
【小白学PyTorch】8.实战之MNIST小试牛刀
共 11771字,需浏览 24分钟
·
2020-09-21 18:06
<<小白学PyTorch>>
小白学PyTorch | 7 最新版本torchvision.transforms常用API翻译与讲解
小白学PyTorch | 6 模型的构建访问遍历存储(附代码)
小白学PyTorch | 5 torchvision预训练模型与数据集全览
小白学PyTorch | 3 浅谈Dataset和Dataloader
参考目录:
1 探索性数据分析
1.1 数据集基本信息
1.2 数据集可视化
1.3 类别是否均衡
2 训练与推理
2.1 构建dataset
2.2 构建模型类
2.3 训练模型
2.4 推理预测
1 探索性数据分析
一般在进行模型训练之前,都要做一个数据集分析的任务。这个在英文中一般缩写为EDA,也就是Exploring Data Analysis(好像是这个)。
数据集获取方面,这里本来是要使用之前课程提到的torchvision.datasets.MNIST(),但是考虑到这个torchvision提供的MNIST完整下载下来需要200M的大小,所以我就直接提供了MNIST的数据的CSV文件(包含train.csv和test.csv),大小压缩成.zip之后只有14M,代码就基于了这个数据文件。
1.1 数据集基本信息
import pandas as pd
# 读取训练集
train_df = pd.read_csv('./MNIST_csv/train.csv')
n_train = len(train_df)
n_pixels = len(train_df.columns) - 1
n_class = len(set(train_df['label']))
print('Number of training samples: {0}'.format(n_train))
print('Number of training pixels: {0}'.format(n_pixels))
print('Number of classes: {0}'.format(n_class))
# 读取测试集
test_df = pd.read_csv('./MNIST_csv/test.csv')
n_test = len(test_df)
n_pixels = len(test_df.columns)
print('Number of test samples: {0}'.format(n_test))
print('Number of test pixels: {0}'.format(n_pixels))
输出结果: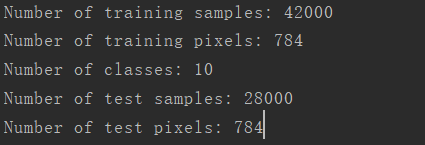
训练集有42000个图片,每个图片有784个像素(所以变成图片的话需要将784的像素变成),样本总共有10个类别,也就是0到9。测试集中有28000个样本。
1.2 数据集可视化
# 展示一些图片
import numpy as np
from torchvision.utils import make_grid
import torch
import matplotlib.pyplot as plt
random_sel = np.random.randint(len(train_df), size=8)
data = (train_df.iloc[random_sel,1:].values.reshape(-1,1,28,28)/255.)
grid = make_grid(torch.Tensor(data), nrow=8)
plt.rcParams['figure.figsize'] = (16, 2)
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.axis('off')
plt.show()
print(*list(train_df.iloc[random_sel, 0].values), sep = ', ')
输出结果有一个图片:
以及一行打印: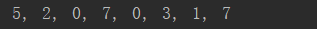
随机挑选了8个样本进行可视化,然后打印出来的是样本对应的标签值。
1.3 类别是否均衡
然后我们需要检查一下训练样本中类别是否均衡,利用直方图来检查:
# 检查类别是否不均衡
plt.figure(figsize=(8,5))
plt.bar(train_df['label'].value_counts().index, train_df['label'].value_counts())
plt.xticks(np.arange(n_class))
