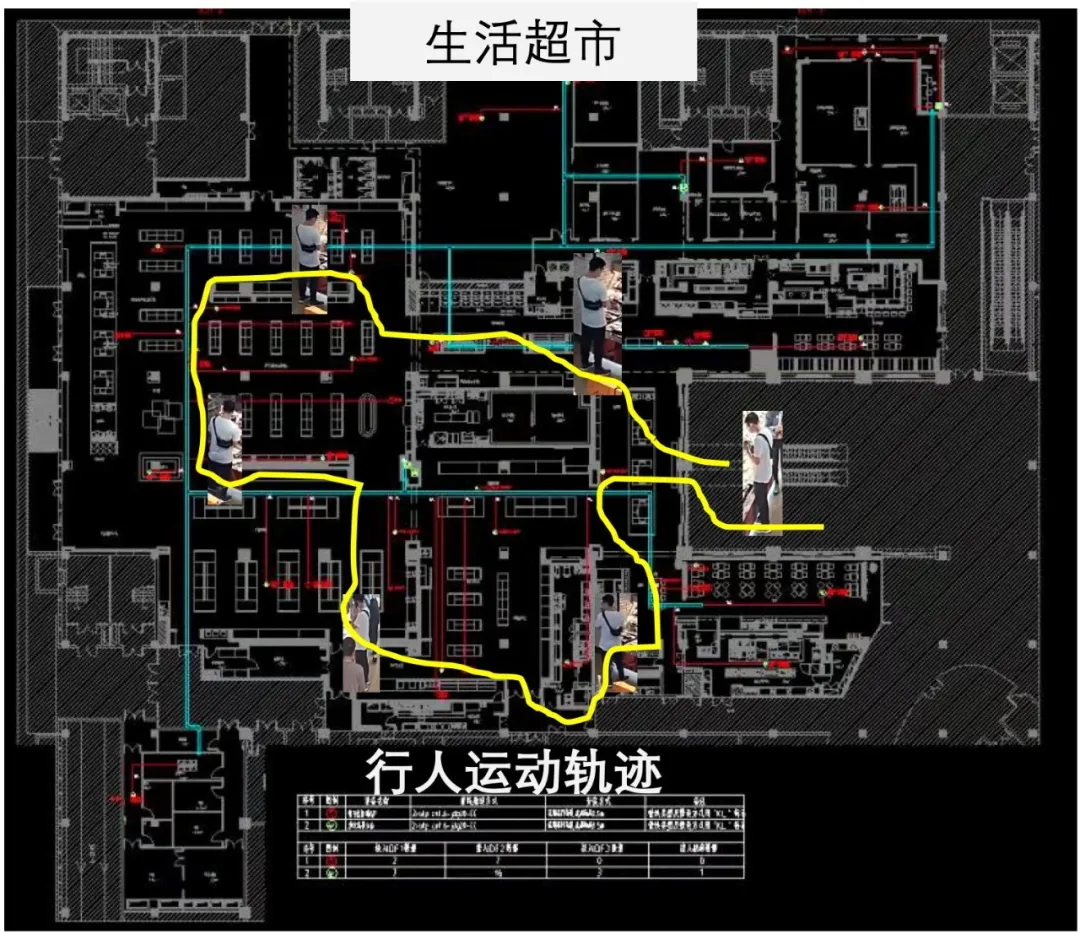
举个例子,下图是由四张图片构成,黄衣男子为某犯罪案件中重点观察对象。此人出现在多个摄像头画面中,但多张图像都极其模糊,仅有几个像素大小,导致识别算法失效,增加警察刑侦难度。这时,ReID 技术就可以根据行人的穿着、体貌,在各个摄像头中去检索,将其在各个不同摄像头出现的视频段关联起来,形成轨迹协助破案。

此外,在新零售场景中,ReID技术也可以让“人”与“场”之间的关系数据有办法被收集并以可视化的方式重现。商家对用户画像和用户行为有更强的感知,从而能够做出更准确的商业决策。同时,也为线下针对用户的个性化服务和精准营销提供了可能。

目前,ReID往往被应用到不同规模的特定目标轨迹分析上,这就会导致系统处理的数据规模快速成倍的增长,模型的推理速度变慢,最终使得ReID算法的性能不能被完全发挥。此外,ReID领域中的学术研究与工程模型部署存在着较大的差距,代码对齐问题使得学术研究成果很难直接转化为可落地的产品,限制其在大规模商业化场景中的应用。
为加速学术界研究人员和工业界工程师对重识别技术的发展,FastReID代码开源库应运而生。
参照了Detectron2的整体概念和设计哲学,FastReID设计成了一个高度模块化和可拓展的架构,从而可以让研究人员快速的实现新的idea;更重要的是,该框架友好的管理系统配置和工程部署函数可以让工程师快速的部署它。FastReID开源库可针对ReID任务提供完整的工具箱,包括模型训练、模型评估、模型部署等模块,并且实现了在多个任务中性能领先的模型。
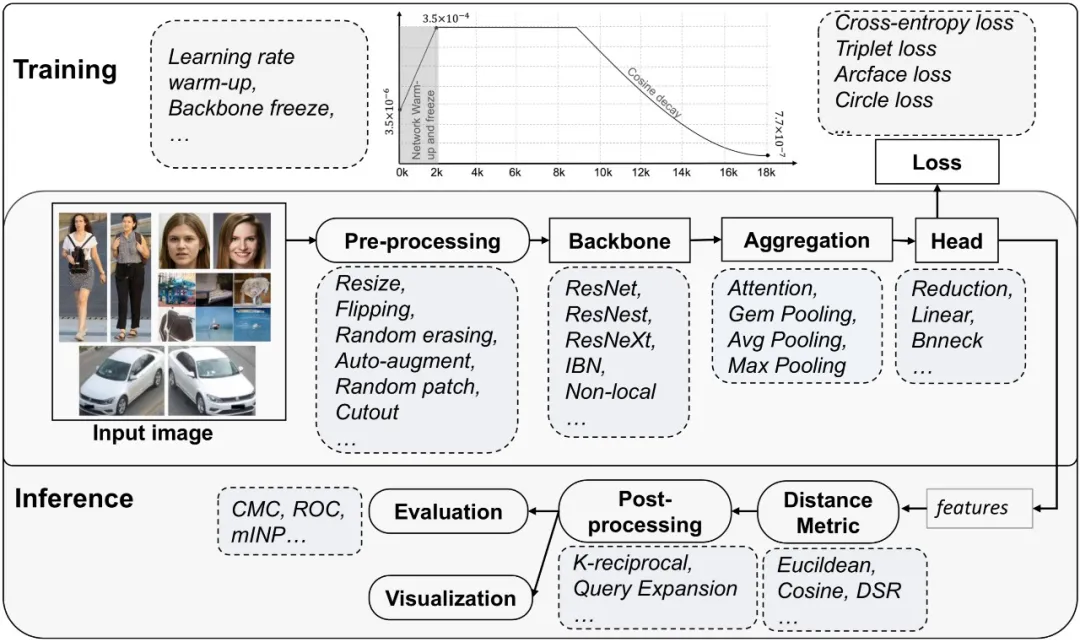
下图,完整列出了FastReID各个模块,上下分别为训练和推理。训练阶段包括模块:图像预处理(Preprocssing)、骨干网(Backbone)、聚合模块(Aggregation)、Head 模块、训练策略、损失函数;在推理阶段包含模块:度量部分,以及度量后处理指对检索结果的处理,包括K-reciprocal coding和 Query Expansion (QE) 两种重排序方法。
详细架构解析可见:
基于此,在 V1.0 的全新升级中,FastReID 经过对以上各个模块的优化,更新了FastReID V1.0 版本,不仅实现了更快的分布式训练和测试,提供模型一键转码(模型一键导出 caffe/onnx/tensorRT)等功能外,而且还实现了模型蒸馏,自动超参搜索以及更多任务的扩展,有潜力做更多的事情,也有了更多的应用场景。

深度神经网络一般有较多的信息冗余,同时模型太大会导致推理速度变慢,消耗更多计算资源,并且降低整个系统的响应速度。所以开发者通常需要在模型部署的时候,考虑对模型进行压缩,减小模型的参数量。
目前行业里有较多的模型压缩方式,比如剪枝,量化,蒸馏等等,其中蒸馏可以保证模型不需要进行结构修改的情况下,获得进一步的精度提升,从而可以在使用小模型部署时获得更好的性能。
虽然蒸馏发展了数十年,但通过大量的实验发现Hinton的Distilling the Knowledge in a Neural Network还是最solid的选择。基于这篇paper的方式,进一步将原本的蒸馏KL Div loss优化为具有对称性的JS Div loss,同时还优化了蒸馏的soft label生成方式。
不同于softmax分类loss,在embedding任务中通常会使用效果更好的margin-based softmax,比如arcface等等, 这时直接使用基于margin的logits生成soft label效果很不好,所以将soft label修改为去掉margin的logits输出。