plt.xlabel('Class', fontsize=16)
plt.ylabel('Count', fontsize=16)
plt.grid('on', axis='y')
plt.show()
输出图像: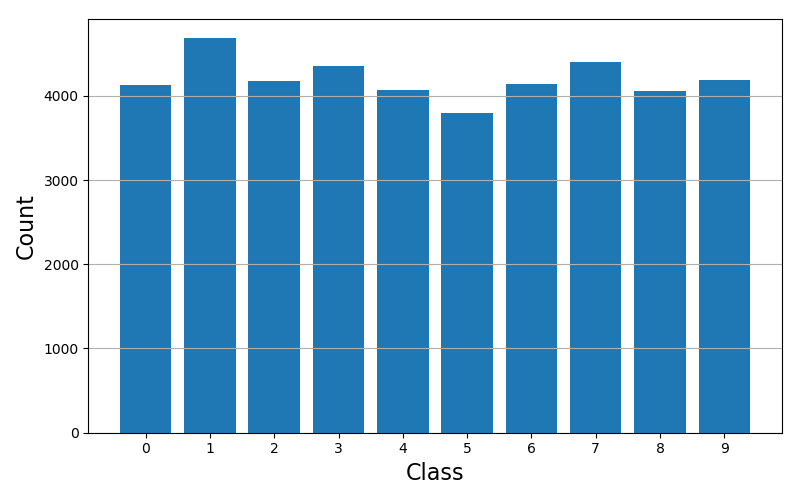
基本没毛病,是均衡的。
2 训练与推理
2.1 构建dataset
我们可以重新写一个python脚本,首先还是导入库和读取文件:
import pandas as pd
train_df = pd.read_csv('./MNIST_csv/train.csv')
test_df = pd.read_csv('./MNIST_csv/test.csv')
n_train = len(train_df)
n_test = len(test_df)
n_pixels = len(train_df.columns) - 1
n_class = len(set(train_df['label']))
然后构建一个Dataset,Dataset和Dataloader的知识前面的课程已经讲过了,这里直接构建一个:
import torch
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
class MNIST_data(Dataset):
def __init__(self, file_path,
transform=transforms.Compose([transforms.ToPILImage(), transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))])
):
df = pd.read_csv(file_path)
if len(df.columns) == n_pixels:
# test data
self.X = df.values.reshape((-1, 28, 28)).astype(np.uint8)[:, :, :, None]
self.y = None
else:
# training data
self.X = df.iloc[:, 1:].values.reshape((-1, 28, 28)).astype(np.uint8)[:, :, :, None]
self.y = torch.from_numpy(df.iloc[:, 0].values)
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
if self.y is not None:
return self.transform(self.X[idx]), self.y[idx]
else:
return self.transform(self.X[idx])
可以看到,这个dataset中,根据是否有标签分成返回两个不同的值。(训练集的话,同时返回数据和标签,测试集中仅仅返回数据)。
batch_size = 64
train_dataset = MNIST_data('./MNIST_csv/train.csv',
transform= transforms.Compose([
transforms.ToPILImage(),
transforms.RandomRotation(degrees=20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))]))
test_dataset = MNIST_data('./MNIST_csv/test.csv')
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=False)
关于这段代码:
构建了一个train的dataset和test的dataset,然后再分别构建对应的dataloader train_dataset中使用了随机旋转,因为这个函数是作用在PIL图片上的,所以需要将数据先转成PIL再进行旋转,然后转成Tensor做标准化,这里标准化就随便选取了0.5,有需要的可以做进一步的更改。 需要注意的是,转成PIL之前的数据是numpy的格式,所以数据应该是的形式,因为这里是单通道图像,所以数据的shape为:(72000,28,28,1).(72000为样本数量) 像是旋转、缩放等图像增强方法在训练集中才会使用,这是增强模型训练难度的操作,让模型增加鲁棒性;在测试集中常规情况是不使用旋转、缩放这样的图像增强方法的。(训练阶段是让模型学到内容,测试阶段主要目的是提高预测的准确度,这句话感觉是废话。。。)
2.2 构建模型类