除了可以对label进行蒸馏之外,也可以对feature进行蒸馏。通过实验了一大堆不work的特征蒸馏方法之后, FastReID发现overhaul-distillation可以在loss 蒸馏的基础上进一步对网络进行提升,所以也将该方法加入其中。由于overhaul需要对 backbone进行一些修改,获得激活函数relu之前的feature,通过构建了一个新的project去修改backbone而不是直接去FastReID里面修改 backbone,这样可以避免影响其他的project和以前训练的模型。
要在FastReID中使用蒸馏也非常简单,只需要首先按照正常的方式训练一个 teacher model,如果只想使用loss蒸馏,可以使用Distiller作为meta_arch。如果希望加上overhaul进行feature蒸馏,也只需要使用DistillerOverhaul作为meta_arch就可以。最后再指定teacher model的配置文件和训好的weights就可以了。
举个例子,用 R101_ibn 作为 teacher model,R34 作为 student model:
1# teacher model training
2python3 projects/FastDistill/train_net.py \
3--config-file projects/FastDistill/configs/sbs_r101ibn.yml \
4--num-gpus 4
5
6# loss distillation
7python3 projects/FastDistill/train_net.py \
8--config-file projects/FastDistill/configs/kd-sbs_r101ibn-sbs_r34.yaml \
9--num-gpus 4 \
10MODEL.META_ARCHITECTURE Distiller
11KD.MODEL_CONFIG projects/FastDistill/logs/dukemtmc/r101_ibn/config.yaml \
12KD.MODEL_WEIGHTS projects/FastDistill/logs/dukemtmc/r101_ibn/model_best.pth
13
14# loss+overhaul distillation
15python3 projects/FastDistill/train_net.py \
16--config-file projects/FastDistill/configs/kd-sbs_r101ibn-sbs_r34.yaml \
17--num-gpus 4 \
18MODEL.META_ARCHITECTURE DistillerOverhaul
19KD.MODEL_CONFIG projects/FastDistill/logs/dukemtmc/r101_ibn/config.yaml \
20KD.MODEL_WEIGHTS projects/FastDistill/logs/dukemtmc/r101_ibn/model_best.pth<左右滑动以查看完整代码>
FastReID V1.0优化了整体的代码结构,不仅能够同时兼顾算法研究和业务落地,还能使开发者更加方便地扩展不同的自定义任务,并能基于FastReID内部的核心代码,用少量代码即可实现一个新项目的开发。优化后的算法库不仅能够进行目标重识别的任务,同时还支持行人属性识别、地标检索、行人和车辆跟踪、图片分类等等任务。