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.features = nn.Sequential(
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(64 * 7 * 7, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(512, 10),
)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.features1(x)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
这个模型类整体来看中规中矩,都是之前讲到的方法。小测试:还记得xavier初始化时怎么回事吗?xavier初始化方法是一个非常常用的方法,在之前的文章中也详细的推导了这个。
之后呢,我们对模型实例化,然后给模型的参数传到优化器中,然后设置一个学习率衰减的策略,学习率衰减就是训练的epoch越多,学习率就越低的这样一个方法,在后面的文章中会详细讲述 。
import torch.optim as optim
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Net().to(device)
# model = torchvision.models.resnet50(pretrained=True).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.003)
criterion = nn.CrossEntropyLoss().to(device)
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
print(model)
运行结果自然是把整个模型打印出来了:
Net(
(features1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(features): Sequential(
(0): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): Dropout(p=0.5, inplace=False)
(5): Linear(in_features=512, out_features=512, bias=True)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU(inplace=True)
(8): Dropout(p=0.5, inplace=False)
(9): Linear(in_features=512, out_features=10, bias=True)
)
)
2.3 训练模型
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 读入数据
data = data.to(device)
target = target.to(device)
# 计算模型预测结果和损失
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad() # 计算图梯度清零
loss.backward() # 损失反向传播
optimizer.step()# 然后更新参数
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
exp_lr_scheduler.step()
先定义了一个训练一个epoch的函数,然后下面是训练10个epoch的主函数代码。
log = [] # 记录一下loss的变化情况
n_epochs = 2
for epoch in range(n_epochs):
train(epoch)
# 把log化成折线图
import matplotlib.pyplot as plt
plt.plot(log)
plt.show()
注意注意,这时候会报一个错误,我们来看一下,我详细标注了我个人看报错时候的一个习惯: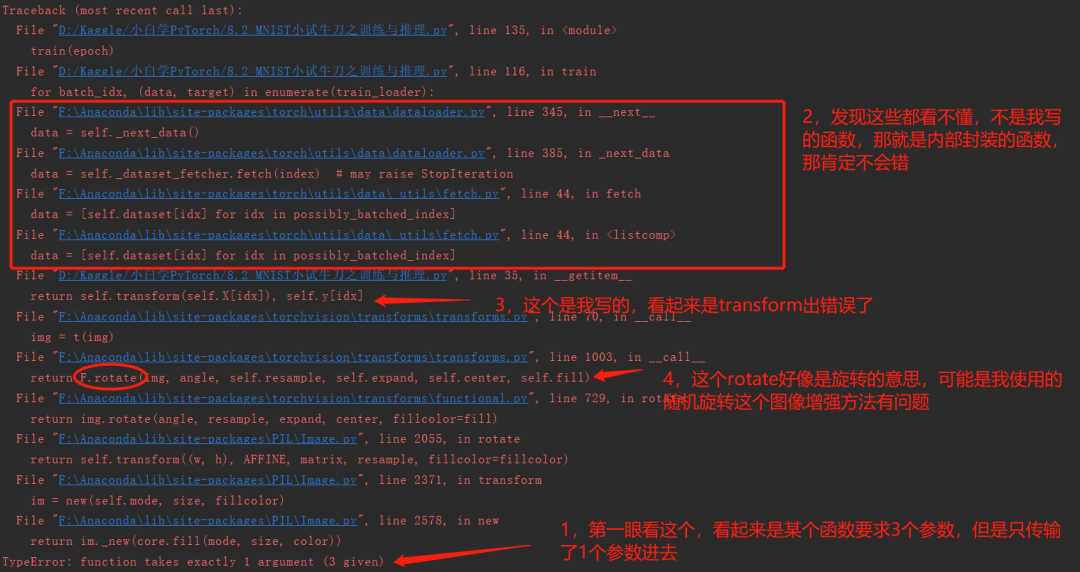
这时候我大概可以猜到,因为我们这个图片是灰度图片,是单通道的,可能这个RandomRotate函数要求输入图片是3个通道的(这个官方API上也没有细说),怎么办呢?完全可以直接在转成PIL格式之前,把numpy的那个(72000,28,28,1)复制第四维度,变成(72000,28,28,3).但是这里我想用上一节课教的一个方法torchvision.transforms.GrayScale(num_output_channels), 活学活用嘛.