其实,在之前的版本中,FastReID注重为算法研究提供便利,但是面对高速开发的业务, FastReID发现用户需要额外花费很多的时间去做相同的事情。这就意味着,FastReID不仅需要保留很好的灵活性能够支持算法研究,还需要有很强的扩展性能够支持大量自定义的业务快速开发。
然而,每种任务都有属于自己的一些特殊性,把这些特殊性全部往FastReID里面“塞”肯定不现实。为了不引入冗余性,我们通过对每种task单独构建project的方式对FastReID进行扩展,同时也为开发者提供了一些扩展任务的参考写法和example。
对于自定义的项目,开发者只需要判断是否需要加入新的配置文件、是否需要加入新的数据集、是否需要加入新的网络结构、是否需要加入新的测试协议等内容。如果这些内容在FastReID里面已经有现成的实现,那么直接将FastReID作为一个库导入相应的模块即可。对于内部没有实现的内容,开发者可以自己实现一个最小化的版本,与FastReID提供的内容进行拼接,这样就能够实现一个完整的自定义项目开发。
自开源至今,FastReID一直在努力思考如何让开发者上手更加容易。之前的版本中, FastReID具备扩展各种任务的能力,但却无法提供一些参考案例和demo。并且,由于之前的版本主要集中在目标重识别相关领域的模型训练和开发,FastReID所提供的配置文件和默认的超参数往往是针对重识别任务的,对于扩展的任务其实并不具有指导意义。
在新版的升级中,FastReID V1.0不仅为开发者提供了更多通用任务的最小实现模板,还提供了相应的配置文件和参数设定,方便开发者能够基于模板进行特定任务的简单修改。此外,为开发者在使用FastReID开发新项目时提供baseline结果,还能够避免开发者花费大量精力对不熟悉的任务进行调参。
众所周知,“炼丹”一直困扰着各位“调参侠”,特别是每次遇到新的场景,就需要重新调参来适应新的数据分布,非常浪费时间。而在FastReID V1.0中加入自动超参搜索的功能,就能解放各位“调参侠”的双手。
举个例子,如果你想用 Bayesian 超参搜索跑 12 组试验,可以使用下面的代码就可以开始自动分布式训练,如果有 4 张卡,那么可以 4 个试验同步一起跑。
1python3 projects/FastTune/tune_net.py \
2--config-file projects/FastTune/configs/search_trial.yml \
3--num-trials 12 --srch-alog "bohb"
<左右滑动以查看完整代码>
更具体的使用方式,请参考:https://github.com/JDAI-CV/fast-reid/issues/293 。

自2020年6月开源至今,FastReID在各种任务中的评测结果都表现得十分抢眼。这个SOTA级的ReID方法集合工具箱(SOTA ReID Methods and Toolbox),已面向学术界和工业界落地,并在京东内部该开源库已经成为了京东内部ReID技术研究和开发的核心引擎。
2021年,FastReID计划继续加入更多先进的算法,不断提高性能,提供更完善的文档、参考案例和demo,同时进一步优化计算效率,进一步提升大规模数据下的稳定性。
我们也热忱欢迎个人、实验室使用FastReID,互相交流,互相合作。希望在给ReID社区提供稳定高效代码实现的同时,大家也能够基于FastReID去做算法研究,扩展到更多其他任务上,共同加速人工智能研究,共同实现技术突破。