所以把train_dataset那一块改成:
train_dataset = MNIST_data('./MNIST_csv/train.csv',
transform= transforms.Compose([
transforms.ToPILImage(),
transforms.Grayscale(num_output_channels=3),
transforms.RandomRotation(degrees=20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))]))
test_dataset = MNIST_data('./MNIST_csv/test.csv',
transform=transforms.Compose([
transforms.ToPILImage(),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))]))
然后不要忘记把模型类中的第一个卷积层的输入通道改成3哦~
# self.features1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.features1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
然后重新运行代码,发现可以正常训练了,打印输出的部分截图如下: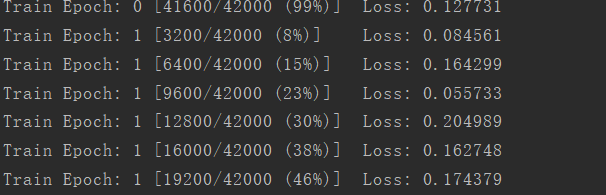
然后看一下损失下降的情况,算是收敛了,训练的epoch更多应该会更好: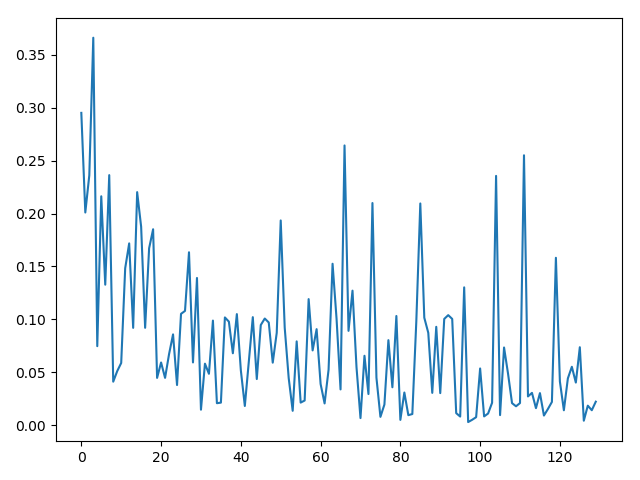 发现训练是收敛的。这里需要注意的是,现在用全部的数据进行训练,没有使用验证集的做法,是有可能过拟合情况出现的(但是这里只是训练了10个epoch应该不会过拟合),更稳妥的做法是把数据分成训练集和验证机(可以是2:1,3:1,4:1)都可以,4:1比较常用,这也就是n-fold的方法。 在之后的学习中会详细介绍这个,不过这个知识点也不难,也可以自行查阅。
发现训练是收敛的。这里需要注意的是,现在用全部的数据进行训练,没有使用验证集的做法,是有可能过拟合情况出现的(但是这里只是训练了10个epoch应该不会过拟合),更稳妥的做法是把数据分成训练集和验证机(可以是2:1,3:1,4:1)都可以,4:1比较常用,这也就是n-fold的方法。 在之后的学习中会详细介绍这个,不过这个知识点也不难,也可以自行查阅。
2.4 推理预测
def prediciton(data_loader):
model.eval()
test_pred = torch.LongTensor()
for i, data in enumerate(data_loader):
data = data.to(device)
output = model(data)
pred = output.cpu().data.max(1, keepdim=True)[1]
test_pred = torch.cat((test_pred, pred), dim=0)
return test_pred
test_pred = prediciton(test_loader)
类似trian,写一个预测的函数,返回预测的值。然后像是在EDA中那样,抽取测试集的8个数字,看看图像和预测结果的匹配情况
from torchvision.utils import make_grid
random_sel = np.random.randint(len(test_df), size=8)
data = (test_df.iloc[random_sel,:].values.reshape(-1,1,28,28)/255.)
grid = make_grid(torch.Tensor(data), nrow=8)
plt.rcParams['figure.figsize'] = (16, 2)
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.axis('off')
plt.show()
print(*list(test_pred[random_sel].numpy()), sep = ', ')
输出图像是: 打印输出:
打印输出: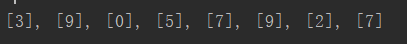
OK了,恭喜你,完成了MNIST手写数字集的分类。
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):